【无标题】
本文由掌控安全学院?-?杳若?投稿
起因
有时候目录扫描,我们会顺便扫描是否存在备份的情况,这时候就自己简单的写了一个python的脚本
主要想做到的是 例如我扫?http://xxx.cn?的站点目标的时候
会根据域名自动的去匹配以下这种基于域名生成的文件备份路径
http://a.xxx.cn/zkap.zip
http://a.xxx.cn/a.zip第一步-大大的logo
from colorama import init #cmd终端带颜色
init(autoreset=True)
def title():
print('+------------------------------------------')
print('+ 33[34m......初始化开始...... 33[0m')
print('+ 33[34m杳若出品 33[0m')
print('+ 33[34mTitle: 用于文件备份扫描~ 33[0m')
print('+ 33[36m使用格式: 输入必要的参数 33[0m')
print('+------------------------------------------')第二步-随机的请求头
当然是为了减少被ban的几率了
from faker import Faker # 随机请求头的库
import random # 为了增加随机的ip
# 随机请求头
def header():
headers = {
'Accept': '*/*',
'Referer': 'http://www.baidu.com',
'User-Agent': Faker().user_agent(),
'Cache-Control': 'no-cache',
'X-Forwarded-For': '127.0.0.{}'.format(random.randint(1, 255)),
}
return headers利用库做到了UA请求头随机,用random做到了xff的伪随机,当然Referer也可以换
第三步-确认传入的内容是否带协议以及切割URL
传入的内容可能带http可能https也可能不带,就要自己添加,这里写一个检测
from urllib.parse import urlparse # 协议分离的库
import requests # http协议请求的库
def urlpar(url):
# 这里是检测传入是否带http,不带的话就会自动去拼接
if 'http' not in url:
if url[-1] == '/':
url, p2, p3 = url.partition('/')
# 拼接的话会请求http,如果访问失败那就添加https
try:
requests.head(url='http://' + url, headers=header(), verify=False, timeout=(3, 8))
return 'http://' + url
except Exception as e:
return 'https://' + url
# 不然就是带协议头啦
else:
url_Doman = urlparse(url).netloc
url_http = urlparse(url).scheme
url_main = "{}{}{}".format(url_http, '://', url_Doman)
return url_main
# url域名分割
def tldex(url):
url = tldextract.extract(urlpar(url))
one = url.subdomain
three = url.suffix
two = url.domain
# 切割成了三个部分,顶级域名、主域和尾
return one, two, three第四步-做成字典
首先需要一个分割好的字典集合,然后添加对应的后缀
# 组合自定义字典
def dith(one, two, three):
urls = []
urls = urls + diy(one)
urls = urls + diy(two)
urls = urls + diy(three)
urls = urls + diy(two + '.' + three)
urls = urls + diy(one + '.' + two)
urls = urls + diy(one + '.' + two + '.' + three)
# 返回就是一个字典集合了
return urls
# 自定义字典内容
def diy(ci):
url = []
url.append('/' + ci + '.rar')
url.append('/' + ci + '.zip')
url.append('/' + ci + '.txt')
url.append('/' + ci + '.apk')
url.append('/' + ci + '.gz')
return url
这里都可以自定义各种内容第五步-发起http请求
发起请求的话就是不断的将url以及对应的路由进行拼接判定,这里利用了Content-Length来判断大小,大于一定的值就证明存在文件备份
但是考虑到了vue等框架的误报情况,做了一定的防误报处理
import requests # http协议请求的库
import requests.packages.urllib3.util.ssl_
requests.packages.urllib3.util.ssl_.DEFAULT_CIPHERS = 'ALL'
from urllib3.exceptions import InsecureRequestWarning
# 防止无证书连接的报错
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
# 进行备份扫描以及确认
# 这里传入需要检测的url以及需要拼接的后缀urls做的字典
def scan(url, urls):
a = 0
u = []
b = 0
# 传入了字典,进行遍历
for url1 in urls:
try:
# time.sleep(random.randint(1,10))
r = requests.head(url=url + url1, headers=header(), verify=False, timeout=(3, 30)) # 通过请求漏洞存在网址,获取其数据流的大小
rarsize = int(r.headers.get('Content-Length')) # 是str格式-对数据流大小的获取
if rarsize >= 1000 * 10:
print('33[32m [o] 存在漏洞[>]%s[>]%skb33[0m' % (url + url1, str(rarsize)))
a = a + 1
u.append(url + url1 + '\t' + str(rarsize))
if (a >= 5):
print('33[31m [x] 存在误报[>]%s[>]%skb33[0m' % (url + url1, str(rarsize)))
break
pass
else:
print('33[31m [x] 不存在漏洞[>]%s[>]%skb33[0m' % (url + url1, str(rarsize)))
except Exception as e:
try:
r = requests.head(url=url + url1, headers=header(), verify=False, timeout=(3, 30))
if r.status_code == 404:
b = b + 1
except Exception as e:
b = b +1
# 如果请求了10个数据包都是404,那太慢了,直接提示url不行
if b >= 10:
break
print(' [?] 存在问题>' + url + url1)
# 如果存在漏洞的数量大于5个,极大可能就是误报了
if a < 5 and u != []:
for url in u:
with open('cunzai.txt', 'a+', encoding='utf-8') as fp:
fp.write(url + '\n')简易的备份扫描工具就做好啦
# -*- coding:utf-8 -*-
import random # 请求协议/域名分割/随机
import re
from urllib.parse import urlparse # 协议分离
from colorama import init #cmd终端带颜色
init(autoreset=True)
import requests
# import time
# requests防止报错
import requests.packages.urllib3.util.ssl_
import tldextract
#from fake_useragent import UserAgent # 随机请求头
from faker import Faker # 随机请求头二代
requests.packages.urllib3.util.ssl_.DEFAULT_CIPHERS = 'ALL'
from urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
# 随机请求头
def header():
headers = {
'Accept': '*/*',
'Referer': 'http://www.baidu.com',
'User-Agent': Faker().user_agent(),
'Cache-Control': 'no-cache',
'X-Forwarded-For': '127.0.0.{}'.format(random.randint(1, 255)),
}
return headers
# url进行协议分割
def urlpar(url):
if 'http' not in url:
if url[-1] == '/':
url, p2, p3 = url.partition('/')
try:
requests.head(url='http://' + url, headers=header(), verify=False, timeout=(3, 8))
return 'http://' + url
except Exception as e:
return 'https://' + url
else:
url_Doman = urlparse(url).netloc
url_http = urlparse(url).scheme
url_main = "{}{}{}".format(url_http, '://', url_Doman)
return url_main
# url域名分割
def tldex(url):
url = tldextract.extract(urlpar(url))
one = url.subdomain
three = url.suffix
two = url.domain
return one, two, three
# 自定义字典内容
def diy(ci):
url = []
url.append('/' + ci + '.rar')
url.append('/' + ci + '.zip')
url.append('/' + ci + '.txt')
url.append('/' + ci + '.apk')
url.append('/' + ci + '.gz')
return url
# 组合自定义字典
def dith(one, two, three):
urls = []
urls = urls + diy(one)
urls = urls + diy(two)
urls = urls + diy(three)
urls = urls + diy(two + '.' + three)
urls = urls + diy(one + '.' + two)
urls = urls + diy(one + '.' + two + '.' + three)
return urls
# 拼接比较常见的备份地址
def dithadd(url):
urls = ['/.git', '/.svn', '/新建文件夹.rar', '/新建文件夹.zip', '/备份.rar', '/wwwroot.rar', '/wwwroot.zip', '/backup.rar',
'/bf.rar', '/beifen.rar', '/www.rar', '/vera_Mobile.zip', '/web.rar', '/zuixin.rar', '/最新.rar',
'/test.rar', '/test.zip', '/web.zip', '/www.zip', '/最新备份.rar']
url = url + urls
return url
# 拼接字典
def adithaddadd(url):
urls = []
for urla in open('dict.txt', encoding='utf-8'):
urla = urla.replace('\n', '')
if len(urla) != 0:
urls.append(urla)
else:
pass
urls = urls + url
return urls
# 进行备份扫描以及确认
def scan(url, urls):
a = 0
u = []
b = 0
for url1 in urls:
try:
# time.sleep(random.randint(1,10))
r = requests.head(url=url + url1, headers=header(), verify=False, timeout=(3, 30)) # 通过请求漏洞存在网址,获取其数据流的大小
rarsize = int(r.headers.get('Content-Length')) # 是str格式-对数据流大小的获取
if rarsize >= 1000 * 10:
print('33[32m [o] 存在漏洞[>]%s[>]%skb33[0m' % (url + url1, str(rarsize)))
a = a + 1
u.append(url + url1 + '\t' + str(rarsize))
if (a >= 5):
print('33[31m [x] 存在误报[>]%s[>]%skb33[0m' % (url + url1, str(rarsize)))
break
pass
else:
print('33[31m [x] 不存在漏洞[>]%s[>]%skb33[0m' % (url + url1, str(rarsize)))
except Exception as e:
try:
r = requests.head(url=url + url1, headers=header(), verify=False, timeout=(3, 30))
if r.status_code == 404:
b = b + 1
except Exception as e:
b = b +1
if b >= 10:
break
print(' [?] 存在问题>' + url + url1)
if a < 5 and u != []:
for url in u:
with open('cunzai.txt', 'a+', encoding='utf-8') as fp:
fp.write(url + '\n')
def main(url, key):
p1, p2, p3 = url.replace('http://', '').replace('https://', '').partition(':')
if re.match(r"^(?:[0-9]{1,3}\.){3}[0-9]{1,3}$", p1):
add_url = dithadd([])
else:
one, two, three = tldex(url)
urls = dith(one, two, three) # 自定义列表
add_url = dithadd(urls)
if key == 'yes':
add_url = adithaddadd(add_url)
scan(urlpar(url), add_url)
# 这是标题~
def title():
print('+------------------------------------------')
print('+ 33[34m......初始化开始...... 33[0m')
print('+ 33[34m杳若出品 33[0m')
print('+ 33[34mTitle: 用于文件备份扫描~ 33[0m')
print('+ 33[36m使用格式: 输入必要的参数 33[0m')
print('+------------------------------------------')
if __name__ == "__main__":
title()
mode = input("请选择模式单个/多个:Please A/B ->")
key = input("是否需要使用字典yes/no:")
if mode == 'A':
url = input("请输入需要目录扫描的url:")
main(url, key)
elif mode == 'B':
txt = input("请输入需要目录扫描的TXT:")
for url in open(txt, encoding='utf-8'):
url = url.replace('\n', '')
main(url, key)
else:
print("请输入正确的mode!")在成品里面多了个附加的功能,哈哈(也就是选择A/B之类的)
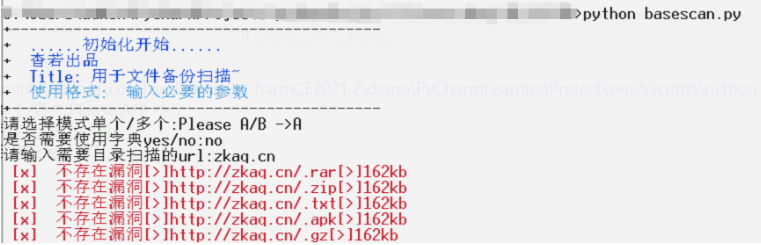
单个
请选择模式单个/多个:Please A/B -> 第一步是选择要扫单个文件还是多个文件
???????????如果选A
请选择模式单个/多个:Please A/B ->A
是否需要使用字典yes/no: #第二步是选择是否需要字典,不需要会使用基础的备份扫描功能
如果选yes 默认加载启动dict.txt
请选择模式单个/多个:Please A/B ->A
是否需要使用字典yes/no:yes
请输入需要目录扫描的url: #第三步是选择需要扫描的url地址

