集合的核心知识
什么是java集合
Java集合是一组用于存储和操作数据的类和接口。它们提供了各种数据结构,如数组、链表、栈、队列、散列表等,以及与数据的增删改查操作相关的方法。
Java集合框架包括以下几个主要接口和类:
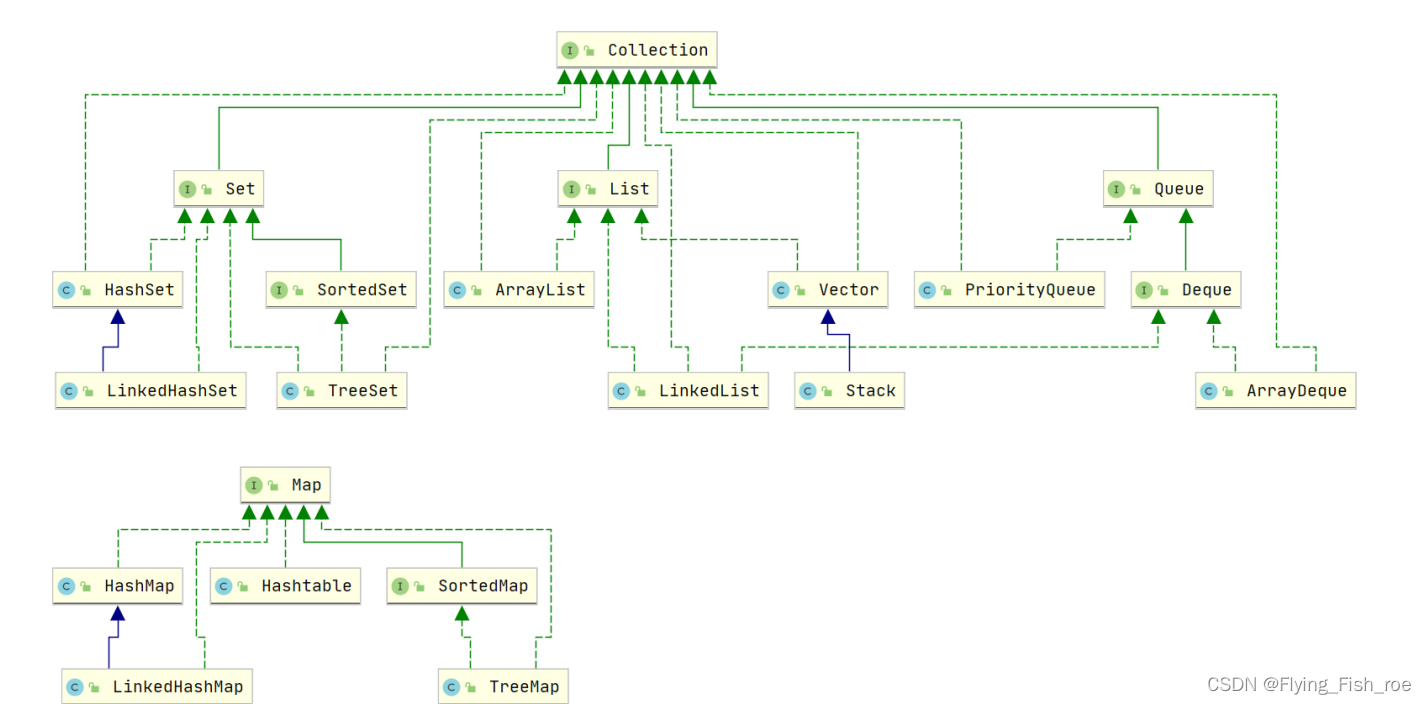
- Collection接口是所有集合类的根接口,它定义了一组方法来操作集合中的元素。
- List接口是一个有序的集合,元素可以重复。常用的实现类有ArrayList、LinkedList和Vector。
- Set接口是一个无序的集合,不允许元素重复。常用的实现类有HashSet和TreeSet。
- Map接口是一个键值对的集合,每个键最多只能关联一个值。常用的实现类有HashMap、TreeMap和LinkedHashMap。
- Queue接口是一个用于存储元素的队列,遵循先进先出的原则。常用的实现类有LinkedList和PriorityQueue。
- Stack类是一个后进先出的堆栈,它继承自Vector类。
除了以上的接口和类,Java还提供了一些其他的集合类,如BitSet、Hashtable、EnumSet等。
List, Set, Queue, Map 四者的区别?
