【性能调优】local模式模式下flink处理离线任务能力分析
文章目录
本文相关讨论
- flink内存对任务性能的影响:通过了解内存模型,了解这些模型都负责那些工作,比如用户代码使用堆,数据通讯使用直接内存等,以便能够根据任务特点针对性调整任务内存;
- 并发与带宽之间的关系,local模式下怎么根据带宽,设置最佳线程数;
- 内存监控相关命令。
?
任务说明:
使用local模式运行flink sql任务,任务为:从hdfs解析数据到hdfs中的离线任务,其中数据量有4亿,文件数有13个,初始运行参数为:堆内存设为3g、并发设为13,其中运行命令如下:
java -XX:NativeMemoryTracking=summary -Xms3096m -Xmx3096m -cp $FLINK_HOME/lib/chunjun-core.jar:$FLINKX_HOME/bin/:$FLINK_HOME/lib/*:$HADOOP_CLASSPATH \
$CLASS_NAME -job hdfs-hdfs.sql -mode local -jobType sql \
-flinkConfDir $FLINK_HOME/conf \
-flinkLibDir $FLINK_HOME/lib \
-hadoopConfDir $HADOOP_CONF_DIR \
-confProp "{ \"taskmanager.numberOfTaskSlots\":13}"
本例子使用chunjun提交flink任务。
?
一. flink的内存管理
了解flink内存模型,可以让我们针对任务特点,合理设置内存,在不造成内存浪费的同时,分析出任务性能瓶颈。
1.Jobmanager的内存模型
| 组成部分 | 配置参数 | 描述 |
|---|---|---|
| JVM 堆内存 | jobmanager.memory.heap.size | JobManager 的 JVM 堆内存。框架内存、特殊批处理source、cp、akka通讯(java api实现)。 |
| 堆外内存 | jobmanager.memory.off-heap.size | JobManager 的_堆外内存(直接内存或本地内存)_。 |
| JVM Metaspace | jobmanager.memory.jvm-metaspace.size | Flink JVM 进程的 Metaspace。 |
| JVM 开销 | jobmanager.memory.jvm-overhead.min jobmanager.memory.jvm-overhead.max jobmanager.memory.jvm-overhead.fraction | 用于其他 JVM 开销的本地内存,例如栈空间、垃圾回收空间等。该内存部分为基于进程总内存的受限的等比内存部分。 |
Flink 需要多少 JVM 堆内存,很大程度上取决于运行的作业数量、作业的结构及上述用户代码的需求。
jobManager的内存管理相关调优不用关注太多,因为jobmanager的任务相对固定。
?
2.TaskManager的内存模型
2.1. 模型说明
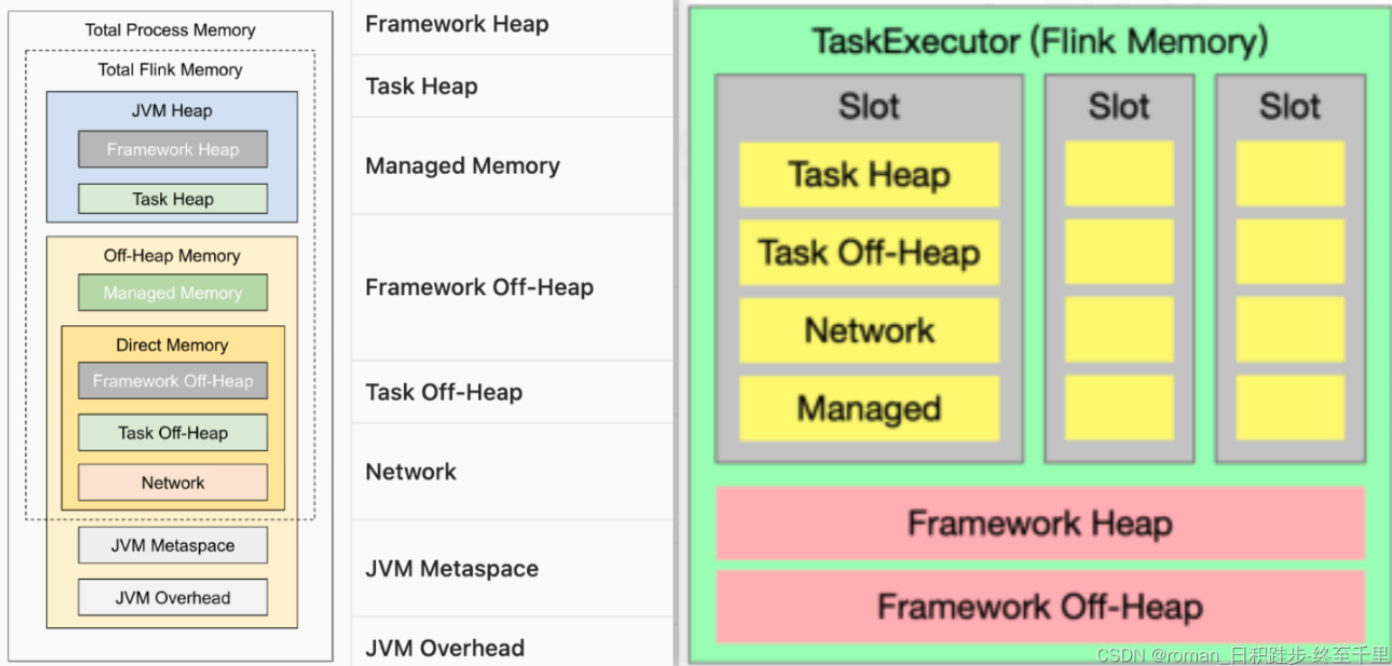
| 内存分类 | 解释 |
|---|---|
| 一. 堆内存 | |
| 1. 框架堆内存 | 启动TM所需内存 |
| 2. Task堆内存 | 存放、执行Flink算子及用户代码 |
| 二.堆外内存 | |
| 3. 框架堆外内存* | 用于 Flink 框架的堆外内存(直接内存或本地内存) |
| 4. 任务堆外内存* | 用于 Flink 应用的算子及用户代码的堆外内存(直接内存或本地内存)(比如用户代码使用netty进行数据传输)。 |
| 5. 网络内存* | 用户任务之间数据传输的直接内存 |
| 6. 托管内存 | 用于存放Flink的中间结果和RocksDB State Backend 的本地内存 |
| 7. JVM Metaspace和Overhead内存 | 用于JVM存储类元数据;JVM的例如栈空间、垃圾回收空间等开销 |
*代表直接内存。
?
