MySQL基础应用之DDL、DCL、DML、DQL
发布时间:2024年01月14日
文章目录
前言
本章内容主要以mysql基础应用、代名词、DDL语句的学习为主,通过前两章内容,已了解了数据库的安装、sql的执行过程、基础管理的学习。
一、sql基础应用
sql介绍
1、结构化的查询语言
2、关系型数据库通用的命令
3、遵循SQL92的国际标准
sql常用种类
DDL 、DML 、DCL 、DQL
sql引入-数据库的逻辑结构
库
库名
库属性: 字符集、排序规则
表
表名
表属性: 存储引擎、字符集、排序规则
列名
列属性: 数据类型,约束,其他属性
数据行
字符集
show charset; 查看mysql都有哪些字符集;建议使用utf8(占3个字节)、utf8mb4(占4个字节)
排序规则
show collation; 查看mysql都有哪些排序规则,建议使用utf8mb4_general_ci(大小写不敏感)、utf8mb4_bin(大小写敏感)
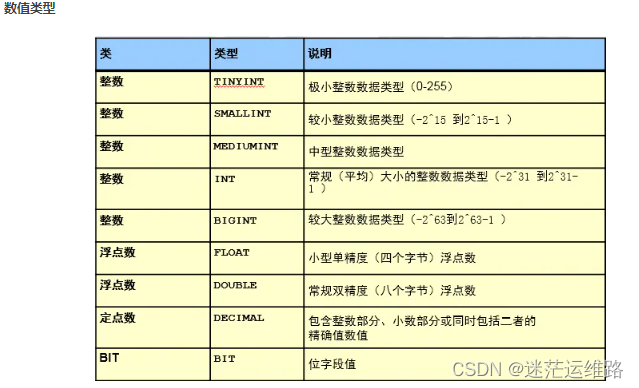
数据类型
数字类型 --> 整数、浮点数 tinyint : -128~127 、 int :-2^31~2^31-1
说明:手机号是无法存储到int的。一般是使用char类型来存储收集号
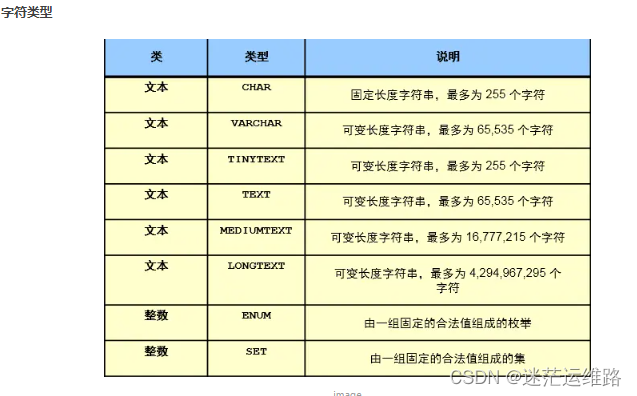
字符串 -->
char(长度)(定长字符串类型,不管字符串长度多长,都立即分配100个字符长度的存储空间,未占满的空间使用“空格”填充、 varchar(长度)(变长字符串类型,每次存储数据前,先判断长度,按需分配空间)、enum('bj','tj','sh')
枚举类型,比较适合于将来此列的值是固定范围内的特点,可以使用enum,可以很大程度的优化我们的索引结构。
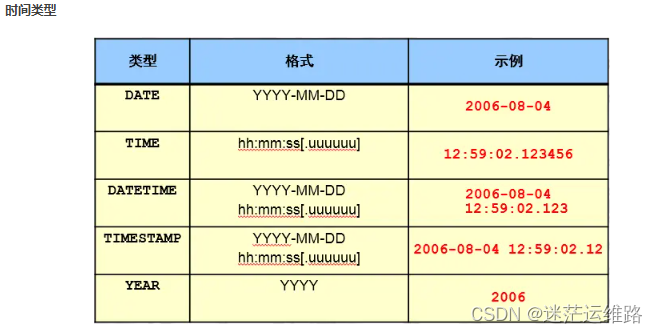
时间 --> datatime、timestamp
二进制
注意:
列值不能为空,也是表设计的规范,尽可能将所有的列设置为非空。可以设置默认值为0
unique key:
唯一键,列值不能重复
unsigned:
无符号 针对数字列,非负数。
其他属性:
key :索引,可以在某列上建立索引,来优化查询
二、列、表属性
1、列属性
约束(一般建表时添加):
primary key :主键约束
设置为主键的列,此列的值必须非空且唯一,主键在一个表中只能有一个,但是可以有多个列一起构成。
not null :非空约束
列值不能为空,也是表设计的规范,尽可能将所有的列设置为非空。可以设置默认值为0
unique key :唯一键
列值不能重复
unsigned :无符号
针对数字列,非负数。
其他属性:
key :索引
可以在某列上建立索引,来优化查询,一般是根据需要后添加
default :默认值
列中,没有录入值时,会自动使用default的值填充
auto_increment :自增长
针对数字列,顺序的自动填充数据(默认是从1开始,将来可以设定起始点和偏移量)
comment : 注释
2、表属性
存储引擎:
InnoDB(默认的)
字符集:
utf8
utf8mb4
排序规则:
utf8mb4_general_ci(大小写不敏感)
utf8mb4_bin(大小写敏感)
三、sql学习记录—DDL应用之数据库定义语言
1、建库规范
a、建库使用小写字符
b、库名不能以数字开头
c、不能是数据库内部的关键字
d、必须设置字符集
2、创建库并设置字符集、校验规则
mysql> create database test charset utf8mb4 collate utf8mb4_bin;
Query OK, 1 row affected (0.00 sec)
3、查看数据库
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
| test |
+--------------------+
5 rows in set (0.00 sec)
mysql> show create database test;
+----------+--------------------------------------------------------------------------------------+
| Database | Create Database |
+----------+--------------------------------------------------------------------------------------+
| test | CREATE DATABASE `test` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_bin */ |
+----------+--------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
4、删除数据库
(生产禁止该操作,如需操作,需要层层审批)
mysql> drop database test;
Query OK, 0 rows affected (0.00 sec)
5、修改数据库字符集
注意: 一定是从小往大改,比如 utf8-->utf8mb4
mysql> create database test;
Query OK, 1 row affected (0.00 sec)
mysql> show create database test;
+----------+-----------------------------------------------------------------+
| Database | Create Database |
+----------+-----------------------------------------------------------------+
| test | CREATE DATABASE `test` /*!40100 DEFAULT CHARACTER SET latin1 */ |
+----------+-----------------------------------------------------------------+
