【Python案例实战】水质安全分析及建模预测
一、引言
1.水资源的重要性
水是生命之源,是人类生存和发展的基础。它是生态系统中不可或缺的组成部分,对于维系地球上的生命、农业、工业、城市发展等方面都具有至关重要的作用。
2.水质安全与人类健康的关系
水质安全直接关系到人类的健康和生存。水中的污染物和有害物质可能对人体造成严重的健康危害,如肠道疾病、皮肤疾病、癌症等。因此,确保水质安全是保障人类健康的重要前提。
3.建模预测在水质安全分析中的必要性
为了应对水质安全面临的挑战,需要采取科学的方法进行水质监测和分析。而建模预测作为一种重要的分析工具,可以帮助我们更好地理解水质变化的规律和趋势,预测未来的水质状况,为水质管理和保护提供科学依据。通过建模预测,可以提前预警可能出现的污染事件,及时采取应对措施,保障水质安全。因此,建模预测在水质安全分析中具有不可替代的作用。
二、水质安全分析
1.水质标准与指标
a. 世界卫生组织(WHO)水质标准
世界卫生组织(WHO)制定了一套全球通用的水质标准,以确保人类和生态系统健康。这些标准包括对各种污染物的最大允许浓度,如重金属、有害有机物、细菌、病毒等。
b. 各国水质标准与法规
各国根据自身实际情况和需求,制定了自己的水质标准与法规。这些标准通常会参考或采纳WHO的标准,但也可能根据本国的特定环境和条件进行调整。
c. 特定污染物指标
除了上述通用指标外,针对特定环境和用途,还可能有一些特定的污染物指标。例如,针对农业灌溉的水质,可能更加关注农药残留和盐分等指标;而针对工业用水,可能更加关注pH值、硬度、悬浮物等指标。
2. 水质检测方法
a. 物理检测法
物理检测法主要通过测量水的物理性质来评估水质。例如,浊度、色度、温度、pH值等都可以通过物理方法测量。
b. 化学检测法
化学检测法涉及使用化学试剂和仪器来测量水中的化学物质。这种方法可以检测出更多的污染物,尤其是那些不能通过物理方法检测的物质。
c. 生物检测法
生物检测法利用生物体的反应来评估水质。例如,通过观察生物的生长、繁殖或死亡情况,可以判断水质的好坏。这种方法通常用于评估水体的综合质量。
3. 水质污染源分析
a. 点源污染
点源污染指的是具有明确排放源的污染,如工业废水、城市污水等。这类污染源通常具有较大的排放量,且污染物种类较为单一。
b. 面源污染
面源污染指的是没有固定排放源的污染,如农业排水、雨水冲刷等。这类污染源排放的污染物种类多、数量大,且难以控制。
c. 移动源污染
移动源污染主要指交通工具排放的废气和废水等。这类污染源具有流动性大、排放不规律等特点,对水质安全造成一定威胁。
4.水质安全风险评估
a. 暴露评估
暴露评估是指评估人们通过饮水、食物、呼吸等途径接触到的污染物量。通过了解暴露量,可以判断人体受到的健康风险。
b. 毒性评估
毒性评估是指对污染物对人体和生态系统的危害程度进行评估。通过对污染物进行毒性实验,可以了解其对人体和生态系统的潜在危害。
c. 风险特征描述
风险特征描述是对暴露评估和毒性评估的综合分析,以判断某一污染物对人体和生态系统的风险水平。根据风险水平的高低,可以制定相应的管理措施和预警方案。
三、项目准备
1.电脑配置
本机系统为Window10s,运行软件使用JupyterNote
| 库名 | 版本号 |
|---|---|
| pandas | 1.5.3 |
| matplotlib | 3.7.2 |
| seaborn | 2.1.0 |
2.数据集描述
本数据集是一个综合性的水质分析数据集,由7999条模拟数据记录组成。
数据集包括多种化学物质的浓度测量值,如铝、氨、砷、钡、镉等,以及每种化学物质的安全阈值。
这些化学物质在实际水源中的浓度通常由多种因素决定,包括环境污染、工业排放、自然矿物质含量等。
数据集中包括一列“是否安全”分类变量,用于指示水样是否满足人类消费的安全标准。这个字段是基于各化学物质浓度与其对应安全阈值的比较得出的。
本数据为模拟数据集,但在设计上参考了实际情况,通过这个数据集,你可以探索数据预处理、特征工程、模型构建和评估等多个方面。这些探索分析结论也可以为研究水质安全与公共卫生之间关系提供有价值的参考信息。
3.问题描述
预测水是否安全(二元分类问题)
使用机器学习算法(如逻辑回归、支持向量机、随机森林)来预测水是否安全。
