Dify学习笔记-模型配置(五)
1、接入 Hugging Face 上的开源模型
Dify 支持 Text-Generation 和 Embeddings,以下是与之对应的 Hugging Face 模型类型:
- Text-Generation:text-generation,text2text-generation
- Embeddings:feature-extraction
具体步骤如下:
- 你需要有 Hugging Face 账号(注册地址)。
- 设置 Hugging Face 的 API key(获取地址)。
- 进入 Hugging Face 模型列表页,选择对应的模型类型。
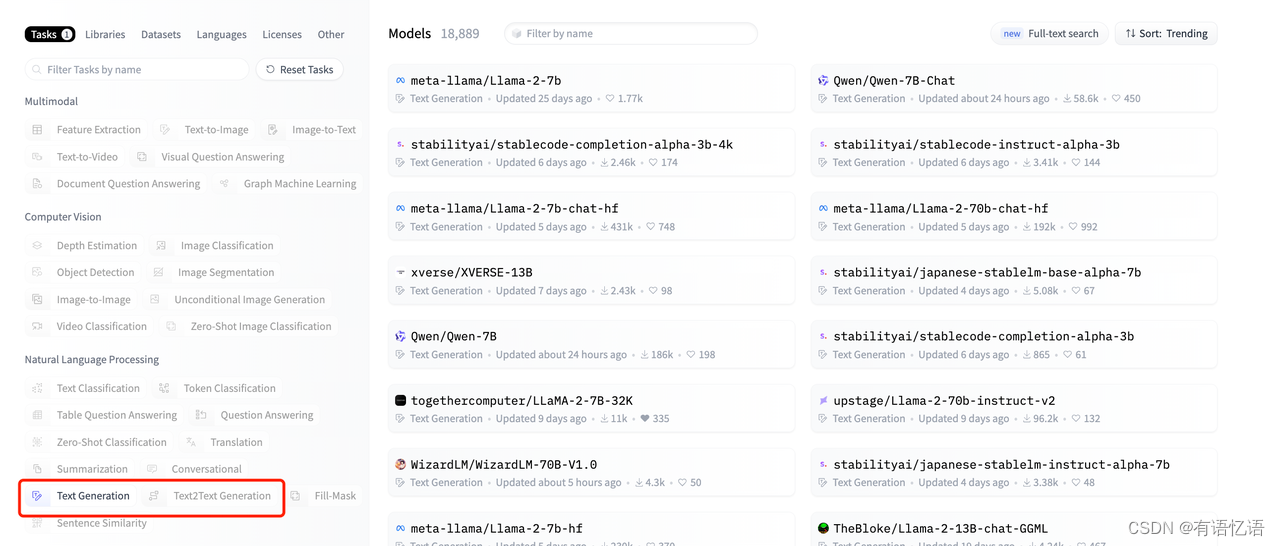
Dify 支持用两种方式接入 Hugging Face 上的模型:
- Hosted Inference API。这种方式是用的 Hugging Face 官方部署的模型。不需要付费。但缺点是,只有少量模型支持这种方式。
- Inference Endpoint。这种方式是用 Hugging Face 接入的 AWS 等资源来部署模型,需要付费。
1.1、接入 Hosted Inference API 的模型
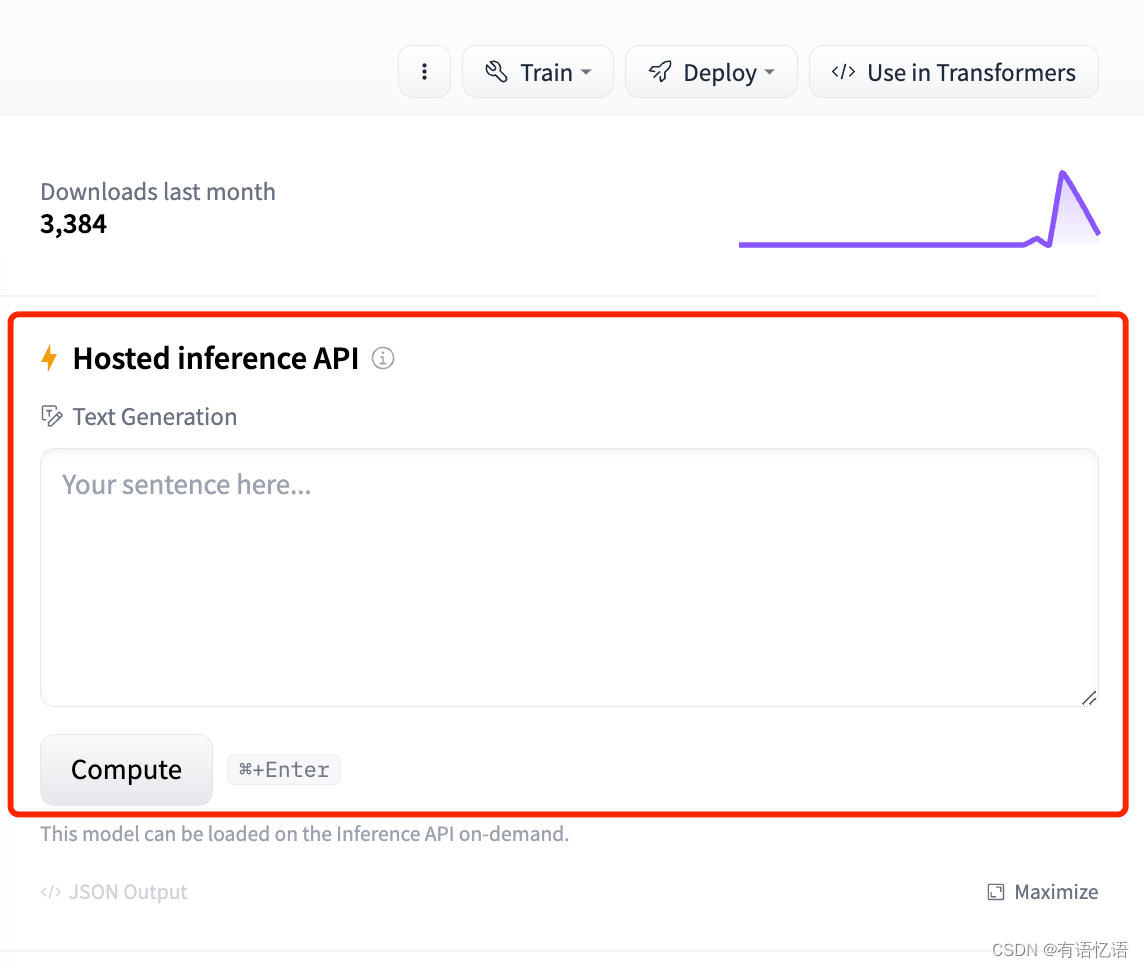
1 选择模型
模型详情页右侧有包含 Hosted inference API 的 区域才支持 Hosted inference API 。如下图所:
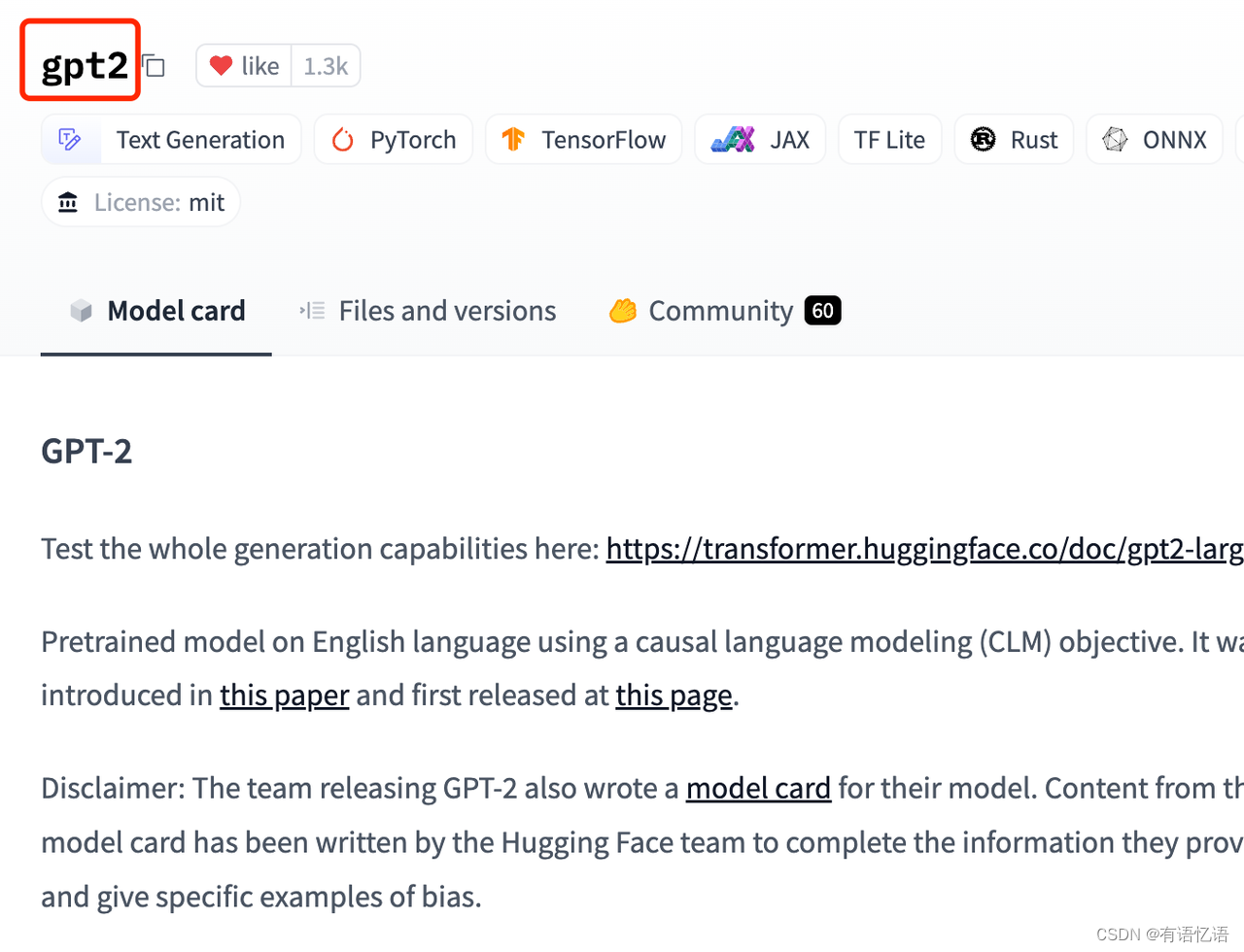
在模型详情页,可以获得模型的名称。
2 在 Dify 中使用接入模型
在 设置 > 模型供应商 > Hugging Face > 模型类型 的 Endpoint Type 选择 Hosted Inference API。如下图所示:
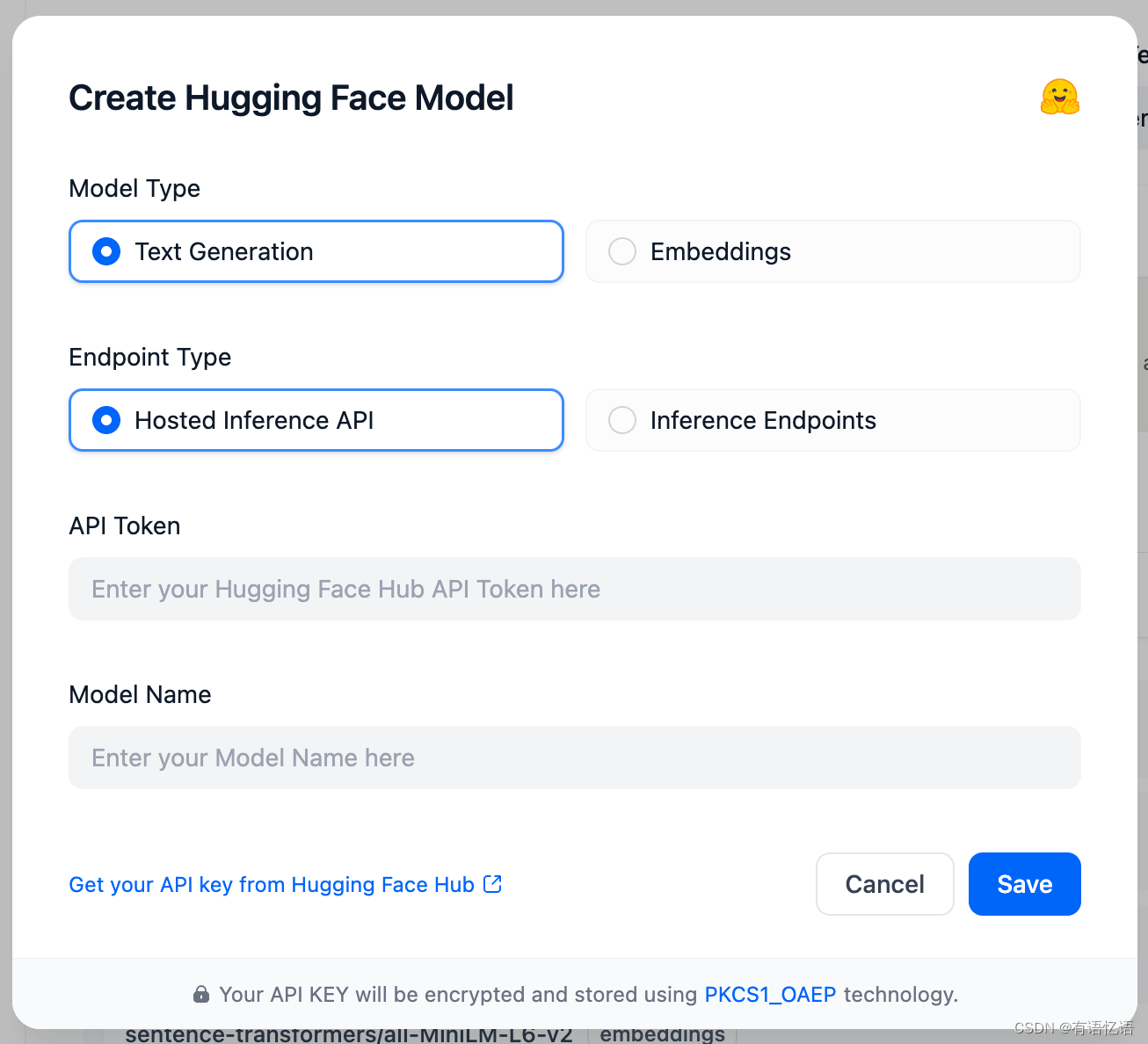
API Token 为文章开头设置的 API Key。模型名字为上一步获得的模型名字。
1.2、方式 2: Inference Endpoint
1 选择要部署模型
