书生·浦语全链条开源开放体系
一、大模型的发展前景
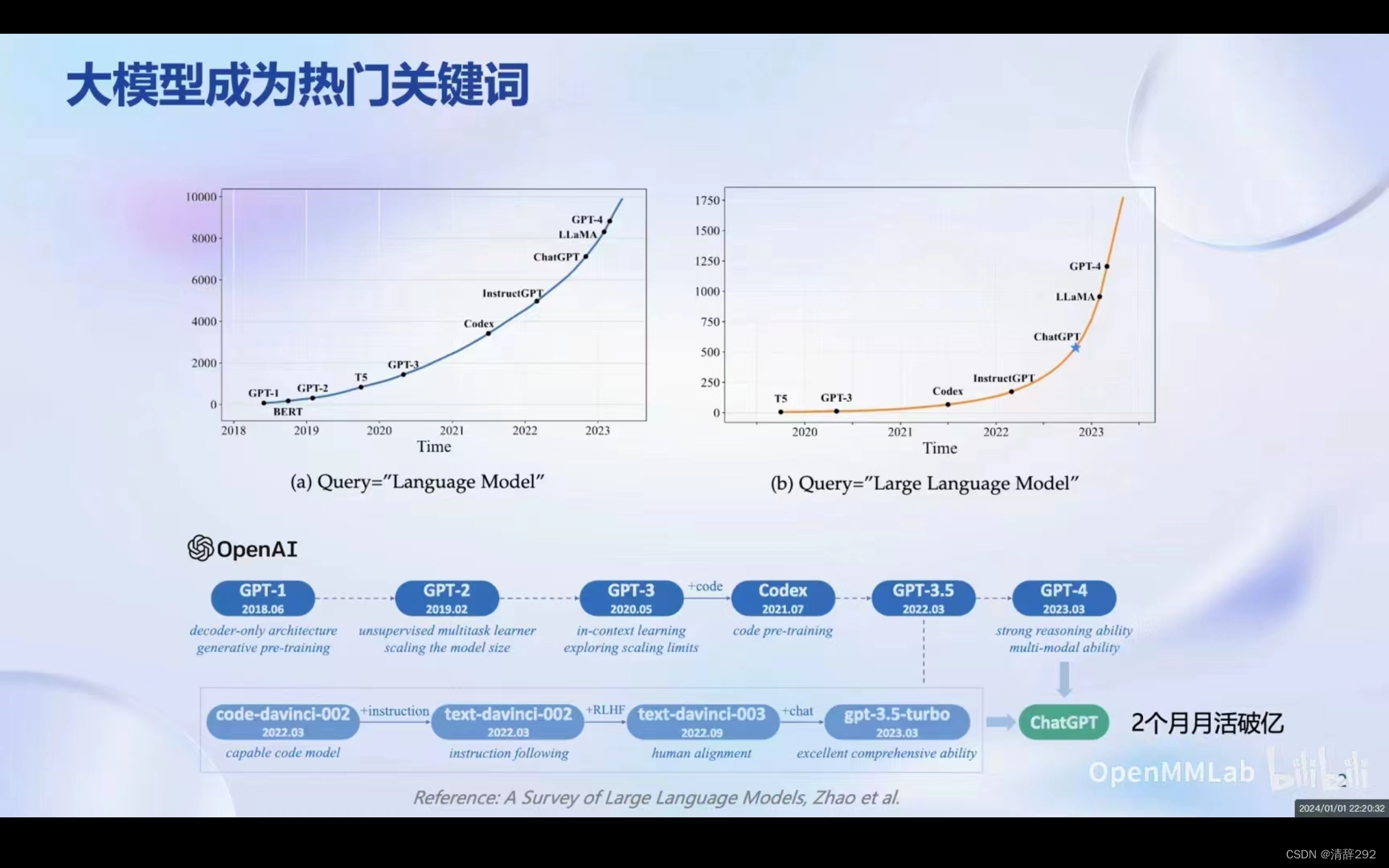
1. 大模型成为热门关键词
随着人工智能技术的不断进步,大型语言模型正成为研究的热点。从OpenAI GPT-3的模型到最近备受关注的ChatGPT,大型语言模型在不断进化,大型语言模型的关注度也在持续增长。随着技术的不断突破,大型语言模型的发展趋势将更加明显,为人工智能领域带来更多的创新和变革。
2.大模型成为发展通用人工智能的重要途经
专用大模型:针对特定任务进行训练,一个模型解决一个问题。
通用大模型:能够应对多种任务和模态,具有更强的泛化能力和更高的灵活性。
专用大模型和通用大模型各有其特点和应用场景。专用大模型针对特定任务进行优化,表现出色,但灵活性和泛化能力有限;而通用大模型旨在成为通用人工智能的重要途径,能够应对多种任务和模态,具有更强的泛化能力和更高的灵活性。随着技术的不断进步和研究的深入,通用大模型将越来越受到关注和应用,成为人工智能领域的发展趋势。

二、书生·浦语大模型系列
?该图片信息主要展示了三个不同规模的模型系列(书生-滴灌大模型系列、以太坊2.0书生-滴灌大模型系列和微众银行书生-滴灌大模型系列)以及它们在不同维度上的特点和能力。这些模型在参数规模、训练数据、语境长度、应用场景等方面展现了不同的优势和适用性。

