MySQL库的操作
目录
字符集和校验规则
往文件中存储数据是要指明编码格式的,这样未来读文件中的数据时才能根据相同的编码格式进行解码读取,才能在读数据时不会读出来一堆乱码。对于本段内容,更具体的说明如下:
- 对于编码格式来说,准确叫字符集编码格式,我们向文件输入数据时,该数据可能会是字符数据,问题来了,文件是存在磁盘上的,也就是说文件只能存储二进制数字,文件上本质也全是二进制数字,那为什么我们可以输入字符数据到文件中呢?同时又为什么我们打开文件看到的不是二进制,而是之前输入的字符数据呢?
- 我们向文件中输入字符类型的数据时,是要指定编码格式的,比如我们向文件输入字符类型的数据例如【你s】时,此时就需要指定一个编码格式,将这个字符串根据编码格式转换成二进制序列,假如为UTF-8的格式,那么字符串进行编码后转换成的二进制序列为【你(1110xxxx 10xxxxxx 10xxxxxx)s(0xxxxxxx)】,所以实际上存进文件的内容依然是一个二进制序列,所以第一个问题的答案也就出来了,即我们不能输入字符数据到文件中,表面上输入的是字符数据,但实际上存进文件的内容依然是一个二进制序列。
- 往文件中输入【你s】后,假如我们想要在打开或者读取该文件时看见【你s】,我们指定的解码的格式就也应该是UTF-8,如果你指定的解码格式为GBK,那么就会显示出乱码。同时,我们在打开文件查看内容时,文件不会直接显示它在内存中的全是二进制数字的样子,这是因为文件会自动将二进制数字按照我们指定的解码格式转码转换成字符串,然后就显示成我们能识别的数据了,这就是上面的第二个问题的答案了。注意不要认为字符只是abcd,字符还指中文或者其他所有语言。
问题:那什么是字符集和校验规则呢?为什么在已经有了字符集的存在的情况下,还要有校验规则的存在呢?答案如下:
- 在<<MySQL数据库的基础概念>>一文中我们说过,数据库存储数据时本质也是通过文件来存储数据的,所以往数据库中存数据本质就是在往文件中存数据,只不过访问读写文件时并不由用户直接访问,而是需要数据库这个软件层作为中间人。既然往数据库中存数据本质就是在往文件中存数据,那么根据上文的内容可知,当然往数据库中存数据前也需要指定字符集这种编码格式,这样未来读数据库中的数据时才能根据相同的字符集编码格式进行解码读取,才能在读数据时不会读出来一堆乱码。
- 至于校验规则,对于数据库来说,用户在使用数据库时不光会有把数据库中所有的数据读出来的需求(毕竟如果只需要把数据库中的数据全部读出来,干嘛不一开始就用文件来存数据,而用数据库来存数据呢?),用户还有【按照某种条件在所有数据中查找符合该条件的数据,并把找到的数据显示出来】的需求,用户还有【按照某种条件将某些数据排序,再把排好序的数据显示出来】,注意,本质上在数据库中进行数据的查找、将数据库中的数据排序,都是需要和数据库中的二进制数据进行比较的,谁和数据库中的二进制数据进行比较呢?
- 对于数据的查找而言,是用户提供的条件数据来和数据库中的二进制数据进行比较,校验规则本质也是一种编码格式,用户提供的条件数据会根据校验规则这种编码格式被转换成二进制数据,然后数据库会在自己存储的所有二进制数据中查找和这个被转换成二进制数据的条件数据相等的数据。问题来了,为什么数据库不直接使用字符集这种编码格式将用户提供的条件数据转化成二进制数据,然后在自己存储的所有二进制数据中查找和这个被转换成二进制数据的条件数据相等的数据呢?这是因为用户的需求可能会变,举个例子,假如用户要在数据库中查找字符数据A,如果此时用户想按照大小写敏感的方式去查找,用户就可以使用校验规则1,此时校验规则1这种编码格式可以和字符集这种编码格式相同;但如果用户想按照大小写不敏感的方式去查找,则用户就需要使用校验规则2,此时校验规则2这种编码格式就不可以和字符集这种编码格式相同,否则就查找不了字符a而只能查找字符A,此时字符A就会根据校验规则2这种编码格式被转换成2个二进制数据,然后数据库就会在自己存储的所有二进制数据中查找和这个被转换成2个二进制数据的字符A相等的数据(说一下,字符A一定是被校验规则2转化成了2个二进制数字,分别和数据库中的字符A以及字符a对应的二进制数字相等);
- 而对于数据的排序而言,是数据库中的二进制数据互相比较,只不过在进行比较时,数据库会先把二进制数据按照字符集的编码规则转换成字符数据,然后再把字符数据按照校验规则这种编码格式转换成二进制数据,然后再对所有二进制数据进行排序。问题来了,数据库中的数据一开始就全是二进制数据,为什么不一开始就直接进行比较,而要先转回成字符数据,再转化成二进制数据进行比较呢?这是因为用户的需求可能会变,举个例子,假如数据库中有字符数据a、b、c、d,而当用户想要按照升序排序这些数据时(排序会根据字符的二进制数字比较大小),用户就可以使用校验规则1,此时校验规则1这种编码格式可以和字符集这种编码格式相同;但如果用户想要按照降序排序这些数据时,则用户就需要使用校验规则2,此时校验规则2这种编码格式就不可以和字符集这种编码格式相同,这样一来,数据库先把字符数据a、b、c、d对应的二进制数据按照字符集的编码规则转换成字符数据a、b、c、d,然后再把字符数据a、b、c、d按照校验规则2这种编码格式转换成二进制数据后,再对所有的二进制数据进行排序才可能排成降序。
- 综上所述,也正是因为用户在使用数据库时不光会有把数据库中所有的数据读出来的需求,用户的需求可能会变,所以在数据库中不光需要有字符集这种编码格式的存在,还需要有校验规则这种编码格式的存在。
- 根据上文内容我们还可以得到一个结论:一个字符集可以匹配多个校验规则。
对于以上内容,我们可以粗略理解成:字符集就是往数据库中存储数据前需要指定的编码格式,而校验规则就是从数据库中读取数据前需要指定的编码格式,这样一来,存数据的时候按照字符集将字符转码成二进制序列,取数据的时候按照校验规则将二进制数据转码成字符序列,所以编码集和校验规则必须匹配,不然读取数据时就会乱码。
查看MySQL数据库支持的字符集和校验规则
如下图所示,使用show charset语句即可查看数据库支持的字符集。下图中的Charset这一列就表示字符集;Description表示该字符集(本质就是一种编码格式)能将哪些国家的语言(即字符)和二进制序列互相转化;Default collation表示该字符集对应的默认校验规则,注意,我们在给MySQL设置字符集和校验规则时,是可以只指定字符集的,校验规则可以省略,这是因为给MySQL设置字符集后,MySQL会自动根据下图的这个表找到该字符集对应的Default collation默认校验规则,然后自动设置校验规则。当然我们也可以既指定字符集,又指定校验规则。
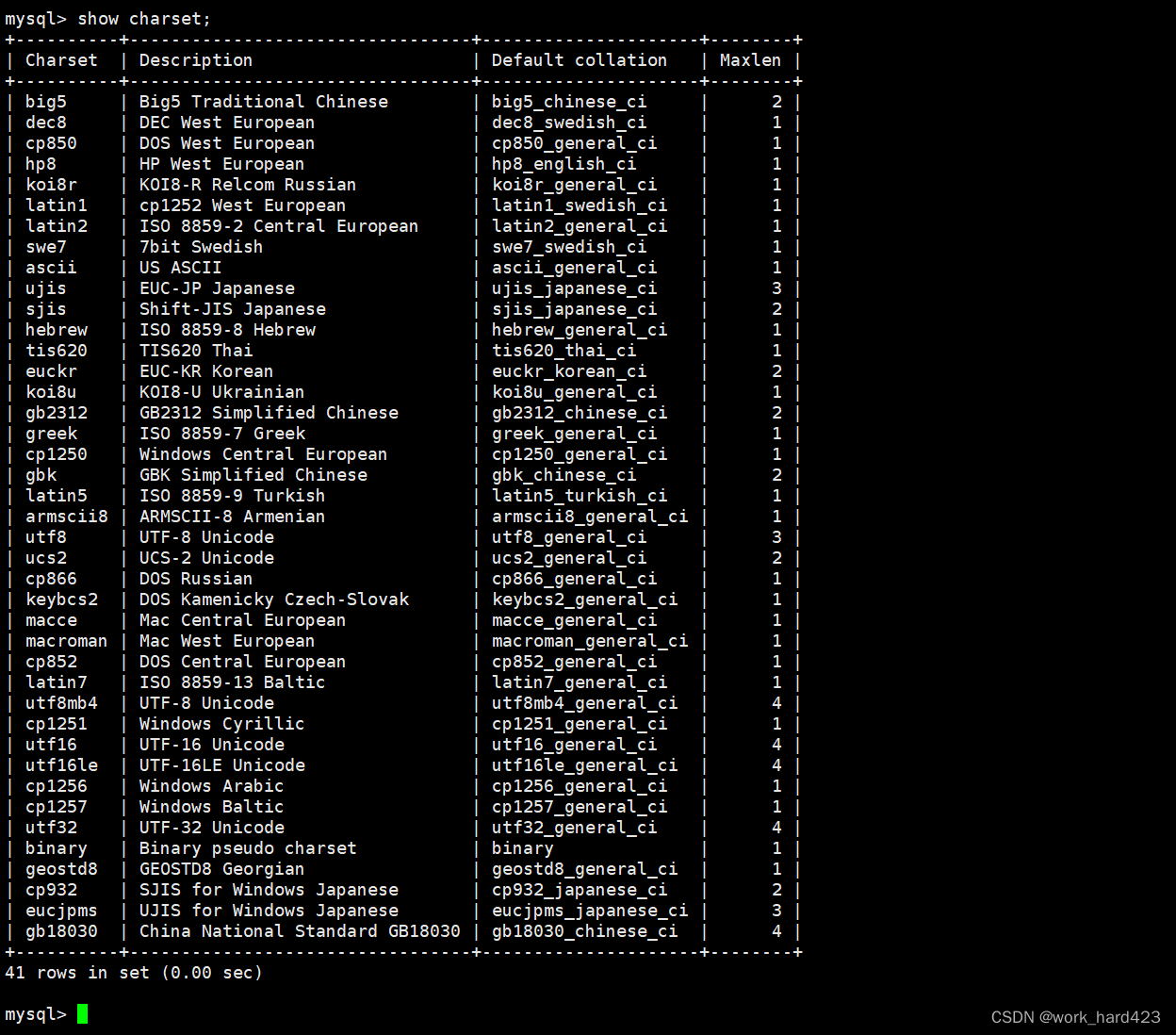
如下图所示,使用show collation即可查看数据库支持的校验规则。下图中的Collation这一列就表示校验规则;Charset表示该校验规则是匹配的哪个字符集;至于Default,在上文中说过一个字符集是可以匹配多个校验规则的,如下图红框处所示, 相同的字符集latin1可以匹配左侧蓝框处的多个校验规则就再次佐证了这一点,而黄框处的Yes则表示字符集latin1匹配的默认的校验规则是latin1_swedish_ci(如果忘了默认校验规则是什么意思,请回顾上一段的内容)。
说一下,通过下图这个表我们还可以得到一个结论A,即【一个校验规则只能唯一匹配一个字符集】,既然校验规则是一对一匹配的,所以我们又能再得到一个结论B,即【我们在给MySQL设置字符集和校验规则时,是可以只指定校验规则的,字符集可以省略,这是因为给MySQL设置校验规则后,MySQL会自动根据下图的这个表找到该校验规则唯一匹配的Charset字符集,然后自动设置字符集】。
最后结论A加上在上文中我们得到的结论【一个字符集可以匹配多个校验规则】,我们就得到了一个完整的结论:一个字符集可以匹配多个校验规则,但一个校验规则只能唯一匹配一个字符集。
查看系统默认字符集以及默认校验规则
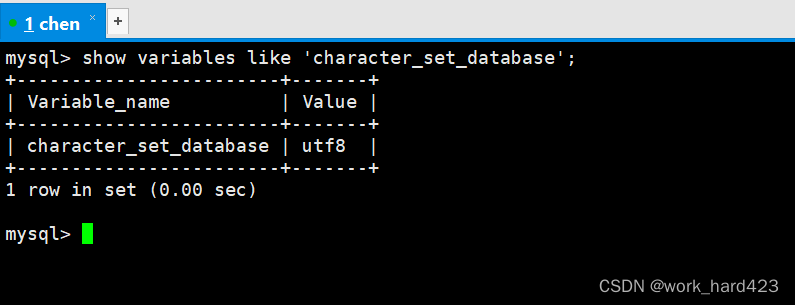
如下图1所示,通过查看MySQL系统变量variables中的character_set_database,可以得知系统默认的字符集,说一下,如下图2所示,系统默认的字符集就是MySQL配置文件(即MySQL客户端进程mysql和MySQL服务端进程mysqld共同的配置文件my.cnf)中提前配置的字符集。
注意:?如果是use进入某个数据库DB后再使用show variables语句,则查看的是该数据库DB默认使用的字符集,而不是系统默认的字符集。
- 图1如下。
- 图2如下。

