基础+常用的数据结构
基础
java基础
JDK 和 JRE
JDK,它是功能齐全的 Java SDK,是提供给开发者使用,能够创建和编译 Java 程序的开发套件。它包含了 JRE,同时还包含了编译 java 源码的编译器 javac 以及一些其他工具比如 javadoc(文档注释工具)、jdb(调试器)、jconsole(基于 JMX 的可视化监控?具)、javap(反编译工具)等等。
JRE 是 Java 运行时环境。
什么是字节码
在 Java 中,JVM 可以理解的代码就叫做字节码即扩展名为 .class 的文件
为什么说 Java 语言“编译与解释并存”?
因为 Java 程序要经过先编译,后解释两个步骤,由 Java 编写的程序需要先经过编译步骤,生成字节码(.class 文件),这种字节码必须由 Java 解释器来解释执行。
基本数据类型
Java 中有 8 种基本数据类型,分别为:
6 种数字类型:
4 种整数型:byte、short、int、long
2 种浮点型:float、double
1 种字符类型:char
1 种布尔型:boolean
接口和抽象类有什么共同点和区别?
共同点是
- 都不能被实例化。
- 都可以包含抽象方法。
区别: - 接口主要用于对类的行为进行约束,你实现了某个接口就具有了对应的行为。抽象类主要用于代码复用,强调的是所属关系。
- 一个类只能继承一个类,但是可以实现多个接口
- 接口中的成员变量只能是 public static final 类型的,不能被修改且必须有初始值,而抽象类的成员变量默认 default可在子类中被重新定义,也可被重新赋值
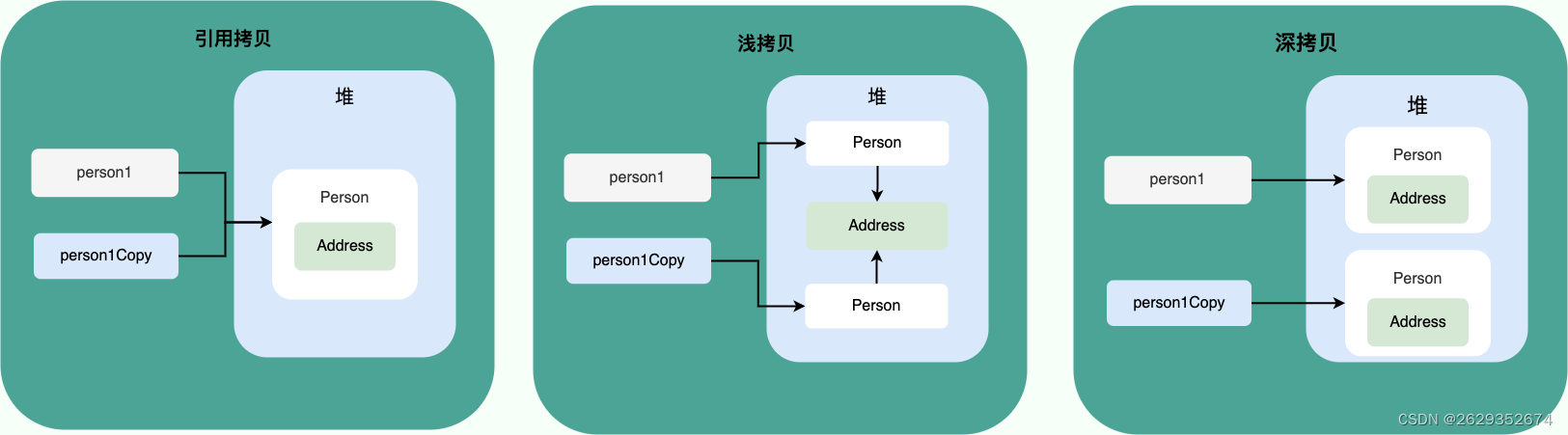
深拷贝和浅拷贝区别了解吗?什么是引用拷贝?
- 浅拷贝:浅拷贝会在堆上创建一个新的对象(区别于引用拷贝的一点),不过,如果原对象内部的属性是引用类型的话,浅拷贝会直接复制内部对象的引用地址,也就是说拷贝对象和原对象共用同一个内部对象。
- 深拷贝:深拷贝会完全复制整个对象,包括这个对象所包含的内部对象。
为什么重写 equals() 时必须重写 hashCode() 方法?