模型详情页右侧的 Deploy 按钮下有 Inference Endpoints 选项的模型才支持 Inference Endpoint。如下图所示:
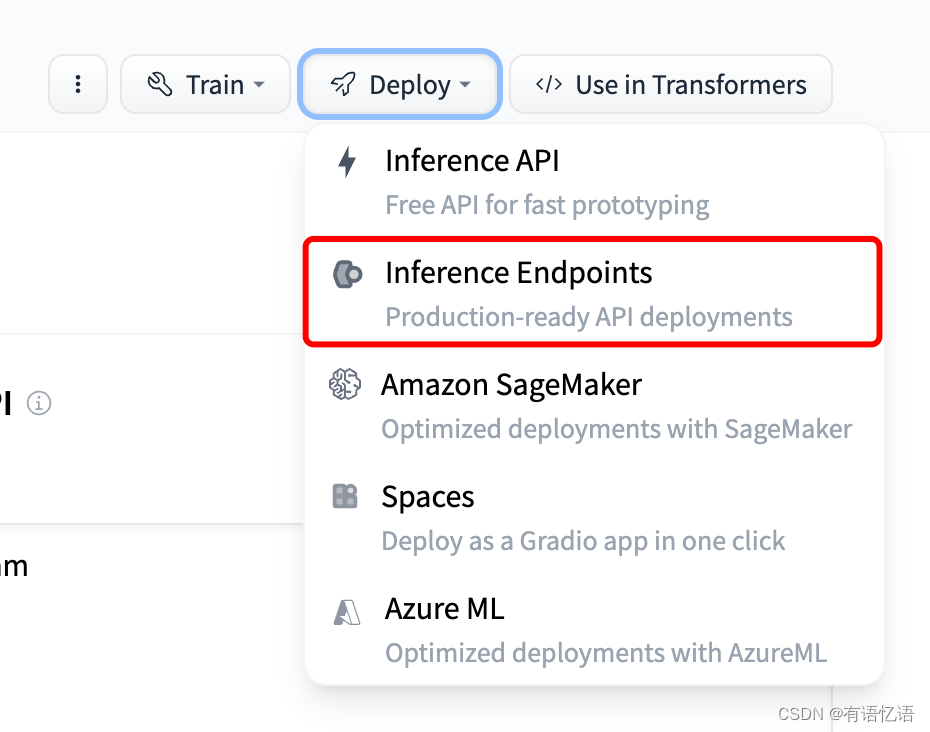
2 部署模型
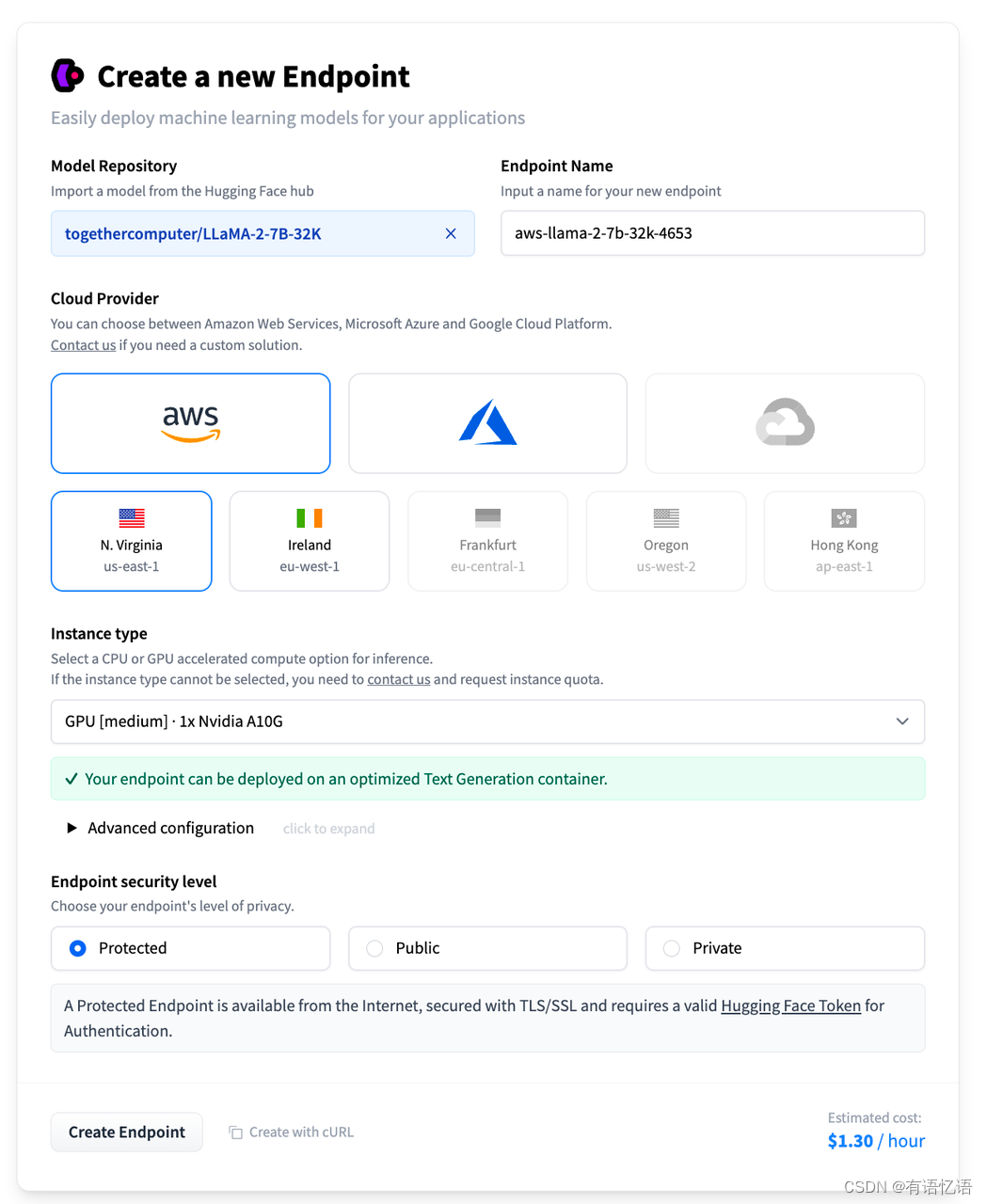
点击模型的部署按钮,选择 Inference Endpoint 选项。如果之前没绑过银行卡的,会需要绑卡。按流程走即可。绑过卡后,会出现下面的界面:按需求修改配置,点击左下角的 Create Endpoint 来创建 Inference Endpoint。
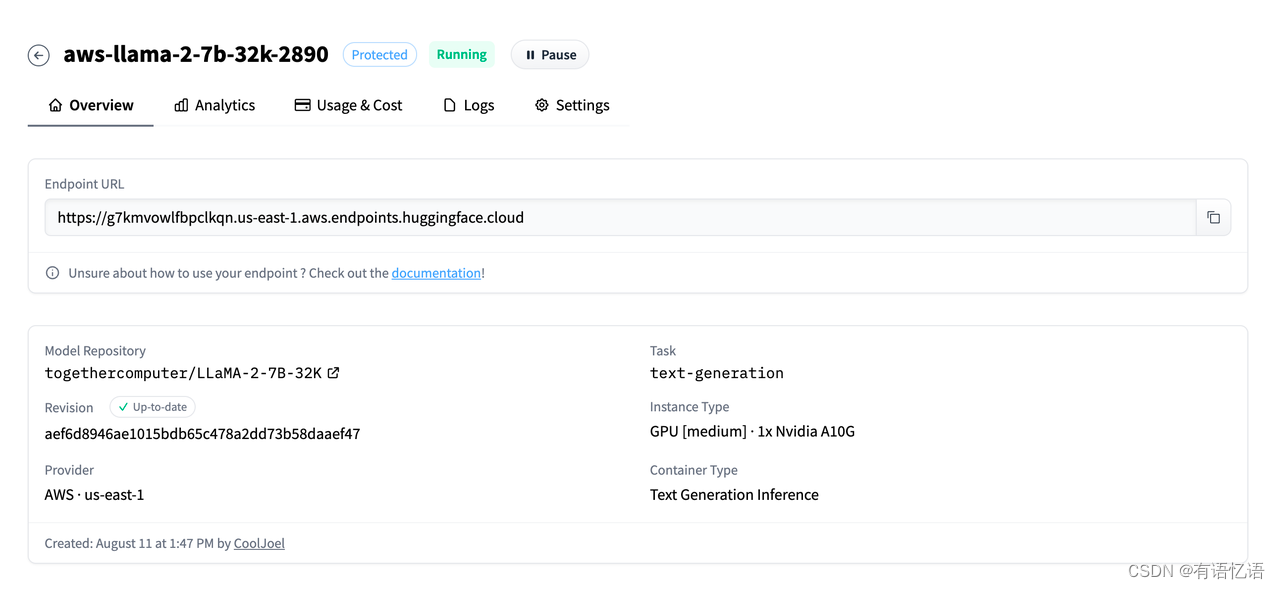
模型部署好后,就可以看到 Endpoint URL。
3 在 Dify 中使用接入模型
在 设置 > 模型供应商 > Hugging Face > 模型类型 的 Endpoint Type 选择 Inference Endpoints。如下图所示:
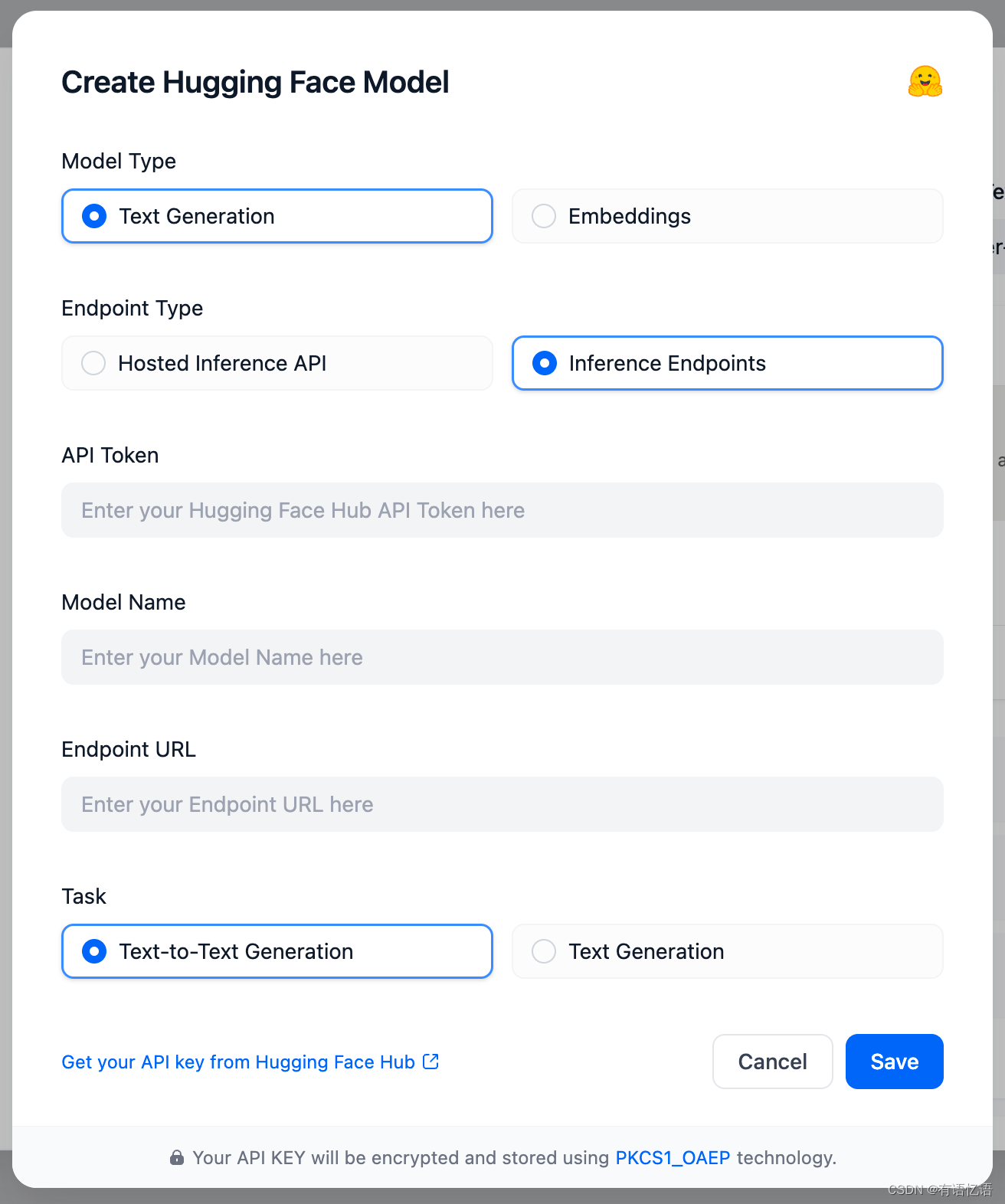
API Token 为文章开头设置的 API Key。Text-Generation 模型名字随便起,Embeddings 模型名字需要跟 Hugging Face 的保持一致。Endpoint URL 为 上一步部署模型成功后获得的 Endpoint URL。
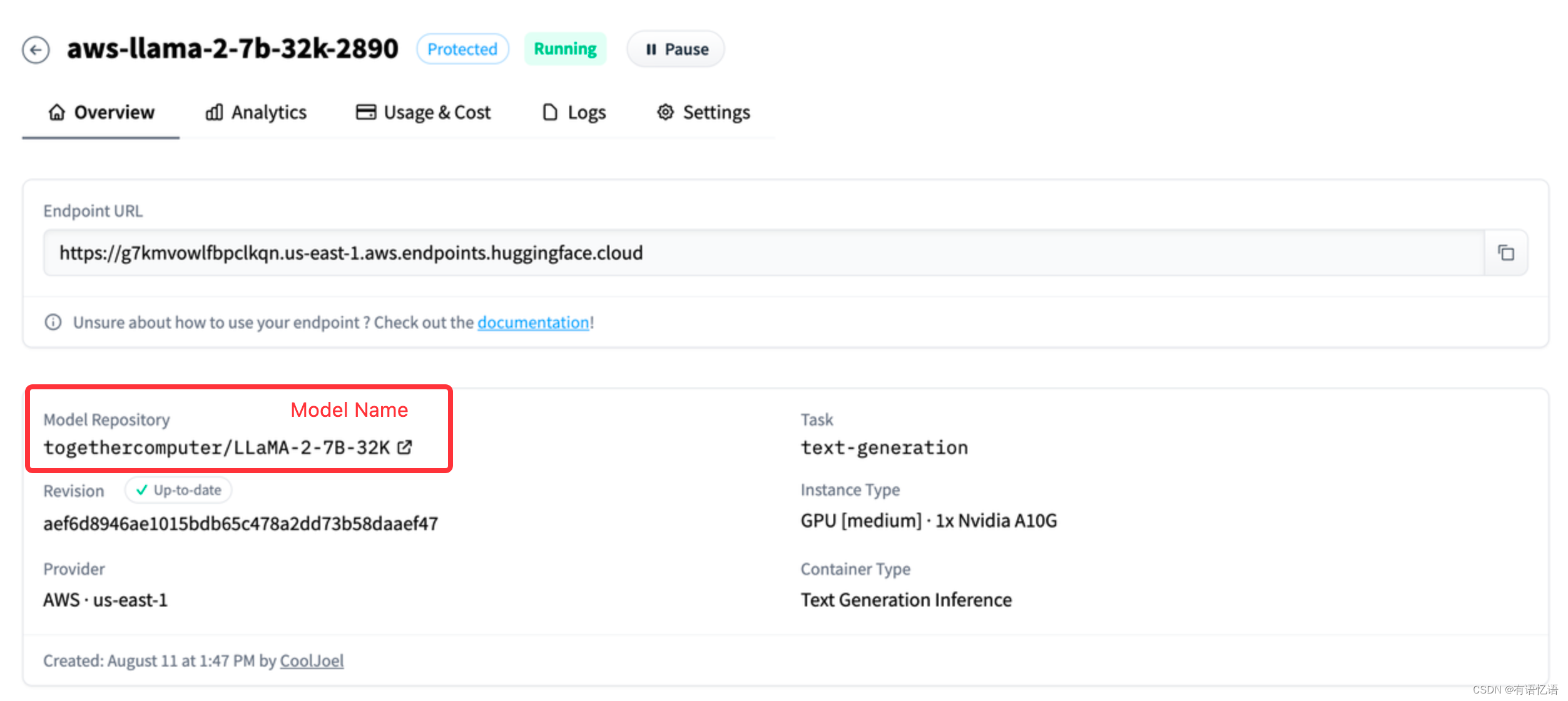
注意:Embeddings 的「用户名 / 组织名称」,需要根据你在 Hugging Face 的 Inference Endpoints 部署方式,来填写「用户名」或者「组织名称」。
2、接入 Replicate 上的开源模型
Dify 支持接入 Replicate 上的 Language models 和 Embedding models。Language models 对应 Dify 的推理模型,Embedding models 对应 Dify 的 Embedding 模型。
具体步骤如下:
- 你需要有 Replicate 的账号(注册地址)。
- 获取 API Key(获取地址)。
