【头歌实训】PySpark Streaming 入门
第1关:SparkStreaming 基础 与 套接字流
任务描述
本关任务:使用 Spark Streaming 实现词频统计。
相关知识
为了完成本关任务,你需要掌握:
- Spark Streaming 简介;
- Python 与 Spark Streaming;
- Python Spark Streaming API;
- Spark Streaming 初体验(套接字流)。
Spark Streaming 简介
Spark Streaming 是 Spark 的核心组件之一,为 Spark 提供了可拓展、高吞吐、容错的流计算能力。如下图所示,Spark Streaming 可整合多种输入数据源,如 Kafka、Flume、HDFS,甚至是普通的 TCP 套接字。经处理后的数据可存储至文件系统、数据库,或显示在仪表盘里。

Spark Streaming 的基本原理是将实时输入数据流以时间片(秒级)为单位进行拆分,然后经 Spark 引擎以类似批处理的方式处理每个时间片数据,执行流程如下图所示。

Spark Streaming 最主要的抽象是 DStream(Discretized Stream,离散化数据流),表示连续不断的数据流。在内部实现上,Spark Streaming 的输入数据按照时间片(如 1 秒)分成一段一段的 DStream,每一段数据转换为 Spark 中的 RDD,并且对 DStream 的操作都最终转变为对相应的 RDD 的操作。例如,下图展示了进行单词统计时,每个时间片的数据(存储句子的 RDD)经 flatMap 操作,生成了存储单词的 RDD。整个流式计算可根据业务的需求对这些中间的结果进一步处理,或者存储到外部设备中。
Python 与 Spark Streaming
在 Python 中使用 Spark Streaming 只需要下载 pyspark 扩展库即可,命令如下:
pip install pyspark
键入命令后,等待下载完成。