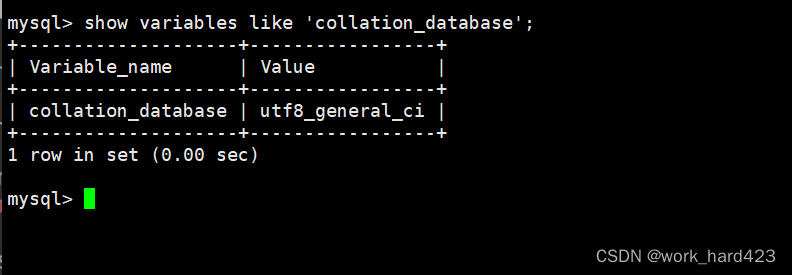
如下图1所示,通过查看MySQL系统变量variables中的collation_database,可以得知系统默认的校验规则。
说一下,有人此时可能会疑惑,说【在表示MySQL系统配置文件/etc/my.cnf的下图2中只配置了系统默认的字符集,并没有配置系统默认的校验规则,为什么查看MySQL系统变量variables中的collation_database可以得知系统默认的校验规则呢?】,这里笔者要说的是,在上文中说过,我们在给MySQL设置字符集和校验规则时,是可以只指定字符集的,校验规则可以省略,这是因为给MySQL设置字符集后,MySQL会自动根据下图3的这个表找到该字符集对应的Default collation默认校验规则,然后自动设置校验规则。
- 图1如下。
- 图2如下。?
- 图3如下。
创建数据库
create database [if not exists] 数据库名称 [charset=字符集名称] [ collate=校验集名称];
该SQL语句就用于创建数据库,说明一下:
- 注意设置数据库名称时,建议加上反引号``,比如想设置数据库的名称为helloworld时,最好是【create database `helloworld`;】,反引号?`?在键盘上数字1的左边。为什么呢?如果不加上``,则如果创建数据库给数据库起名时名字和MySQL中的关键字冲突,就会导致创建数据库失败,而如果加上``,即使冲突了,也能创建成功。
- [ ]中的内容代表的是可选项,即可以省略不写。
- CHARSET用于指定数据库所采用的字符集。
- COLLATE用于指定数据库所采用的校验规则。
如果创建数据库时未指明数据库的编码格式或校验规则,则默认使用下图这个MySQL配置文件(即MySQL客户端进程mysql和MySQL服务端进程mysqld共同的配置文件my.cnf)中提前配置的字符集或校验规则。
说一下,在使用create语句创建一个数据库后(本质是在Linux的var/lib/mysql路径上创建一个目录文件),在该数据库(或者说目录中)中会自动创建一个db.opt文件,在这个文件中就记录了当前数据库的默认字符集和默认校验规则(如何证明呢?在上文我们说过如果use进入某个数据库DB后再使用show variables语句,则查看的是该数据库DB默认使用的字符集,而不是系统默认的字符集。然后如下图蓝框处所示,在使用create语句创建数据库helloworld和hiworld时分别指定数据库的字符集是big5和gbk后,使用use进入对应数据库再使用show variables语句查看数据库DB默认使用的字符集,能够发现的确是big5和gbk,这就证明了数据库helloworld的默认字符集是big5,数据库hiworld的默认字符集是gbk,然后如下图黄框处所示,分别cat打印两个数据库中的db.opt文件,能够发现其记录的字符集的确是自己所在的数据库的默认字符集,这就证明了在db.opt文件中记录了当前数据库的默认字符集和默认校验规则),往后在当前数据库中建表时如果在建表的SQL语句中不指定字符集和校验规则,则就会默认使用db.opt文件中的字符集和校验规则(即使用当前数据库DB的默认字符集和默认校验规则)。
将上一段的内容和上上段的内容结合,我们就能得到一个完整的结论:对MySQL客户端进程mysql和MySQL服务端进程mysqld共同的配置文件my.cnf中的默认字符集和默认校验规则进行设置后(或者说对MySQL系统中的字符集和校验规则进行设置后),如果创建数据库时在SQL语句中不指定字符集和校验规则,则该数据库就会默认使用MySQL系统配置文件my.cnf中的字符集和校验规则(即会让db.opt文件中的字符集和校验规则等于MySQL系统配置文件my.cnf中的字符集和校验规则);对某个数据库DB的配置文件db.opt中的默认字符集和默认校验规则进行设置后,如果在该数据库DB中创建表时在SQL语句中不指定字符集和校验规则,则该表就会默认使用当前数据库DB的配置文件db.opt中的字符集和校验规则。