- 挑选模型。在 Language models 和 Embedding models 下挑选模型。
- 在 Dify 的 设置 > 模型供应商 > Replicate 中添加模型。
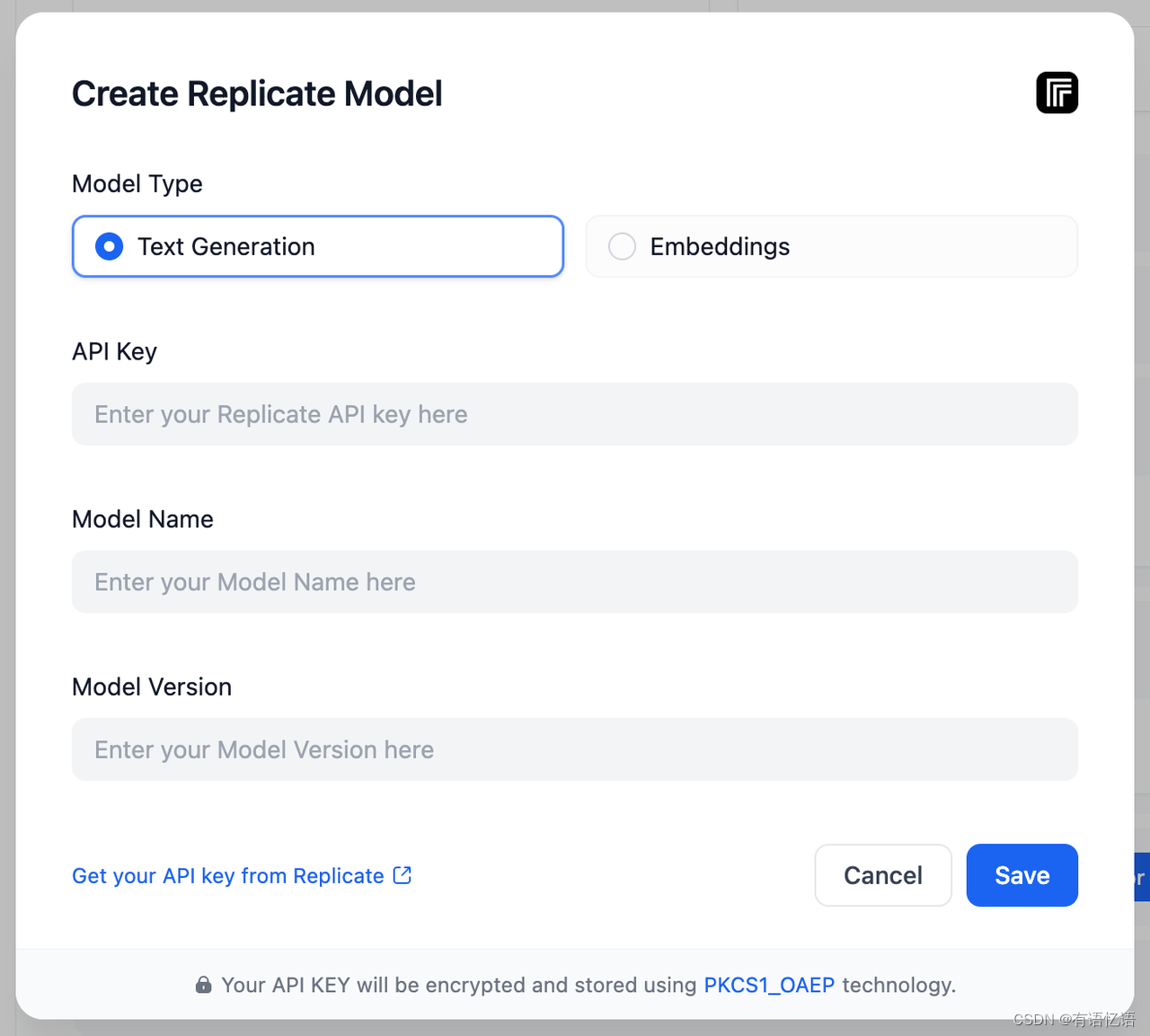
API key 为第 2 步中设置的 API Key。Model Name 和 Model Version 可以在模型详情页中找到:

3、接入 Xinference 部署的本地模型
Xorbits inference 是一个强大且通用的分布式推理框架,旨在为大型语言模型、语音识别模型和多模态模型提供服务,甚至可以在笔记本电脑上使用。它支持多种与GGML兼容的模型,如 chatglm, baichuan, whisper, vicuna, orca 等。 Dify 支持以本地部署的方式接入 Xinference 部署的大型语言模型推理和 embedding 能力。
部署 Xinference
开始部署
部署 Xinference 有两种方式,分别为本地部署和分布式部署,以下以本地部署为例。
- 首先通过 PyPI 安装 Xinference:
$ pip install "xinference[all]"
- 本地部署方式启动 Xinference:
$ xinference-local
2023-08-20 19:21:05,265 xinference 10148 INFO Xinference successfully started. Endpoint: http://127.0.0.1:9997
2023-08-20 19:21:05,266 xinference.core.supervisor 10148 INFO Worker 127.0.0.1:37822 has been added successfully
2023-08-20 19:21:05,267 xinference.deploy.worker 10148 INFO Xinference worker successfully started.
Xinference 默认会在本地启动一个 worker,端点为:http://127.0.0.1:9997,端口默认为 9997。 默认只可本机访问,可配置 -H 0.0.0.0,非本地客户端可任意访问。 如需进一步修改 host 或 port,可查看 xinference 的帮助信息:xinference-local --help。