三、从模型到应用?
在“模型选型”流程中,首先需要进行模型的评估,这涉及到对不同模型的性能和适用性的评估。接着,需要分析业务场景的复杂度,如果场景复杂,可能需要进行全参数调优。然后,需要将数据集划分为训练集和验证集,以便于模型的训练和验证。最后,根据评估结果和业务需求选择合适的模型,可以选择已经训练好的模型或者自行训练模型。
在“模型应用”流程中,首先需要进行模型的部署,包括模型剪枝、模型融合等操作,以适应实际应用。接着,需要使用OpenMMLab工具对模型进行实时监控,确保模型在复杂环境中稳定运行。然后,可以根据实际应用效果调整模型的超参数,优化模型性能。最后,如果业务场景发生变化或模型出现性能下降,可能需要重新训练或进行全参数微调。

?四、全链条开源开放体系
1.数据
多模态融合是指将不同类型的数据进行整合和处理,包括书籍、文档、图像和视频等,旨在提供全面的信息和资源支持。这种融合方式能够充分利用不同模态的数据特点,提升模型训练和应用的效果。
精细化处理是指对数据进行深入分析和处理,以满足模型训练和应用的需求。
价值观对齐是指在对数据进行处理和应用时,要符合主流的价值观和道德标准。

2.预训练?
- 高可扩展:支持从8卡到千卡(干卡)训练。
- 吞吐量:每秒512个token/GPU。
- 算法:预训练微调,加速效率达92%。
- 技术优势:使用Megatron-1774、DeepSpeed进行极致性能优化,浦语训练框架提供3835个训练优势。
- HybridZero技术:提供高性能和多种并行策略。
- Transformer计算库:极致优化,加速50%。
- 兼容性:与主流Megatron-DeepSpeed通信/计算调度、梯度累积算法无缝接入HuggingFace等1.50技术生态。
- 轻量化技术支持:支持各类轻量化1.00技术。
- 开箱即用:显存管理优化器状态、梯度参数支持多种规格语言模型,修改配置即可训练
- OpenMMLab:提供技术和应用支持。

3.微调?
全链条开源开放体系|微调:
- 高效微调框架XTuner,适配多种生态、任务类型、数据格式、训练引擎,支持算法加载。
- 覆盖各类SFT场景,包括InternLMLlamaQWenBaiChuanChatGLM。
- 支持微调增量预训练、MOSS、DeepSpeed、ZeRO、LoRA微调指令等。
- 自动优化加速,提供全量参数微调工具类指令。
- 适配多种硬件,包括消费级显卡、数据中心等,最低只需8GB显存即可微调7B模型。
- 由OpenMMLab提供技术支持和应用方案。

?4.评测
在当今的开源世界,软件的质量、性能以及是否符合特定的行业标准变得至关重要。为了提供一个全面、可靠的开源软件评价体系,OpenCompass开源评价平台应运而生。以下是OpenCompass架构的四个核心部分,分别为工具层、方法层、能力层和模型层。
工具层:这一层主要涉及分布式评测提示词工程评测数据库上报评测榜单发布评测报告生成等工具,为评价工作提供必要的支持。这些工具旨在简化评价流程,提高评价的准确性和效率。
方法层:在OpenCompass中,方法层涵盖了自动化客观评测、基于模型辅助的主观评测以及基于人类反馈的主观评测。这些方法不仅确保了评价的客观性和准确性,同时也考虑到了主观因素,使得评价更为全面。
能力层:这一层主要关注通用能力和特色能力。前者包括学科语言知识理解、推理、安全等核心能力,而后者则针对特定领域或应用进行优化。通过这种分层设计,OpenCompass能够灵活地满足不同领域和行业的需求。
模型层:基座模型、对话模型等都是OpenCompass的底层模型。这些模型在各种实际应用中进行了充分验证,能够为上层评价提供稳定、可靠的数据支持。

?5.?部署
全链条开源开放体系在部署大语言模型时面临技术挑战。由于模型内存开销巨大,需要庞大的参数量,同时还需要优化推理计算和访存。此外,动态Shape也是一个技术难点,需要解决如何加速token的生成速度。为了有效管理和利用内存,需要解决如何有效管理和利用内存的问题。最后,OpenMMLab Sili提供了一些解决方案来提升系统整体吞吐量并降低请求的平均响应时间。

?6.智能体
这是一个关于全链条开源开放体系的介绍。其中提到了智能体这一项,并指出智能体框架Lagent支持多种类型的智能体能力,可以灵活支持多种大语言模型,如ReAct、ReWoo、AutoGPT、GPT-3.5/4、InternLM等。此外,该框架还提供了输入、Hugging Face、Llama、Transformers等选择工具,并计划拆分人工干预,实现简单易拓展,支持丰富的工具执行。此外,该体系还提供了文生图搜索、出行API、条件计划执行、文生语音计算器、财经API等多种API接口,以及图片描述、代码解释器、体育资讯等API服务。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 触摸屏监控双速电动机-任务要求
- 推荐一款开源软件Easy-Sharing
- 5分钟更新你的图像处理小技巧(1)opencv旋转矩阵的不同之处
- Multimodal Transformer for Unaligned Multimodal Language Sequences
- C#编程-实现多线程
- python蓝桥杯备考——字符串小知识点
- 设计模式篇章(3)——七种结构型模式
- 函数式编程 - 组合compose的使用方法
- C++学习笔记(二十二)
- 【python自动化系列01】Openpyxl,操作Excel文件的利器