应用实践|基于Python手把手教你实现雪花算法

📫 作者简介:「六月暴雪飞梨花」,专注于研究Java,就职于科技型公司后端工程师
🏆 近期荣誉:华为云云享专家、阿里云专家博主、
🔥 三连支持:欢迎 ??关注、👍点赞、👉收藏三连,支持一下博主~
文章目录
概述
分布式策略ID的主要应用在互联网网站、搜索引擎、社交媒体、在线购物、金融、大数据处理、日志场景中,这些应用需要支持大量的并发请求和用户访问,分布式ID策略可以通过请求分发到不同的服务器节点来做计算,以提高服务的响应速度和可用性。
常见的分布式ID生成策略:
● UUID(Universally Unique Identifier)
● 雪花算法(Snowflake)
● Redis原子自增
● 基于数据库的自增主键(有些数据库不支持自增主键)
● 取当前毫秒数
本文主要简单介绍下雪花ID算法(Snowflake)的Python语言的计算方法。

雪花算法(Snowflake)是 Twitter 开源的分布式ID生成算法。雪花ID,或称雪花,是分布式计算中使用的唯一标识符的一种形式。该格式由Twitter创建,用于推文的ID。人们普遍认为,每片雪花都有唯一的结构,因此他们取了“雪花ID”这个名字。在当时Twitter的团队从MySQL转向Cassandra时,需要一种新的方法来生成ID号,而Cassandra中没有顺序ID生成工具,所以,应运而生雪花ID出现了。
雪花算法的相关知识可以参考Github:https://github.com/twitter-archive/snowflake/tree/b3f6a3c6ca8e1b6847baa6ff42bf72201e2c2231
什么是雪花ID
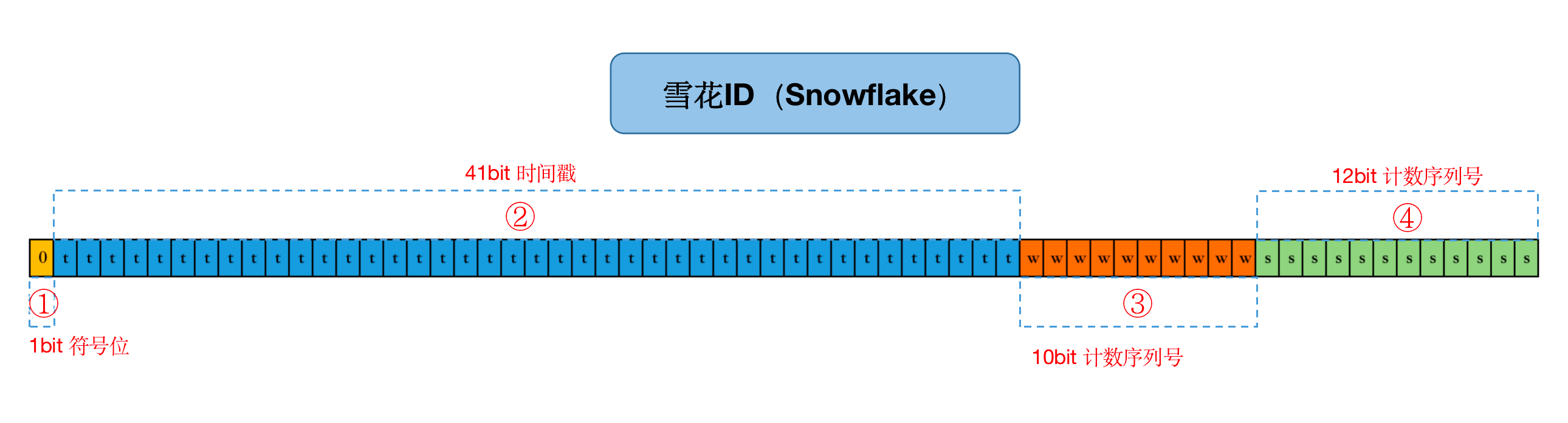
根据官方的介绍,雪花ID是由Twitter团队开发的一种分布式ID生成算法,它的设计目标是在分布式系统中生成唯一ID,具备趋势递增、高性能、可扩展等特点。其实雪花ID生成的唯一ID是由64位二进制数组成,结果是一个long型的ID。可以分解为四个部分:
● 1 符号位:符号位,也就是最高位,始终是0,没有任何意义,因为要是唯一计算机二进制补码中就是负数,0才是正数。
● 2 时间戳:占用41位,记录生成ID的时间戳,精确到毫秒级。
● 3 机器标识:占用10位,用于标识不同的机器。
● 4 计数序列号:占用12位,用于解决同一毫秒内生成多个ID的冲突。
Snowflake ID的结构可以用二进制格式表示如下:
0 1 41 51 64
+-----------------------------------------+------+-----------+
|0|timestamp (milliseconds since epoch) |worker| sequence |
+-----------------------------------------+------+-----------+
Snowflake ID的结构可以用图表示如下:
代码演示步骤
1 引入依赖库
使用Python标准库中的time模块来获取当前时间戳,并使用random模块来生成随机worker_id和data_center_id。
import time
import random
2 初始化参数
此处我们定义一个类Snowflake类,提前初始化机器标识ID、数据中心ID、计数序列号、时间戳。
def __init__(self, worker_id, data_center_id):
### 机器标识ID
self.worker_id = worker_id
### 数据中心ID
self.data_center_id = data_center_id
### 计数序列号
self.sequence = 0
### 时间戳
self.last_timestamp = -1
3 定义并实现
这是最重要的一个步骤,我们来实现一个生成ID的方法,这个方法根据雪花算法的规则生成唯一ID,具体的实现过程包括获取当前时间戳、判断是否为同一毫秒、更新序列号等。在next_id()方法中,我们首先获取当前时间戳,并检查是否比上一次生成ID的时间戳小。
(1)如果是,则抛出异常,因为这表示时钟回退。
(2)如果时间戳相同,则递增序列号,如果序列号达到最大值4095,则等待下一毫秒。如果时间戳不同,则重置序列号为0。
(3)最后,我们将生成的ID返回。
具体代码如下所示:
def next_id(self):
timestamp = int(time.time() * 1000)
