LightGBM原理和调参
背景知识
LightGBM(Light Gradient Boosting Machine)是一个实现GBDT算法的框架,具有支持高效率的并行训练、更快的训练速度、更低的内存消耗、更好的准确率、支持分布式可以处理海量数据等优点。
普通的GBDT算法不支持用mini-batch的方式训练,在每一次迭代的时候,都需要多次遍历整个训练数据。这样如果把整个训练数据装进内存则会限制训练集的大小,如果不装进内存,反复的读写数据又会大量消耗时间,特别不适合工业级海量数据的应用。LGBM的提出就是为了解决这些问题。
XGBoost
在LGBM提出之前,应用最广泛的GBDT工具就是XGBoost了,它是基于预排序的决策树算法。这种构建决策树的算法基本思想是:
- 首先,对所有特征都按特征的数值进行预排序;
- 其次,在遍历分割点的时候用O(#data)的代价找到一个特征上的最佳分割点;
- 最后,在找到一个特征的最佳分割点后,将数据分裂成左右子节点。
这样预排序算法的优点是能精确地找到分割点,但是缺点也很明显:
- 空间消耗大。这样的算法需要保存数据的特征值,还保存了特征排序的结果(例如,为了后续快速的计算分割点,保存了排序后的索引),这就需要消耗训练数据两倍的内存。
- 时间开销大。在遍历每一个分割点的时候,都需要进行分裂增益的计算,消耗的代价大。
- 对cache优化不友好。在预排序后,特征对梯度的访问是一种随机访问,并且不同的特征访问的顺序不一样,无法对cache进行优化。同时,在每一层生成树的时候 ,需要随机访问一个行索引到叶子索引的数组,并且不同特征访问的顺序也不一样,也会造成较大的cache miss。
LGBM的优化
为了弥补XGBoost的缺陷,并且能够在不损害准确率的条件下加快GBDT模型的训练速度,LGBM在传统的GBDT算法上进行了如下优化:
- 基于Histogram的决策树算法。
- 单边梯度采样(Gradient-based One-side Sampling, GOSS):使用GOSS可以减少大量只具有小梯度的数据实例,这样在计算信息增益的时候只利用剩下的具有高梯度的数据就可以了,相比XGBoost遍历所有特征节省了不少时间和空间上的开销。
- 互斥特征捆绑(Exclusive Feature Bundling, EFB):使用EFB可以将许多互斥的特征绑定为一个特征,这样达到了降维的目的。
- 带深度限制的Leaf-wise的叶子生长策略:大多数GBDT工具使用低效的按层生长(level-wise)的决策树生长策略,因为它不加区分的对待同一层叶子,带来了很多没必要的开销,实际上很多叶子的分裂增益较低,没必要进行搜索和分裂。LGBM使用了带有深度限制的按叶子生长(leaf-wise)算法。
- 直接支持类别特征(Categorical Feature)。
- 支持高效并行。
- Cache命中率优化。
LGBM基本原理
LGBM是基于Histogram的决策树算法。直方图算法的基本思想是:先将连续的浮点特征值离散成K个整数,同时构造一个宽度为k的直方图。在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量,当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。
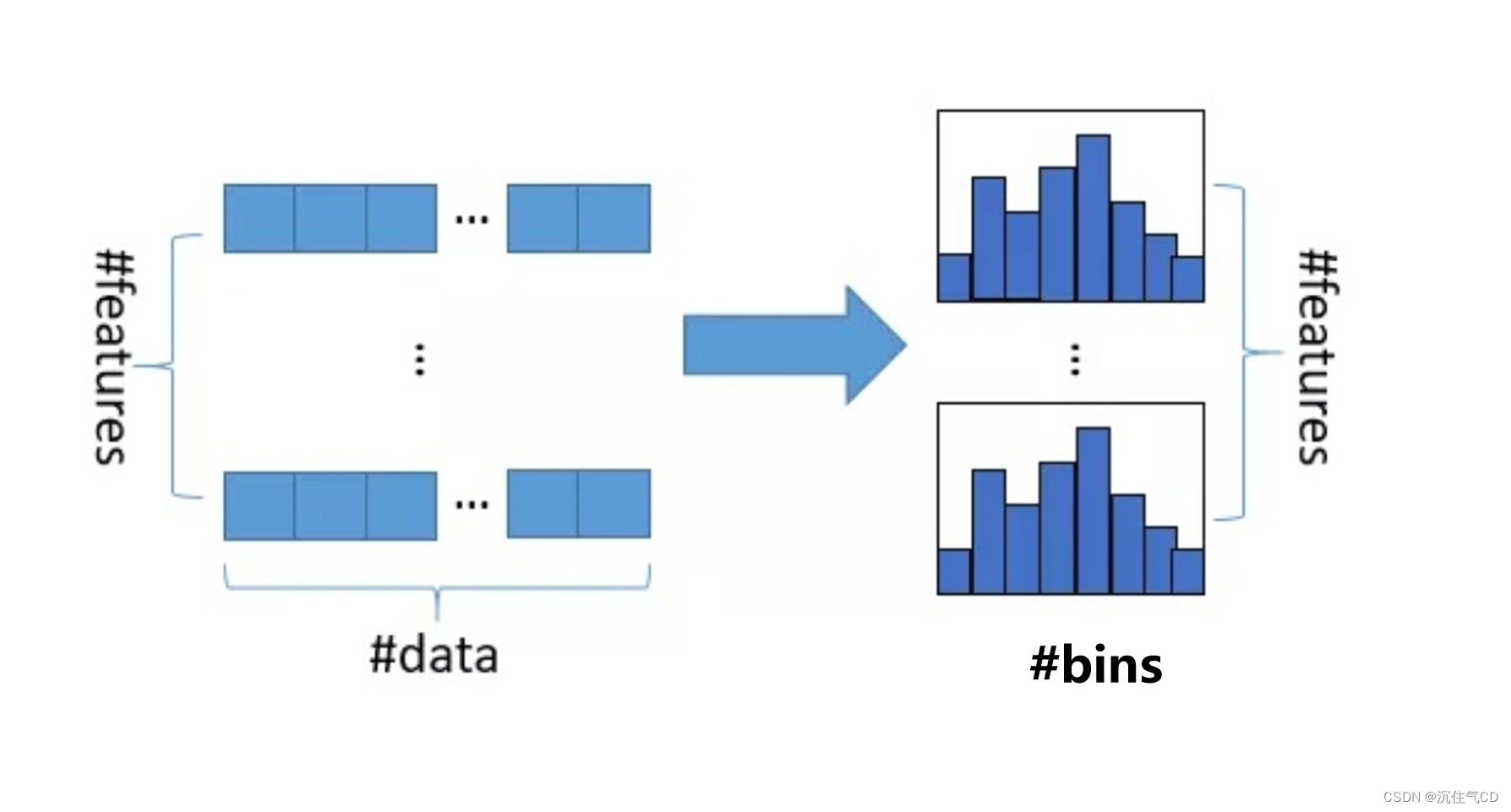
直方图算法的简单理解为:首先确定对于每个特征需要多少个箱子(bin)并为每个箱子分配一个整数;然后将浮点数的范围均分成若干区间,区间个数与箱子个数相等,将属于该箱子的样本数据更新为箱子的值;最后用直方图(#bins)表示。该算法本质上很简单,就是将大规模的数据放在了直方图中,就是直方图统计。
特征离散化具有很多优点,如存储方便、运算更快、鲁棒性强、模型更加稳定等。对直方图算法来说最直接的有以下两个优点:
- 内存占用更小。直方图算法不仅不需要额外存储预排序的结果,而且可以只保存特征离散化后的值,而这个值一般用8位整型存储就足够了,内存消耗可以降低为原来的1/8。也就是说XGBoost需要用32位的浮点数去存储特征值,并用32位的整形去存储索引,而LGBM只需要用8位整型去存储直方图,内存相当于减少了1/8。
- 计算代价更小:预排序算法XGBoost每遍历一个特征值就需要计算一次分裂的增益,而直方图算法LGBM只需要计算k次(k可以认为是常数),直接将时间复杂度从 O ( # d a t a × # f e a t u r e ) O(\#data\times \#feature) O(#data×#feature)降低到 O ( k × # f e a t u r e ) O(k \times \#feature) O(k×#feature)。
缺点:
直方图算法并不是完美的。由于特征被离散化后,找到的并不是精确的分割点,所以会对结果产生影响。但在不同数据集上的测试结果表明,离散化的分割点对最终的精度影响并不是很大,甚至有时会好一些。这是由于决策树本身就是弱学习器,分割点是不是精确并不太重要,较粗糙的分割点也有正则化的效果,可以有效地防止过拟合,这样即使单个树的训练误差比精确分割的算法稍大,但在梯度提升的框架下并没有太大的影响。
LGBM调参
建议根据经验确定的参数
learning_rate:通常来说,学习率越小模型的最终表现越容易获得比较好的结果,但是过小的学习率往往会导致模型的过拟合以及影响模型训练的时间。一般来说,在调参的过程中会预设一个固定的值如0.1或者0.05,再在其他参数确定后在[0.05-0.2]之间搜索一个不错的值作为最终模型的参数。通常在学习率较小时,n_estimators的数值会大,而学习率大的时候,n_estimators会比较小,它们是一对此消彼长的参数对。n_estimators:- 一般情况下迭代次数越多模型表现越好,但是过大的迭代次往往会导致模型的过拟合以及影响模型训练的时间。一般我们选择的值在100-1000之间,训练时需要时刻关注过拟合的情况以便及时调整迭代次数。通常通过
lgb.plot_metrics(model,metrics='auc')来观察学习曲线的变化,如果在测试集表现趋于下降的时候模型还没有停止训练就说明出现过拟合了。 - 通常为了防止过拟合,都会选一个比较大的
n_estimators,然后设置early_stop_round为[20,50,100]来让模型停止在测试集效果还不错的地方,但如果模型过早的停止训练,比如只迭代了20次,那可能这样的结果是有问题的,需要再仔细研究下原因。 - 还有个通过交叉验证确定
n_estimators的办法,但已有的实验结果表明没有加early_stop_round来的稳定,但也是可以尝试的,具体做法是:进行3-5折交叉检验,训练时加上early_stop_round,记录下每折模型停止时的n_estimators数值,然后n_estimators取交叉检验模型停止的迭代次数的平均值的1.1倍,然后确定这个数值后调整其他参数,最终模型再通过early_stop_round得到最终的n_estimators数值。
- 一般情况下迭代次数越多模型表现越好,但是过大的迭代次往往会导致模型的过拟合以及影响模型训练的时间。一般我们选择的值在100-1000之间,训练时需要时刻关注过拟合的情况以便及时调整迭代次数。通常通过
min_split_gain:不建议调整。增大这个数值会得到相对浅的树深,可通过调整其他参数得到类似的效果。如果实在要调整,可以画出第一棵树和最后一棵树,把每次决策分叉的gain的数值画出来看一下大致范围,然后确定一个下限。但往往设置后模型性能会下降不少,所以如果不是过拟合很严重且没有其他办法缓解才建议调整这个参数。min_child_sample:这个参数需要根据数据集来确定,一般小数据集用默认的20就足够了,但大数据集用20的话会使得生成的叶子结点上数据量过少,会导致出现数据集没有代表性的问题,所以建议按树深为4共16个叶子时平均的训练数据个数的25%的数值来确定这个参数或者在这个范围稍微搜索下,这样模型的稳定性会有所保障。min_child_weight和min_child_sample的作用类似,但这个参数本身对模型的性能影响并不大,而且影响的方式不容易被人脑所理解,不建议过多的进行调整。