2.2. 通讯、数据传输方面
TaskManager和JobManager之间的通讯
主要依赖JVM堆内存,网络缓冲器内存在数据传输方面也起到了一定的作用。具体来说:
- TaskManager和JobManager之间的所有通信(例如任务提交,状态更新等)都是通过Akka消息进行的。
- 在数据传输过程中,TaskManager使用的网络缓冲器内存也在一定程度上参与了和JobManager的通信。比如说,TaskManager需要向JobManager发送一些统计信息,或者在写入或读取远程状态数据时,都需要使用网络缓冲器内存。
?
TaskManager之间的通信
TaskManager之间的通信主要使用的是网络缓冲器内存(Network Memory)。当两个TaskManager之间需要交换数据时,会使用网络缓冲器内存来存储待发送的数据以及接收到的数据。
Flink的网络通信基于Netty,Netty默认使用堆外(off-heap)内存进行数据的读写操作。在数据发送方,Flink会先将数据序列化后存放到网络缓冲器中,然后通过网络发送到接收方。在接收方,Flink会从网络缓冲器中读取数据,然后进行反序列化,恢复成原始的数据格式。 网络缓冲器内存的大小会影响Flink job的性能,如果设置得过小可能会导致数据传输的瓶颈,过大则可能会浪费内存资源。
?
2.3. 框架、任务堆外内存
- 框架堆外内存:主要用于网络缓冲和一些需要大数据计算的操作,如排序或哈希操作。Flink使用堆外内存以存储中间结果,防止大数据操作时耗尽所有的Java堆内存。
- 任务堆外内存:主要用于用户代码和操作,以及用户代码依赖的库和插件的内存需求。它使得用户代码和框架操作能在任务中并行运行而不会互相干扰。
在实际操作中,你可以根据具体工作负载的需求来调整这三部分内存的配置。
?
2.4. 托管内存
托管内存(Managed Memory)主要用于数据处理和中间结果的存储,被用于以下几个主要的用途:
- 状态后端:如果你使用RockDB这样的内存稀疏状态后端,那么托管内存可以用作写缓冲区或者读缓冲区,用来优化读写的性能。
- 网络缓冲:在数据发送和接收过程中,Flink使用托管内存作为网络缓冲区。
- 批处理算子:在进行批处理的计算时,如排序和哈希操作,Flink会使用到托管内存。
?
状态后端存储
- Flink 任务处理中的状态(例如键控状态)通常需要持久化,以确保容错性和恢复能力。
托管内存是Flink特地为状态后端和网络缓冲等用途分配的内存段。 托管内存被用于存储状态后端的数据,这样可以避免将大量状态数据存储在 JVM 堆内存中,从而提高任务的稳定性和性能。- 当你启用RockDB状态后端时,Flink将把数据写入磁盘,而不仅仅是维持在内存中,这样可以支持更大的状态大小和更长的保留周期。
?
3.任务分析
任务为local模式,任务为从hdfs读到hdfs写,hdfs的源数据有13个文件,总共有4亿的数据,每条数据98byte。下面从flink内存模型的角度分析下任务对各内存的使用情况
local模式代表,在机器上启动一个minicluster,这包含一个jobmanager、一个taskmanager。
- 任务启动时会使用框架堆内存(Framework Heap Memory)创建启动jobmanager和taskmanager。
- 因为只有一个taskmanager,也就是不会涉及到taskmanager之间的数据传输,所以不会用到网络缓存(Network Memory)。
- 从用户代码层面看,这里使用的是flink sql ,其中hdfs-connector用于读写数据,这算是用户代码,而相关读写实现使用的是hdfs
client相关api实现,api中没有涉及到使用直接内存的方法,所以读写数据的操作是在堆内存中(.任务堆内存(Task Heap Memory))。- 此离线任务来一条数据处理一条,即任务无状态、或中间结果,也就是说任务不需要托管内存(Managed memory)
所以总体分析下来,local模式下我们需要调控的是堆内存,因为数据传输主要存在于用户代码中。
?