使用 Dify Docker 部署方式的需要注意网络配置,确保 Dify 容器可以访问到 Xinference 的端点,Dify 容器内部无法访问到 localhost,需要使用宿主机 IP 地址。
- 创建并部署模型
进入 http://127.0.0.1:9997 选择需要部署的模型和规格进行部署,如下图所示:

由于不同模型在不同硬件平台兼容性不同,请查看 Xinference 内置模型 确定创建的模型是否支持当前硬件平台。
4. 获取模型 UID
从上图所在页面获取对应模型的 ID,如:2c886330-8849-11ee-9518-43b0b8f40bea
5. 模型部署完毕,在 Dify 中使用接入模型
在 设置 > 模型供应商 > Xinference 中填入:
- 模型名称:vicuna-v1.3
- 服务器 URL:http://<Machine_IP>:9997 替换成您的机器 IP 地址
- 模型 UID:2c886330-8849-11ee-9518-43b0b8f40bea
“保存” 后即可在应用中使用该模型。
Dify 同时支持将 Xinference embed 模型 作为 Embedding 模型使用,只需在配置框中选择 Embeddings 类型即可。
如需获取 Xinference 更多信息,请参考:Xorbits Inference
4、接入 OpenLLM 部署的本地模型
使用 OpenLLM, 您可以针对任何开源大型语言模型进行推理,部署到云端或本地,并构建强大的 AI 应用程序。 Dify 支持以本地部署的方式接入 OpenLLM 部署的大型语言模型的推理能力。
4.1、部署 OpenLLM 模型
开始部署
您可以通过以下方式部署:
docker run --rm -it -p 3333:3000 ghcr.io/bentoml/openllm start facebook/opt-1.3b --backend pt
注意:此处使用 facebook/opt-1.3b 模型仅作为示例,效果可能不佳,请根据实际情况选择合适的模型,更多模型请参考:支持的模型列表。
