Linux - ElasticSearch安装部署
一、简介
全文搜索属于最常见的需求,开源的 Elasticsearch (以下简称 es)是目前全文搜索引擎的首选。
它可以快速地储存、搜索和分析海量数据。维基百科、Stack Overflow、Github 都采用它。
Elasticsearch简称es,在企业内同样是一款应用非常广泛的搜索引擎服务。
很多服务中的搜索功能,都是基于es来实现的。
二、安装
1、添加yum仓库
# root执行
# 导入仓库密钥
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
# 添加yum源
# 编辑文件
vim /etc/yum.repos.d/elasticsearch.repo
[elasticsearch-7.x]
name=Elasticsearch repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
# 更新yum缓存
yum makecache2、安装es
yum install -y elasticsearch3、配置es
vim /etc/elasticsearch/elasticsearch.yml
# 17行,设置集群名称
cluster.name: my-cluster
# 23行,设置节点名称
node.name: node-1
# 56行,允许外网访问
network.host: 0.0.0.0
# 74行,配置集群master节点
cluster.initial_master_nodes: ["node-1"]4、启动es
systemctl start | stop | status | enable | disable elasticsearch5、关闭防火墙
systemctl stop firewalld
systemctl disable firewalld6、测试
浏览器打开:http://ip:9200/?pretty
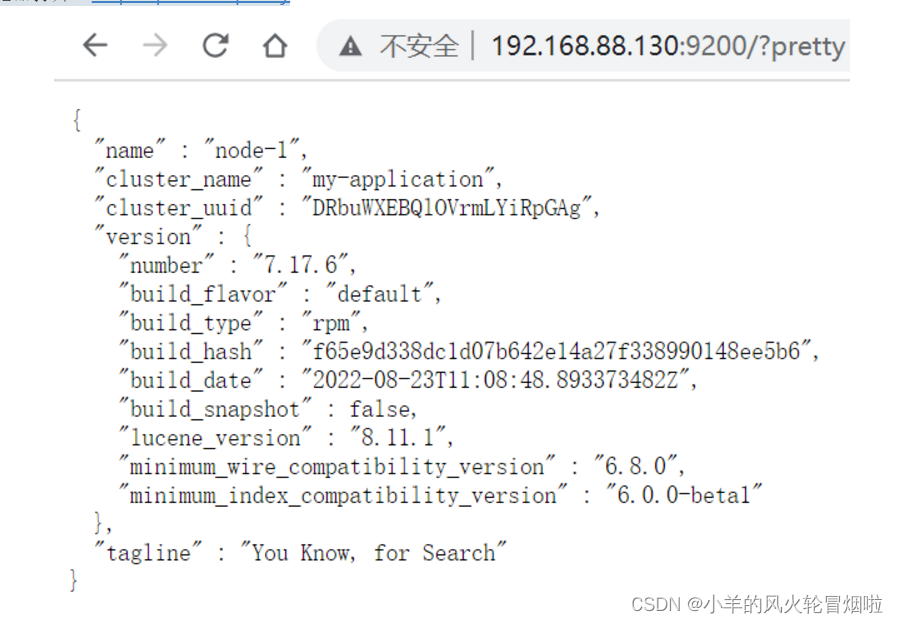
以上es部署成功。
三、ES 集群化环境前置准备
1、介绍
在前面,我们所学习安装的软件,都是以单机模式运行的。
后续,我们将要学习大数据相关的软件部署,所以后续我们所安装的软件服务,大多数都是以集群化(多台服务器共同工作)模式运行的。
所以,在当前小节,我们需要完成集群化环境的前置准备,包括创建多台虚拟机,配置主机名映射,SSH免密登录等等。
2、部署
配置多台Linux虚拟机
安装集群化软件,首要条件就是要有多台Linux服务器可用。
我们可以使用VMware提供的克隆功能,将我们的虚拟机额外克隆出3台来使用。
2.1 首先,关机当前CentOS系统虚拟机(可以使用root用户执行init 0来快速关机)
2.2?新建文件夹
2.3?克隆
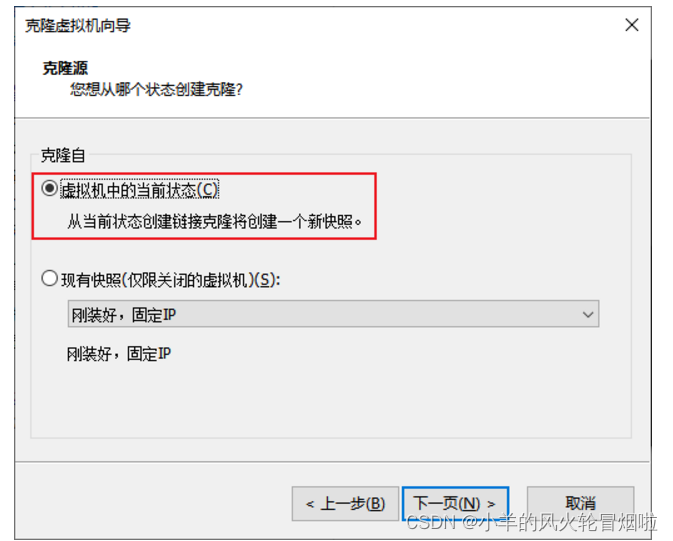