Java集合中的List、Set、Queue和Map是四种不同的接口,它们分别用于存储和操作不同类型的数据。
-
List(列表)是有序的集合,允许存储重复的元素。List接口的常用实现类有ArrayList和LinkedList,前者基于数组实现,后者基于链表实现。List接口提供了按照索引访问元素的功能,可以根据需要插入、删除和修改元素。
-
Set(集合)是无序的集合,不允许存储重复的元素。Set接口的常用实现类有HashSet和TreeSet,前者基于哈希表实现,后者基于红黑树实现。Set接口提供了判断元素是否存在和添加、删除元素的功能。
-
Queue(队列)是一种特殊的集合,按照特定的顺序进行操作,通常是先进先出(FIFO)或者优先级优先。Queue接口的常用实现类有LinkedList和PriorityQueue,前者基于链表实现,后者基于堆实现。Queue接口提供了添加、移除和检查元素的功能。
-
Map(映射)是一种键值对的集合,每个元素都包含一个键和一个值。Map接口的常用实现类有HashMap和TreeMap,前者基于哈希表实现,后者基于红黑树实现。Map接口提供了根据键查找值、添加和删除键值对的功能。
总结:
- List是有序可重复的集合,提供了按照索引访问元素的功能。
- Set是无序不可重复的集合,提供了判断元素是否存在的功能。
- Queue是按照特定顺序操作的集合,通常是先进先出或者优先级优先。
- Map是键值对的集合,提供了根据键查找值的功能。
ArrayList 和 Vector 的区别?
-
线程安全性:Vector是线程安全的,而ArrayList不是。在多线程环境下,多个线程可以同时访问和修改Vector,不会发生线程安全问题;而在ArrayList中,多个线程同时修改可能导致数据不一致或抛出ConcurrentModificationException异常。
-
扩容方式:ArrayList和Vector在扩容时的方式不同。ArrayList每次扩容会增加当前长度的50%,而Vector每次扩容会增加当前长度的一倍。
-
性能:由于ArrayList不是线程安全的,它的性能比Vector要好。在单线程环境下,使用ArrayList效率更高;在多线程环境下,如果需要保证线程安全,可以使用Vector。不过,在Java 1.2之后,引入了更高效的线程安全集合类如ConcurrentHashMap和CopyOnWriteArrayList,已经成为更好的选择。
-
遗留问题:Vector是Java早期版本中的集合类,而ArrayList是在Java 1.2之后引入的。为了向后兼容,Vector仍然被保留,但在新的代码中推荐使用ArrayList。
总结来说,ArrayList和Vector的主要区别在于线程安全性和扩容方式。如果需要线程安全的集合,可以使用Vector,如果不需要线程安全,推荐使用ArrayList。
集合框架底层数据结构?
-
ArrayList:
- 底层数据结构:基于数组实现的动态数组。
- 特点:ArrayList允许随机访问元素,通过索引可以快速访问或修改元素。
- 适用场景:当需要频繁地查询和修改元素时,ArrayList是一个较好的选择。
-
LinkedList:
- 底层数据结构:基于链表实现的双向链表。
- 特点:LinkedList通过指针将元素连接形成链表,每个元素都包含指向前后元素的引用。
- 适用场景:当需要频繁地在集合的前后插入或删除元素时,LinkedList是一个较好的选择。
-
HashSet:
- 底层数据结构:基于HashMap实现的哈希表。
- 特点:HashSet使用哈希函数将元素映射到数组中,并使用链表处理哈希冲突。
- 适用场景:当需要高效地检查是否包含某个元素,并且不关心元素的顺序时,HashSet是一个较好的选择。
-
TreeSet:
- 底层数据结构:基于红黑树实现的自平衡二叉搜索树。
- 特点:TreeSet中的元素会根据其值进行排序,并且支持高效的插入、删除和查询操作。
- 适用场景:当需要对元素进行有序存储,并且需要快速地查找最小和最大元素时,TreeSet是一个较好的选择。
-
HashMap:
- 底层数据结构:基于数组和链表实现的哈希表。
- 特点:HashMap使用哈希函数将键映射到数组的索引位置,并使用链表处理哈希冲突。在Java 8及以上版本中,当链表长度达到一定阈值时,会将链表转换为红黑树以提供更高效的操作。
- 适用场景:当需要根据键进行快速查找和更新值时,HashMap是一个较好的选择。
-
TreeMap:
- 底层数据结构:基于红黑树实现的自平衡二叉搜索树。
- 特点:TreeMap中的键会根据其值进行排序,并且支持高效的插入、删除和查询操作。
- 适用场景:当需要根据键进行有序存储,并且需要快速地查找最小和最大键时,TreeMap是一个较好的选择。
-
LinkedHashMap:
- 底层数据结构:基于哈希表和双向链表实现的有序哈希表。
- 特点:LinkedHashMap使用哈希表维护键值对的存储顺序,并使用双向链表维护插入顺序。可以选择按照插入顺序或者访问顺序进行迭代。
- 适用场景:当需要按照插入顺序或者访问顺序进行迭代,并且不关心元素的排序时,LinkedHashMap是一个较好的选择。
?
ArrayList 与 LinkedList 区别
-
数据结构:
- ArrayList 是基于数组实现的列表,它在内存中按照连续的索引存储元素。
- LinkedList 是基于链表实现的列表,它通过节点之间的链接存储元素。
-
插入和删除操作:
- ArrayList 在插入和删除元素时需要将其后的元素向后移动或向前移动,因为数组中的元素是连续存储的。
- LinkedList 在插入和删除元素时只需要修改节点的链接即可,不需要移动其他元素。
-
访问元素:
- ArrayList 可以通过索引直接访问元素,因为它在内存中按照连续的索引存储元素。
- LinkedList 在访问元素时需要从头节点或尾节点开始遍历,直到找到目标位置。
-
内存占用:
- ArrayList 在每个元素上存储额外的空间作为缓冲区,以便在需要时扩展数组的大小。因此,它可能会浪费一些内存空间。
- LinkedList 需要为每个节点存储额外的指针,因此在存储相同数量的元素时可能占用更多的内存空间。
-
性能:
- ArrayList 在随机访问元素时性能较好,因为可以通过索引直接访问元素。但插入和删除操作可能较慢,特别是在列表的中间位置。
- LinkedList 在插入和删除操作时性能较好,因为只需要修改节点的链接,不需要移动其他元素。但在随机访问元素时性能较差,因为需要遍历节点。
comparable 和 Comparator 的区别?