二. 单个节点的带宽瓶颈
根据拿到的带宽,与任务消费数据速度,我们大概可以测试出任务的并发度。
1. 带宽相关理论
网络带宽是指在一个固定的时间内(1秒),能通过的最大位数据,是个峰值数据, 单位是Mbps。
?
上行带宽/下行带宽
带宽的上行和下行分别指的是网络传输中数据的上传和下载方向。
- 对于服务器来说对外提供服务用的是自己的
上行带宽和用户的下行带宽, 而用户上传东西则用的自己的上行带宽和服务器的下行带宽- 对于用户来说访问服务器用的是用户的
下行带宽和服务器的上行带宽, 而上传文件则用的用户的上行带宽和服务器的下行带宽
?
流量单位/存储单位
下载速度的单位为KB/s,而带宽所使用的计量单位为Kb/s,两者相差8倍:8 bit = 1 B 一字节 (1Byte)
带宽速度计算:
1M带宽下载速度125KB/s;
2M带宽下载速度125KB/s*2;
10M带宽下载速度125KB/s*10=1.25M/s;
20M带宽下载速度125KB/s*20=2.5M/s;
100M带宽下载速度125KB/s*100=12.5M/s
?
实际带宽速率的损失
理论上,2Mbps带宽,宽带理论速率是 256KB/s。实际速率大约为103–200kB/s。4M,即4Mb/s宽带理论速率是 512KB/s 实际速率大约为200—440kB/s。
其原因是受用户计算机性能、网络设备质量、资源使用情况、网络高峰期、网站服务能力、线路衰耗、信号衰减等多因素的影响而造成的)。
?
吞吐量
吞吐量是指在没有帧丢失的情况下,设备能够接收并转发的最大数据速率实际带宽,单位Mbps, 通常用来描述一个系统的性能。
与带宽的关系:吞吐量即在规定时间、空间及数据在网络中所走的路径(网络路径)的前提下,下载文件时实际获得的带宽值。由于多方面的原因,实际上吞吐量往往比传输介质所标称的最大带宽小得多
例如: 带宽为10Mbps的链路连接的一对节点可能只达到2Mbps的吞吐量。这样就意味着,一个主机上的应用能够以2Mbps的速度向另外的一个主机发送数据。
?
2. 使用speedtest-cli 测试带宽
# 安装
$ sudo yum install -y speedtest-cli
# 测试
$ speedtest-cli
Retrieving speedtest.net configuration...
Testing from China Unicom (111.206.170.119)...
Retrieving speedtest.net server list...
Selecting best server based on ping...
Hosted by China Telecom TianJin-5G (TianJin) [123.83 km]: 65.213 ms
Testing download speed................................................................................
Download: 143.51 Mbit/s
Testing upload speed......................................................................................................
Upload: 456.74 Mbit/s
?
3. 任务分析
Speedtest-cli测量出的是你的网络连接的最大理论带宽。实际上,你的实际网络带宽可能因为很多因素(例如网络拥堵,服务器性能,距离测试服务器的远近,你本地网络的设置等)而低于这个理论值。对于代码中处理数据,还要考虑代码处理数据的效率。
实际在测试过程中,有如下瓶颈:
- 使用3G内存启动flink任务,对于每条数据为98Byte,单线程每次处理4万条数据,13个线程(数据源共有13个文件)同时消费,花费20s,大概算下来每秒处理2.43MB/s数据。
- 当增大堆内存时效率并未提升,也就是到了带宽瓶颈。且当我将内存降低到2G时,消费速度并未明显减小。
?
也就是说每秒处理2.43MB/s数据是机器带宽瓶颈,目前最佳内存为2G,并发减小时处理时间会比例减小,当并发减小到4时,处理速度达到快,3秒处理完,但总体算下来小于每秒处理2.43MB/s数据,也就是说并发根据文件数设置可以达到最佳性能。
?
3. 其他工具使用介绍
测试任务占用内存: jps + top
# 1. 找到指定进程
jps -l
2900 com.dtstack.chunjun.Main
3645 sun.tools.jps.Jps
# 2. 查看一个进程占用内存
top -p <pid>
按e会转换内存为byte->m->g等单位,较为人性化的展示。

?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 《PySpark大数据分析实战》-08.宽窄依赖和阶段划分
- 如何编写高效清晰的嵌入式C程序
- ConcurrentHashMap JDK1.7中Segment
- 想要拿到中留服认证,需要出境多少天?180天/360天吗??
- 业务架构映射-1 之 业务能力模型映射
- HTTPS协议把什么加密了?
- 接口测试——精通Postman测试工具
- 005文章解读与程序——数字技术与应用北大核心《微电网优化调度》已提供下载资源
- ARM 点灯
- 代码随想录算法训练营第三十五天|860.柠檬水找零、406.根据身高重建队列、452. 用最少数量的箭引爆气球