出现如上图所示,则表示安装完成。
创建 Spark Streaming 的上下文对象:
方式一
# 导入包
from pyspark import SparkContext, SparkConf
from pyspark.streaming import StreamingContext
# 通过 SparkConf() 设置配置参数
sparkConf = SparkConf()
sparkConf.setAppName('demo')
sparkConf.setMaster('local[*]')
# 创建 spark 上下文对象
sc = SparkContext(conf=sparkConf)
# 创建 Spark Streaming 上下文对象
# 参数1:spark 上下文对象
# 参数2:读取间隔时间(秒)
ssc = StreamingContext(sc, 5)
方式二
# 导入包
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
# 创建 spark 上下文对象
sc = SparkContext("local[*]", "demo")
# 创建 Spark Streaming 上下文对象
# 参数1:spark 上下文对象
# 参数2:读取间隔时间(秒)
ssc = StreamingContext(sc, 5)
Python Spark Streaming API
在 pyspark 库中有很多丰富的 API 提供使用,下面将介绍常用的一些 API。
Spark Streaming 核心 API
| 名称 | 释义 |
|---|---|
| StreamingContext(sparkContext[, …]) | Spark Streaming 功能的主要入口点。 |
| DStream(jdstream、ssc、jrdd_deserializer) | 离散流 (DStream) 是 Spark Streaming 中的基本抽象,是表示连续数据流的 RDD 的连续序列(相同类型)。 |
Spark Streaming 操作 API
| 名称 | 释义 |
|---|---|
| StreamingContext.addStreamingListener(…) | 添加一个 [[org.apache.spark.streaming.scheduler.StreamingListener]] 对象,用于接收与流相关的系统事件。 |
| StreamingContext.awaitTermination([timeout]) | 等待执行停止。 |
| StreamingContext.awaitTerminationOrTimeout([timeout]) | 等待执行停止。 |
| StreamingContext.checkpoint(directory) | 设置上下文以定期检查 DStream 操作以实现主控容错。 |
| StreamingContext.getActive() | 返回当前活动的 StreamingContext 或无。 |
| StreamingContext.getActiveOrCreate(……) | 要么返回活动的 StreamingContext(即当前已启动但未停止),要么从检查点数据重新创建 StreamingContext 或使用提供的 setupFunc 函数创建新的 StreamingContext。 |
| StreamingContext.remember(duration) | 在此上下文中设置每个 DStreams 以记住它在最后给定持续时间内生成的 RDD。 |
| StreamingContext.sparkContext | 返回与此 StreamingContext 关联的 SparkContext。 |
| StreamingContext.start() | 开始执行流。 |
| StreamingContext.stop([stopSparkContext,…]) | 停止流的执行,可选择确保所有接收到的数据都已处理。 |
| StreamingContext.transform(dstreams,……) | 创建一个新的 DStream,其中每个 RDD 都是通过在 DStream 的 RDD 上应用函数来生成的。 |
| StreamingContext.union(*dstreams) | 从多个相同类型和相同幻灯片时长的 DStream 创建一个统一的 DStream。 |
输入与输出 API
| 名称 | 释义 |
|---|---|
| StreamingContext.binaryRecordsStream(……) | 创建一个输入流,用于监控与 Hadoop 兼容的文件系统中的新文件,并将它们作为具有固定长度记录的平面二进制文件读取。 |
| StreamingContext.queueStream(rdds[, …]) | 从 RDD 或列表的队列中创建输入流。 |
| StreamingContext.socketTextStream(hostname, port) | 从 TCP 源主机名创建输入:端口。 |
| StreamingContext.textFileStream(directory) | 创建一个输入流,用于监视与 Hadoop 兼容的文件系统中的新文件并将它们作为文本文件读取。 |
| DStream.pprint([num]) | 打印此 DStream 中生成的每个 RDD 的前 num 个元素。 |
| DStream.saveAsTextFiles(prefix[, suffix]) | 将此 DStream 中的每个 RDD 保存为文本文件,使用元素的字符串表示。 |
常用的转换与操作 API
| 名称 | 释义 |
|---|---|
| DStream.count() | 返回一个新的 DStream,其中每个 RDD 都有一个元素,该元素是通过计算此 DStream 的每个 RDD 生成的。 |
| DStream.countByValue() | 返回一个新的 DStream,其中每个 RDD 包含此 DStream 的每个 RDD 中每个不同值的计数。 |
| DStream.filter(F) | 返回一个新的 DStream,仅包含满足条件的元素。 |
| DStream.flatMap(f[,preservesPartitioning]) | 通过对该 DStream 的所有元素应用一个函数,然后将结果展平,返回一个新的 DStream。 |
| DStream.flatMapValues(F) | 通过将 flatmap 函数应用于此 DStream 中每个键值对的值而不更改键,返回一个新的 DStream。 |
| DStream.foreachRDD(func) | 对这个 DStream 中的每个 RDD 应用一个函数。 |
| DStream.groupByKey([numPartitions]) | 通过在每个 RDD 上应用 groupByKey 返回一个新的 DStream。 |
| DStream.join(other[,numPartitions]) | 通过在这个 DStream 和其他DStream 的 RDD 之间应用 ‘join’ 返回一个新的DStream。 |
| DStream.map(f[,preservesPartitioning]) | 通过对 DStream 的每个元素应用一个函数来返回一个新的 DStream。 |
| DStream.mapValues(F) | 通过对该 DStream 中每个键值对的值应用映射函数返回一个新的 DStream,而不更改键。 |
| DStream.reduce(func) | 返回一个新的 DStream,其中每个 RDD 具有通过减少此 DStream 的每个 RDD 生成的单个元素。 |
| DStream.reduceByKey(func[,numPartitions]) | 通过对每个 RDD 应用 reduceByKey 来返回一个新的 DStream。 |
| DStream.updateStateByKey(updateFunc[, …]) | 返回一个新的“状态” DStream,其中每个键的状态通过对键的先前状态和键的新值应用给定函数来更新。 |
Spark Streaming 初体验(套接字流)
下面让我们快速了解一下简单的 Spark Streaming 程序是什么样的,假设我们要计算从侦听 TCP 套接字的数据服务器接收到的文本数据中的字数,实现一个流式的 WordCount 计算程序。
第一步,导入包
打开右侧命令行窗口,等待连接后,在主目录下创建文件 test.py,导入 Spark Streaming 所需要的包。
touch test.py
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
第二步,创建上下文对象
首先,我们导入StreamingContext,它是所有流功能的主要入口点。创建一个具有多个执行线程的本地 StreamingContext,批处理间隔为 20 秒。
sc = SparkContext("local[*]", "demo")
# 每 20 秒读取一次
ssc = StreamingContext(sc, 20)
第三步,指定数据流
使用这个上下文,我们可以创建一个表示来自 TCP 源的流数据的 DStream,指定为主机名(例如:localhost)和端口(例如:7777)。
lines = ssc.socketTextStream("localhost", 7777)
第四步,分词统计与输出
接下来,我们要按空格(根据数据流的情况来)将行拆分为单词。
words = lines.flatMap(lambda line: line.split(" "))
在这种情况下,每一行将被拆分为多个单词,单词流表示为 wordsDStream。接下来,我们要计算这些单词,输出结果到屏幕。
pairs = words.map(lambda word: (word, 1))
wordCounts = pairs.reduceByKey(lambda x, y: x + y)
wordCounts.pprint()
第五步,启动与停止
请注意,当执行这些行时,Spark Streaming 仅设置它在启动时将执行的计算,并且尚未开始真正的处理。在所有转换设置完成后才开始处理,所以我们最后调用。
# 开始执行流
ssc.start()
# 等待计算终止
ssc.awaitTermination()
启动前我们需要先新开一个命令行窗口用于创建数据流服务器发送端。点击右侧 + 号,新增一个命令行窗口,启动数据流服务器。
nc -l -p 7777
必须先启动数据流服务器,然后再开始执行程序。
回到刚刚的代码窗口,启动程序,开始监听。启动后,我们切换到数据流服务器窗口,输入如下单词:
hello python
hello spark
hello spark streaming
代码窗口界面结果输出如下:
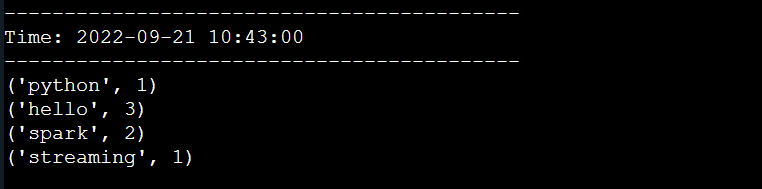
当我们在数据流服务器窗口再次输入和上面一样的单词时,发现结果没有进行累加,如下所示:

