【深度学习】Anaconda3 + PyCharm 的环境配置 5:手把手带你运行 predict.py 文件,史上最全的问题解决记录
前言
文章性质:实操记录 💻
主要内容:主要记录了运行 predict.py 文件时遇到的错误以及相应的解决方案。
项目源码:GitHub - SZU-AdvTech-2022/213-Rethinking-Image-Restoration-for-Object-Detection
相关文档:睿智的目标检测 26 :Pytorch 搭建 yolo3 目标检测平台
冷知识+1:小伙伴们不经意的?点赞?👍🏻 与?收藏?? 可以让作者更有创作动力!?
?
目录
Q1:ImportError: cannot import name 'YOLO' from 'yolo'
Q2:OMP: Error #15: Initializing libiomp5md.dll, but...
Q3:FileNotFoundError: [Errno 2] No such file or directory...
Q1:ImportError: cannot import name 'YOLO' from 'yolo'
【遇到错误】ImportError: cannot import name 'YOLO' from 'yolo'
【错误原因】源代码链接中未提供项目根目录下应有的 yolo.py 文件!
【解决方法】我从?Bubbliiiing 的 GitHub 项目中拿来了 yolo.py 文件~我把代码放在了文章的最后!?
 ?
?
Q2:OMP: Error #15: Initializing libiomp5md.dll, but...
【遇到错误】OMP: Error #15: Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
【错误原因】初始化 libiomp5md.dll 文件时,发现 libiomp5md.dll 文件已经初始化。
【解决方法】在代码的合适位置处添加:
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE" ?
?
Q3:FileNotFoundError: [Errno 2] No such file or directory...
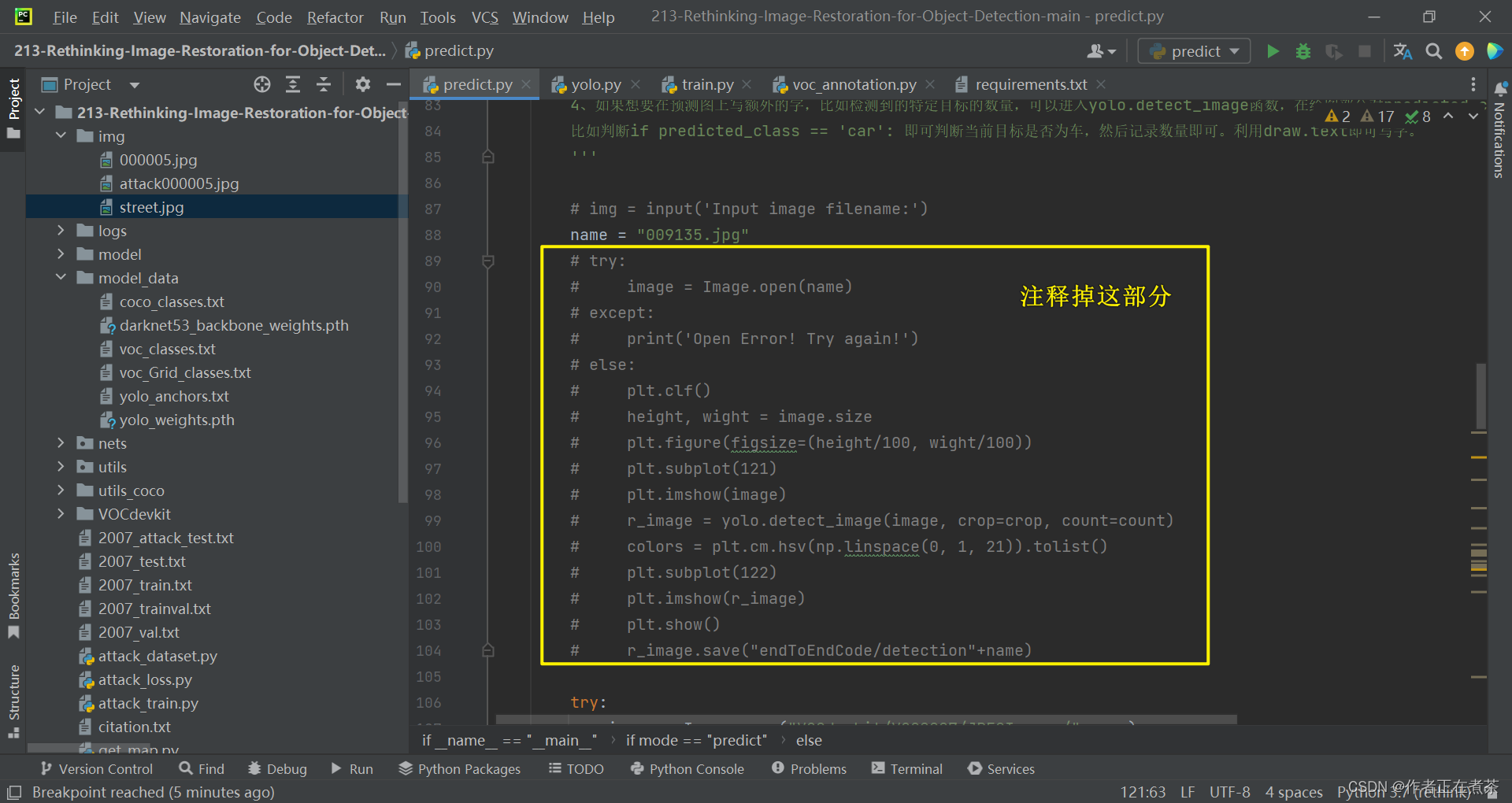
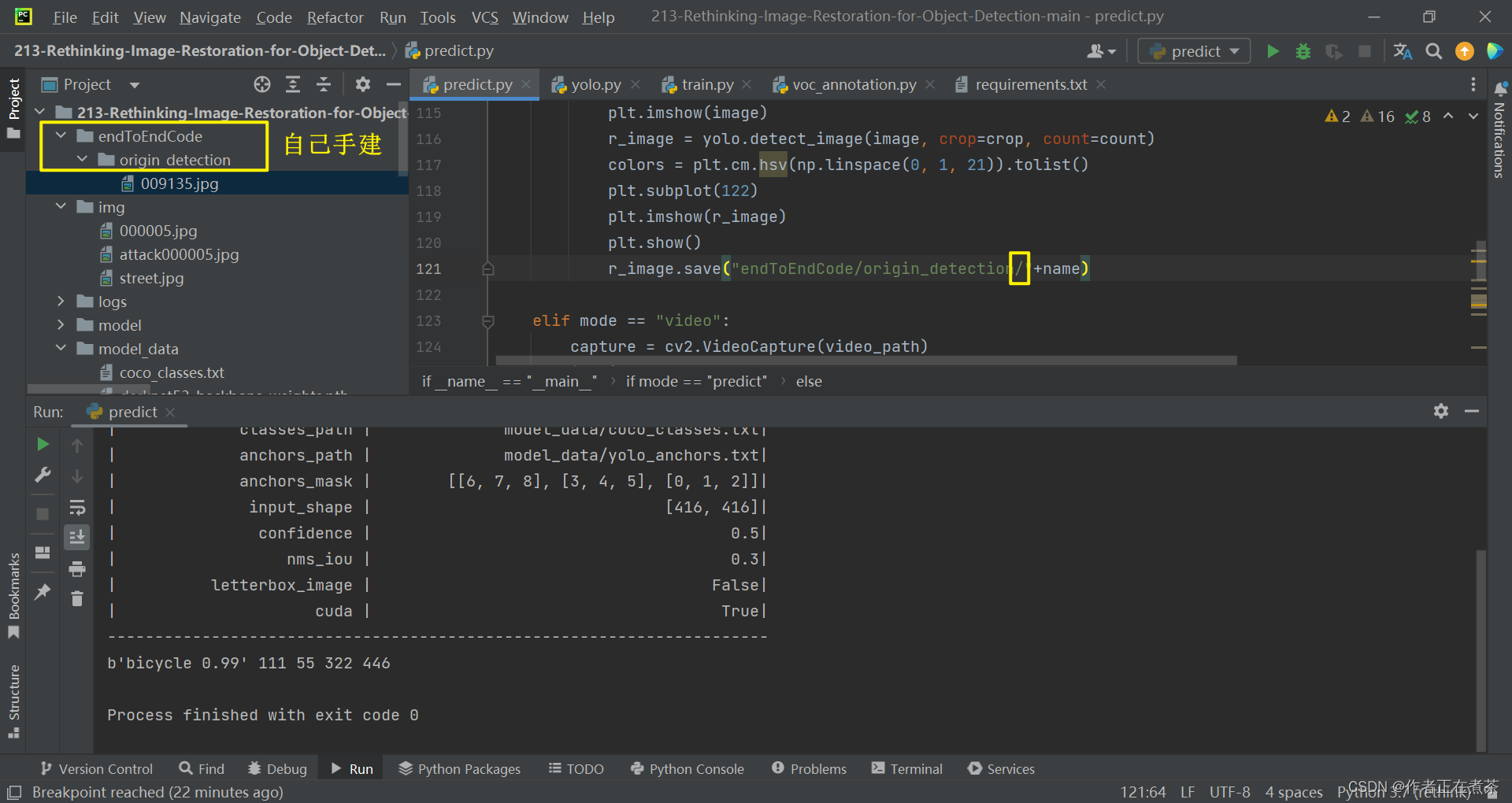
【遇到错误】FileNotFoundError: [Errno 2] No such file or directory:'endToEndCode/origin_detection009135.jpg'
【错误原因】路径拼接错误,应该是 origin_detection 文件夹下的 009135.jpg 文件,且找不到 endToEndCode/origin_detection 路径。
 ?
?
【解决方法】在项目的根目录下新建 endToEndCode 子目录,再在该目录下新建?origin_detection 文件夹。同时修改路径拼接语句,注意还需要注释掉部分内容,具体操作参考下面的截图。
 ?
?
 ?
?
 ?
?
【说明】如果上图中的 plt.clf () 没有注释掉,运行 predict.py 文件会弹出两个 Figure ,且 Figure1 空白,如下图所示:
 ?
?
Q4:No module named 'onnx'
【遇到错误】No module named 'onnx'
【解决方法】在 Terminal 终端执行?pip install onnx?命令,注意在指定的虚拟环境中执行!可用 activate 环境名 激活指定的虚拟环境。
pip install onnx ?
?

【说明】也可以如上图所示,直接在错误提示处 Install package onnx ~
附:yolo.py
import colorsys
import os
import time
import numpy as np
import torch
import torch.nn as nn
from PIL import ImageDraw, ImageFont
from nets.yolo import YoloBody
from utils.utils import (cvtColor, get_anchors, get_classes, preprocess_input,
resize_image, show_config)
from utils.utils_bbox import DecodeBox
'''
训练自己的数据集必看注释!
'''
class YOLO(object):