模型部署完毕,在 Dify 中使用接入模型
在 设置 > 模型供应商 > OpenLLM 中填入:
- 模型名称:facebook/opt-1.3b
- 服务器 URL:http://<Machine_IP>:3333 替换成您的机器 IP 地址 “保存” 后即可在应用中使用该模型。
本说明仅作为快速接入的示例,如需使用 OpenLLM 更多特性和信息,请参考:OpenLLM
5、接入 LocalAI 部署的本地模型
LocalAI 是一个本地推理框架,提供了 RESTFul API,与 OpenAI API 规范兼容。它允许你在消费级硬件上本地或者在自有服务器上运行 LLM(和其他模型),支持与 ggml 格式兼容的多种模型家族。不需要 GPU。 Dify 支持以本地部署的方式接入 LocalAI 部署的大型语言模型推理和 embedding 能力。
部署 LocalAI
使用前注意事项
如果确实需要直接使用容器的 IP 地址,以上步骤将帮助您获取到这一信息。
开始部署
可参考官方 Getting Started 进行部署,也可参考下方步骤进行快速接入:
(以下步骤来自 LocalAI Data query example)
- 首先拉取 LocalAI 代码仓库,并进入指定目录
$ git clone https://github.com/go-skynet/LocalAI
$ cd LocalAI/examples/langchain-chroma
- 下载范例 LLM 和 Embedding 模型
$ wget https://huggingface.co/skeskinen/ggml/resolve/main/all-MiniLM-L6-v2/ggml-model-q4_0.bin -O models/bert
$ wget https://gpt4all.io/models/ggml-gpt4all-j.bin -O models/ggml-gpt4all-j
这里选用了较小且全平台兼容的两个模型,ggml-gpt4all-j 作为默认 LLM 模型,all-MiniLM-L6-v2 作为默认 Embedding 模型,方便在本地快速部署使用。
