Kubeadm 方式部署K8s集群
环境
主节点CPU核数必须是 ≥2核且内存要求必须≥2G,否则k8s无法启动
| 主机名 | 地址 | 角色 | 配置 |
| kube-master | 192.168.134.165 | 主节点 | 2核4G |
| kube-node1 | 192..168.134.166???????? | 工作节点 | 2核4G |
| kube-node2 | 192.168.134.163 | 工作节点 | 2核4G |
1.获取镜像
谷歌镜像[由于国内网络原因,无法下载,后续将采用阿里云镜像代替]
docker pull k8s.gcr.io/kube-apiserver:v1.22.0 docker pull k8s.gcr.io/kube-proxy:v1.22.0 docker pull k8s.gcr.io/kube-controller-manager:v1.22.0 docker pull k8s.gcr.io/kube-scheduler:v1.22.0 docker pull k8s.gcr.io/etcd:3.5.0-0 docker pull k8s.gcr.io/pause:3.5 docker pull k8s.gcr.io/coredns/coredns:v1.8.4 注意所有机器都必须有镜像
每次部署都会有版本更新,具体版本要求,运行初始化过程失败会有版本提示
kubeadm的版本和镜像的版本必须是对应的
?2.安装docker[集群]
????
使用aliyun docker yum源安装新版docker
删除已安装的Docker
# yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-selinux \
docker-engine-selinux \
docker-engine
配置阿里云Docker Yum源
# yum install -y yum-utils device-mapper-persistent-data lvm2 git
# yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
下载docker
# yum install docker-ce -y
启动Docker服务:
#systemctl enable docker
#systemctl start docker
查看docker版本状态:
# docker -v????生产docker的环境配置
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://pilvpemn.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
#注意:一定注意编码问题,出现错误---查看命令:journalctl -amu docker 即可发现错误3. 阿里仓库下载[集群]
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.22.0
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.22.0
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.22.0
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.22.0
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:v1.8.4
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.5.0-0
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.5
# 下载完了之后需要将aliyun下载下来的所有镜像打成k8s.gcr.io/kube-controller-manager:v1.22.0这样的tag
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-controller-manager:v1.22.0 k8s.gcr.io/kube-controller-manager:v1.22.0
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-proxy:v1.22.0 k8s.gcr.io/kube-proxy:v1.22.0
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.22.0 k8s.gcr.io/kube-apiserver:v1.22.0
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-scheduler:v1.22.0 k8s.gcr.io/kube-scheduler:v1.22.0
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/coredns:v1.8.4 k8s.gcr.io/coredns/coredns:v1.8.4
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/etcd:3.5.0-0 k8s.gcr.io/etcd:3.5.0-0
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.5 k8s.gcr.io/pause:3.5
# 可以清理掉aliyun的镜像标签
docker rmi -f `docker images --format {{.Repository}}:{{.Tag}} | grep aliyun`为了方便执行脚本导入镜像
[root@kube-master ~]# rz
[root@kube-master ~]# ls
anaconda-ks.cfg color.sh ip_.sh kube-1.22.0.tar.xz yum-server.sh
[root@kube-master ~]# tar xf kube-1.22.0.tar.xz
[root@kube-master ~]# ls
anaconda-ks.cfg color.sh ip_.sh kube-1.22.0 kube-1.22.0.tar.xz yum-server.sh
[root@kube-master ~]# cd kube-1.22.0
[root@kube-master kube-1.22.0]# ll
总用量 8
-rw-r--r-- 1 root root 915 6月 19 00:23 get-docker-image.sh
drwxr-xr-x 2 root root 4096 6月 19 00:23 images
[root@kube-master kube-1.22.0]# sh get-docker-image.sh load
4.集群环境相关配置【集群】
4.1配置本地解析
cat >> /etc/hosts <<EOF
192.168.134.165 kube-master
192.168.134.166 kube-node1
192.168.134.163 kube-node2
EOF4.2防火墙和时间
1.关闭防火墙:
# systemctl disable firewalld --now
2.禁用SELinux:
# setenforce 0
3.编辑文件/etc/selinux/config,将SELINUX修改为disabled,如下:
# sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/sysconfig/selinux
SELINUX=disabled
4.时间同步
# timedatectl set-timezone Asia/Shanghai
# yum install -y ntpdate
# ntpdate ntp.aliyun.com
# hwclock --systohc
5.配置静态ip4.3关闭系统Swap[集群]
1.关闭swap分区
# swapoff -a
修改/etc/fstab文件,注释掉SWAP的自动挂载,使用free -m确认swap已经关闭。
2.注释掉swap分区:
# sed -i 's/.*swap.*/#&/' /etc/fstab
# free -m
total used free shared buff/cache available
Mem: 3935 144 3415 8 375 3518
Swap: 0 0 0?5.安装Kubeadm包[集群]
配置阿里云源
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF所有节点:
1.安装依赖包及常用软件包
# yum install -y conntrack ntpdate ntp ipvsadm ipset jq iptables curl sysstat libseccomp wget vim net-tools git iproute lrzsz bash-completion tree bridge-utils unzip bind-utils gcc