1 row in set (0.00 sec)
mysql> alter database test charset utf8mb4;
Query OK, 1 row affected (0.00 sec)
mysql> show create database test;
+----------+------------------------------------------------------------------+
| Database | Create Database |
+----------+------------------------------------------------------------------+
| test | CREATE DATABASE `test` /*!40100 DEFAULT CHARACTER SET utf8mb4 */ |
+----------+------------------------------------------------------------------+
1 row in set (0.00 sec)
四、sql学习记录—DDL应用之表定义语言
1、建表规范
a、表名小写字母,不能是数字开头、内置关键字
b、尽量跟业务相关
c、选择合适的数据类型及长度
d、每个列设置not null +default,对于数据0填充,对于字符使用有效字填充
e、每个列添加注释
f、表必须设置存储引擎类型、字符集
g、主键列尽量是无关列数字列,最好是自增长
h、enum枚举类型不要保存数字,只能是字符串类型
2、建表
表名、列名、列属性、表属性
常用的列属性
PRIMARY KEY :主键约束,表中只能有一个且非空
NOT NULL : 非空约束,不允许空值
UNIQUE KEY : 唯一键约束,不允许重复
DEFAULT : 一般配合NOT NULL 使用
UNSIGNED: 无符号,一般是配合数字列,非负数
COMMENT: 注释,每列必须要有自己的注释
AUTO_INCRMENT: 自增长的列
mysql> create table test.stu(
id int primary key not null auto_increment comment "学号",
sname varchar(255) not null comment "姓名",
age tinyint unsigned not null default 0 comment '年龄',
gender enium('m','f','n') not null default 'n' comment '性别',
intime datetime not null default NOW() comment '入学时间'
) engine innodb charset utf8mb4 comment '学生信息表';
Query OK, 0 rows affected (0.01 sec)
3、查询建表信息
查询建表信息
mysql> show tables;
+----------------+
| Tables_in_test |
+----------------+
| stu |
+----------------+
1 row in set (0.00 sec)
4、创建一个表结构一样的表
mysql> create table students like stu;
Query OK, 0 rows affected (0.01 sec)
5、删表
mysql> drop table students;
Query OK, 0 rows affected (0.01 sec)
6、修改表
a、在stu表中添加手机号列 (注意: 当数量过大可能会产生锁表现象)
mysql> desc stu; #查看表结构
+--------+---------------------+------+-----+-------------------+----------------+
| Field | Type | Null | Key | Default | Extra |
+--------+---------------------+------+-----+-------------------+----------------+
| id | int(11) | NO | PRI | NULL | auto_increment |
| sname | varchar(255) | NO | | NULL | |
| age | tinyint(3) unsigned | NO | | 0 | |
| gender | enum('m','f','n') | NO | | n | |
| intime | datetime | NO | | CURRENT_TIMESTAMP | |
+--------+---------------------+------+-----+-------------------+----------------+
5 rows in set (0.00 sec)
mysql> alter table stu add phone varchar(11) not null unique comment '手机号';
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
b、在sname列后加微信列
mysql> alter table stu add wechat varchar(64) not null unique comment '微信号' after sname;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
c、在第一列前加一列card
mysql> alter table stu add card int not null unique comment '身份证号' first;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
d、把刚才添加的列删除掉(注意: 可能会产生锁表现象)
mysql> alter table stu drop card;
