【iOS】——基于Vision Kit框架实现图片文字识别
文章目录
前言
根据苹果的官方文档,Vision可以执行面部检测、文本检测、条形码识别、图像注册和一般功能跟踪。Vision还允许将自定义Core ML模型用于分类或对象检测等任务。下面只是对文本识别的一个学习。
一、文本识别的分类
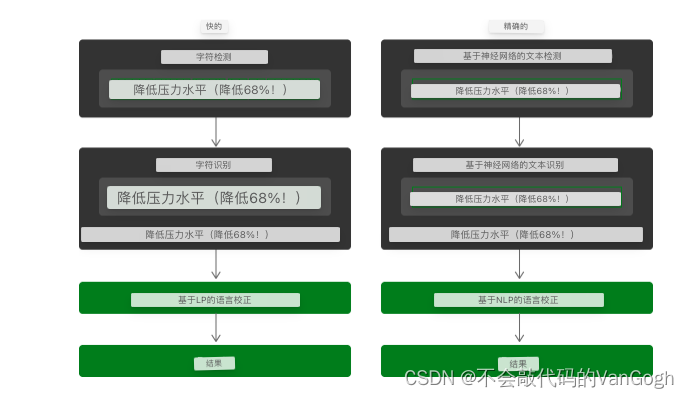
Vision的文本识别分为两种方式。
第一种是快速路径(fast),它使用框架的字符检测功能来查找单个字符,然后使用小型机器学习模型来识别单个字符和单词,这种方法类似于传统的光学字符识别(OCR)。
第二种是准确路径(accurate),它使用神经网络查找字符串和行的文本,然后执行进一步分析以查找单个单词和句子。这种方法更符合人类阅读文本的方式。
这两种识别方式都在VNRecognizeTextRequest 类的 recognitionLevel 属性中,并且该属性为枚举类型:
VNRequestTextRecognitionLevelAccurate: 表示精确级别的文本识别。在这个级别下,识别结果的准确性较高,但可能会增加处理时间和资源消耗。
VNRequestTextRecognitionLevelFast: 表示快速级别的文本识别。在这个级别下,识别速度较快,但可能会牺牲一些准确性。
使用其中任意一个路径都可以选择应用基于自然语言处理(NLP)的语言校正阶段,以尽量减少误读的可能性。
流程图如下:
二、实现步骤
实现文字识别总共分为六个步骤:
- 第一步:导入Vision Kit框架
- 第二步:创建请求处理器
- 第三步:在请求处理器中设置文字识别功能
- 第四步:将图片添加到请求处理器中
- 第五步:发起文字识别请求
- 第六步:处理识别结果
1.导入Vision Kit框架
1.打开需要导入的Xcode项目
2.在导航器面板中,选择您的项目文件
3.在项目设置中点击"General"选项卡,然后在"Frameworks, Libraries, and Embedded Content"(框架、库和嵌入内容)部分,点击"+"按钮。
4.在弹出窗口中,搜索并选择"Vision.framework"。

5.在项目文件中引入头文件
#import <Vision/Vision.h>
#import <VisionKit/VisionKit.h>
2.创建请求处理器
// 创建一个请求处理器
VNRecognizeTextRequest *request = [[VNRecognizeTextRequest alloc] initWithCompletionHandler:^(VNRequest * _Nonnull request, NSError * _Nullable error) {
if (error) {
NSLog(@"文字识别出错: %@", error);
return;
}
}];
3.在请求处理器中设置文字识别功能
通过设置VNRecognizeTextRequest属性来设置文字识别功能
//设置参数
//搜索路径为准确路径
request.recognitionLevel = VNRequestTextRecognitionLevelAccurate;
//语言范围是英文或者简体中文
request.recognitionLanguages = @[@"en-US", @"zh-Hans"];
使用 recognitionLanguages 属性来设置文本识别的语言范围。recognitionLanguages 是一个字符串数组,你可以将支持的语言标识符添加到数组中。
4.将图片添加到请求处理器中
创建了一个 VNImageRequestHandler 对象,并将需要识别的图像以 CGImage 的形式传入
VNImageRequestHandler *handler = [[VNImageRequestHandler alloc] initWithCGImage:image.CGImage options:@{}];
5.发起文字识别请求
通过使用 VNImageRequestHandler 的 performRequests方法来实现
// 发起文字识别请求
NSError *error = nil;
[handler performRequests:@[request] error:&error];
if (error) {
NSLog(@"文字识别请求出错: %@", error);
}
6.处理识别结果
VNRecognizedTextObservation 类代表了 Vision 框架识别出的文本观察结果。使用 VNRecognizedTextObservation 对象的 topCandidates 方法返回一个数组,其中包含了识别结果的候选文本。
// 处理识别结果
NSArray *results = request.results;
for (VNRecognizedTextObservation *observation in results) {
NSArray<VNRecognizedText *> *topCandidates = [observation topCandidates:1];
if (topCandidates.count > 0) {
VNRecognizedText *recognizedText = [topCandidates firstObject];
NSString *text = recognizedText.string;
NSLog(@"识别结果: %@", text);
self.medicineLabel.text = text;
} else {
NSLog(@"没有找到候选文本");
}
}
三、运行结果测试
1.纯英文环境
1.准确路径下的运行结果

2.快速路径下的运行结果

可以看到在纯英文环境下,两种路径的识别准确率都是非常高的
2.中英文混合环境
1.准确路径下的运行结果

2.快速路径下的运行结果

在中英文混合环境下,虽然设置了识别范围是英文和简体中文但是准确路径只识别到了一个单词,快速路径虽然识别了一个字段但是准确率不是特别高
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 智慧园区建设方案简述
- python使用贪心算法求最大整数问题
- Android Context在四大组件及Application中的表现
- 详解Java中@Accessors注解(全)
- rk3566-Android11 从驱动到 app 第二章添加 hall 层
- ELF文件的段
- 【OpenCV学习笔记07】- 【彩蛋】实现轨迹条控制画笔颜色和笔刷半径,并可以正常绘画
- 第二周:AI产品经理全局学习
- 两种方法求解平方根 -- 牛顿法、二分法
- HarmonyOS开发FA应用模型下多个页面的声明方式