_defaults = {
# --------------------------------------------------------------------------#
# 使用自己训练好的模型进行预测一定要修改model_path和classes_path!
# model_path指向logs文件夹下的权值文件,classes_path指向model_data下的txt
#
# 训练好后logs文件夹下存在多个权值文件,选择验证集损失较低的即可。
# 验证集损失较低不代表mAP较高,仅代表该权值在验证集上泛化性能较好。
# 如果出现shape不匹配,同时要注意训练时的model_path和classes_path参数的修改
# --------------------------------------------------------------------------#
"model_path": 'model_data/yolo_weights.pth',
"classes_path": 'model_data/coco_classes.txt',
# ---------------------------------------------------------------------#
# anchors_path代表先验框对应的txt文件,一般不修改。
# anchors_mask用于帮助代码找到对应的先验框,一般不修改。
# ---------------------------------------------------------------------#
"anchors_path": 'model_data/yolo_anchors.txt',
"anchors_mask": [[6, 7, 8], [3, 4, 5], [0, 1, 2]],
# ---------------------------------------------------------------------#
# 输入图片的大小,必须为32的倍数。
# ---------------------------------------------------------------------#
"input_shape": [416, 416],
# ---------------------------------------------------------------------#
# 只有得分大于置信度的预测框会被保留下来
# ---------------------------------------------------------------------#
"confidence": 0.5,
# ---------------------------------------------------------------------#
# 非极大抑制所用到的nms_iou大小
# ---------------------------------------------------------------------#
"nms_iou": 0.3,
# ---------------------------------------------------------------------#
# 该变量用于控制是否使用letterbox_image对输入图像进行不失真的resize,
# 在多次测试后,发现关闭letterbox_image直接resize的效果更好
# ---------------------------------------------------------------------#
"letterbox_image": False,
# -------------------------------#
# 是否使用Cuda
# 没有GPU可以设置成False
# -------------------------------#
"cuda": True,
}
@classmethod
def get_defaults(cls, n):
if n in cls._defaults:
return cls._defaults[n]
else:
return "Unrecognized attribute name '" + n + "'"
# ---------------------------------------------------#
# 初始化YOLO
# ---------------------------------------------------#
def __init__(self, **kwargs):
self.__dict__.update(self._defaults)
for name, value in kwargs.items():
setattr(self, name, value)
self._defaults[name] = value
# ---------------------------------------------------#
# 获得种类和先验框的数量
# ---------------------------------------------------#
self.class_names, self.num_classes = get_classes(self.classes_path)
self.anchors, self.num_anchors = get_anchors(self.anchors_path)
self.bbox_util = DecodeBox(self.anchors, self.num_classes, (self.input_shape[0], self.input_shape[1]),
self.anchors_mask)
# ---------------------------------------------------#
# 画框设置不同的颜色
# ---------------------------------------------------#
hsv_tuples = [(x / self.num_classes, 1., 1.) for x in range(self.num_classes)]
self.colors = list(map(lambda x: colorsys.hsv_to_rgb(*x), hsv_tuples))
self.colors = list(map(lambda x: (int(x[0] * 255), int(x[1] * 255), int(x[2] * 255)), self.colors))
self.generate()
show_config(**self._defaults)
# ---------------------------------------------------#
# 生成模型
# ---------------------------------------------------#
def generate(self, onnx=False):
# ---------------------------------------------------#
# 建立yolov3模型,载入yolov3模型的权重
# ---------------------------------------------------#
self.net = YoloBody(self.anchors_mask, self.num_classes)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.net.load_state_dict(torch.load(self.model_path, map_location=device))
self.net = self.net.eval()
print('{} model, anchors, and classes loaded.'.format(self.model_path))
if not onnx:
if self.cuda:
self.net = nn.DataParallel(self.net)
self.net = self.net.cuda()
# ---------------------------------------------------#
# 检测图片
# ---------------------------------------------------#
def detect_image(self, image, crop=False, count=False):
image_shape = np.array(np.shape(image)[0:2])
# ---------------------------------------------------------#
# 在这里将图像转换成RGB图像,防止灰度图在预测时报错。
# 代码仅仅支持RGB图像的预测,所有其它类型的图像都会转化成RGB
# ---------------------------------------------------------#
image = cvtColor(image)
# ---------------------------------------------------------#
# 给图像增加灰条,实现不失真的resize
# 也可以直接resize进行识别
# ---------------------------------------------------------#
image_data = resize_image(image, (self.input_shape[1], self.input_shape[0]), self.letterbox_image)
# ---------------------------------------------------------#
# 添加上batch_size维度
# ---------------------------------------------------------#
image_data = np.expand_dims(np.transpose(preprocess_input(np.array(image_data, dtype='float32')), (2, 0, 1)), 0)
with torch.no_grad():
images = torch.from_numpy(image_data)
if self.cuda:
images = images.cuda()