- 配置 .env 文件
$ mv .env.example .env
- 启动 LocalAI
# start with docker-compose
$ docker-compose up -d --build
# tail the logs & wait until the build completes
$ docker logs -f langchain-chroma-api-1
7:16AM INF Starting LocalAI using 4 threads, with models path: /models
7:16AM INF LocalAI version: v1.24.1 (9cc8d9086580bd2a96f5c96a6b873242879c70bc)
┌───────────────────────────────────────────────────┐
│ Fiber v2.48.0 │
│ http://127.0.0.1:8080 │
│ (bound on host 0.0.0.0 and port 8080) │
│ │
│ Handlers ............ 55 Processes ........... 1 │
│ Prefork ....... Disabled PID ................ 14 │
└───────────────────────────────────────────────────┘
开放了本机 http://127.0.0.1:8080 作为 LocalAI 请求 API 的端点。
并提供了两个模型,分别为:
- LLM 模型:ggml-gpt4all-j
对外访问名称:gpt-3.5-turbo(该名称可自定义,在 models/gpt-3.5-turbo.yaml 中配置。 - Embedding 模型:all-MiniLM-L6-v2
对外访问名称:text-embedding-ada-002(该名称可自定义,在 models/embeddings.yaml 中配置。
使用 Dify Docker 部署方式的需要注意网络配置,确保 Dify 容器可以访问到 Xinference 的端点,Dify