这是由于我们并没有实现更新的操作,我们需要使用 updateStateByKey(func) 方法对其进行累加统计,其参数为一个函数,也就是根据传入的这个函数来实现状态更新功能。
当我们使用累加器时还需借助 checkpoint() 方法设置检查点,告知累加器其检查区域,其参数为一个字符串,指定为保存检查点的目录,如果指定目录未存在,则会自动创建。
具体实现方式如下代码所示:
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
# 累加器(状态更新)
def updateFunction(newValues, runningCount):
if runningCount is None:
runningCount = 0
return sum(newValues, runningCount)
sc = SparkContext("local[*]", "demo")
# 设置输入日志等级
sc.setLogLevel("ERROR")
ssc = StreamingContext(sc, 20)
# 设置检查点
ssc.checkpoint("file:///usr/local/word_log")
# 指定监听端口
lines = ssc.socketTextStream("localhost", 7777)
# 进行词频统计
words = lines.flatMap(lambda line: line.split(" "))
pairs = words.map(lambda word: (word, 1))
# 调用累加器
wordCounts = pairs.updateStateByKey(updateFunction)
# 输出到屏幕
wordCounts.pprint()
ssc.start()
ssc.awaitTermination()
**运行程序,注意,先启动数据流服务器。**输入如下数据两次,请在第一次数据输出到屏幕上后再输入第二次:
hello python
hello spark
hello spark streaming
第一次结果如下:

第二次结果如下:

从结果中可以看出,我们已经实现了从套接字流中读取数据并完成词频统计。
编程要求
打开右侧代码文件窗口,在 Begin 至 End 区域补充代码,执行程序,读取套接字流数据,按空格进行分词,完成词频统计。补充代码,将词频统计的输出内容存储到 /data/workspace/myshixun/project/step1/result 文件中。
代码文件目录: /data/workspace/myshixun/project/step1/work.py
套接字流相关信息:
- 地址:
localhost - 端口:
8888 - 输入数据:
程序启动后(5s),请在 60 秒内写入数据,如果需要调整时间,你可以通过修改代码文件中 ssc.awaitTermination(timeout=60) 的 timeout 指定时间。
It is believed that the computer is bringing the world into a brand new era.
At the time the computer was invented, scientists, marveling at its calculating speed,
felt that they had created a miracle.
Nowadays, the function of the computer is no longer confined to calculation;
It permeates peoples daily lives and has become an inseparable part of human society.
输入内容后,注意按回车。
检查点存放本地目录:/root/mylog/
请在程序运行完成后再点击评测,否则会影响评测结果。
小贴士:
pprint()方法中可以设置数据输出显示的数量。
测试说明
平台将对你编写的代码进行评测,如果与预期结果一致,则通关,否则测试失败。
答案代码
先写入代码
#!/usr/local/bin/python
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
# 累加器(状态更新)
def updateFunction(newValues, runningCount):
if runningCount is None:
runningCount = 0
return sum(newValues, runningCount)
sc = SparkContext("local[*]", "work")
ssc = StreamingContext(sc, 10)
###################### Begin ######################
# 设置检查点
ssc.checkpoint("/root/mylog/")
# 指定监听端口
lines = ssc.socketTextStream("localhost", 8888)
# 进行词频统计
words = lines.flatMap(lambda line: line.split(" "))
pairs = words.map(lambda word: (word, 1))
# 调用累加器
wordCounts = pairs.updateStateByKey(updateFunction)
# 输出到屏幕
wordCounts.pprint()
# 保存输出内容到指定文件中
wordCounts.saveAsTextFiles("/data/workspace/myshixun/project/step1/result","txt")
###################### End ######################
ssc.start()
ssc.awaitTermination(timeout=60)
在第一个命令行窗口执行,启动数据流服务器
mkdir -p /root/mylog/
cd /root/mylog/
nc -l -p 8888
启动程序,开始监听后,打开另一个命令行窗口执行
cd /data/workspace/myshixun/project/step1/
chmod 777 work.py
python work.py # 现在开始运行代码文件,请在 60 秒内写入下面数据
回到第一个命令行窗口下把下面数据粘贴上去,再打一个回车
It is believed that the computer is bringing the world into a brand new era.
At the time the computer was invented, scientists, marveling at its calculating speed,
felt that they had created a miracle.
Nowadays, the function of the computer is no longer confined to calculation;
It permeates peoples daily lives and has become an inseparable part of human society.
再去另一个命令行窗口就可以看到正在统计词频了
第2关:文件流
任务描述
本关任务:使用 Spark Streaming 实现文件目录监听,完成词频统计。
相关知识
为了完成本关任务,你需要掌握:
- 文件流概述;
- Python 与 Spark Streaming 文件流;
- Spark Streaming 文件流初体验。
文件流概述
文件流就是数据从一个地方流到另一个地方,像一块大蛋糕一样把一个大的文件分成一块一块的流过去就叫文件流。其中流分为输入流与输出流,输入流指从外界向我们的程序中移动的方向,因此是用来获取数据的流,作用就是读操作。输出流与之相反,从程序向外界移动的方向,用来输出数据的流,作用就是写操作。流是单向的,输入用来读,输出用来写。