# ---------------------------------------------------------#
# 将图像输入网络当中进行预测!
# ---------------------------------------------------------#
outputs = self.net(images)
outputs = self.bbox_util.decode_box(outputs)
# ---------------------------------------------------------#
# 将预测框进行堆叠,然后进行非极大抑制
# ---------------------------------------------------------#
results = self.bbox_util.non_max_suppression(torch.cat(outputs, 1), self.num_classes, self.input_shape,
image_shape, self.letterbox_image, conf_thres=self.confidence,
nms_thres=self.nms_iou)
if results[0] is None:
return image
top_label = np.array(results[0][:, 6], dtype='int32')
top_conf = results[0][:, 4] * results[0][:, 5]
top_boxes = results[0][:, :4]
# ---------------------------------------------------------#
# 设置字体与边框厚度
# ---------------------------------------------------------#
font = ImageFont.truetype(font='model_data/simhei.ttf',
size=np.floor(3e-2 * image.size[1] + 0.5).astype('int32'))
thickness = int(max((image.size[0] + image.size[1]) // np.mean(self.input_shape), 1))
# ---------------------------------------------------------#
# 计数
# ---------------------------------------------------------#
if count:
print("top_label:", top_label)
classes_nums = np.zeros([self.num_classes])
for i in range(self.num_classes):
num = np.sum(top_label == i)
if num > 0:
print(self.class_names[i], " : ", num)
classes_nums[i] = num
print("classes_nums:", classes_nums)
# ---------------------------------------------------------#
# 是否进行目标的裁剪
# ---------------------------------------------------------#
if crop:
for i, c in list(enumerate(top_label)):
top, left, bottom, right = top_boxes[i]
top = max(0, np.floor(top).astype('int32'))
left = max(0, np.floor(left).astype('int32'))
bottom = min(image.size[1], np.floor(bottom).astype('int32'))
right = min(image.size[0], np.floor(right).astype('int32'))
dir_save_path = "img_crop"
if not os.path.exists(dir_save_path):
os.makedirs(dir_save_path)
crop_image = image.crop([left, top, right, bottom])
crop_image.save(os.path.join(dir_save_path, "crop_" + str(i) + ".png"), quality=95, subsampling=0)
print("save crop_" + str(i) + ".png to " + dir_save_path)
# ---------------------------------------------------------#
# 图像绘制
# ---------------------------------------------------------#
for i, c in list(enumerate(top_label)):
predicted_class = self.class_names[int(c)]
box = top_boxes[i]
score = top_conf[i]
top, left, bottom, right = box
top = max(0, np.floor(top).astype('int32'))
left = max(0, np.floor(left).astype('int32'))
bottom = min(image.size[1], np.floor(bottom).astype('int32'))
right = min(image.size[0], np.floor(right).astype('int32'))
label = '{} {:.2f}'.format(predicted_class, score)
draw = ImageDraw.Draw(image)
label_size = draw.textsize(label, font)
label = label.encode('utf-8')
print(label, top, left, bottom, right)
if top - label_size[1] >= 0:
text_origin = np.array([left, top - label_size[1]])
else:
text_origin = np.array([left, top + 1])
for i in range(thickness):
draw.rectangle([left + i, top + i, right - i, bottom - i], outline=self.colors[c])
draw.rectangle([tuple(text_origin), tuple(text_origin + label_size)], fill=self.colors[c])
draw.text(text_origin, str(label, 'UTF-8'), fill=(0, 0, 0), font=font)
del draw
return image
def get_FPS(self, image, test_interval):
image_shape = np.array(np.shape(image)[0:2])
# ---------------------------------------------------------#
# 在这里将图像转换成RGB图像,防止灰度图在预测时报错。
# 代码仅仅支持RGB图像的预测,所有其它类型的图像都会转化成RGB
# ---------------------------------------------------------#
image = cvtColor(image)
# ---------------------------------------------------------#
# 给图像增加灰条,实现不失真的resize
# 也可以直接resize进行识别
# ---------------------------------------------------------#
image_data = resize_image(image, (self.input_shape[1], self.input_shape[0]), self.letterbox_image)
# ---------------------------------------------------------#
# 添加上batch_size维度
# ---------------------------------------------------------#
image_data = np.expand_dims(np.transpose(preprocess_input(np.array(image_data, dtype='float32')), (2, 0, 1)), 0)
with torch.no_grad():
images = torch.from_numpy(image_data)
if self.cuda:
images = images.cuda()
