A Zero-shot Learning Method with a Multi-modal Knowledge Graph

F
~
s
+
u
\tilde{F}_{s+u}
F~s+u? represents the result of two-layer network activation

extracted classifier weights for seen-class (denoted with W
i
_i
i?)
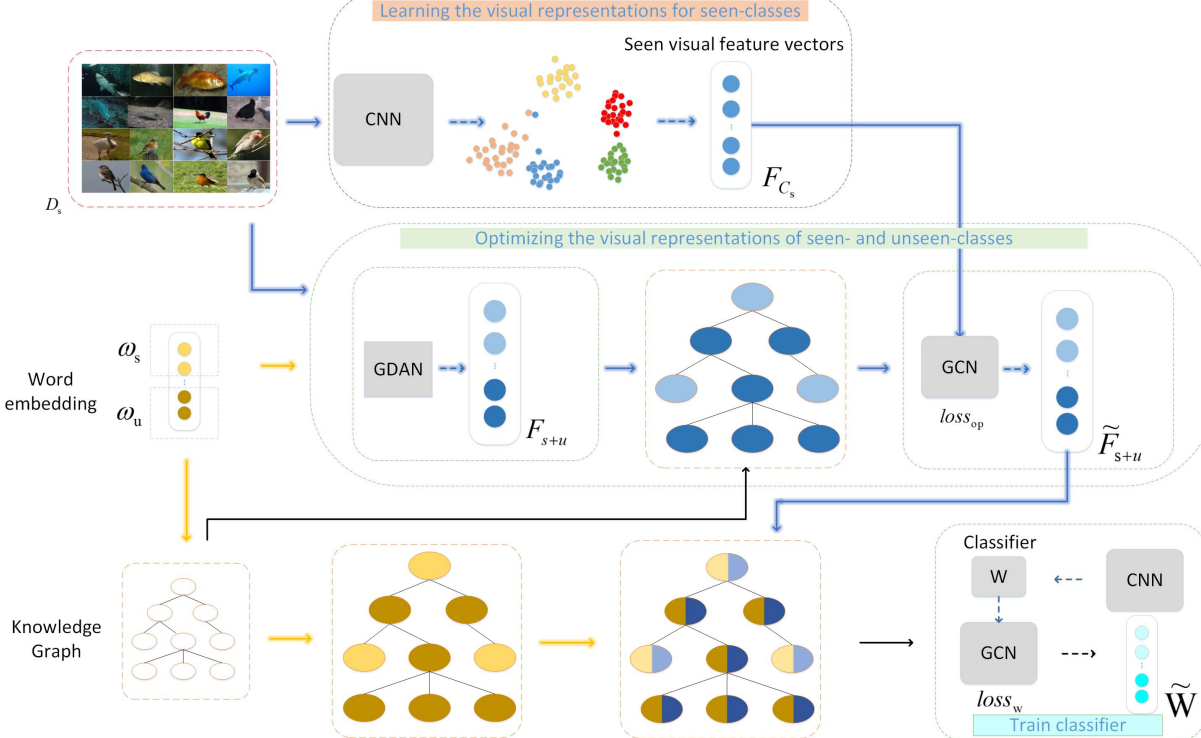
CNN is used to extract the visual representations for seen-classes, denoted as F
C
s
_{C_s}
Cs??.generative adversarial network (GDAN),visual representations of all classes F
s
+
u
_{s+u}
s+u?
额外信息
作者未提供代码
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 字节员工:本以为大厂出来好找工作,没想到行情比预想的差
- 【系统DFX】如何诊断占用过多 CPU、内存、IO 等的神秘进程?
- 微信小程序长按图片识别二维码
- Python 架构模式:第五章到第九章
- Web开发自动测试工具-Selenium的具体使用办法(填坑中……)
- CGAL-5.4.1三角剖分和点云分割简单案例
- 警告!!!Terrapin攻击(CVE-2023-48795)~~~
- 电子万能试验机位移传感器安装位置对位移测量之影响
- 手机上的软件怎么修改网络IP地址
- 24节气-第11届蓝桥杯省赛Python真题精选