容器内部无法访问到 localhost,需要使用宿主机 IP 地址。
- LocalAI API 服务部署完毕,在 Dify 中使用接入模型
在 设置 > 模型供应商 > LocalAI 中填入:
模型 1:ggml-gpt4all-j
- 模型类型:文本生成
- 模型名称:gpt-3.5-turbo
- 服务器 URL:http://127.0.0.1:8080
若 Dify 为 docker 部署,请填入 host 域名:http://:8080,可填写局域网 IP 地址,如:http://192.168.1.100:8080
“保存” 后即可在应用中使用该模型。
模型 2:all-MiniLM-L6-v2 - 模型类型:Embeddings
- 模型名称:text-embedding-ada-002
- 服务器 URL:http://127.0.0.1:8080
若 Dify 为 docker 部署,请填入 host 域名:http://:8080,可填写局域网 IP 地址,如:http://192.168.1.100:8080
“保存” 后即可在应用中使用该模型。
如需获取 LocalAI 更多信息,请参考:https://github.com/go-skynet/LocalAI
6、接入 Ollama 部署的本地模型
Ollama 是一个本地推理框架客户端,可一键部署如 Llama 2, Mistral, Llava 等大型语言模型。 Dify 支持接入 Ollama 部署的大型语言模型推理和 embedding 能力。
快速接入
下载并启动 Ollama
- 下载 Ollama
访问 https://ollama.ai/download,下载对应系统 Ollama 客户端。 - 运行 Ollama 并与 Llava 聊天
ollama run llava
启动成功后,ollama 在本地 11434 端口启动了一个 API 服务,可通过 http://localhost:11434 访问。
其他模型可访问 Ollama Models 了解详情。 - 在 Dify 中接入 Ollama
在 设置 > 模型供应商 > Ollama 中填入:
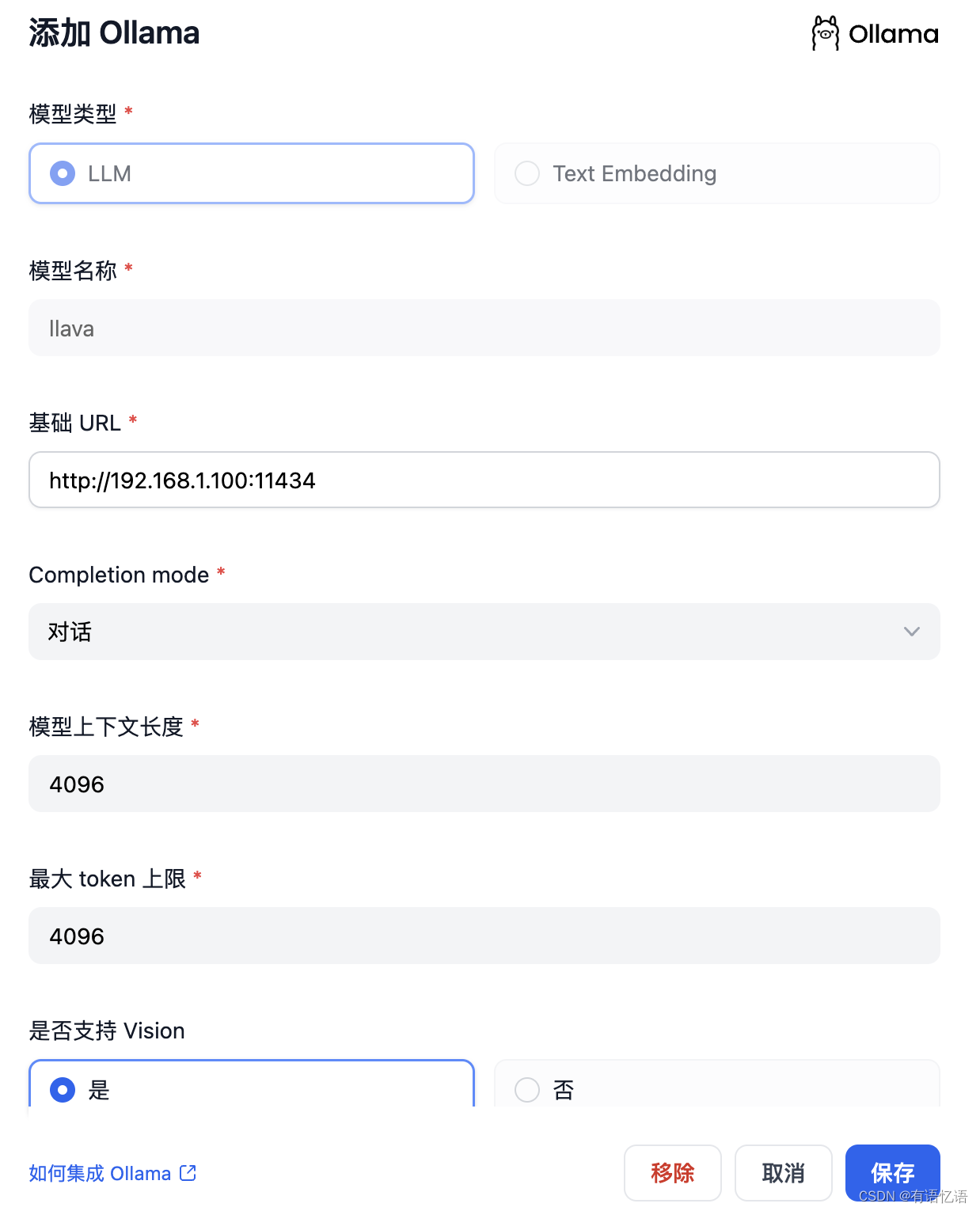