那么我们为什么需要流呢?
- 当外部设备与内存中的数据规模不一致,内存小,外部设备大,如果内存大小只有 1G ,但从磁盘读 2G,不能一次读完,这时就需要流。
- 当外部设备与内存处理数据的能力不一致,内存处理数据快,外部设备慢,内存给磁盘写了 1G ,磁盘可能需要 5 秒去处理写数据,其他事件就会受到影响,这时就需要流。
- 当读取或者写入大文件时数据会推挤在内存中,导致效率低(内存数据多,导致执行时间变长),这时就需要流。
Python 与 Spark Streaming 文件流
Spark 支持从兼容 HDFS API 的文件系统中读取数据,创建数据流。在 Python 中使用 Spark Streaming 文件流十分简单,通过 textFileStream() 方法就可以对创建文件流。
在 Python 中创建 Spark Streaming 文件流:
# 导入包
from pyspark import SparkContext, SparkConf
from pyspark.streaming import StreamingContext
# 通过 SparkConf() 配置参数
sparkConf = SparkConf()
sparkConf.setAppName('demo')
sparkConf.setMaster('local[*]')
# 创建 spark 上下文对象
sc = SparkContext(conf=sparkConf)
# 创建 Spark Streaming 上下文对象
# 参数1:spark 上下文对象
# 参数2:读取间隔时间(秒)
ssc = StreamingContext(sc, 10)
# 指定目录或文件,创建文件流
ssc.textFileStream("xxxxxx")
Spark Streaming 文件流初体验
通过对文件流及其创建方法的了解,我们现在通过实际的文件流案例来学习 Spark Streaming 读取文件流的具体实现。
打开右侧命令行窗口,创建一个目录 test,并在里面创建两个子文件 log1.txt、log2.txt,用于模拟数据。
cd /root
mkdir test
cd /root/test
touch log1.txt log2.txt
创建完成后,我们在新建的两个文件 log1.txt 和 log2.txt 中任意写入一些数据。
echo -e "hello python \nhello spark streaming \nI love big data!" > /root/test/log1.txt
echo -e "hello python \nhello spark streaming \nI love big data!" > /root/test/log2.txt
下面我们就进入 python shell 界面,创建文件流。
python
进入后,出现如下界面:

第一步,指定监听目录 /root/test,创建 Spark Streaming 文件流
# 导入包
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
# 创建 spark 上下文对象
sc = SparkContext("local[*]","demo")
# 创建 Spark Streaming 上下文对象
ssc = StreamingContext(sc, 10)
# 指定 /root/test 目录,创建文件流
lines = ssc.textFileStream("/root/test")
第二步,数据处理
完成对文件流中相关数据的处理。
lines.pprint()
第三步,启动与停止
ssc.start()
ssc.awaitTermination()
运行后发现,并没有输出我们之前写入到文件 log1.txt 和 log2.txt中的内容。

原因是,程序启动后只会只监听 /root/test 目录下在程序启动后新增的文件,不会去处理历史上已经存在的文件,即使你对其进行更新操作。
现在我们点击 + 号新增一个命令行窗口,验证是否真的如此。打开新窗口后,切换到监听目录中,创建一个新文件 log3.txt,任意写入一些数据。
cd /root/test
vi log3.txt
hello python
hello spark
此时我们返回程序运行窗口,稍作等待,查看输出内容,发现刚刚创建的文件 log3.txt 其中的内容输出到了屏幕上。

现在我们来测试更新操作是否会被读取到,对程序运行前创建的文件 log2.txt 进行更新操作,任意追加一些内容。
cd /root/test
vi log2.txt
I like ping!