额外说一下,因为在<<MySQL数据库的基础概念>>一文中我们说过,本质上MySQL中的一个数据库DB就是Linux系统下/var/lib/mysql路径上的一个目录文件,?所以在MySQL中所谓的创建数据库就是在Linux系统下创建了一个目录文件,所以SQL语句create database就等同于Linux命令mkdir(注意也不是完全等同,因为如果在数据库存储所有数据的路径/var/lib/mysql上手动mkdir创建一个目录也就是数据库时,在该数据库中不会有db.opt文件)。
校验规则对数据库的影响
举个例子说明校验规则对数据库的影响,如下。
情况一:当操作数据库时采用utf8_general_ci校验规则时情况如下。
如下图所示,当在创建数据库时指定数据库的校验规则为utf8_general_ci时,数据库的编码格式默认匹配为utf8。

如下图所示,在该数据库中创建一个简单的person表,由于创建表时在SQL语句中未指定表的字符集和校验规则,因此person表将继承当前数据库的字符集和校验规则(即继承当前数据库中的配置文件db.opt中的字符集和校验规则)。

这时向表中插入一些数据。如下:?

通过select语句可以查看插入表中的数据。如下:
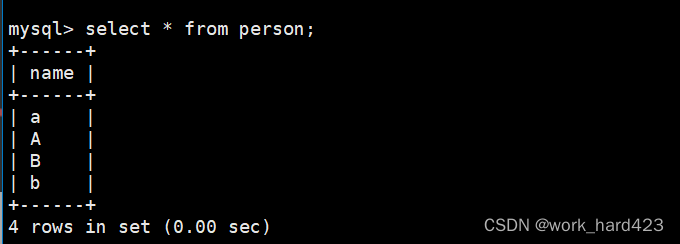
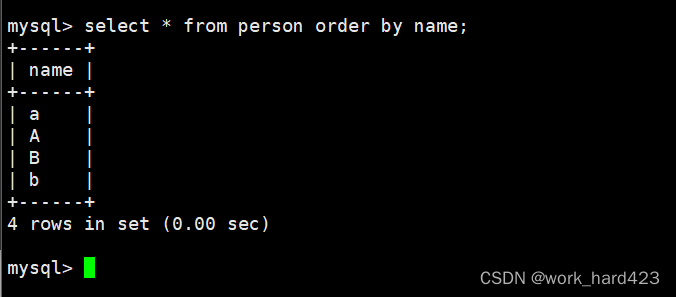
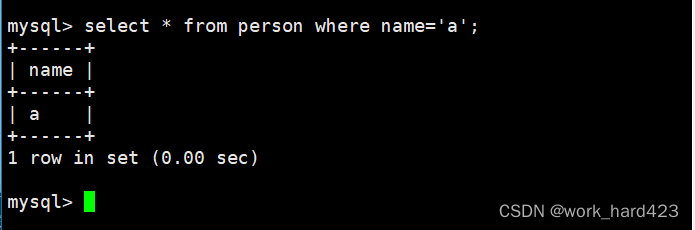
如下图1所示,这时指定查看表中name = 'a'的记录时会将A和a一并筛选出来,其根本原因就是校验规则utf8_general_ci在进行数据比对时是不区分大小写的;如下图2所示,这时将表中的所有数据进行排序时(默认从上到下是升序,同时因为A的阿斯克码小于a,同时也小于B,所以正常排是A<B<a<b,即A在最上面,然后是B,然后是a,b在最下面)a能排在B的上面和a能排在A的上面,其根本原因也是校验规则utf8_general_ci在进行数据比对时是不区分大小写的。
- 图1如下。

- 图2如下。?
情况二:当操作数据库时采用utf8_bin校验规则时情况如下。
如下图所示,当在创建数据库时指定数据库的校验规则为utf8_bin时,数据库的编码格式默认匹配也为utf8。?

如下图所示,在该数据库中同样创建一个简单的person表,由于创建表时在SQL语句中未指定表的字符集和校验规则,因此person表将继承当前数据库的字符集和校验规则(即继承当前数据库中的配置文件db.opt中的字符集和校验规则)。
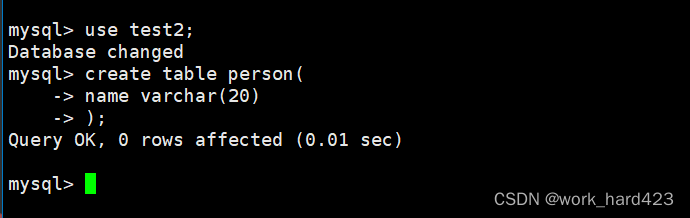
这时向表中插入刚才相同的数据。如下:
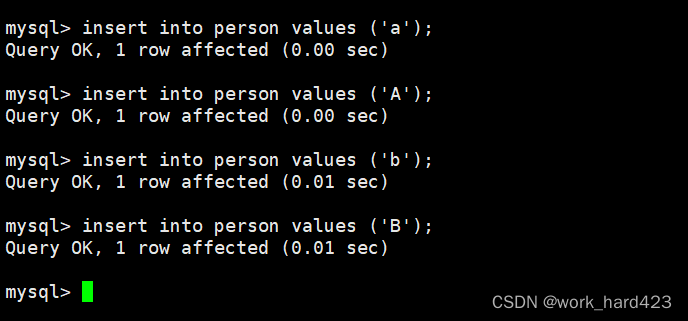
通过select语句可以看到表中的数据与之前相同。如下:?