if timestamp < self.last_timestamp:
raise Exception("Clock moved backwards. Refusing to generate id for %d milliseconds" % abs(timestamp - self.last_timestamp))
if timestamp == self.last_timestamp:
self.sequence = (self.sequence + 1) & 4095
if self.sequence == 0:
timestamp = self.wait_for_next_millis(self.last_timestamp)
else:
self.sequence = 0
self.last_timestamp = timestamp
return ((timestamp - 1288834974657) << 22) | (self.data_center_id << 17) | (self.worker_id << 12) | self.sequence
注意??:由于时间戳是以毫秒为单位的,所以每毫秒最多可以生成4096个ID。如果ID生成器的负载较高,可能会在同一毫秒内多次调用next_id()方法,导致序列号耗尽。为了避免这种情况,我们在等待下一毫秒时检查时间戳是否小于上一次生成ID的时间戳。如果是,则抛出异常,因为这表示时钟回退。
4 测试代码
在测试代码中,我们使用一个循环来生成10个唯一的ID,并打印出来。如果时钟回退,则会抛出一个异常并打印错误信息。
if __name__ == '__main__':
worker_id = 1
data_center_id = 1
snowflake = Snowflake(worker_id, data_center_id)
for i in range(10):
try:
print(snowflake.next_id())
except Exception as e:
print("Clock moved backwards:", e)
5 异常处理
通过上面几步我们已经实现了雪花ID的核心代码工作,但是为了确保算法的正确性和程序的严谨性,我们需要处理错误和边界情况,比如当同一毫秒内生成的ID超过序列号的最大值时,需要等待下一毫秒再生成。具体代码如下所示:
def wait_for_next_millis(self, last_timestamp):
timestamp = int(time.time() * 1000)
while timestamp <= last_timestamp:
timestamp = int(time.time() * 1000)
return timestamp
完整代码示例
接下来就来整合一下上面的分解步骤,这里将展示一个完整的Python语言代码示例,后面会展示运行的最终结果。示例代码将按照上面的步骤来实现雪花算法,并输出生成的唯一ID,下面就是完整的示例代码:
import time
import random
class Snowflake:
def __init__(self, worker_id, data_center_id):
### 机器标识ID
self.worker_id = worker_id
### 数据中心ID
self.data_center_id = data_center_id
### 计数序列号
self.sequence = 0
### 时间戳
self.last_timestamp = -1
def next_id(self):
timestamp = int(time.time() * 1000)
if timestamp < self.last_timestamp:
raise Exception("Clock moved backwards. Refusing to generate id for %d milliseconds" % abs(timestamp - self.last_timestamp))
if timestamp == self.last_timestamp:
self.sequence = (self.sequence + 1) & 4095
if self.sequence == 0:
timestamp = self.wait_for_next_millis(self.last_timestamp)
else:
self.sequence = 0