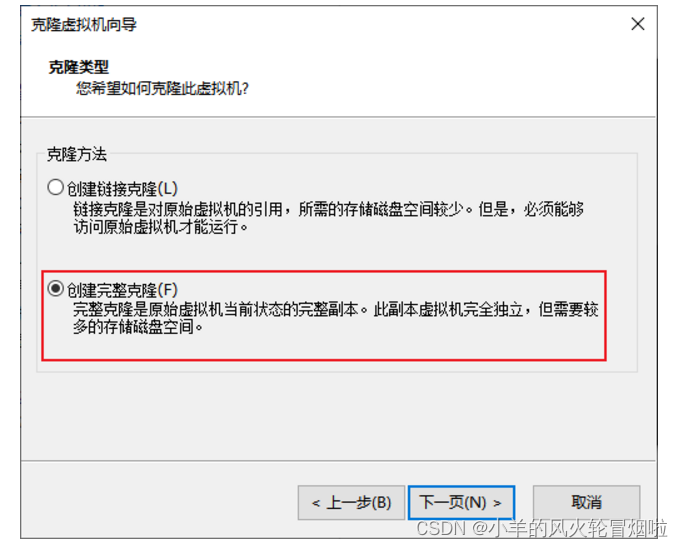
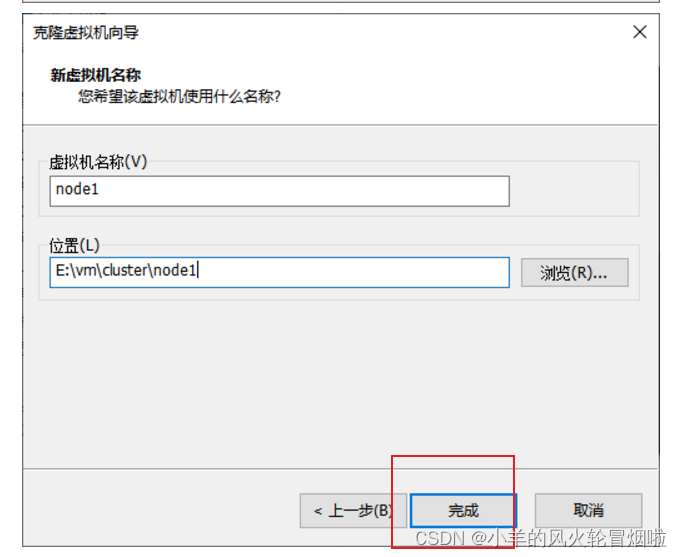
2.4?同样的操作克隆出:node2和node3

2.5?开启node1,修改主机名为node1,并修改固定ip为:192.168.88.131
# 修改主机名
hostnamectl set-hostname node1
# 修改IP地址
vim /etc/sysconfig/network-scripts/ifcfg-ens33
IPADDR="192.168.88.131"
# 重启网卡
systemctl stop network
systemctl start network
# 或者直接
systemctl restart network?2.6??同样的操作启动node2和node3,
修改node2主机名为node2,设置ip为192.168.88.132
修改node2主机名为node3,设置ip为192.168.88.133
2.7?配置FinalShell,配置连接到node1、node2、node3的连接
为了简单起见,建议配置root用户登录
准备主机名映射
1、在Windows系统中修改hosts文件,填入如下内容:
如果同学们使用MacOS系统,请:
-
sudo su -,切换到root
-
修改/etc/hosts文件
192.168.88.131 node1
192.168.88.132 node2
192.168.88.133 node32、在3台Linux的/etc/hosts文件中,填入如下内容(3台都要添加)
192.168.88.131 node1
192.168.88.132 node2
192.168.88.133 node3配置SSH免密登录
1、简介
SSH服务是一种用于远程登录的安全认证协议。
我们通过FinalShell远程连接到Linux,就是使用的SSH服务。
SSH服务支持:
-
通过账户+密码的认证方式来做用户认证
-
通过账户+秘钥文件的方式做用户认证
SSH可以让我们通过SSH命令,远程的登陆到其它的主机上,比如:
在node1执行:ssh root@node2,将以root用户登录node2服务器,输入密码即可成功登陆
或者ssh node2,将以当前用户直接登陆到node2服务器
2、SSH免密配置
后续安装的集群化软件,多数需要远程登录以及远程执行命令,我们可以简单起见,配置三台Linux服务器之间的免密码互相SSH登陆
-
在每一台机器都执行:
ssh-keygen -t rsa -b 4096,一路回车到底即可 -
在每一台机器都执行:
ssh-copy-id node1
ssh-copy-id node2
ssh-copy-id node3? ? ? 3.执行完毕后,node1、node2、node3之间将完成root用户之间的免密互通 ?
