哈夫曼算法详细讲解(算法+源码)
博主介绍:?全网粉丝喜爱+、前后端领域优质创作者、本质互联网精神、坚持优质作品共享、掘金/腾讯云/阿里云等平台优质作者、擅长前后端项目开发和毕业项目实战?有需要可以联系作者我哦!
🍅文末获取源码联系🍅
👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟
?
目录
一、哈夫曼算法
哈夫曼编码是一种可变字长编码(Variable Length Coding)的一种方法,通过根据不同字符出现的频率来构建一颗具有最小编码长度的二叉树。该树的构建和遍历规则使得出现频率高的字符获得较短的编码,而出现频率低的字符获得较长的编码,从而达到对数据进行高效压缩的目的。
以下是哈夫曼编码的基本步骤:
1. 统计字符频率:遍历输入的字符流,统计每个字符出现的频率。
2. 构建哈夫曼树:?将每个字符及其频率作为叶子节点,构建一颗二叉树。在每一步中,选择两个最小频率的节点合并,直到只剩下一个根节点。
3. 生成编码:*通过遍历哈夫曼树,从根节点到每个叶子节点的路径上赋予0或1的编码。叶子节点上的编码即为对应字符的哈夫曼编码。
4. 生成编码表:?将每个字符及其对应的哈夫曼编码存储在一个编码表中,用于编码和解码。
5. 数据压缩:*使用生成的哈夫曼编码对原始数据进行编码,从而实现数据的压缩。
6. 数据解压:?利用编码表对压缩后的数据进行解码,还原为原始数据。
哈夫曼编码的优点在于对频率较高的字符进行了有效的压缩,使得整体的编码长度较短,从而节省了存储空间。这使得哈夫曼编码在数据传输和存储中得到广泛应用,特别是在无损数据压缩领域。
二、哈夫曼算法(完整C语言算法)
#include<stdio.h>
#include<malloc.h>
#include <iostream>
//定义初始化
#define Max 20
#define MaxValue 1000
using namespace std;
typedef struct huffNode
{
char ch;
int weight; //赋以权重
int lChild; //左孩子
int rChild; //右孩子
int parent; //父节点
char hCode[Max]; //记录哈夫曼编码
}huffman;
void init(huffman *huffmanTree,int *w,char *z,int n)
{
int i;
//for(i=0;i<2*n-1;i++)
// huffmanTree[i]=(huffman *)malloc(sizeof(huffman));
for(i=0;i<2*n-1;i++)
{
huffmanTree[i].ch=z[i];
huffmanTree[i].weight=w[i];
huffmanTree[i].parent=-1;
huffmanTree[i].lChild=-1;
huffmanTree[i].rChild=-1;
}
}
void setHuffmanTree(huffman *huffmanTree,int n)
{
int m,m1,m2,x1,x2,i,j;
m=2*n-1;
for(i=n;i<m;++i)
{
m1=m2=MaxValue;
x1=x2=0;
for(j=0;j<i;++j)
{
if(huffmanTree[j].parent==-1&&huffmanTree[j].weight<m1)
{
m2=m1;x2=x1;m1=huffmanTree[j].weight;x1=j;
}
else if (huffmanTree[j].parent==-1&&huffmanTree[j].weight<m2)
{ m2=huffmanTree[j].weight;x2=j;
}
}
huffmanTree[x1].parent=i;
huffmanTree[x2].parent=i;
huffmanTree[i].lChild=x1;
huffmanTree[i].rChild=x2;