模型名称:llava
基础 URL:http://:11434
此处需填写可访问到的 Ollama 服务地址。
若 Dify 为 docker 部署,建议填写局域网 IP 地址,如:http://192.168.1.100:11434 或 docker 宿主机 IP 地址,如:http://172.17.0.1:11434。
若为本地源码部署,可填写 http://localhost:11434。
模型类型:对话
模型上下文长度:4096
模型的最大上下文长度,若不清楚可填写默认值 4096。
最大 token 上限:4096
模型返回内容的最大 token 数量,若模型无特别说明,则可与模型上下文长度保持一致。
是否支持 Vision:是
当模型支持图片理解(多模态)勾选此项,如 llava。
点击 “保存” 校验无误后即可在应用中使用该模型。
Embedding 模型接入方式与 LLM 类似,只需将模型类型改为 Text Embedding 即可。
4. 使用 Ollama 模型
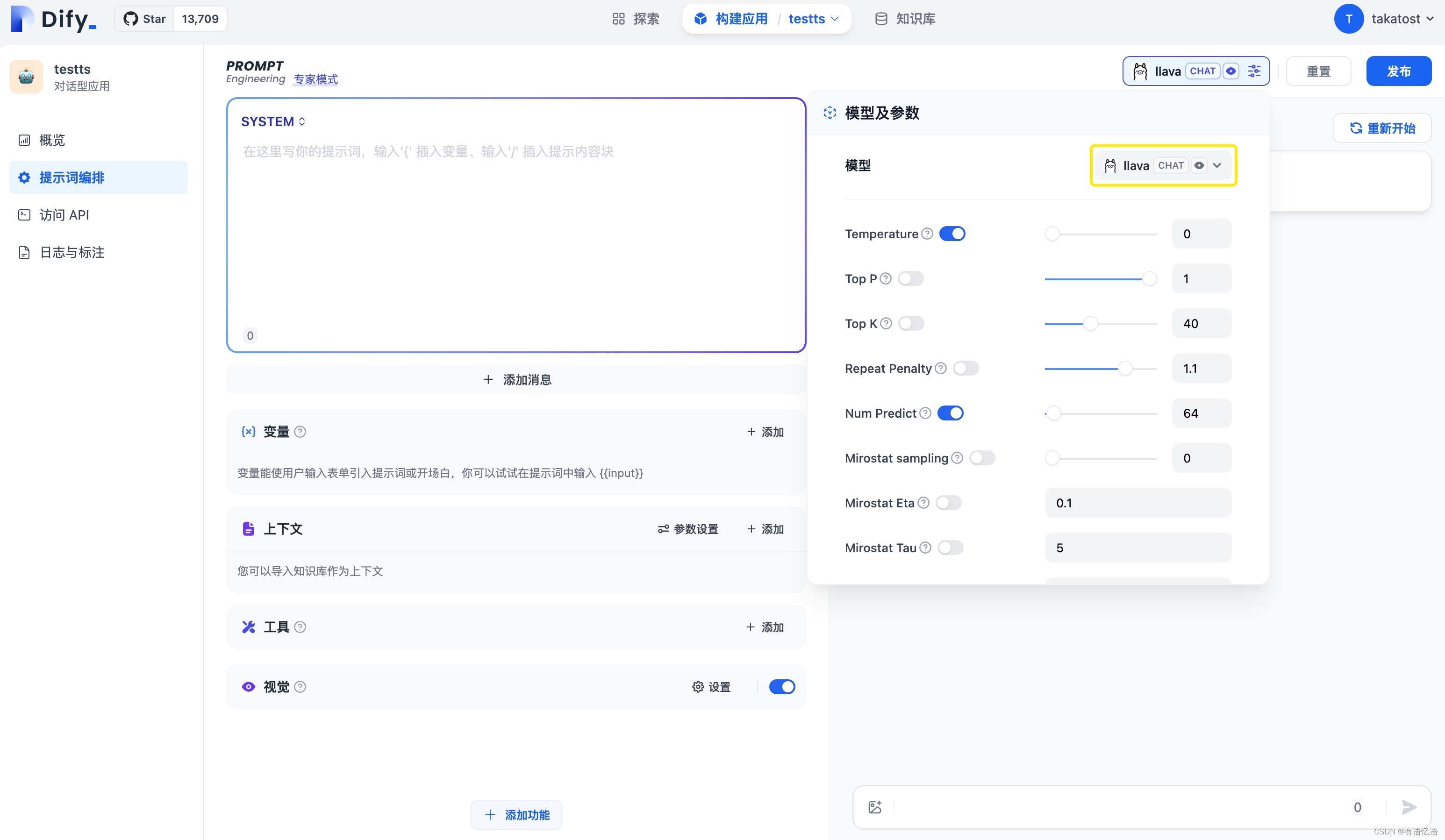
进入需要配置的 App 提示词编排页面,选择 Ollama 供应商下的 llava 模型,配置模型参数后即可使用。
如需获取 Ollama 更多信息,请参考:https://github.com/jmorganca/ollama
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 无脑学习更高效 最后几天,冲冲冲背完,干就完了。重复练习和肌肉记忆扮演重要角色 大量的听力和口语练习通常比单纯的语法分析更有效
- 特产零售元宇宙
- Word2Vector介绍
- C++基础-内存模型详解
- 护眼台灯哪个牌子好?书客、明基、飞利浦横向对比测评
- 数据结构与算法教程,数据结构C语言版教程!(第五部分、数组和广义表详解)三
- 基于JavaServerlet +Jsp的学生成绩管理系统(有部署视频和演示视频、Java毕业设计)
- 第38节: Vue3 鼠标按钮修改器
- 手把手带你死磕ORBSLAM3源代码(四十六) Tracking.cc Reset
- 考古学家 - 华为OD统一考试