此时我们返回程序运行窗口,稍作等待,查看输出内容,发现对 log2.txt 文件追加的内容并没有输出到屏幕上。

说明程序运行前监听目录下的文件并不会被识别。
文件流的扩展知识:
- 可以提供
POSIX glob模式,例如:hdfs://namenode:8040/logs/2017/*,在这里,DStream 将包含与该模式匹配的目录中的所有文件。也就是说:它是目录的模式,而不是目录中的文件。 - 所有文件必须采用相同的数据格式。
- 文件根据其修改时间而非创建时间被视为时间段的一部分。
- 一旦处理完毕,在当前窗口中对文件的更改不会导致文件被重新读取,即:更新被忽略。
- 目录下的文件越多,扫描更改所需的时间就越长——即使没有文件被修改。
- 如果使用通配符来标识目录,例如:
hdfs://namenode:8040/logs/2016-*,重命名整个目录以匹配路径,则会将该目录添加到受监视目录列表中。只有目录中修改时间在当前窗口内的文件才会包含在流中。 - 调用FileSystem.setTimes() 修复时间戳是一种在以后的窗口中拾取文件的方法,即使它的内容没有改变。
编程要求
打开右侧代码文件窗口,在 Begin 至 End 区域补充代码,执行程序,读取文件流数据,按空格进行分词,完成词频统计。补充代码,将词频统计的输出内容存储到 /data/workspace/myshixun/project/step2/result 文件中。
代码文件目录: /data/workspace/myshixun/project/step2/work.py
文件流相关信息:
- 监听目录:
/root/file_stream(需要自行创建) - 文件名称:
words.txt(需要自行创建) - 文件内的数据:
程序启动后(5s),请在 60 秒内创建文件并写入数据,如果需要调整时间,你可以通过修改代码文件中 ssc.awaitTermination(timeout=60) 的 timeout 指定时间。
Hiding behind the loose dusty curtain, a teenager packed up his overcoat into the suitcase.
He planned to leave home at dusk though there was thunder and lightning outdoors.
As a result, his score in each exam never added up to over 60, his name is LiMing.
输入内容后,注意保存退出。
检查点存放本地目录:/root/mylog2/
小贴士:
pprint()方法中可以设置数据输出显示的数量。
测试说明
平台将对你编写的代码进行评测,如果与预期结果一致,则通关,否则测试失败。
答案代码
#!/usr/local/bin/python
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
# 累加器(状态更新)
def updateFunction(newValues, runningCount):
if runningCount is None:
runningCount = 0
return sum(newValues, runningCount)
sc = SparkContext("local[*]", "work")
ssc = StreamingContext(sc, 10)
###################### Begin ######################
# 设置检查点
ssc.checkpoint("/root/mylog2/")
# 指定监听端口
lines = ssc.textFileStream("/root/test")
# 进行词频统计
words = lines.flatMap(lambda line: line.split(" "))
pairs = words.map(lambda word: (word, 1))
# 调用累加器
wordCounts = pairs.updateStateByKey(updateFunction)
# 输出到屏幕
wordCounts.pprint()
# 保存输出内容到指定文件中
wordCounts.saveAsTextFiles("/data/workspace/myshixun/project/step2/result","txt")
###################### End ######################
ssc.start()
ssc.awaitTermination(timeout=60)
在第一个命令行窗口执行
mkdir -p /root/test/
mkdir -p /root/mylog2/
cd /data/workspace/myshixun/project/step2/
chmod 777 work.py
python work.py # 现在开始运行代码文件,请在 60 秒内创建文件并写入下面数据
再打开一个命令行窗口创建文件并写入下面数据
vim /root/test/words.txt
把下面数据粘贴上去
Hiding behind the loose dusty curtain, a teenager packed up his overcoat into the suitcase.
He planned to leave home at dusk though there was thunder and lightning outdoors.
As a result, his score in each exam never added up to over 60, his name is LiMing.
再去另一个命令行窗口就可以看到正在统计词频了
第3关:RDD 队列流
任务描述
本关任务:使用 Spark Streaming 实现队列流,完成词频统计。
相关知识
为了完成本关任务,你需要掌握:
- 队列流概述;
- Python 与 Spark Streaming 队列流;
- Spark Streaming 队列流初体验。
队列流概述
队列是无须的或共享的消息。使用队列消息传递,可以创建多个消费者来从点对点消息传递通道接收消息。当通道传递消息时,任何消费者都可能收到消息。消息传递系统的实现确定哪个消费者实际接收消息。Queuing 通常与无状态应用程序一起使用。无状态应用程序不关心顺序,但它们确实需要识别或删除单个消息的能力,以及尽可能扩展并行消耗的能力。

相比之下,流是严格有序的或独占的消息传递。使用流消息传递,始终只有一个消费者使用消息传递通道。消费者接收从通道发送的消息,其顺序与消息的写入顺序一致。Streaming 通常与有状态的应用程序一起使用。有状态应用程序关心消息顺序及其状态。消息的顺序决定有状态应用程序的状态。当发生无序消费时,排序将影响应用程序,需要处理逻辑的正确性。
Python 与 Spark Streaming 队列流
为了使用测试数据测试 Spark Streaming 应用程序,还可以基于 RDD 队列创建 DStream,使用 streamingContext.queueStream(queueOfRDDs). 每个推入队列的 RDD 都会被视为 DStream 中的一批数据,像流一样处理。

