【特征工程】分类变量:BinaryEncoder二进制编码方法详解
发布时间:2024年01月17日
Binary Encoding:二进制编码方法详解
Binary Encoding是将每个整数表示为二进制数,然后按位拆分为多个二进制变量。这种方法旨在减少维度,同时避免了One-Hot Encoding的高维稀疏问题。
Binary encoding for categorical variables, similar to onehot, but stores categories as binary bitstrings.
例如,如果有一个分类变量有3个类别,分别用0、1、2表示,那么它们的二进制编码可能如下:
- 类别 0: 00
- 类别 1: 01
- 类别 2: 10
这样,每个类别都被编码为一个唯一的二进制数。
2. 优缺点
优点:
- 维度减少: 相较于One-Hot Encoding,Binary Encoding能够显著减少维度,降低模型复杂度,提高训练效率。
- 空间效率: 由于二进制编码的方式,Binary Encoding相对于One-Hot Encoding在存储上更加紧凑,尤其在处理大规模数据时具备优势。
缺点:
- 大小关系的引入: 与其他编码方法一样,Binary Encoding也可能引入类别之间的大小关系,可能对某些模型产生误导。
3. 参考代码案例
以下是使用Python的category_encoders库进行Binary Encoding的简单示例:
import pandas as pd
from category_encoders import BinaryEncoder
# 创建示例数据
data = {'Category': [0, 1, 2, 3, 0, 1, 2, 3]} # 可以增加类别
df = pd.DataFrame(data)
# 初始化BinaryEncoder
encoder = BinaryEncoder(cols=['Category'])
# 对分类变量进行二进制编码
df_encoded = encoder.fit_transform(df)
# 打印编码后的数据
df_encoded
| 输入 | 输出 |
|---|---|
| [0, 1, 2, 3, 0, 1, 2, 3] | 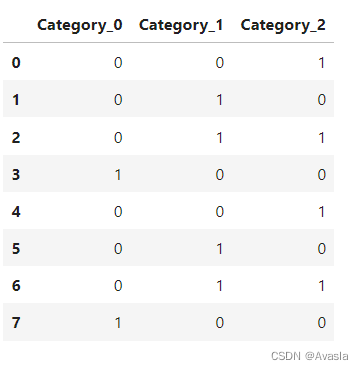 |
| [0, 1, 2, 0, 1, 2] | 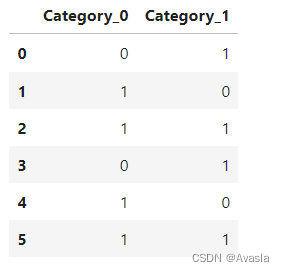 |
| [0, 1, 2, 0, 1, 2,3,4,5,6,7,8,9] | 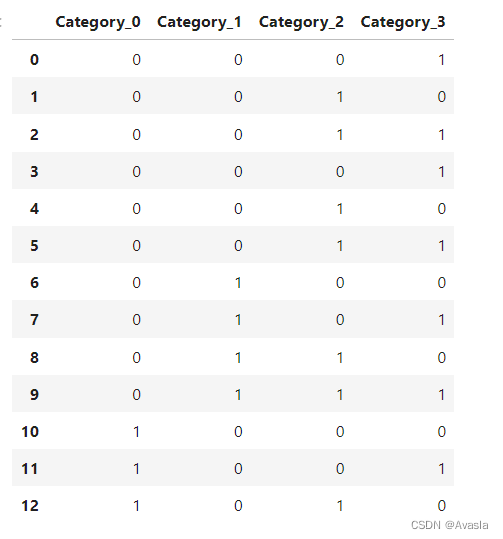 |
可以修改示例数据中的类别,比如增加到7、8、9等等,会发现相比起独热编码——将每个类别作为一列,使用0和1判断是否属于这一个类别,二进制方法不会新增更多的维度(列)。
4. 适合的模型类型
Binary Encoding主要适用于树状模型,如决策树、随机森林和梯度提升树等。这是因为这些模型能够有效处理高维度的输入,且不受类别大小关系的影响。在处理大规模数据集时,Binary Encoding能够在保持模型性能的同时降低计算成本,使其成为一种有效的特征工程方法。
总体而言,Binary Encoding在适用场景下是一种强大的编码方法,通过平衡维度减少和空间效率,为建模提供了一种有效的特征表示方式。
官方文档:https://contrib.scikit-learn.org/category_encoders/
文章来源:https://blog.csdn.net/WHYbeHERE/article/details/135605722
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Vue组合式与选项式写法的一些总结及部分代码
- 【Linux操作系统】探秘Linux奥秘:进程与任务管理的解密与实战
- Network unreachable
- 某汽车塑料制品有限公司:采用监控易管理平台提升IT运营效率
- MySQL触发器
- 智能充电桩电动工具 wifi蓝牙 解决方案
- 网络安全产品之认识入侵防御系统
- 《PCI Express体系结构导读》随记 —— 第I篇 第2章 PCI总线的桥与配置(17)
- 原子累加器 LongAdder
- 微服务研发时,多个人共同调试一个服务,在nacos会启动多个实例,导致请求服务接口时在你和别人之间来回轮询问题处理