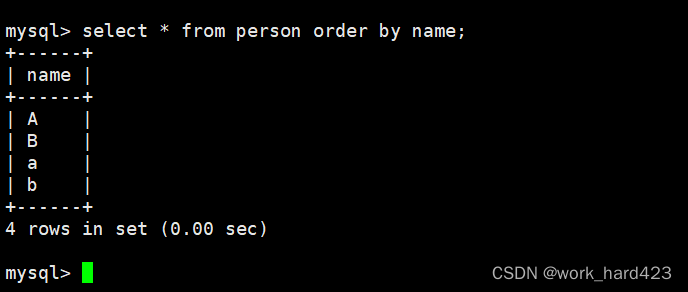
如下图1所示,但这时指定查看表中name = 'a'的记录时只会将a筛选出来而不会将A筛选出来,其根本原因就是utf8_bin校验规则在进行数据比对时是区分大小写的;如下图2所示,这时将表中的所有数据进行排序时(默认从上到下是升序,同时因为A的阿斯克码小于a,同时也小于B,所以正常排是A<B<a<b,即A在最上面,然后是B,然后是a,b在最下面)能正常排序,其根本原因也是utf8_bin校验规则在进行数据比对时是区分大小写的。
- 图1如下。
- 图2如下。
?对以上内容的总结:
综合上文可以发现,以上两种情况中所有的因素都相等,唯一的区别就是情况1采用utf8_general_ci校验规则,情况2采用utf8_bin校验规则,但最后在查询或者排序时呈现的结果却截然不同,这就是校验规则对数据库的影响的一角。
查看数据库
如下图所示,使用SQL语句show database即可查看系统中所有的数据库。
额外说一下,因为在<<MySQL数据库的基础概念>>一文中我们说过,本质上MySQL中的一个数据库DB就是Linux系统下的一个目录文件,并且MySQL中所有的数据都存储在路径/var/lib/mysql上(即所有的数据库DB都存储在该路径上),所以在MySQL中所谓的查看系统中的所有数据库就是在Linux系统下调用了一下ls?/var/lib/mysql -l命令,所以SQL语句show database就等同于Linux命令ls?/var/lib/mysql -l(但不完全等同,因为Linux命令ls?/var/lib/mysql -l会把该路径上的非目录普通文件也显示出来,但show databases只显示/var/lib/mysql路径上的数据库也就是目录文件,不显示表也就是非目录普通文件)。

显示创建语句
如下图所示,使用SQL语句【 show create database 数据库名称?】即可查看对应数据库的创建语句。说一下,该条语句并不是用于创建新的数据库的,而是用于查看一个已经存在的数据库的创建语句、用于查看曾经在创建该数据库时写的SQL语句是怎样的。
注意事项:
- 说一下,MySQL建议SQL语句中的关键字使用大写,但不是必须的。
- 数据库的名字加上反引号,是为了防止使用的数据库名与关键字冲突。
- /*!40100 DEFAULT CHARACTER SET utf8 */不是注释,它表示当前MySQL版本如果大于4.01,则执行后面的SQL语句。