需要通过算法来搜索的参数
max_depth:一般在[3,4,5]这三个数里挑一个就好了,设置过大的数值过拟合会比较严重。num_leaves:在LGBM里,叶子节点数设置要和max_depth配合,要小于 2 m a x d e p t h ? 1 2^max_depth-1 2maxd?epth?1。一般max_depth取3时,叶子数要小于7。在参数搜索时,需要用max_depth去限制num_leaves的取值范围。subsample:不建议过度的精细细节,比如用搜索算法搜一个0.816386328这样的结果就不是很好。一般给出大致的搜索范围[0.7,0.8,0.9,1]这样几个比较整的数值就足够了。colsample_bytree:和subsample同理,一般给出大致的搜索范围[0.7,0.8,0.9,1]这样几个比较整的数值就足够了。reg_alpha:此参数用于L1正则化,一般在[0-1000]之间去进行调参。如果优化出来的数值过大,则说明有一些不必要的特征可以剔除,可以先做特征筛选后再进行调参,然后调节出来模型效果好的时候reg_alpha是个相对小的数值,那么我们对这个模型的信心会大很多。reg_lambda:此参数用于L2正则化,一般也在[0-1000]之间去进行调参。如果有非常强势的特征,可以人为加大一些使得整体特征效果平均一些,一般比reg_alpha略大一些,但如果大的夸张也需要查看一遍特征是否合理。
总结
在进行调参之前应该做好特征工程,确定特征后,更加数据规模和几个模型尝试的结果初步敲定learning_rate、n_estimators、min_split_gain、min_child_sample、min_child_weight这几个参数,然后使用grid_search、Bayesian optimization或random search来调整max_depth、 num_leaves、 subsample、 colsample_bytree、 reg_alpha、 reg_lambda。其中重点要调节max_depth和num_leaves,并注意两者的关系,其次subsample和 colsample_bytree在[0-1000]之间去进行粗略的调整下即可,reg_alpha和reg_lambda在[0,1000]范围调整,最后比较好的模型这两个参数值不应过大,尤其是reg_alpha,过大需要查看特征。
参考:
- Guolin Ke et al.(2017). Lightgbm: A highly efficient gradient boosting decision tree
- LightGBM(lgb)介绍
- LightGBM参数设置,看这篇就够了
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 初识 Elasticsearch 应用知识,一文读懂 Elasticsearch 知识文集(3)
- 如何获取用友ERP的动态Token?
- Docker 与 Podman:揭示容器编排的最佳 25 大常见问题解答
- macOS系统下载安装PyCharm社区版本的流程(详细)
- 如何实现高效的Web自动化测试?
- Java中的String类
- 力扣题目学习笔记(OC + Swift) 11
- 【SpringBoot】日期格式化
- Yaklang 中的类型和变量
- SpringTask简单使用