爬取彼案壁纸
代码展现: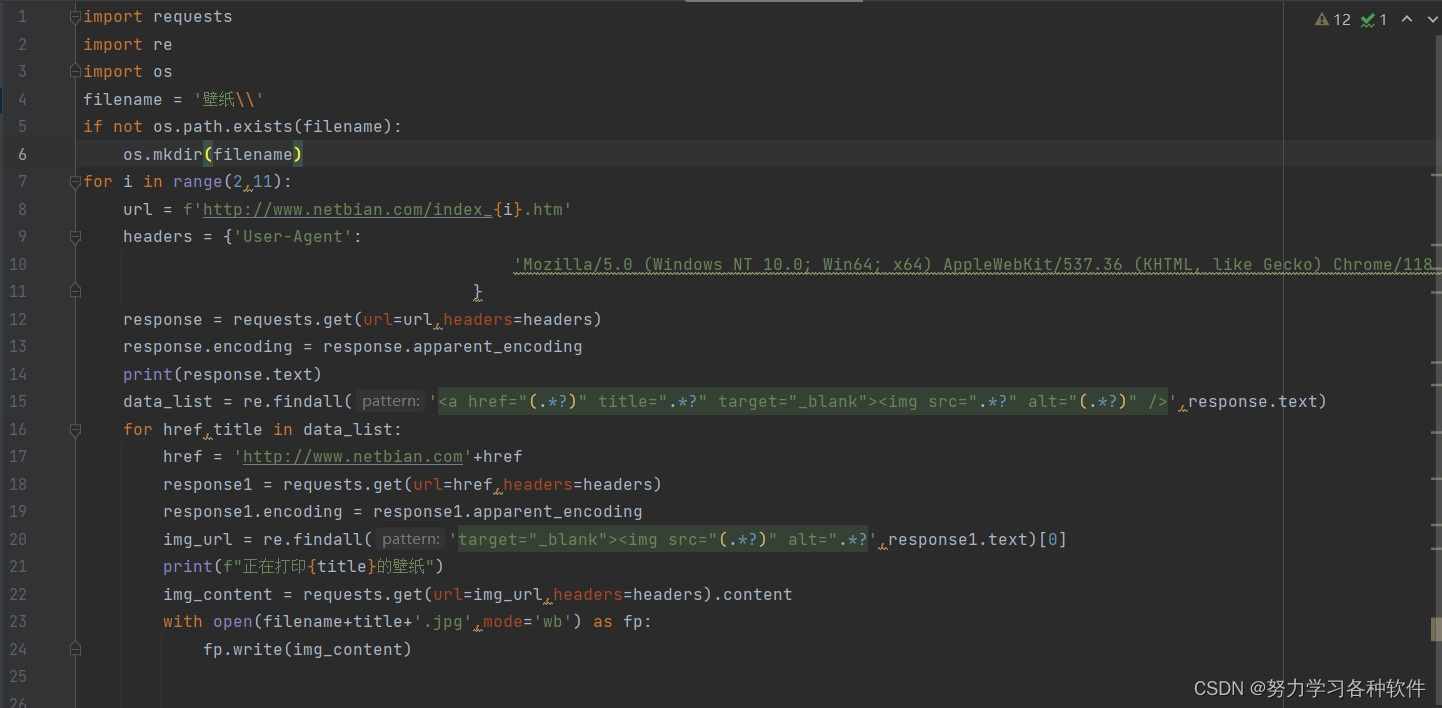
具体代码:
import requests
import re
import os
filename = '壁纸\\'
if not os.path.exists(filename):
? ? os.mkdir(filename)
for i in range(2,11):
? ? url = f'http://www.netbian.com/index_{i}.htm'
? ? headers = {'User-Agent':
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36',
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?}
? ? response = requests.get(url=url,headers=headers)
? ? response.encoding = response.apparent_encoding
? ? print(response.text)
? ? data_list = re.findall('<a href="(.*?)" title=".*?" target="_blank"><img src=".*?" alt="(.*?)" />',response.text)
? ? for href,title in data_list:
? ? ? ? href = 'http://www.netbian.com'+href
? ? ? ? response1 = requests.get(url=href,headers=headers)
? ? ? ? response1.encoding = response1.apparent_encoding
? ? ? ? img_url = re.findall('target="_blank"><img src="(.*?)" alt=".*?',response1.text)[0]
? ? ? ? print(f"正在打印{title}的壁纸")
? ? ? ? img_content = requests.get(url=img_url,headers=headers).content