因为两个相等的对象的 hashCode 值必须是相等。也就是说如果 equals 方法判断两个对象是相等的,那这两个对象的 hashCode 值也要相等。
如果重写 equals() 时没有重写 hashCode() 方法的话就可能会导致 equals 方法判断是相等的两个对象,hashCode 值却不相等。
String、StringBuffer、StringBuilder 的区别?
- 操作少量的数据: 适用 String
- 单线程操作字符串缓冲区下操作大量数据: 适用 StringBuilder
- 多线程操作字符串缓冲区下操作大量数据: 适用 StringBuffer
异常使用有哪些需要注意的地方?
抛出的异常信息一定要有意义。建议抛出更加具体的异常比如字符串转换为数字格式错误的时候应该抛出NumberFormatException而不是其父类IllegalArgumentException。使用日志打印异常之后就不要再抛出异常了(两者不要同时存在一段代码逻辑中)。
项目中哪里用到了泛型
- 自定义接口通用返回结果 CommonResult 通过参数 T 可根据具体的返回类型动态指定结果的数据类型
- 定义 Excel 处理类 ExcelUtil 用于动态指定 Excel 导出的数据类型
- 构建集合工具类(参考 Collections 中的 sort, binarySearch 方法)。
何谓注解?
Annotation (注解) 是 Java5 开始引入的新特性,可以看作是一种特殊的注释,主要用于修饰类、方法或者变量,提供某些信息供程序在编译或者运行时使用。
注解本质是一个继承了Annotation 的特殊接口
注解的解析方法有哪几种?
注解只有被解析之后才会生效,常见的解析方法有两种
- 编译期直接扫描:编译器在编译 Java 代码的时候扫描对应的注解并处理,比如某个方法使用@Override 注解,编译器在编译的时候就会检测当前的方法是否重写了父类对应的方法。
- 运行期通过反射处理:像框架中自带的注解(比如 Spring 框架的 @Value、@Component)都是通过反射来进行处理的。
序列化和反序列化
序列化:将数据结构或对象转换成二进制字节流的过程
反序列化:将在序列化过程中所生成的二进制字节流转换成数据结构或者对象的过程
OSI 七层协议模型中的应用层、表示层和会话层对应的都是 TCP/IP 四层模型中的应用层,所以序列化协议属于 TCP/IP 协议应用层的一部分。
对于不想进行序列化的变量,使用 transient 关键字修饰。
java 集合
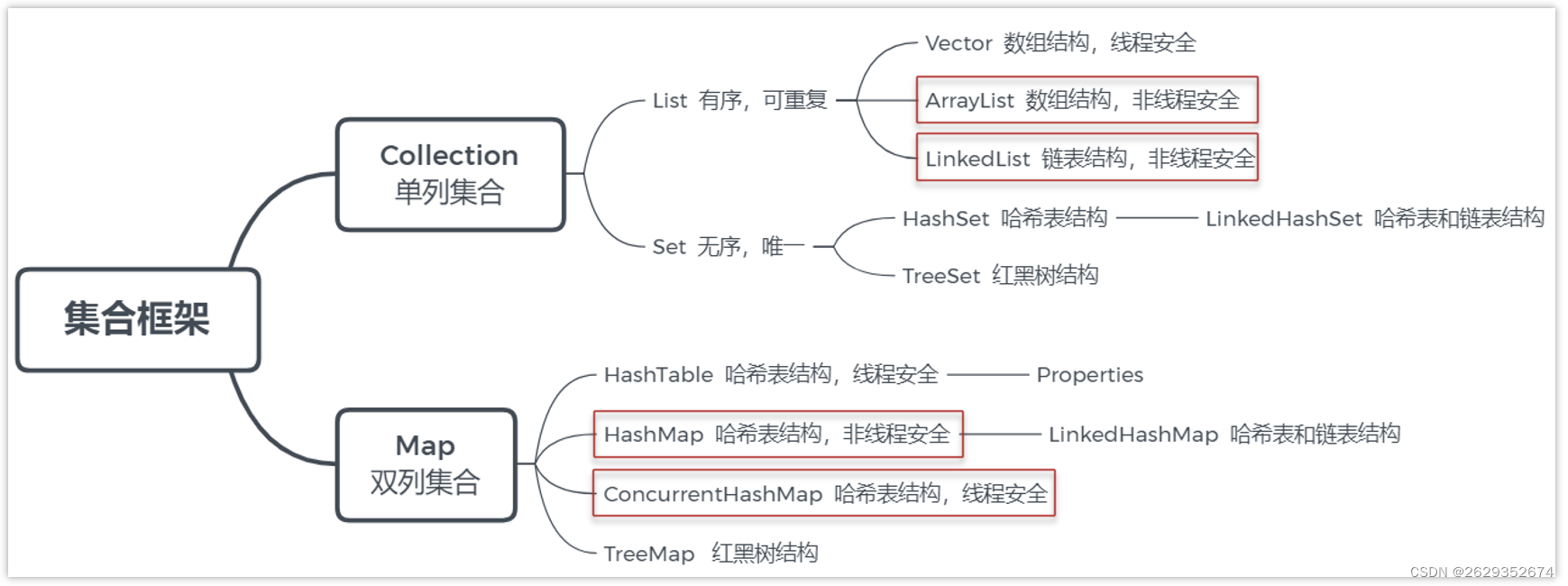
- ArrayList底层实现是数组
- LinkedList底层实现是双向链表
- HashMap的底层实现使用了众多数据结构,包含了数组、链表、散列表、红黑树等
List相关面试题
ArrayList源码分析
- 底层数据结构
ArrayList底层是用动态的数组实现的
- 初始容量
ArrayList初始容量为0,当第一次添加数据的时候才会初始化容量为10
- 扩容逻辑
