Python 基于pytorch实现多头自注意力机制代码;Multiheads-Self-Attention代码实现
1.Multiheads-Self-Attentiona简介
多头自注意力机制(Multi-Head Self-Attention)是一种注意力机制的变体,用于增强模型在处理序列数据时的建模能力。它在自注意力机制的基础上引入了多个头(Attention Head),每个头都可以学习到不同的注意力权重分布,从而能够捕捉到不同的关系和特征。
多头自注意力机制可以分为以下几个主要步骤:
1.1查询、键和值的线性变换
????????首先,将输入的查询向量Q、键向量K和值向量V进行线性变换,得到多组查询、键和值。具体来说,将它们通过不同的线性变换矩阵分别投射到不同的低维空间中,得到多组变换后的查询向量Q'、键向量K'和值向量V'。
1.2多头注意力权重的计算
????????在这一步骤中,针对每个注意力头,分别计算出对应的注意力权重。具体来说,对于每个头,将变换后的查询向量Q'与键向量K'进行点积操作,然后通过softmax函数将得分归一化为概率分布。这样就得到了多组注意力权重。
1.3多头上下文向量的计算
????????针对每个注意力头,将对应的注意力权重与变换后的值向量V'进行加权求和,得到多组上下文向量。这些上下文向量将包含各个头所关注的不同信息。
1.4多头上下文的融合
????????将多组上下文向量在特定维度上进行拼接或线性变换,将它们融合成最终的上下文向量。这样得到的上下文向量将包含从多个头中学到的不同特征和关系。
????????多头自注意力机制的优势在于可以并行地学习多组不同的注意力权重,从而能够提取不同层次、不同类型的相关信息。通过引入多头机制,模型可以同时关注序列中的多个位置,并从不同的角度对序列进行编码,提高了模型的表达能力和泛化能力。
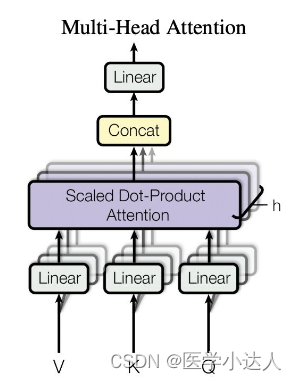
图中h就是代表头的数量,这个是transformer结构的一部分
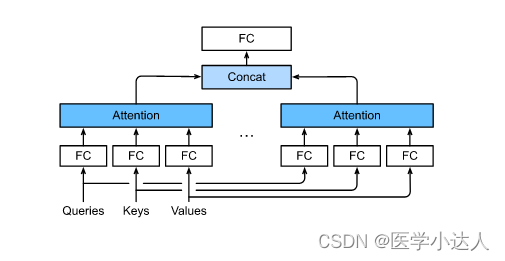
2.代码实现Multi-heads-Self-Attentiona结构
import torch
import torch.nn.functional as F
# 一个形状为 (batch_size, seq_len, feature_dim) 的张量 x
x = torch.randn(2, 3, 4) # 形状 (batch_size, seq_len, feature_dim)
# 定义头数和每个头的维度
num_heads = 2
head_dim = 2
# feature_dim 必须是 num_heads * head_dim 的整数倍
assert x.size(-1) == num_heads * head_dim
# 定义线性层用于将 x 转换为 Q, K, V 向量
linear_q = torch.nn.Linear(4, 4)
linear_k = torch.nn.Linear(4, 4)
linear_v = torch.nn.Linear(4, 4)
# 通过线性层计算 Q, K, V
Q = linear_q(x) # 形状 (batch_size, seq_len, feature_dim)
K = linear_k(x) # 形状 (batch_size, seq_len, feature_dim)
V = linear_v(x) # 形状 (batch_size, seq_len, feature_dim)
# 将 Q, K, V 分割成 num_heads 个头
def split_heads(tensor, num_heads):
batch_size, seq_len, feature_dim = tensor.size()
head_dim = feature_dim // num_heads
output = tensor.view(batch_size, seq_len, num_heads, head_dim).transpose(1, 2)
return output # 形状 (batch_size, num_heads, seq_len, feature_dim)
Q = split_heads(Q, num_heads) # 形状 (batch_size, num_heads, seq_len, head_dim)