# ---------------------------------------------------------#
# 将图像输入网络当中进行预测!
# ---------------------------------------------------------#
outputs = self.net(images)
outputs = self.bbox_util.decode_box(outputs)
# ---------------------------------------------------------#
# 将预测框进行堆叠,然后进行非极大抑制
# ---------------------------------------------------------#
results = self.bbox_util.non_max_suppression(torch.cat(outputs, 1), self.num_classes, self.input_shape,
image_shape, self.letterbox_image, conf_thres=self.confidence,
nms_thres=self.nms_iou)
t1 = time.time()
for _ in range(test_interval):
with torch.no_grad():
# ---------------------------------------------------------#
# 将图像输入网络当中进行预测!
# ---------------------------------------------------------#
outputs = self.net(images)
outputs = self.bbox_util.decode_box(outputs)
# ---------------------------------------------------------#
# 将预测框进行堆叠,然后进行非极大抑制
# ---------------------------------------------------------#
results = self.bbox_util.non_max_suppression(torch.cat(outputs, 1), self.num_classes, self.input_shape,
image_shape, self.letterbox_image,
conf_thres=self.confidence, nms_thres=self.nms_iou)
t2 = time.time()
tact_time = (t2 - t1) / test_interval
return tact_time
def detect_heatmap(self, image, heatmap_save_path):
import cv2
import matplotlib.pyplot as plt
def sigmoid(x):
y = 1.0 / (1.0 + np.exp(-x))
return y
# ---------------------------------------------------------#
# 在这里将图像转换成RGB图像,防止灰度图在预测时报错。
# 代码仅仅支持RGB图像的预测,所有其它类型的图像都会转化成RGB
# ---------------------------------------------------------#
image = cvtColor(image)
# ---------------------------------------------------------#
# 给图像增加灰条,实现不失真的resize
# 也可以直接resize进行识别
# ---------------------------------------------------------#
image_data = resize_image(image, (self.input_shape[1], self.input_shape[0]), self.letterbox_image)
# ---------------------------------------------------------#
# 添加上batch_size维度
# ---------------------------------------------------------#
image_data = np.expand_dims(np.transpose(preprocess_input(np.array(image_data, dtype='float32')), (2, 0, 1)), 0)
with torch.no_grad():
images = torch.from_numpy(image_data)
if self.cuda:
images = images.cuda()
# ---------------------------------------------------------#
# 将图像输入网络当中进行预测!
# ---------------------------------------------------------#
outputs = self.net(images)
plt.imshow(image, alpha=1)
plt.axis('off')
mask = np.zeros((image.size[1], image.size[0]))
for sub_output in outputs:
sub_output = sub_output.cpu().numpy()
b, c, h, w = np.shape(sub_output)
sub_output = np.transpose(np.reshape(sub_output, [b, 3, -1, h, w]), [0, 3, 4, 1, 2])[0]
score = np.max(sigmoid(sub_output[..., 4]), -1)
score = cv2.resize(score, (image.size[0], image.size[1]))
normed_score = (score * 255).astype('uint8')
mask = np.maximum(mask, normed_score)
plt.imshow(mask, alpha=0.5, interpolation='nearest', cmap="jet")
plt.axis('off')
plt.subplots_adjust(top=1, bottom=0, right=1, left=0, hspace=0, wspace=0)
plt.margins(0, 0)
plt.savefig(heatmap_save_path, dpi=200, bbox_inches='tight', pad_inches=-0.1)
print("Save to the " + heatmap_save_path)
plt.show()
def convert_to_onnx(self, simplify, model_path):
import onnx
self.generate(onnx=True)
im = torch.zeros(1, 3, *self.input_shape).to('cpu') # image size(1, 3, 512, 512) BCHW
input_layer_names = ["images"]
output_layer_names = ["output"]
# Export the model
print(f'Starting export with onnx {onnx.__version__}.')