-
Comparable(可比较)是一个接口,用于实现对象的自然排序。当一个类实现了Comparable接口时,它必须实现compareTo()方法,该方法用于定义对象之间的排序规则。在Java中,许多类(如String、Integer等)都实现了Comparable接口,因此它们可以直接进行比较和排序。当使用Collections.sort()或Arrays.sort()方法时,会自动调用实现了Comparable接口的类的compareTo()方法进行排序。
例如,String类实现了Comparable接口,可以使用compareTo()方法比较字符串的字典顺序:
String str1 = "apple"; String str2 = "banana"; int result = str1.compareTo(str2); // result < 0,str1在字典中排在str2之前 -
Comparator(比较器)是一个独立的接口,用于定义两个对象之间的自定义排序规则。Comparator接口需要实现compare()方法,该方法用于比较两个对象的大小。当需要对一个类进行排序时,但该类未实现Comparable接口或需要使用不同的排序规则时,可以使用Comparator来实现自定义的排序。
public class Employee { private String name; private int age; // ... } public class AgeComparator implements Comparator<Employee> { @Override public int compare(Employee emp1, Employee emp2) { return emp1.getAge() - emp2.getAge(); } } List<Employee> employeeList = new ArrayList<>(); // 添加员工到employeeList... Collections.sort(employeeList, new AgeComparator());在上面的例子中,我们创建了一个AgeComparator类来根据员工的年龄进行排序。通过调用Collections.sort()方法,并传递一个AgeComparator对象,可以根据自定义的比较规则对员工列表进行排序。
总结:
- Comparable接口用于实现对象的自然排序,它是在对象内部定义的排序规则;
- Comparator接口用于实现自定义的排序规则,它是在对象外部定义的排序规则;
双向链表和双向循环链表?
双向链表(Doubly Linked List)是一种链表结构,每个节点除了存储数据之外,还有两个指针,分别指向前一个节点和后一个节点。它具有以下特点:
- 支持双向遍历:由于每个节点都指向前一个和后一个节点,因此可以很方便地在链表中进行前向和后向遍历,即可以从头到尾或从尾到头遍历链表。
- 插入和删除操作高效:相较于单向链表,双向链表的插入和删除操作更高效。因为在双向链表中,不仅可以通过当前节点的指针找到下一个节点,还可以通过前一个节点的指针找到当前节点。所以在插入或删除节点时,只需要修改相邻节点的指针即可,而不需要从头开始遍历链表。
- 占用更多的内存空间:由于每个节点需要保存两个指针,相较于单向链表,双向链表会占用更多的内存空间。

双向循环链表(Doubly Circular Linked List)是双向链表的一种变体,它的最后一个节点指向第一个节点,形成一个闭环。它具有以下特点:
- 支持循环遍历:由于最后一个节点指向第一个节点,因此可以很方便地在链表中进行循环遍历,即无论从头到尾还是从尾到头,都可以无限次遍历整个链表。
- 支持基于节点的循环算法:在一些算法实现中,需要通过循环遍历链表中的节点,双向循环链表可以很方便地实现这种算法。当遍历到最后一个节点时,会再次回到第一个节点,从而实现循环迭代。

区别:
- 结构上的差异:双向链表中每个节点有两个指针,分别指向前一个节点和后一个节点;而双向循环链表中最后一个节点的指针指向第一个节点,形成一个闭环。
- 遍历方式的不同:双向链表支持前向和后向遍历,而双向循环链表支持循环遍历,可以无限次遍历整个链表。
- 内存占用的差异:双向链表每个节点需要额外存储两个指针,因此占用更多的内存空间;而双向循环链表通过闭环结构,可以节省最后一个节点到第一个节点的指针所占用的内存空间。
在空间允许的情况下,双向链表和双向循环链表更加灵活和高效,适用于对链表进行频繁的插入和删除操作,或者需要循环遍历链表的场景。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Redis集群搭建
- 详细教程!VMware Workstation Pro16 安装 + 创建 win7 虚拟机!
- 八股文打卡day22——操作系统(5)
- 启程K3s:用简单的步骤构建你的Kubernetes天地
- 智能优化算法应用:基于社会群体算法3D无线传感器网络(WSN)覆盖优化 - 附代码
- LDD学习笔记 -- Linux内核模块
- 双指针——移动零
- Spark四:Spark Streaming和Structured Streaming
- 九州金榜|家庭教育学会给高三孩子减压,助力孩子考上好大学!
- 软件工程期末复习