ArrayList在进行扩容的时候是原来容量的1.5倍,每次扩容都需要拷贝数组
如何实现数组和List之间的转换
- 数组转List ,使用JDK中java.util.Arrays工具类的asList方法
- List转数组,使用List的toArray方法。无参toArray方法返回 Object数组,传入初始化长度的数组对象,返回该对象数组
ArrayList和LinkedList的区别是什么?
-
底层数据结构
-
ArrayList 是动态数组的数据结构实现
-
LinkedList 是双向链表的数据结构实现
-
-
操作数据效率
- ArrayList按照下标查询的时间复杂度O(1)【内存是连续的,根据寻址公式】, LinkedList不支持下标查询
- 查找(未知索引): ArrayList需要遍历,链表也需要链表,时间复杂度都是O(n)
- 新增和删除
- ArrayList尾部插入和删除,时间复杂度是O(1);其他部分增删需要挪动数组,时间复杂度是O(n)
- LinkedList头尾节点增删时间复杂度是O(1),其他都需要遍历链表,时间复杂度是O(n)
-
内存空间占用
-
ArrayList底层是数组,内存连续,节省内存
-
LinkedList 是双向链表需要存储数据,和两个指针,更占用内存
-
-
线程安全
- ArrayList和LinkedList都不是线程安全的
- 如果需要保证线程安全,有两种方案:
- 在方法内使用,局部变量则是线程安全的
- 使用线程安全的ArrayList和LinkedList
HashMap相关
二叉搜索树概述
二叉查找树要求,在树中的任意一个节点,其左子树中的每个节点的值,都要小于这个节点的值,而右子树节点的值都大于这个节点的值
红黑树(Red Black Tree):也是一种自平衡的二叉搜索树(BST),之前叫做平衡二叉B树(Symmetric Binary B-Tree)
红黑树的特质
性质1:节点要么是红色,要么是黑色
性质2:根节点是黑色
性质3:叶子节点都是黑色的空节点
性质4:红黑树中红色节点的子节点都是黑色
性质5:从任一节点到叶子节点的所有路径都包含相同数目的黑色节点
散列表
散列表(Hash Table)概述
散列表(Hash Table)又名哈希表/Hash表,是根据键(Key)直接访问在内存存储位置值(Value)的数据结构,它是由数组演化而来的,利用了数组支持按照下标进行随机访问数据的特性
HashMap的实现原理
HashMap的数据结构: 底层使用hash表数据结构,即数组和链表或红黑树
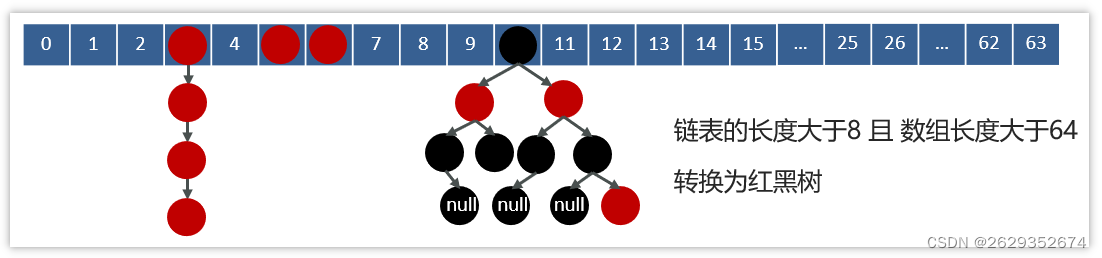
-
JDK1.8之前采用的是拉链法。拉链法:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
-
jdk1.8在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8) 时并且数组长度达到64时,将链表转化为红黑树,以减少搜索时间。扩容 resize( ) 时,红黑树拆分成的树的结点数小于等于临界值6个,则退化成链表