self.last_timestamp = timestamp
return ((timestamp - 1288834974657) << 22) | (self.data_center_id << 17) | (self.worker_id << 12) | self.sequence
def wait_for_next_millis(self, last_timestamp):
timestamp = int(time.time() * 1000)
while timestamp <= last_timestamp:
timestamp = int(time.time() * 1000)
return timestamp
### test
if __name__ == '__main__':
worker_id = 1
data_center_id = 1
snowflake = Snowflake(worker_id, data_center_id)
for i in range(10):
try:
print(snowflake.next_id())
except Exception as e:
print("Clock moved backwards:", e)
运行结果演示
通过上面完整示例代码运行之后,可以得到下面的运行结果,即输出生成的唯一ID。具体的运行结果如下所示:
[Running] python -u "/Users/Aion/WorkSpace/PythonSpace/Snowflow/Snowflow.py"
1742096523036069888
1742096523036069889
1742096523036069890
1742096523036069891
1742096523036069892
1742096523036069893
1742096523036069894
1742096523036069895
1742096523036069896
1742096523036069897
[Done] exited with code=0 in 0.057 seconds
问题分析
(1)第一位为什么不使用
在计算机的表示中,第一位是符号位,0表示整数,第一位如果是1则表示负数,我们用的ID默认就是正数,所以默认就是0,那么这一位默认就没有意义。
(2)机器位怎么用
机器位或者机房位,一共10 bit,如果全部表示机器,那么可以表示1024台机器,如果拆分,5 bit 表示机房,5bit表示机房里面的机器,那么可以有32个机房,每个机房可以用32台机器。
(3)时间戳比较
在获取时间戳小于上一次获取的时间戳的时候,不能生成ID,而是继续循环,直到生成可用的ID,这里没有使用拓展位防止时钟回拨。
结束语
其实对于分布式ID的生成策略。无论是我们上述提到的哪一种。无非需要具有以下两种特点:分布式、唯一。通过本文,可以快速了解雪花ID(雪花算法,SnowFlake),SnowFlake的优点是:
(1)单机上整体自增,集群上整体自增,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞;
(2)效率较高,经测试,SnowFlake每秒能够产生26万ID左右。
(3)强依赖性,依赖与系统时间的一致性,如果系统时间被回调,或者改变,可能会造成id冲突或者重复。
希望本文能帮助您理解雪花算法的实现过程,也希望能够为您在分布式系统开发中提供一些使用帮助。
欢迎关注博主 「六月暴雪飞梨花」 或加入【六月暴雪飞梨花社区】一起学习和分享Linux、C、C++、Python、Matlab,机器人运动控制、多机器人协作,智能优化算法,滤波估计、多传感器信息融合,机器学习,人工智能等相关领域的知识和技术。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 软件测试/测试开发丨Python常用数据结构-元组Tuple
- [情商-10]:聊天过程中如何开场和控场
- 线程切换步骤及wait() notify() notifyAll()
- Day2Qt
- 非递归方式遍历二叉树的原理
- 力扣hot100 二叉树的层序遍历 BFS 队列
- 单片机原理及应用:数码管的动态扫描显示、余晖效应与消影
- 半新手向,webservice开发调用wsdl,调用他人的服务
- mongodb学习笔记:3. mongodb的基本操作
- vuejs 3.x项目使用terser-webpack-plugin 去除console 没有生效