selenium爬虫爬取当当网书籍信息 | 最新!
发布时间:2024年01月18日
如果对selenium不了解的话可以到下面的链接中看基础内容:
废话不多说了下面是代码并且带有详细的注释:
爬取其他类型的书籍和下面基本上是类似的可以自行更改。
# 导入所需的库
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
import csv
# 创建一个Chrome浏览器实例,并设置为无头模式(不显示界面)
options = webdriver.ChromeOptions()
options.add_argument('--headless')
driver = webdriver.Chrome(options=options)
# 访问当当网首页
driver.get('https://www.dangdang.com/')
# 在搜索框中输入关键词"科幻"
key = driver.find_element(By.ID, "key_S")
key.send_keys("科幻")
# 点击搜索按钮
element = driver.find_element(By.ID, "search_btn")
driver.execute_script("arguments[0].click();", element)
# 创建CSV文件并写入表头
with open('output.csv', 'w', newline='', encoding='utf-8') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['标题', '价格'])
# 循环爬取前3页的书籍信息
for i in range(3):
# 获取当前页面的所有书籍列表
shoplist = driver.find_elements(By.CSS_SELECTOR, ".shoplist li")
# 遍历每本书的信息
for li in shoplist:
# 获取书名
title = li.find_element(By.CSS_SELECTOR, "a").get_attribute("title")
# 获取价格
price = li.find_element(By.CSS_SELECTOR, ".search_now_price").text
# 将获取到的数据添加到CSV文件中
with open('output.csv', 'a', newline='', encoding='utf-8') as csvfile:
writer = csv.writer(csvfile)
writer.writerow([title, price])
# 获取下一页的链接并点击
next = driver.find_element(By.LINK_TEXT, "下一页")
next.click()
# 等待页面加载完成
time.sleep(2)
# 当用户输入1时,退出浏览器
if input('1'):
driver.quit()
下面是运行效果
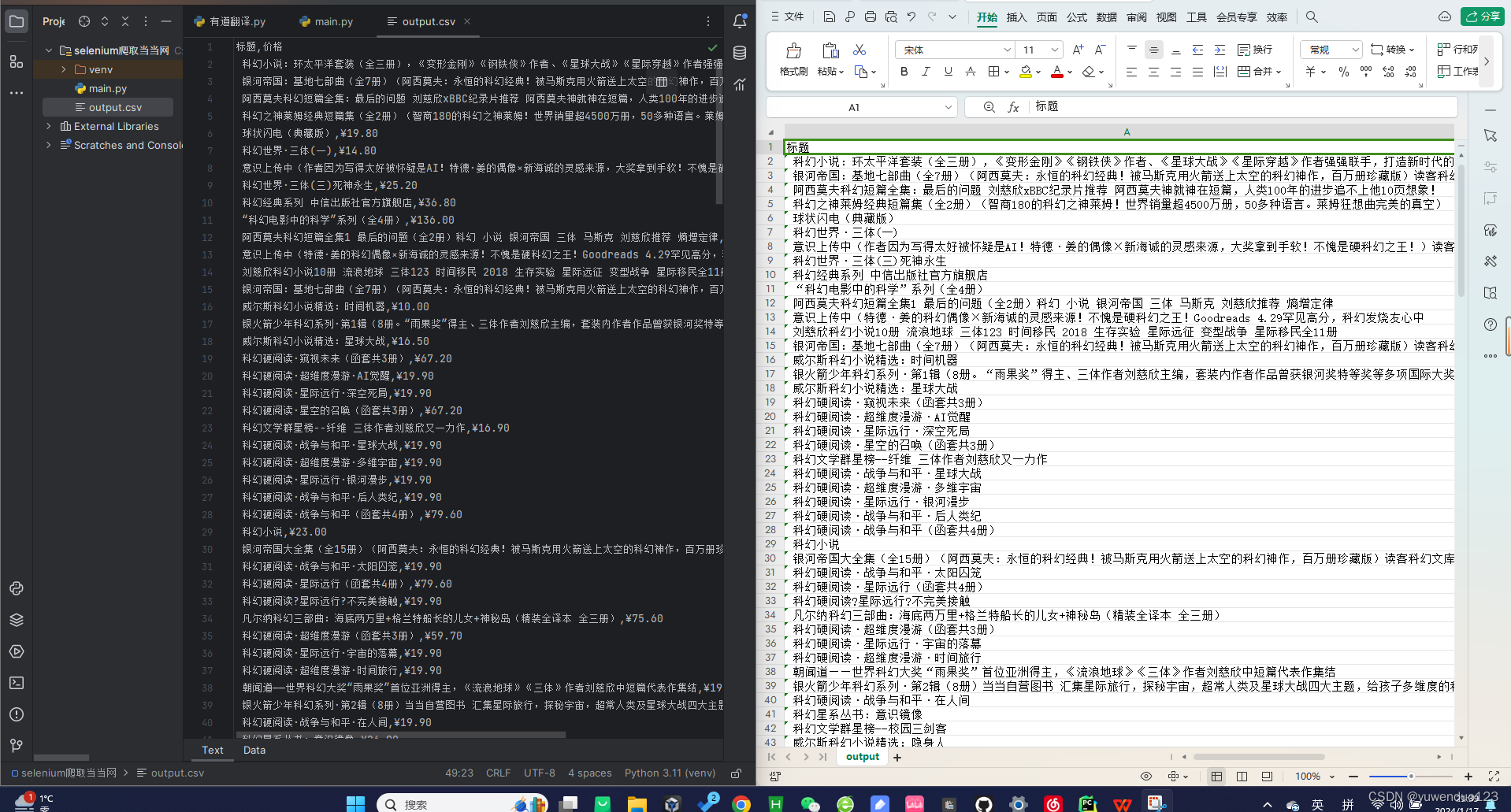
代码是最新的,在这一段时间内一定是可以运行的
如果有啥问题可以问我看到一定会回复大家,如果大家喜欢可以作者点赞和关注
大家的支持是我创作下去的最大动力!
?
文章来源:https://blog.csdn.net/yuwenduo123/article/details/135660927
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!