2.安装对应版本
# yum install -y kubelet-1.22.0-0.x86_64 kubeadm-1.22.0-0.x86_64 kubectl-1.22.0-0.x86_643.加载ipvs相关内核模块
# cat <<EOF > /etc/modules-load.d/ipvs.conf?
ip_vs
ip_vs_lc
ip_vs_wlc
ip_vs_rr
ip_vs_wrr
ip_vs_lblc
ip_vs_lblcr
ip_vs_dh
ip_vs_sh
ip_vs_nq
ip_vs_sed
ip_vs_ftp
ip_vs_sh
nf_conntrack_ipv4
ip_tables
ip_set
xt_set
ipt_set
ipt_rpfilter
ipt_REJECT
ipip
EOF4.配置:
配置转发相关参数,否则可能会出错
# cat <<EOF > ?/etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
net.ipv4.ip_forward=1
net.ipv4.tcp_tw_recycle=0
vm.swappiness=0
vm.overcommit_memory=1
vm.panic_on_oom=0
fs.inotify.max_user_instances=8192
fs.inotify.max_user_watches=1048576
fs.file-max=52706963
fs.nr_open=52706963
net.ipv6.conf.all.disable_ipv6=1
net.netfilter.nf_conntrack_max=2310720
EOF5.使配置生效
# sysctl --system6.如果net.bridge.bridge-nf-call-iptables报错,加载br_netfilter模块
# modprobe br_netfilter
# modprobe ip_conntrack
# sysctl -p x/etc/sysctl.d/k8s.conf
7.查看是否加载成功
# lsmod | grep ip_vs? ?#如果什么都不显示,重启服务器后再查看?

?6.配置启动kubelet[集群]
配置变量:
[root@k8s-master ~]# DOCKER_CGROUPS=`docker info |grep 'Cgroup' | awk ' NR==1 {print $3}'`
[root@k8s-master ~]# echo $DOCKER_CGROUPS
cgroupfs
2.配置kubelet的cgroups
# cat >/etc/sysconfig/kubelet<<EOF
KUBELET_EXTRA_ARGS="--cgroup-driver=$DOCKER_CGROUPS --pod-infra-container-image=k8s.gcr.io/pause:3.5"
EOF
3.启动
# systemctl daemon-reload
# systemctl enable kubelet && systemctl restart kubelet
在这里使用 # systemctl status kubelet,你会发现报错误信息;
10月 11 00:26:43 node1 systemd[1]: kubelet.service: main process exited, code=exited, status=255/n/a
10月 11 00:26:43 node1 systemd[1]: Unit kubelet.service entered failed state.
10月 11 00:26:43 node1 systemd[1]: kubelet.service failed.
运行 # journalctl -xefu kubelet 命令查看systemd日志才发现,真正的错误是:
unable to load client CA file /etc/kubernetes/pki/ca.crt: open /etc/kubernetes/pki/ca.crt: no such file or directory
#这个错误在运行kubeadm init 生成CA证书后会被自动解决,此处可先忽略。
#简单地说就是在kubeadm init 之前kubelet会不断重启。7.配置master节点[master]
运行初始化过程如下:
[root@kube-master ~]# kubeadm init --kubernetes-version=v1.22.0 --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=192.168.134.165
[init] Using Kubernetes version: v1.22.0
[preflight] Running pre-flight checks
[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 24.0.2. Latest validated version: 20.10
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [kube-master kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 192.168.134.165]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [kube-master localhost] and IPs [192.168.134.165 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [kube-master localhost] and IPs [192.168.134.165 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
[control-plane] Creating static Pod manifest for "kube-scheduler"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 29.002496 seconds