torch.onnx.export(self.net,
im,
f=model_path,
verbose=False,
opset_version=12,
training=torch.onnx.TrainingMode.EVAL,
do_constant_folding=True,
input_names=input_layer_names,
output_names=output_layer_names,
dynamic_axes=None)
# Checks
model_onnx = onnx.load(model_path) # load onnx model
onnx.checker.check_model(model_onnx) # check onnx model
# Simplify onnx
if simplify:
import onnxsim
print(f'Simplifying with onnx-simplifier {onnxsim.__version__}.')
model_onnx, check = onnxsim.simplify(
model_onnx,
dynamic_input_shape=False,
input_shapes=None)
assert check, 'assert check failed'
onnx.save(model_onnx, model_path)
print('Onnx model save as {}'.format(model_path))
def get_map_txt(self, image_id, image, class_names, map_out_path):
f = open(os.path.join(map_out_path, "detection-results/" + image_id + ".txt"), "w")
image_shape = np.array(np.shape(image)[0:2])
# ---------------------------------------------------------#
# 在这里将图像转换成RGB图像,防止灰度图在预测时报错。
# 代码仅仅支持RGB图像的预测,所有其它类型的图像都会转化成RGB
# ---------------------------------------------------------#
image = cvtColor(image)
# ---------------------------------------------------------#
# 给图像增加灰条,实现不失真的resize
# 也可以直接resize进行识别
# ---------------------------------------------------------#
image_data = resize_image(image, (self.input_shape[1], self.input_shape[0]), self.letterbox_image)
# ---------------------------------------------------------#
# 添加上batch_size维度
# ---------------------------------------------------------#
image_data = np.expand_dims(np.transpose(preprocess_input(np.array(image_data, dtype='float32')), (2, 0, 1)), 0)
with torch.no_grad():
images = torch.from_numpy(image_data)
if self.cuda:
images = images.cuda()
# ---------------------------------------------------------#
# 将图像输入网络当中进行预测!
# ---------------------------------------------------------#
outputs = self.net(images)
outputs = self.bbox_util.decode_box(outputs)
# ---------------------------------------------------------#
# 将预测框进行堆叠,然后进行非极大抑制
# ---------------------------------------------------------#
results = self.bbox_util.non_max_suppression(torch.cat(outputs, 1), self.num_classes, self.input_shape,
image_shape, self.letterbox_image, conf_thres=self.confidence, nms_thres=self.nms_iou)
if results[0] is None:
return
top_label = np.array(results[0][:, 6], dtype='int32')
top_conf = results[0][:, 4] * results[0][:, 5]
top_boxes = results[0][:, :4]
for i, c in list(enumerate(top_label)):
predicted_class = self.class_names[int(c)]
box = top_boxes[i]
score = str(top_conf[i])
top, left, bottom, right = box
if predicted_class not in class_names:
continue
f.write("%s %s %s %s %s %s\n" % (predicted_class, score[:6], str(int(left)), str(int(top)), str(int(right)), str(int(bottom))))
f.close()
return
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 鸿蒙(HarmonyOS)项目方舟框架(ArkUI)控件的部分公共属性和事件
- 安防视频监控系统EasyCVR实现H.265视频在3秒内起播的注意事项
- 开源时代:极狐GitLab如何保证软件供应链安全
- python使用openai库0.x版本升级为1.x版本代码所需改动
- 如何自己搭建个人网站(自建)?
- react父组件props变化的时候子组件怎么监听?
- 【C语言】操作符详解(四):结构成员访问操作符
- GoLang:gRPC协议
- HAProxy
- Windows10升级到Windows11 Office未激活解决方案