K = split_heads(K, num_heads) # 形状 (batch_size, num_heads, seq_len, head_dim)
V = split_heads(V, num_heads) # 形状 (batch_size, num_heads, seq_len, head_dim)
# 计算 Q 和 K 的点积,作为相似度分数 , 也就是自注意力原始权重
raw_weights = torch.matmul(Q, K.transpose(-2, -1)) # 形状 (batch_size, num_heads, seq_len, seq_len)
# 对自注意力原始权重进行缩放
scale_factor = K.size(-1) ** 0.5
scaled_weights = raw_weights / scale_factor # 形状 (batch_size, num_heads, seq_len, seq_len)
# 对缩放后的权重进行 softmax 归一化,得到注意力权重
attn_weights = F.softmax(scaled_weights, dim=-1) # 形状 (batch_size, num_heads, seq_len, seq_len)
# 将注意力权重应用于 V 向量,计算加权和,得到加权信息
attn_outputs = torch.matmul(attn_weights, V) # 形状 (batch_size, num_heads, seq_len, head_dim)
# 将所有头的结果拼接起来
def combine_heads(tensor, num_heads):
batch_size, num_heads, seq_len, head_dim = tensor.size()
feature_dim = num_heads * head_dim
output = tensor.transpose(1, 2).contiguous().view(batch_size, seq_len, feature_dim)
return output# 形状 : (batch_size, seq_len, feature_dim)
attn_outputs = combine_heads(attn_outputs, num_heads) # 形状 (batch_size, seq_len, feature_dim)
# 对拼接后的结果进行线性变换
linear_out = torch.nn.Linear(4, 4)
attn_outputs = linear_out(attn_outputs) # 形状 (batch_size, seq_len, feature_dim)
print(" 加权信息 :", attn_outputs)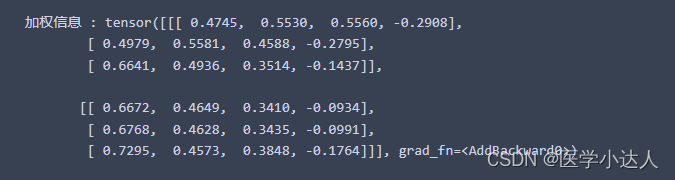
在我的其它文章中详细介绍了transformer和gpt的结构,具体代码见此专栏的其他文章?
3.总结
????????值得注意的是,多头自注意力机制通常还会引入一些线性变换和归一化操作,以增加模型的表达能力和稳定性。比如,可以通过将多个头输出的上下文向量进行线性变换并拼接,然后再通过另一个线性变换将其映射到目标空间。同时,为了保持变换前后的数值范围一致,常常会进行归一化操作,如层归一化(Layer Normalization)或批次归一化(Batch Normalization)。
????????综上所述,多头自注意力机制通过引入多组注意力头,可以并行学习多个不同的注意力权重,从而能够提取不同层次、不同类型的相关信息,增强模型的表达能力和泛化能力。它是当前很多自然语言处理任务中常用的重要注意力机制之一。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【C++】命名空间
- 配置BGP的基本实例
- 字符串删除。输入字符串,输入一个子字符串。删除子字符串,输出删除最终结果。
- 生活自来水厂污水处理设备需要哪些
- P1094 [NOIP2007 普及组] 纪念品分组
- 如何保持工业产线业务安全稳定运行?IoT设备敏捷准入方案有诀窍
- 网站安全每日话题——网页内容被篡改怎么办
- vba设置excel单元格背景色
- C++ I/O操作---输入输出
- OpenVINS学习7——评估工具的简单使用