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.22" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node kube-master as control-plane by adding the labels: [node-role.kubernetes.io/master(deprecated) node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers]
[mark-control-plane] Marking the node kube-master as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[bootstrap-token] Using token: eb813a.0nffrc9cij8a6i3x
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
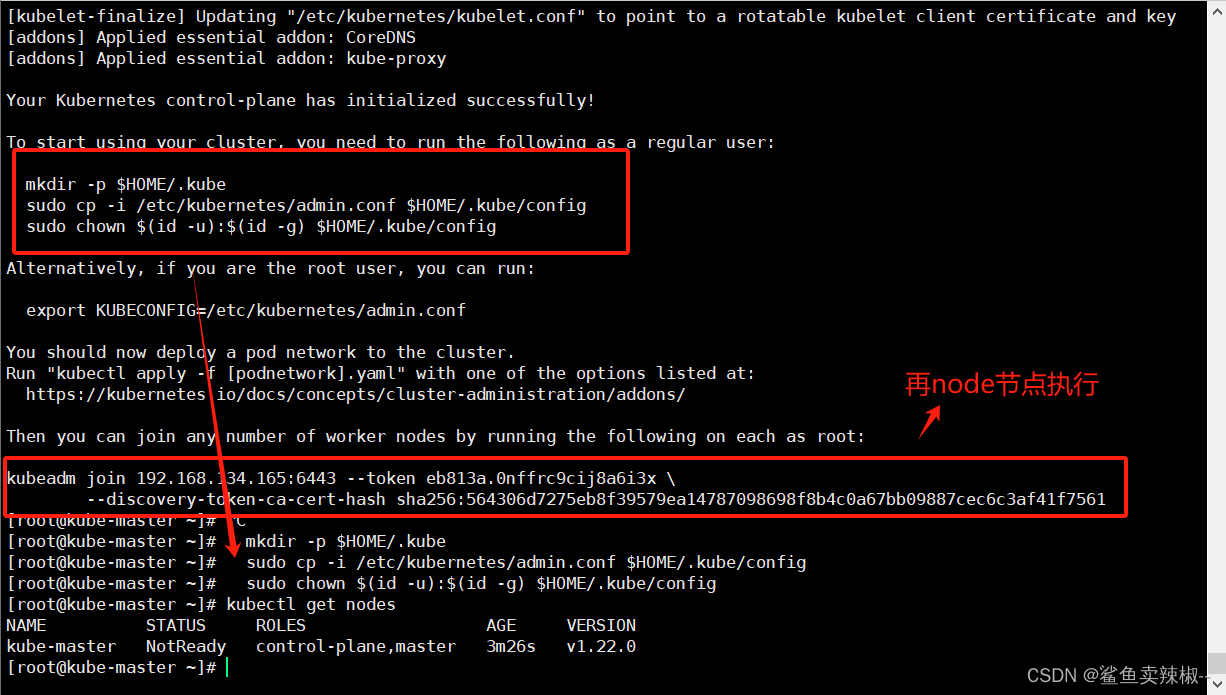
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.134.165:6443 --token eb813a.0nffrc9cij8a6i3x \
--discovery-token-ca-cert-hash sha256:564306d7275eb8f39579ea14787098698f8b4c0a67bb09887cec6c3af41f7561上面记录了完成的初始化输出的内容,根据输出的内容基本上可以看出手动初始化安装一个Kubernetes集群所需要的关键步骤。
其中有以下关键内容:
[kubelet] 生成kubelet的配置文件”/var/lib/kubelet/config.yaml”
[certificates]生成相关的各种证书
[kubeconfig]生成相关的kubeconfig文件
[bootstraptoken]生成token记录下来,后边使用kubeadm join往集群中添加节点时会用到
配置使用kubectl
如下操作在master节点操作
[root@kube-master ~]# mkdir -p $HOME/.kube
[root@kube-master ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@kube-master ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config
8.node加入集群[node]
配置node节点加入集群:
如果报错开启ip转发:
# sysctl -w net.ipv4.ip_forward=1
在所有node节点操作,此命令为初始化master成功后返回的结果
[root@kube-node1 ~]# kubeadm join 192.168.134.165:6443 --token eb813a.0nffrc9cij8a6i3x \
> --discovery-token-ca-cert-hash sha256:564306d7275eb8f39579ea14787098698f8b4c0a67bb09887cec6c3af41f75619.配置使用网络插件[master]
#> 部署calico网络插件
curl -L https://docs.projectcalico.org/v3.22/manifests/calico.yaml -O
kubectl apply -f ?calico.yaml
# kubectl get pod -A
[root@kube-master ~]# kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-7c87c5f9b8-klb7d 1/1 Running 1 (3m41s ago) 28m
kube-system calico-node-4nkrw 1/1 Running 1 (3m41s ago) 28m
kube-system calico-node-hdlqc 1/1 Running 0 27m
kube-system calico-node-pxrbf 1/1 Running 0 27m
kube-system coredns-78fcd69978-6ncn4 1/1 Running 1 (3m41s ago) 29m
kube-system coredns-78fcd69978-m742f 1/1 Running 1 (3m41s ago) 29m
kube-system etcd-kube-master 1/1 Running 2 (3m41s ago) 29m
kube-system kube-apiserver-kube-master 1/1 Running 2 (3m41s ago) 29m
kube-system kube-controller-manager-kube-master 1/1 Running 2 (3m41s ago) 29m
kube-system kube-proxy-4c98v 1/1 Running 0 25m
kube-system kube-proxy-fngss 1/1 Running 0 27m
kube-system kube-proxy-kfp5w 1/1 Running 1 (3m41s ago) 29m
kube-system kube-scheduler-kube-master 1/1 Running 2 (3m41s ago) 29m
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- CC工具箱使用指南:【更改字段别名(属性映射)】
- 网上书店(JSP+java+springmvc+mysql+MyBatis)
- 在未来的一个时期,阿里将会和AI电商联系在一起
- request entity too large
- 跨平台设备管理方案Selenium Grid
- 状态的一致性和FlinkSQL
- python基础教程七(布尔类型,条件语句,断言)
- 家用超声波清洗机哪些适合清洗眼镜?清洁效果好超声波清洗机推荐
- 虚幻UE 特效-Niagara特效实战-眩晕
- Linux curl命令详解,看这篇就够了