对数据集进行训练-测试分割,使用交叉验证来评估模型性能。
分析哪些参数对水质安全性的预测最为重要。
探索化学物质含量与水质安全性之间的关联(相关性分析)
进行统计分析,如皮尔逊或斯皮尔曼相关性测试,来评估不同化学物质含量与水质是否安全之间的关联性。
使用散点图和热图来可视化这些关系。
安全与不安全水样的特性(描述性统计分析)
对安全和不安全的水样分别进行描述性统计分析,包括平均值、中位数、标准差等。
使用箱线图或小提琴图来比较不同化学物质在安全与不安全水样中的分布情况。
识别潜在的危险化学物质(异常值分析)
使用箱线图或其他可视化工具来识别各化学物质中的异常值。
分析这些异常值是否与水质不安全有关。
四、数据准备
1.导入库
import warnings
warnings.filterwarnings("ignore")
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import font_manager
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.preprocessing import StandardScaler
from lazypredict.Supervised import LazyClassifier
from imblearn.over_sampling import SMOTE
## 加载字体
font_path = "dellarespira-regular.ttf"
font_manager.fontManager.addfont(font_path)
prop = font_manager.FontProperties(fname=font_path)
## 定义全局使用
plt.rcParams['font.family'] = 'sans-serif'
plt.rcParams['font.sans-serif'] = prop.get_name()
plt.rcParams['axes.unicode_minus'] = False
这段代码主要进行了一些初始化和配置工作,为后续的数据处理和可视化打下了基础。首先,导入了多个库,这些库提供了数据处理、可视化和机器学习的功能。接着,通过warnings.filterwarnings(“ignore”)来忽略可能出现的警告信息。然后,加载了一个自定义的字体文件,并将其设置为matplotlib的字体,以确保绘图中的文字能以指定的字体显示。最后,设置了matplotlib的全局字体参数,确保所有图形的字体都使用这个自定义字体。
2.数据读取及预处理
#读取数据
df = pd.read_csv("data/waterQuality.csv")
df.drop_duplicates(inplace=True)
# 查看数据信息
items = [
[
col,
df[col].dtype,
df[col].isnull().sum(),
] for col in df
]
display(pd.DataFrame(data=items, columns=[
'Attributes',
'Data Type',
'Total Missing',
]))
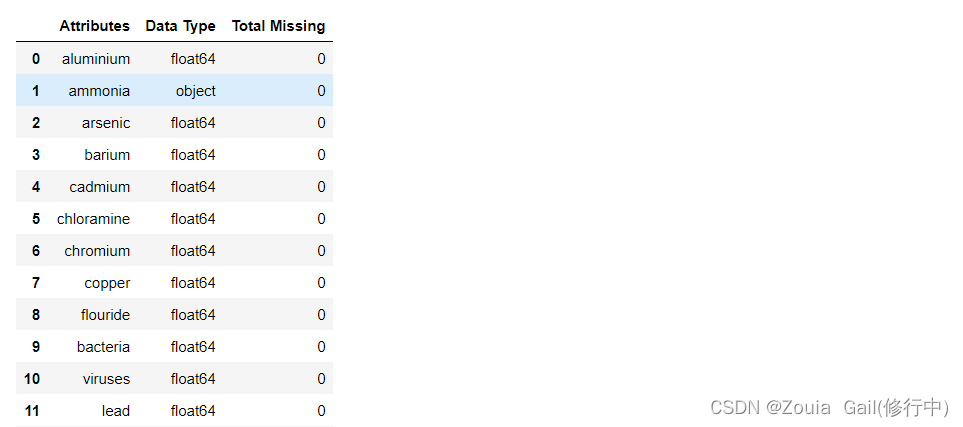
相当于info()函数,不过这样的好处是更加美观,可操作性更强(部分结果)
def conver_type(value):
try:
res =本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Vue中this.$nextTick的执行时机
- 【Java】List,Set,Map
- 双证的中国社科院与英国斯特灵大学创新与领导力博士
- 基于Java SSM框架实现学生寝室管理系统项目【项目源码+论文说明】
- x-cmd pkg | tsx - Node.js 的直接替代品
- NCC开发记录
- 什么是云服务器,阿里云优势如何?
- 解决 conda新建虚拟环境只有一个conda-meta文件&conda新建虚拟环境不干净
- 小区跑腿服务
- 亚马逊云科技:向量数据存储在生成式人工智能应用程序中的作用