huffmanTree[i].weight=m1+m2;
}
}
void huffmanTreeCode(huffman *huffmanTree,int n)
{
char hc[Max];
int hcLen;
int i,j,k,parent,p;
for(i=0;i<n;i++)
{
hcLen=0;
parent=huffmanTree[i].parent;//待编码字符的双亲结点下标
p=i;
while(parent!=-1)//未到达根结点
{
if(huffmanTree[parent].lChild==p)//是左孩子
hc[hcLen]='0',hcLen++;
else if(huffmanTree[parent].rChild==p)//是右孩子
hc[hcLen]='1',hcLen++;
p=parent;
parent=huffmanTree[parent].parent;//继续向根结点查找
}
for(j=0,k=hcLen-1;j<hcLen;j++,k--)//将编码写入相应字符数组
huffmanTree[i].hCode[j]=hc[k];
huffmanTree[i].hCode[j]='\0';//加上字符串结束符
}
return;
}
int main()
{
int n,i;
char z,*Z;
int w,W[Max];
huffman huffmanTree[Max];
printf("请输入叶子个数:\n");
scanf("%d",&n);
//W=(int *)malloc(n*sizeof(int));
Z=(char *)malloc(n*sizeof(char));
printf("请输入%d个字符和权值。\n",n);
for(i=0;i<n;i++)
{
printf("请输入第%d个字符:\n",i+1);
//scanf("%c",&z);
cin>>z;
Z[i]=z;
printf("请输入第%d个字符的权:\n",i+1);
//scanf("%d",&w);
cin>>w;
W[i]=w;
}
init(huffmanTree,W,Z,n);
setHuffmanTree(huffmanTree,n);
huffmanTreeCode(huffmanTree,n);
for(i=0;i<n;i++)
{
printf("%c:%s\n",huffmanTree[i].ch,huffmanTree[i].hCode);
}
return 0;
}
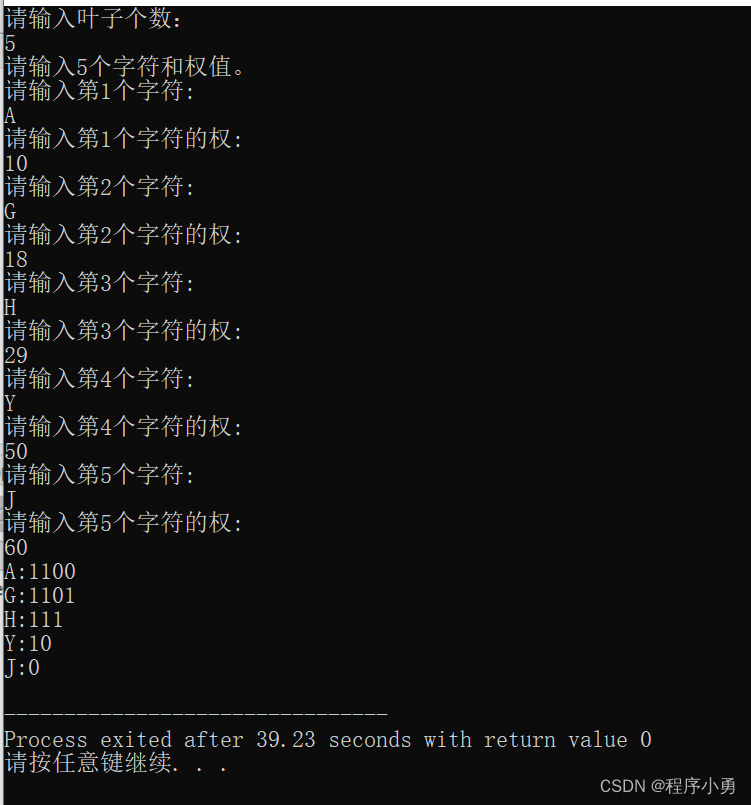
代码执行结果:
三、算法优缺点总结
优点:
? ?高效性:优秀的算法能够在较短的时间内解决问题,提高计算效率。
? ?可读性:?一些算法设计得清晰简洁,易于理解和阅读。
? ?稳定性:一些算法在不同数据情况下表现稳定,对输入变化不敏感。
? ?可靠性: 经过验证和测试的算法能够产生正确的结果。
缺点:
? ?资源占用:某些算法可能对计算资源(时间和空间)要求较高。
? ?问题依赖性:有些算法在处理特定问题时表现出色,但对其他问题可能不适用。
算法的应用方面:
1. 排序算法
?优点:高效地对数据进行排序,提高检索速度。
应用: 数据库检索、搜索引擎、数据分析。
?2.搜索算法
优点:快速定位目标数据。
应用:数据库查询、图像处理、人工智能搜索。
?3. 图算法:
? ?优点:解决图相关的问题,如路径查找、最短路径等。
? ?应用:网络路由、社交网络分析、城市规划。
4. 动态规划:
? ?优点:?解决最优化问题,避免重复计算。
? ?应用:背包问题、最短路径问题、游戏策略。
?5. 哈希算法
? ?优点:快速查找、插入和删除。
? ?应用:数据库索引、密码学、数据缓存。
6. 贪心算法:
? ?优点:?简单、高效,通常用于最优化问题。
? ?应用:调度问题、最小生成树、任务分配。
大家点赞、收藏、关注、评论啦 !
谢谢哦!如果不懂,欢迎大家下方讨论学习哦。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!