修改数据库
alter database 数据库名称 [charset=字符集名称] [collate=校验规则名称];
该SQL语句就用于修改数据库,说明一下:
- [ ]中的内容代表的是可选项,即可以省略不写。
- CHARSET用于指定数据库所采用的字符集。
- COLLATE用于指定数据库所采用的校验规则。
- 对数据库的修改主要指的是修改数据库的字符集或校验规则。比如将数据库的字符集改为gbk,并将数据库的校验规则改为gbk_bin。如下:
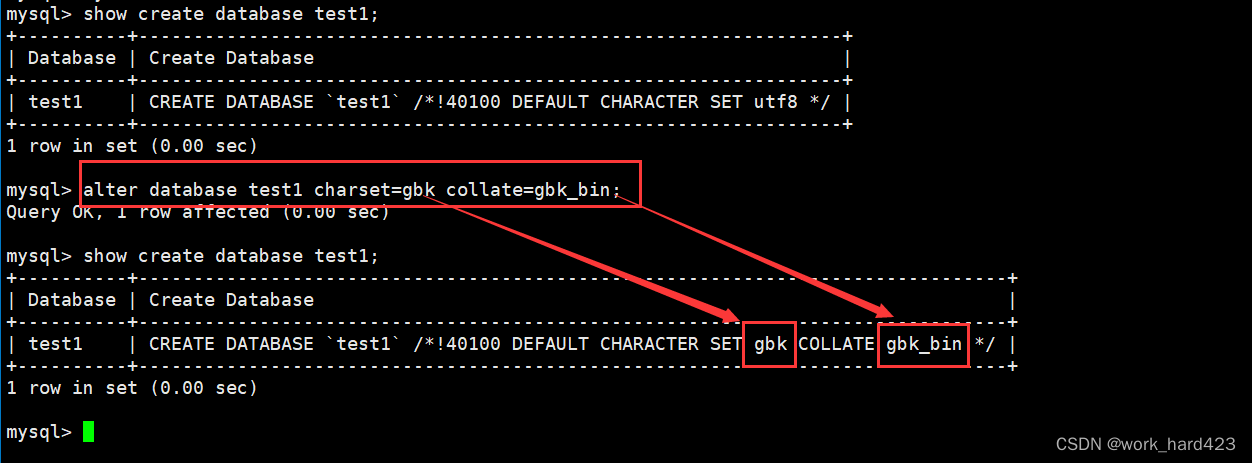
说一下,MySQL是不支持修改某个数据库DB的名称的,但在<<MySQL数据库的基础概念>>一文中我们说过,本质上MySQL中的一个数据库DB就是Linux系统下/var/lib/mysql路径上的一个目录文件,所以如果我们非要改某个数据库DB的名称,先cd?/var/lib/mysql进入该数据库所在的路径,然后通过Linux命令【mv 名称1 名称2】?即可修改名称了,但注意,我们不要这么做,因为如果强制改名后,后序使用MySQL时一定会出现某种未知的错误。
删除数据库
drop database?[if?exists] 数据库名称;
该SQL语句就用于删除数据库,说明一下:
- [ ]中的内容代表的是可选项,即可以省略不写。
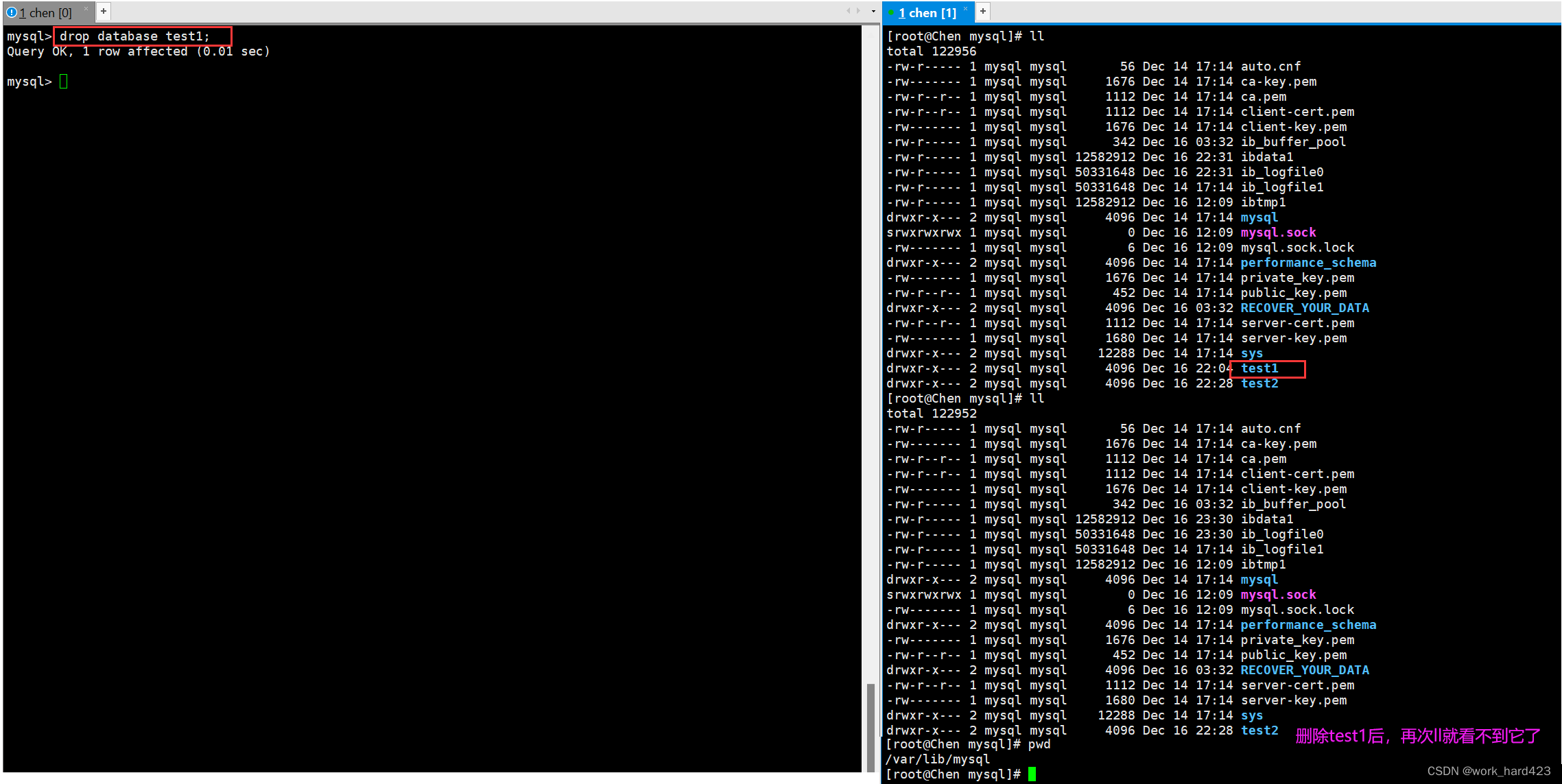
- 在<<MySQL数据库的基础概念>>一文中我们说过,本质上MySQL中的一个数据库DB就是Linux系统下/var/lib/mysql路径上的一个目录文件,所以删除数据库DB本质就是将该数据库DB对应的文件夹删除,所以删除数据库DB(即目录文件)后,该数据库DB(即目录文件)中的所有表(即普通文件)也都会被级联删除,因此不要随意删除数据库。
数据库的备份和恢复
在<<MySQL数据库的基础概念>>一文中我们说过,本质上MySQL中的一个数据库DB就是Linux系统下/var/lib/mysql路径上的一个目录文件,所以如果想备份某个数据库DB,最简单的方式就是先cd?/var/lib/mysql进入该数据库所在的路径,然后通过Linux命令【cp -r 数据库名称 指定路径】即可成功将某个数据库DB拷贝到指定路径上。说一下,如果MySQL客户端和服务端卡住了,但MySQL用于存储所有数据的路径/var/lib/mysql上的数据又很重要,此时如果实在没有办法,可以直接【cp -r /var/lib/mysql 指定路径】将该目录中的所有文件全拷贝到指定路径上。但注意,本段这样的方法虽然可行,但它是违规的,我们平时不要这么做。
数据库的备份
在备份数据库前,我们首先要确保MySQL服务端进程mysqld是启动的,否则无法备份,这是因为接下来要讲解的用于备份数据库和表的Linux命令mysqldump本质也是一个客户端(这也是为什么使用mysqldump时需要在命令行中输入目的端口号),mysqldump之所以能够备份数据库和表,也是因为mysqldump作为客户端向MySQL服务端进程mysqld发起了请求,然后mysqld为mysqldump提供了服务。
在备份数据库前,我们还要确保自己具有备份该数据库的权限,比如张三一般只能备份属于张三的数据库,不能备份属于李四的数据库,但如果是root用户,则都可以进行备份。
mysqldump -P 端口号 -u 用户名 -p 密码 -B 数据库名1 数据库名2 ... > 数据库备份存储的文件路径使用上面的Linux命令即可对指定数据库进行备份。为了演示数据库备份,下面我们创建一个数据库,并在该数据库中创建两个表。如下:
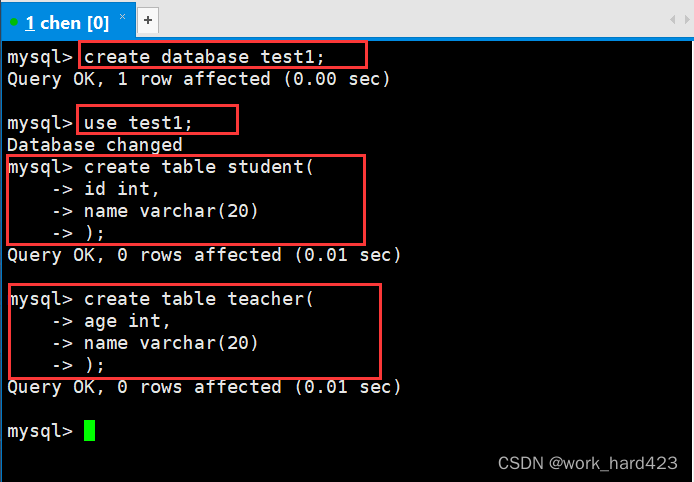
在student和teacher表中分别插入两条记录。如下:?
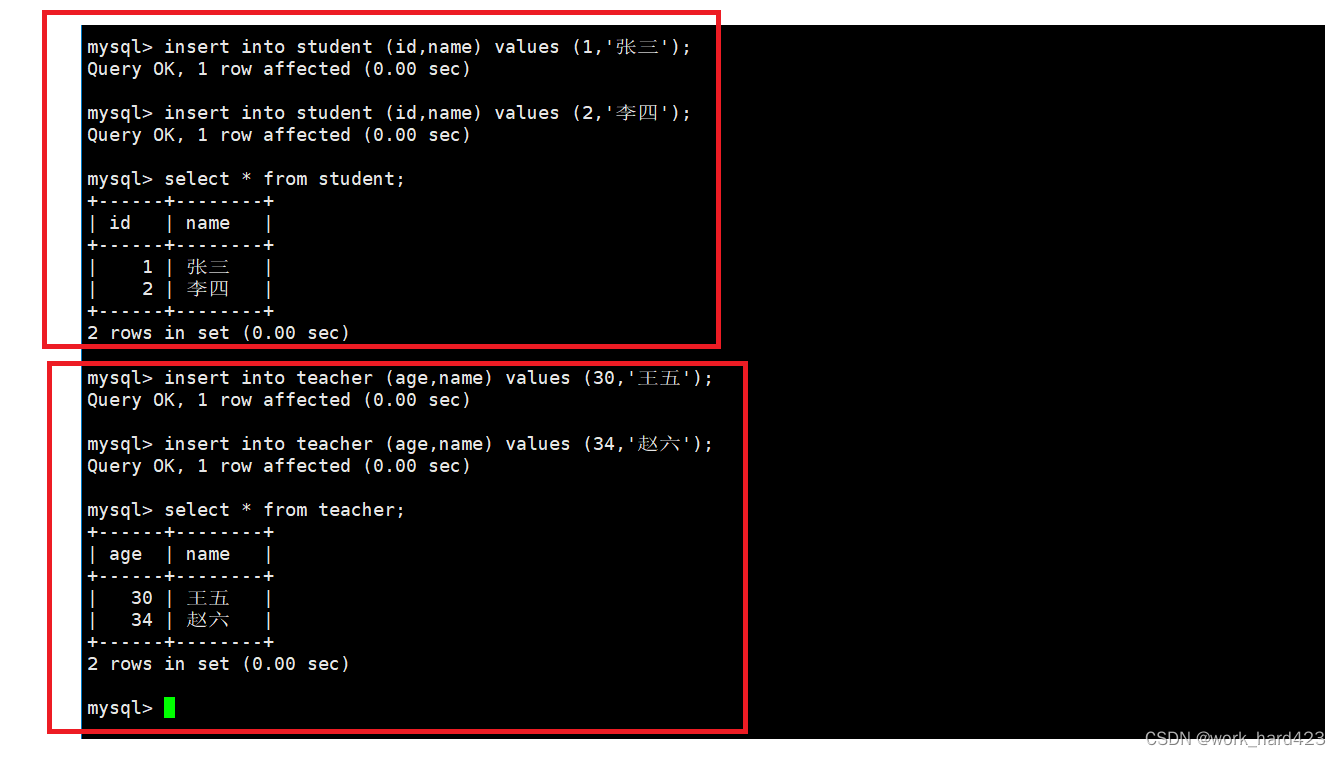
如下图所示,这时在命令行中执行如下命令即可将该数据库进行备份,并指定将备份后产生的文件存放在当前目录下(即用户在哪个路径下调用mysqldump命令,该备份文件就会被放在哪个路径下)。
说一下,下图中的Enter passworld后面是要输入登录MySQL客户端进程mysql以连接MySQL服务端进程mysqld的密码,由于我们在MySQL系统配置文件/etc/my.cnf中配置过可以免密码登录,所以这里直接按回车跳过登录密码的步骤即可。

