【史上最小白】Bert:双向 Transformer 编码器
?
论文地址:https://arxiv.org/pdf/1810.04805.pdf
Bert:论洞察语境,GPT 不如我深刻;论理解含义,ELMo 不如我全面
Bert 采用双向 Transformer 编码器,没有用解码器。
- 编码器作用:生成下一个词时,它只能依赖于已生成的词(通常是左侧的词)
- 解码器没有用是因为,在生成任务中,不仅记住前面的人说的,还想提前知道后面的人会说什么,然后再说它的那一句,这是不可能的,故事还在发展,我们不能知道未来的内容。

Bert 主要是 双向,论文中对比了 GPT、ELMo。
GPT 是单向(左至右)的语言模型,主要关注于给定前文下生成下一个单词。
ELMo 也考虑了双向上下文,但其并不是在每个层级同时考虑两个方向的上下文,因此不如 BERT 的上下文表示能力强。
想象你在玩捉迷藏,Bert是一个聪明的孩子,他站在中间,同时向左和向右看,能够很好地观察到左边和右边的一切动静。
而GPT就像只往一个方向看的孩子,比如他只看左边,就可能会错过右边的同学。
ELMo虽然会左右看,但是他每次只能看一个方向,不能像Bert那样同时看两边。
要么只看一个方向,要么不能同时看两个方向,所以它们可能会错过一些重要的线索。
- 只看一个方向可能会导致对情境的误解和信息的片面解读,进而影响决策和分析的准确性。
- 专注于单一视角可能忽视关键信息,导致对复杂问题的理解不全面和决策失误。
?
输入阶段词嵌入:把词语转换为向量

把词语转换为向量,通过图中 3 中 Embeddings 方式做的,用于捕捉词语间的语义关系
-
Token Embeddings: 每个词语首先被分割成更细小的单元,然后每个token被转换成基本的词向量。
-
Segment Embeddings: BERT可以接受两个句子作为输入,用来区分两个不同的句子。
帮助BERT区分哪些词语来自于第一句,哪些来自于第二句。
就可以更好地理解句子之间的关系,比如哪些词语是回答问题中的答案,哪些是问题本身。
-
Position Embeddings: 由于 Transformer 模型本身不具备顺序感知能力,BERT引入了位置嵌入来给模型提供单词在句子中位置的信息。
第一个预训练 Masked:学习语言的深层次理解
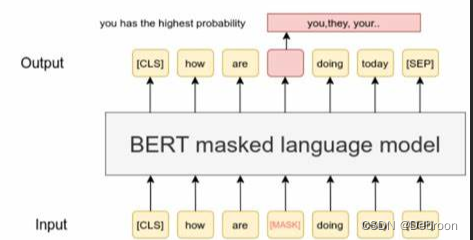
这一步是不断迭代出来的。
尝试 1:预测每个单词
想象一下,我们给电脑出了一个填空题,电脑要猜每个空格里的单词是什么。
但如果我们告诉电脑每个空格里原来的单词是什么,那这个游戏就太简单了,对吧?
电脑会很轻松地每次都猜对,因为它知道所有答案。
该网络事先知道它需要预测什么,因此它可以很容易地学习权值,以达到100%的分类精度。
尝试 2:Masked 语言模型
那我们在句子中随机遮住一些单词,就像玩“填空游戏”时用笔遮住一些单词一样。
电脑的任务是猜出这些遮住的单词。
这样的话,电脑就不能作弊了,因为它不知道被遮住的单词是什么,必须要仔细看周围的单词来猜测答案。
但是,这种方法有一个问题。
电脑只学会了猜测遮住的单词(也就是标记为[MASK]的地方),而在实际使用时,我们不会告诉电脑哪些单词是被遮住的。
尝试 3:用随机单词替换部分遮住的单词
那我们不再总是用[MASK]标记来遮住单词,而是有时候用其他随机的单词来替换。
这样一来,电脑就不能只猜测[MASK]的地方了,它需要对所有的单词都有所判断。
不过,这个方法也有问题。
电脑会学到,如果输入的是一个随机的单词,那么它通常不是答案。
原句:I have a cat.
随机:I have a dog.
其中 “dog” 是一个随机选取的词,替换了 “cat”。
在绝大多数情况下,这些随机生成的词并不是原本句子中应该出现的词。
如果输入中的某个词是随机放置的,那么这个词几乎不可能是正确答案。
因此,模型会形成一个偏见,即倾向于忽略那些随机单词,并认为它们不重要。
尝试 4:结合遮盖、随机替换和不变的单词
从训练数据生成器随机选择句子中大约 15% 的令牌位置。
对于这些被选中的令牌,将会被替换,以帮助模型更好地学习上下文信息:
- 80% 的概率被替换为 [MASK] 令牌。例如,如果选中的令牌是 “cat”,则在80%的情况下,句子变为 “I have a [MASK]”。
- 10% 的概率被替换为一个随机的单词。例如,如果选中的令牌是 “cat”,则在10%的情况下,句子可能变为 “I have a dog”。
- 10% 的概率保持原样不变。例如,如果选中的令牌是 “cat”,则在10%的情况下,句子保持不变为 “I have a cat”。
通过混合这三种方法,模型在训练时无法确定遇到的单词是否是原文中的单词、一个随机单词还是一个遮盖的单词,从而迫使模型必须学习和理解语言的深层规律,这样它在面对新的、未见过的文本时,能够更好地理解和回答问题。
在这种情况下,模型不能只依赖于单词的变化与否来猜测答案。
模型必须更多地依赖于对句子的整体理解和上下文的分析来做出预测。
因此,当模型看到 “I have a dog.” 时,它需要判断 “dog” 是不是原始文本中的单词,还是一个用来混淆其判断的随机单词。
第二个预训练 下一句预测:理解俩个句子之间的关系

输入:俩个A、B句子,有 50% 的 B 是 A 的下一句(他们必须属于同文档)
输出:模型需要预测 B 是不是 A 的下一句
微调:特定任务下,提高准确率
通常只会更新最后一层。

图a:句子对分类。就是在768尺寸的 CLS 输出之上添加一个Linear + Softmax层(图中没显示)。
图b:单独句子分类。就是在768尺寸的 CLS 输出之上添加一个Linear + Softmax层(图中没显示)。
图c:问答任务。只需在BERT模型的输出上添加一个额外的线性层和softmax层来为每个单词预测其对应的词性类别。
图d:单句标注任务
Bert 优势任务
BERT在理解文本中双向上下文和处理细粒度的自然语言处理任务上更强,但在连续文本生成和处理大规模数据集方面不如GPT。
细粒度的自然语言处理任务,主要包括:
- 命名实体识别:识别文本中的具体实体,如人名、地点、组织等。
- 词性标注:为文本中的每个单词分配语法类别,如名词、动词、形容词等。
- 问答系统:根据一个问题从一段文本中提取答案。
- 意图识别:确定用户语句的目的,常用于对话系统和聊天机器人中。
- 情感分析:判断文本的情感倾向,例如正面、负面或中性。
- 文本蕴含:判断一段文本是否能够推断出另一段文本的信息。
- 关系抽取:识别文本中实体之间的关系。
- 语义角色标注:分析句子中的谓语动词及其相关的参数和修饰语。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!