? ? ? ? with open(filename+title+'.jpg',mode='wb') as fp:
? ? ? ? ? ? fp.write(img_content)
结果展现: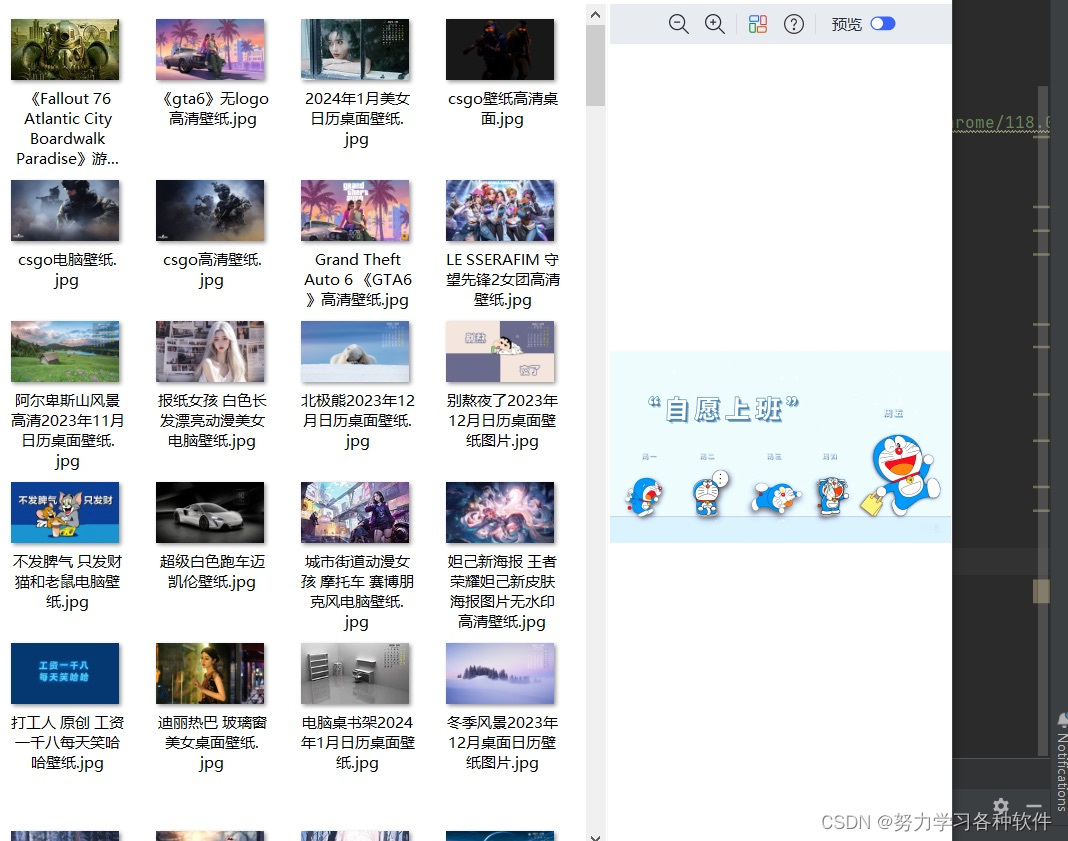 ?
?
总结:这个案例不难,静态网页,爬取二进制数据
复习了一番,注意编码的问题,response.encoding=response.apparent_encoding
学到的新东西:
1.print(response.text)后,在下方,按住ctrl+f键可以搜索如下图
 ?
?
?点击:
点击.*可以用正则表达式,如果用正则表达解析数据,可以在这里尝试,可以看见匹配的数量,然后再写入代码中。
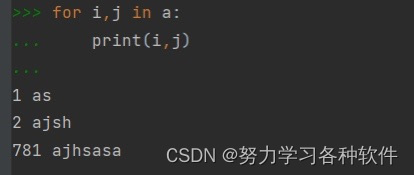
2.列表中嵌套元祖,如何快速找出元祖中的元素。
如:a=[(1,'as'),(2,'ajsh'),(781,'ajhsasa')]

 ?
?
用第二张图的方法,可以直接取出元素
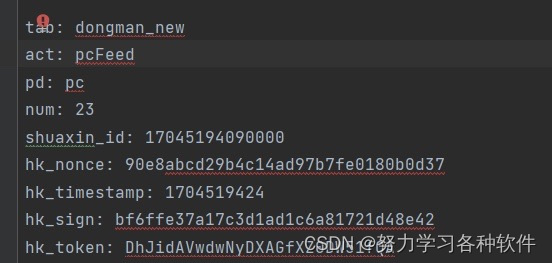
3.遇到参数很多,加冒号很麻烦怎么办,如下图:
?
?首先选中代码,按ctrl+r出现下图:
点击·*进入正则,写入下图: ?
?
代码是:?(.*?): (.*)
'$1': '$2',
点击replaceall
结果展现: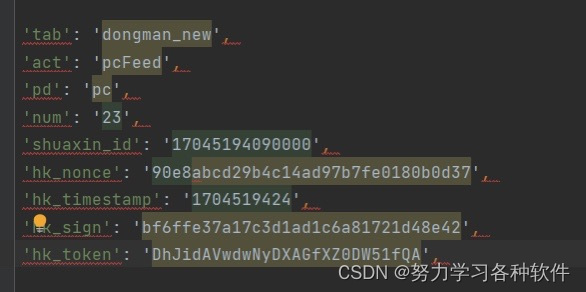
?
?
?
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- P1088 [NOIP2004 普及组] 火星人(全排列怎么从中间开始?)
- ceph之rados设计原理与实现第四章:存储的基石OSD
- 黑客圈内打死都不会说的秘密,自学黑客技术最快的方法。
- 基于粒子群算法的电力分配与电网建设多目标优化求解
- Axure
- 2024数字安全十大技术趋势预测,不容忽视!
- Spring声明式事务失效原因总结
- web安全学习笔记【07】——非http\https抓包
- OpenGL如何基于glfw库 进行 点线面 已解决
- IaC基础设施即代码:Terraform 使用 dynamic动态内联块 创建docker资源