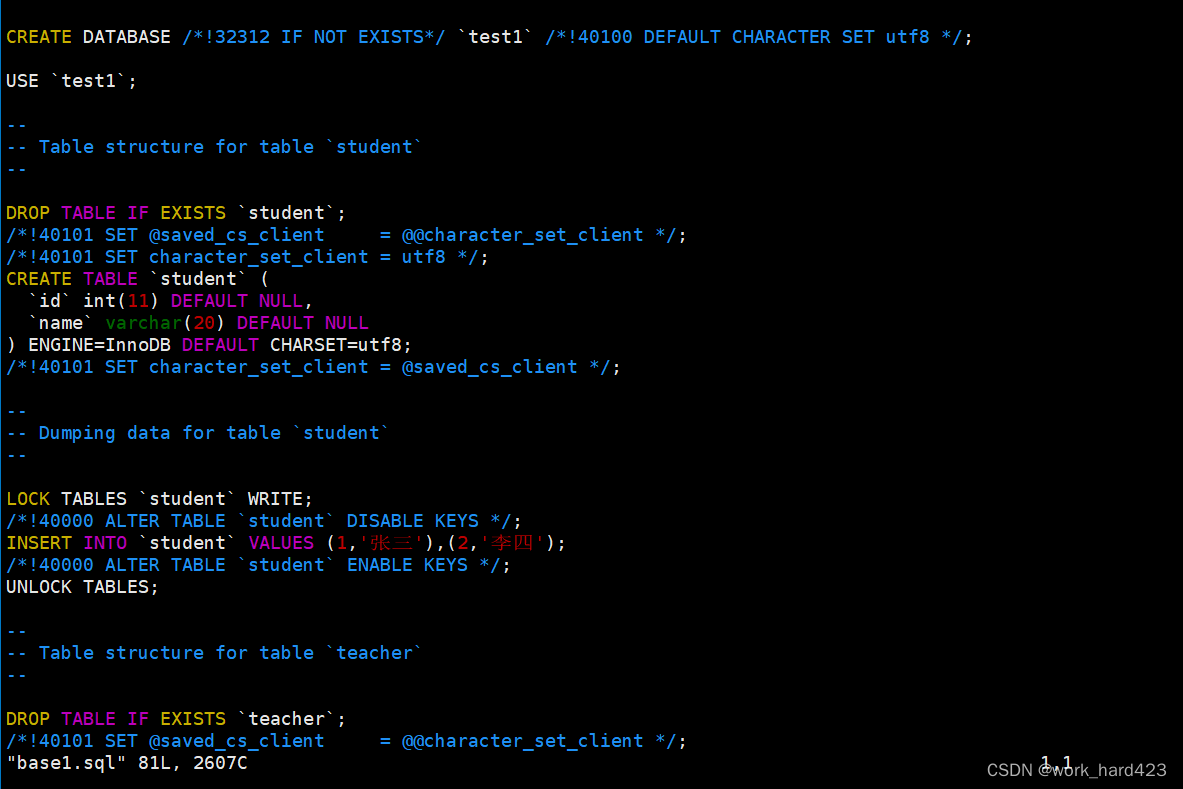
如下图所示,vim打开base.sql文件即可看到,文件中的内容实际就是我们在该数据库中执行的各种SQL命令,包括创建数据库、创建表、插入数据等SQL语句。
数据库的恢复?
source 数据库备份存储的文件路径
使用上面的Linux命令即可对指定数据库进行备份。为了演示数据库恢复,我们先将刚才创建的数据库删除。如下:
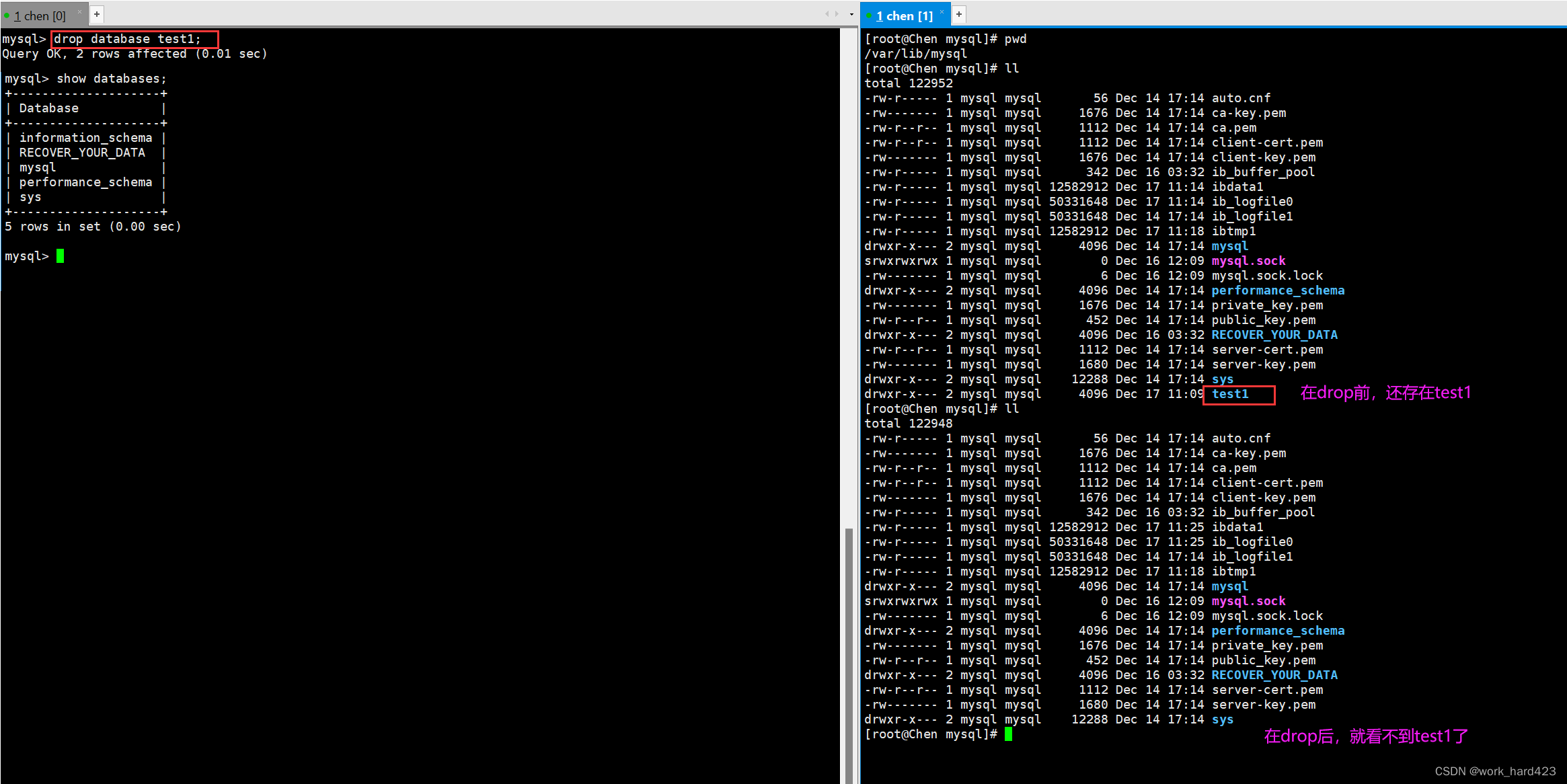
这时让MySQL服务器执行如下命令即可对数据库进行恢复。如下:
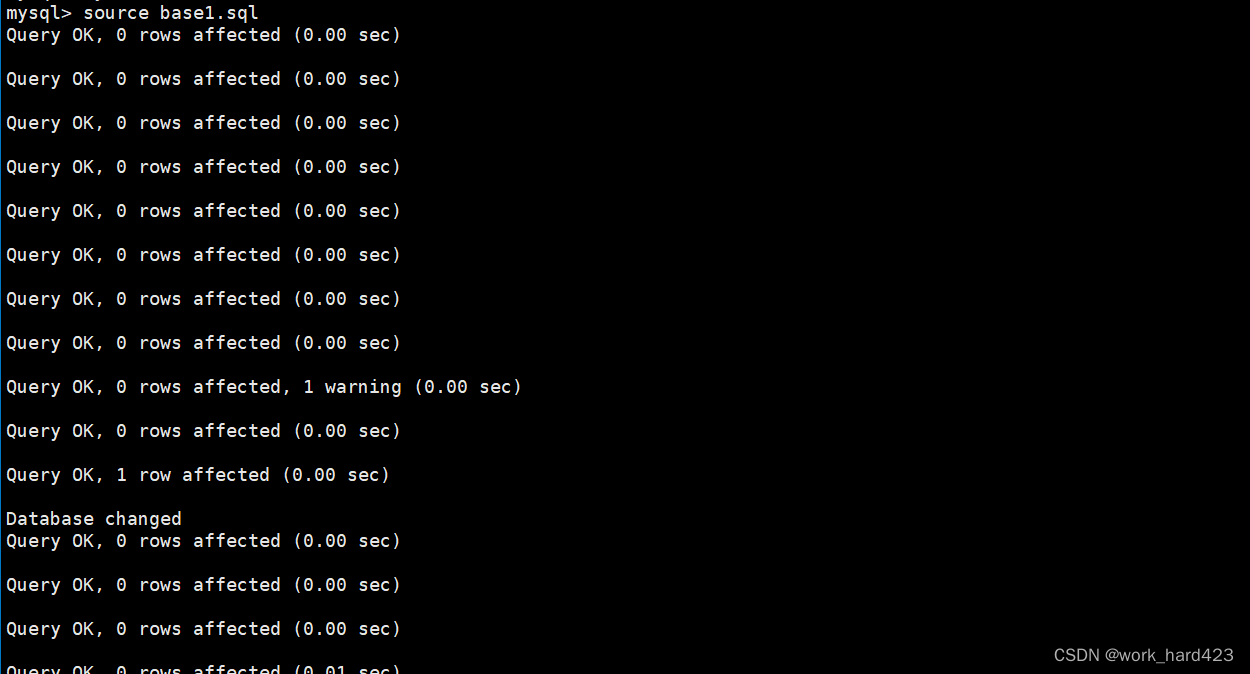
实际恢复数据库的时候就是按顺序执行数据库备份文件中的SQL语句,如下图所示,执行完毕后数据库也就恢复出来了,同时该数据库下的两张表,以及表当中的数据也都恢复出来了。
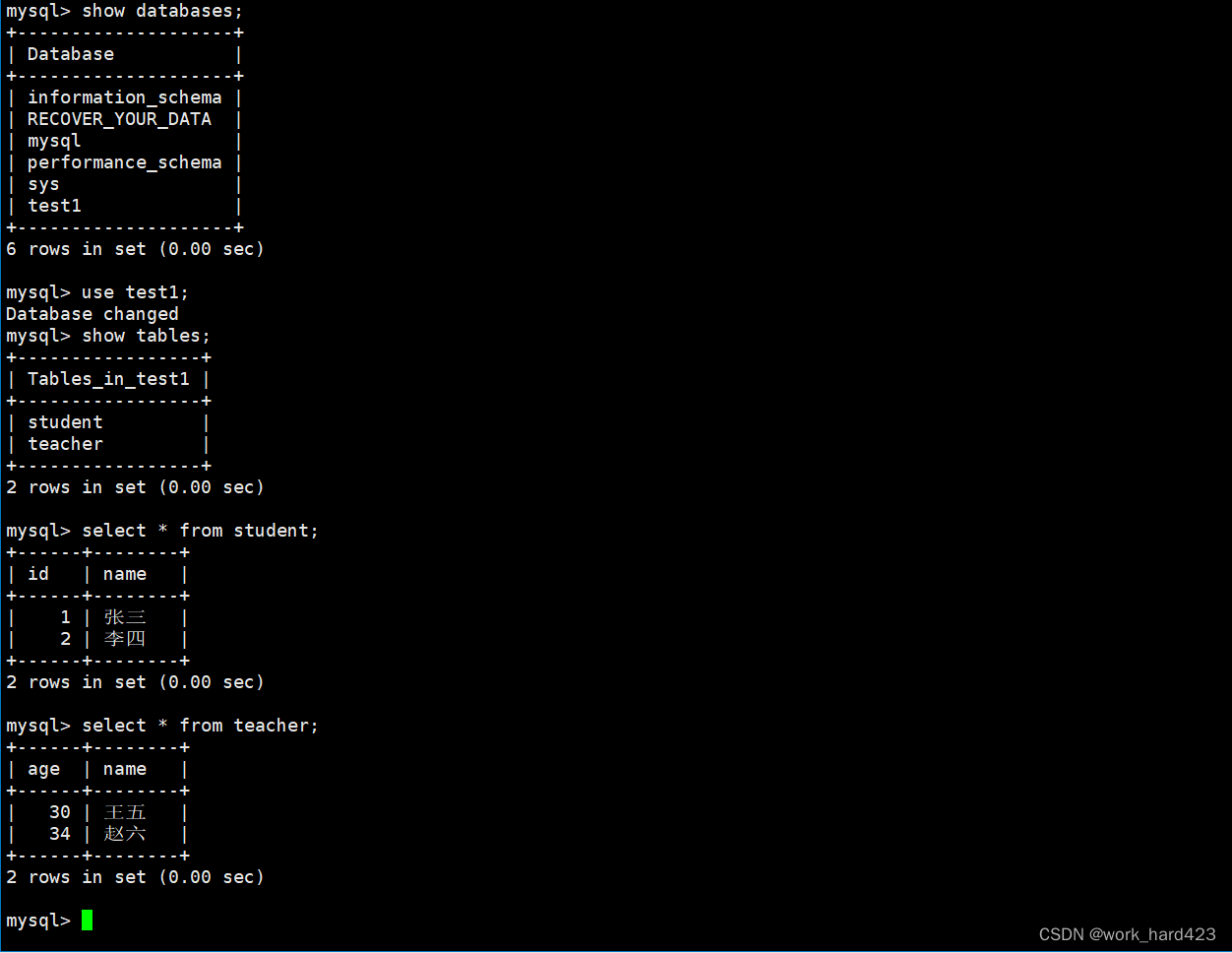
表的备份和恢复
表的备份
mysqldump -P 端口号 -u 用户名 -p 密码 数据库名 表名1 表名2 ... > 表备份存储的文件路径
使用上面的Linux命令即可对指定数据库进行备份。如下图1所示,如果在数据库test1中除了student和teacher表之外,还有其他的表,但我们又只想备份数据库test1中的student表和teacher表,这时就可以如下图2所示,在命令行中执行如下命令,并指定将备份后产生的文件存放在当前目录下(即用户在哪个路径下调用mysqldump命令,该备份文件就会被放在哪个路径下)。
- 图1如下。