HashMap的put方法的具体流程
-
HashMap是懒惰加载,在创建对象时并没有初始化数组
-
在无参的构造函数中,设置了默认的加载因子是0.75
1.判断键值对数组table是否为空或为null,否则执行resize()进行扩容(初始化)
2.根据键值key计算hash值得到数组索引
3.判断table[i]==null,条件成立,直接新建节点添加
4.如果table[i]==null ,不成立
判断table[i]的首个元素是否和key一样,如果相同直接覆盖value
…
5.插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold(数组长度*0.75),如果超过,进行扩容。
HashMap的扩容机制
-
在添加元素或初始化的时候需要调用resize方法进行扩容,第一次添加数据初始化数组长度为16,以后每次每次扩容都是达到了扩容阈值(数组长度 * 0.75)
-
每次扩容的时候,都是扩容之前容量的2倍;
-
扩容之后,会新创建一个数组,需要把老数组中的数据挪动到新的数组中
为何HashMap的数组长度一定是2的次幂?
-
计算索引时效率更高:如果是 2 的 n 次幂可以使用位与运算代替取模
-
扩容时重新计算索引效率更高: hash & oldCap == 0 的元素留在原来位置 ,否则新位置 = 旧位置 + oldCap
hashMap的寻址算法
获取key的hashCode值,然后右移16位 异或运算 原来的hashCode值,主要作用就是使原来的hash值更加均匀,减少hash冲突。
(n-1)&hash : 得到数组中的索引,代替取模,性能更好,数组长度必须是2的n次幂
HashSet与HashMap的区别
(1)HashSet实现了Set接口, 仅存储对象; HashMap实现了 Map接口, 存储的是键值对.
(2)HashSet底层其实是用HashMap实现存储的, HashSet封装了一系列HashMap的方法. 依靠HashMap来存储元素值,(利用hashMap的key键进行存储), 而value值默认为Object对象. 所以HashSet也不允许出现重复值, 判断标准和HashMap判断标准相同, 两个元素的hashCode相等并且通过equals()方法返回true.
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【ARM 嵌入式 编译系列 2.3 -- GCC 编译参数学习 -Wa,-mimplicit-it=thumb 使用介绍】
- langchain学习记录(1)
- 使用k8s 配置 RollingUpdate 滚动更新实现应用的灰度发布
- Linux6.0、IO基础前置储备知识
- 19 v-for遍历数字
- CRM系统对中小企业有哪些好处?为什么中小企业要用CRM?
- 专业数据中台哪个好?亿发数字化运营平台解决方案,助力大中型企业腾飞
- Unity3D对TXT文件的操作
- 产品Axure的安装以及组件介绍
- 【Spring】—— bean如何实例化(四种方式)?