在 Python 中创建 Spark Streaming 队列流:
# 导入包
from pyspark import SparkContext, SparkConf
from pyspark.streaming import StreamingContext
# 通过 SparkConf() 配置参数
sparkConf = SparkConf()
sparkConf.setAppName('demo')
sparkConf.setMaster('local[*]')
# 创建 spark 上下文对象
sc = SparkContext(conf=sparkConf)
# 创建 Spark Streaming 上下文对象
# 参数1:spark 上下文对象
# 参数2:读取间隔时间(秒)
ssc = StreamingContext(sc, 10)
# 创建列表(RDD)
rddQueue = ["Hello python", "Hello spark", "Hello spark streaming"]
# 创建队列流
inputStream = ssc.queueStream(rddQueue)
Spark Streaming 队列流初体验
通过对队列流及其创建方法的了解,我们现在通过一个案例来学习 Spark Streaming 读取队列流的具体实现。
打开右侧命令行窗口,等待连接后,进入 python shell 界面,创建队列流。
python
进入后,出现如下界面:

第一步,创建 Spark Streaming 队列流
# 导入包
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
# 创建 spark 上下文对象
sc = SparkContext("local[*]","demo")
# 创建 Spark Streaming 上下文对象
ssc = StreamingContext(sc, 10)
# 创建列表(RDD)
rddQueue = ["Hello python", "Hello spark", "Hello spark streaming"]
# 创建队列流
inputStream = ssc.queueStream(rddQueue)
第二步,数据处理
完成对队列流中相关数据的处理。
inputStream.pprint()
第三步,启动与停止
ssc.start()
# 检测到没有数据流输入后就会停止
ssc.stop()
运行后发现,并没有一次输出所有的数据,而是依次的进行输出处理。


…
这就是 Spark Streaming 队列流的特性,我们在使用时需要注意。
编程要求
打开右侧代码文件窗口,在 Begin 至 End 区域补充代码,根据所给出的 rdd 列表,创建队列流,按空格进行分词,完成词频统计,使用 pprint() 输出结果。
词频统计要求:
- 对数据按照 26 个字母进行扁平化统计,例如:
('g', 10)。 - 过滤掉所有为
''的值。
检查点存放本地目录:/root/mylog3/
小贴士:
pprint()方法中可以设置数据输出显示的数量。
测试说明
平台将对你编写的代码进行评测,如果与预期结果一致,则通关,否则测试失败。
答案代码
mkdir -p /root/mylog3/
import time
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
# 累加器(状态更新)
def updateFunction(newValues, runningCount):
if runningCount is None:
runningCount = 0
return sum(newValues, runningCount)
sc = SparkContext("local[*]", "work")
ssc = StreamingContext(sc, 5)
# rdd 列表
rdd = ["My father is a basketball fan, he watches the NBA match when he is free.",
"Because of the effect from my father, I fell in love with basketball when I was very small.",
" So when I go to middle school, I join the basketball team in my class",
" I meet many friends who have the same love for basketball.",
" We will play basketball after class or sometimes in the weekend, we will play the match with other team."]
###################### Begin ######################
# 设置检查点
ssc.checkpoint("/root/mylog3/")
# 创建队列流
inputStream = ssc.queueStream([sc.parallelize([line]) for line in rdd])
# 按空格进行分词
words = inputStream.flatMap(lambda line: line.split(" "))
# 过滤掉空字符串
words_filter = words.filter(lambda word: word != '')
# 按字母进行扁平化统计
words_flatMap = words_filter.flatMap(lambda word: [(letter, 1) for letter in word.lower()])
# 使用 updateStateByKey 进行状态更新
wordCnt = words_flatMap.updateStateByKey(updateFunction)
# 输出结果
wordCnt.pprint()
###################### End ######################
ssc.start()
time.sleep(30)
ssc.stop()
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 二、算法与复杂度
- C语言实现八大排序算法(详解插入排序、希尔排序、选择排序、堆排序、冒泡排序、快速排序(递归和非递归)、归并排序(递归和非递归)和计数排序)
- devecho stuido npm 失败
- 初识C语言
- C语言实用第三方库Melon开箱即用之多线程模型
- Windows下Python+PyCharm+miniconda+Cuda/GPU 安装步骤
- TOP刊质量依旧,新编上任后速度猛增!不愧是国内高校推荐期刊!
- 律师应该如何拥抱AI新技术?
- 【Java 进阶篇】Jedis 操作 Set 与 SortedSet 详解
- oracle aq java jms使用(数据类型为XMLTYPE)