- ?图2如下。
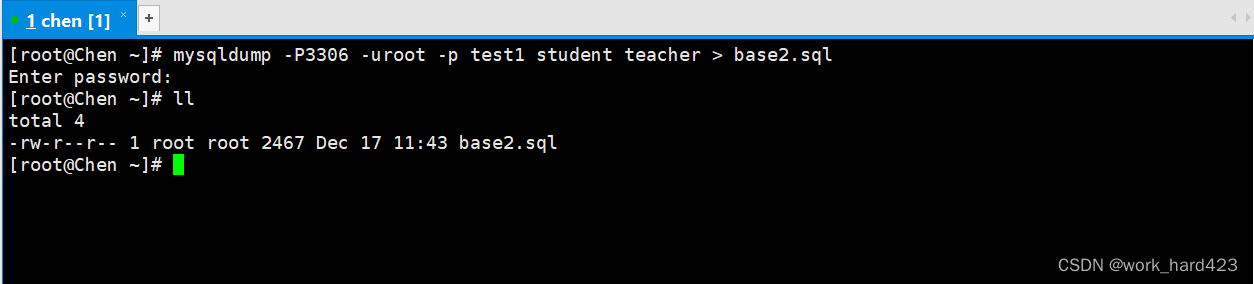
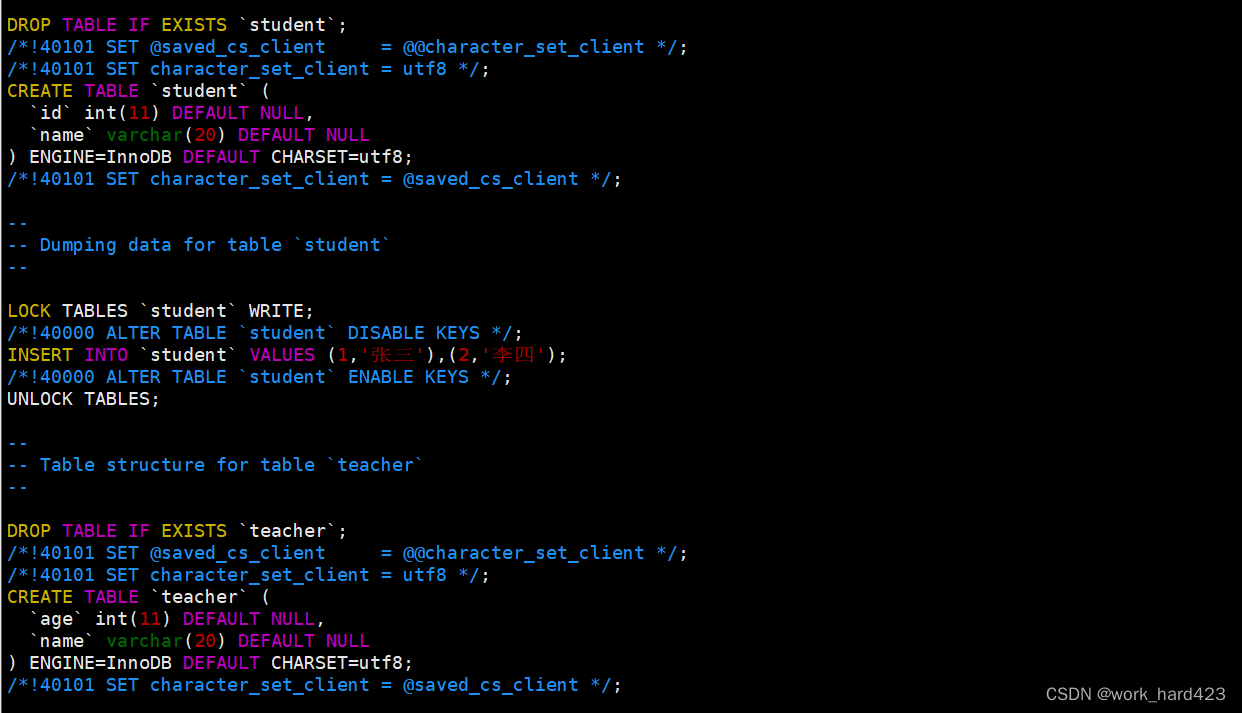
如下图所示,这时历史上与student和teacher表相关的SQL语句,就会被保存到备份文件当中。
表的恢复?
表恢复之前需要先选中一个数据库,表明需要将表恢复到哪一个数据库中,为了防止恢复出来的表与该数据库中已有的表的表名重复,一般在恢复表时会选择创建一个空的数据库,然后在该数据库中进行表的恢复。
在数据库中使用如下命令即可对指定表进行恢复:
source 表备份存储的文件路径
为了演示表恢复,我们先将刚才的数据库删除。如下:

如下图所示,这时创建一个空的数据库并在该数据库中执行如下命令即可对表进行恢复。
如下图所示,当备份文件中的SQL语句执行完毕后,该数据库下就恢复出了student和teacher表,并且表当中的数据也都恢复出来了。

查看连接情况
如下图所示,使用SQL语句show processlist即可查看当前连接MySQL的用户,说明一下:
- Id列:一个标识,可以在MySQL中通过kill id杀死指定id的服务线程。MySQL为多个客户端提供服务时并没有选择多路转接等方案,而是多线程模式,通过创建多个服务线程为客户端提供服务。
- User列:User列上的值表示目前有哪些用户登录MySQL客户端进程mysql连接了MySQL服务端进程mysqld。
- Host列:显示这个语句是从哪个IP的哪个端口上发出的,可用来追踪用户。
- db列:用于查看MySQL中所有用户正在use使用哪个数据库DB(或者说查看所有用户正处于Linux系统下/var/lib/mysql路径上的哪个目录文件中),比如如果用户wang正在use使用数据库test1,则db列上就会显示出test1。
- Command列:Command列中的每个值表示该MySQL服务线程目前正在执行的SQL命令的类型。以下是一些可能在Command列中看到的常见值:Sleep: 表示线程当前正在空闲等待新请求。Query: 表示线程正在执行一个查询操作。Connect: 表示线程正在建立一个新的连接。Binlog Dump: 表示线程正在复制二进制日志。Prepare: 表示线程正在执行一个准备语句的操作。Execute: 表示线程正在执行一个准备语句的执行操作。Init DB: 表示线程正在更改当前数据库。Killed: 表示线程已被强行终止。
- State列:State列中的每个值表示该MySQL服务线程目前执行SQL命令时的状态。
- Time列:表示该MySQL服务线程处于当前State状态的时间,单位是秒。
- Info列:表示该MySQL服务线程正在执行的SQL语句(或是已经执行完毕,但是最新执行的一条SQL语句),默认只显示前100个字符,如果要看全部信息,需要使用show full processlist。
SQL语句show processlist可以告诉我们当前有哪些用户连接到我们的MySQL,如果查出某个用户不是正常登录的,那么很有可能你的数据库被人入侵了,以后如果发现自己的数据库比较慢时,可以用这个SQL语句来查看数据库的连接情况。

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Linux学习记录——??? http协议
- 告别内存容量焦虑,光威龙武系列DDR5内存条48GB才799
- EasyExcel表头宽度根据数据内容自适应+自动换行
- 【Flink】 Flink实时读取mysql数据
- JavaSE语法之十:抽象类(超全!!!)
- 【从原理到应用,只需3分钟】期望值最大化 EM 算法:睹始知终
- 接教程美食外卖美团代付好友代付商城打车搭建叫教程
- 微信扫码支付
- Python打印Python环境、PyTorch和CUDA版本、GPU数量名称等信息
- C语言全局变量使用编程技巧总结