3、配置JDK环境
后续的大数据集群软件,多数是需要Java运行环境的,所以我们为每一台机器都配置JDK环境。
JDK配置参阅:Tomcat安装部署环节。
4、关闭防火墙和SELinux
集群化软件之间需要通过端口互相通讯,为了避免出现网络不通的问题,我们可以简单的在集群内部关闭防火墙。
在每一台机器都执行
systemctl stop firewalld
systemctl disable firewalldLinux有一个安全模块:SELinux,用以限制用户和程序的相关权限,来确保系统的安全稳定。
SELinux的配置同防火墙一样,非常复杂,课程中不多涉及,后续视情况可以出一章SELinux的配置课程。
在当前,我们只需要关闭SELinux功能,避免导致后面的软件运行出现问题即可,
在每一台机器都执行
vim /etc/sysconfig/selinux
# 将第七行,SELINUX=enforcing 改为
SELINUX=disabled
# 保存退出后,重启虚拟机即可,千万要注意disabled单词不要写错,不然无法启动系统5、添加快照
为了避免后续出现问题,在完成上述设置后,为每一台虚拟机都制作快照,留待使用。
6、补充命令 - scp
后续的安装部署操作,我们将会频繁的在多台服务器之间相互传输数据。
为了更加方面的互相传输,我们补充一个命令:scp
scp命令是cp命令的升级版,即:ssh cp,通过SSH协议完成文件的复制。
其主要的功能就是:在不同的Linux服务器之间,通过SSH协议互相传输文件。
只要知晓服务器的账户和密码(或密钥),即可通过SCP互传文件。
语法:
scp [-r] 参数1 参数2
- -r选项用于复制文件夹使用,如果复制文件夹,必须使用-r
- 参数1:本机路径 或 远程目标路径
- 参数2:远程目标路径 或 本机路径
如:
scp -r /export/server/jdk root@node2:/export/server/
将本机上的jdk文件夹, 以root的身份复制到node2的/export/server/内
同SSH登陆一样,账户名可以省略(使用本机当前的同名账户登陆)
如:
scp -r node2:/export/server/jdk /export/server/
将远程node2的jdk文件夹,复制到本机的/export/server/内
# scp命令的高级用法
cd /export/server
scp -r jdk node2:`pwd`/ # 将本机当前路径的jdk文件夹,复制到node2服务器的同名路径下
scp -r jdk node2:$PWD # 将本机当前路径的jdk文件夹,复制到node2服务器的同名路径下本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- [C#]winform部署yolov5-onnx模型
- 2023-年度总结
- NFS原理详解
- Unity is running with Administrator privileges, which is not supported
- go实现判断20000数据范围内哪些是素数(只能被1和它本身整除的数),采用多协程和管道实现
- 更新R版本到4.xxx
- 【NI-DAQmx入门】模拟输出再生模式
- 计算机组成原理-进位计数制(进制表示 进制转换 真值和机器树)
- 2023 PAT exam (Advanced level) in winter Dec.12nd
- vue使用Promise.all可以同时执行多个异步操作,,并将这些异步操作的结果一并返回