多个:
请选择模式单个/多个:Please A/B ->B
是否需要使用字典yes/no:no
请输入需要目录扫描的TXT: #前面与单个相同,这一步开始需要输入txt文本进行批量扫描,不过不是多线程

有时候出货就是这么简单~
申明:本账号所分享内容仅用于网络安全技术讨论,切勿用于违法途径。
免费领取安全学习资料包!
渗透工具

技术文档、书籍
 ?
?

面试题
帮助你在面试中脱颖而出

视频
基础到进阶
环境搭建、HTML,PHP,MySQL基础学习,信息收集,SQL注入,XSS,CSRF,暴力破解等等
 ?
?

应急响应笔记
学习路线

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- uniapp微信小程序投票系统实战 (SpringBoot2+vue3.2+element plus ) -我创建的投票列表实现
- 企业必知的加速FTP传输解决方案
- 迷宫问题的对比实验研究(代码注释详细、迷宫及路径可视化)
- 文件上传进阶(三)值得关注的3种类型漏洞
- redis pipeline实现,合并多个请求,可有效降低redis访问延迟
- ICC2:flip first row的影响
- 除留余数哈希表
- 如何在短视频平台上卖服装
- vue 当提交弹窗表单的时候 父子组件的逻辑记录
- 如何修改element中el-popover + 时间选择器