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
e、修改sname数据类型的属性
mysql> alter table stu modify sname varchar(64) not null comment '姓名';
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
f、修改gender改为sg 数据类型改为char类型
mysql> alter table stu change gender sg char(4) not null comment '性别';
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
五、sql学习记录—DCL应用
grant all on *.* to root@'10.0.0.%' identified by '123'; 授权
revoke delete on 库名.表名 from 用户名@'白名单'; 权限回收
六、sql学习记录—DML应用
1、insert学习–>按照表结构插入一条学生信息
---偷懒写法
mysql> insert stu values(1,'张三','rtsj5k',22,'m',NOW(),'17245679876');
Query OK, 1 row affected (0.00 sec)
mysql> select * from stu;
+----+--------+--------+-----+----+---------------------+-------------+
| id | sname | wechat | age | sg | intime | phone |
+----+--------+--------+-----+----+---------------------+-------------+
| 1 | 张三 | rtsj5k | 22 | m | 2024-01-13 17:07:55 | 17245679876 |
+----+--------+--------+-----+----+---------------------+-------------+
1 row in set (0.00 sec)
---规范写法
mysql> insert into stu (sname,wechat,age,sg,phone) values('李四','kmndy',23,'f','18976585647');
Query OK, 1 row affected (0.00 sec)
mysql> select * from stu;
+----+--------+--------+-----+----+---------------------+-------------+
| id | sname | wechat | age | sg | intime | phone |
+----+--------+--------+-----+----+---------------------+-------------+
| 1 | 张三 | rtsj5k | 22 | m | 2024-01-13 17:07:55 | 17245679876 |
| 2 | 李四 | kmndy | 23 | f | 2024-01-13 17:11:00 | 18976585647 |
+----+--------+--------+-----+----+---------------------+-------------+
2 rows in set (0.00 sec)
---规范写法--一次性插入多条数据
mysql> insert stu (sname,wechat,age,sg,phone) values('王五','djgnoe',22,'f','18976659847'),('可乐','kmdjron',23,'m','16789786756');
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> select * from stu;
+----+--------+---------+-----+----+---------------------+-------------+
| id | sname | wechat | age | sg | intime | phone |
+----+--------+---------+-----+----+---------------------+-------------+
| 1 | 张三 | rtsj5k | 22 | m | 2024-01-13 17:07:55 | 17245679876 |
| 2 | 李四 | kmndy | 23 | f | 2024-01-13 17:11:00 | 18976585647 |
| 3 | 王五 | djgnoe | 22 | f | 2024-01-13 17:14:13 | 18976659847 |
| 4 | 可乐 | kmdjron | 23 | m | 2024-01-13 17:14:13 | 16789786756 |
+----+--------+---------+-----+----+---------------------+-------------+
4 rows in set (0.00 sec)
2、update学习–更新信息
注意:update语句必须要加where。
mysql> UPDATE stu SET sname='赵四' WHERE id=2;
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from stu;
+----+--------+---------+-----+----+---------------------+-------------+
| id | sname | wechat | age | sg | intime | phone |
+----+--------+---------+-----+----+---------------------+-------------+
| 1 | 张三 | rtsj5k | 22 | m | 2024-01-13 17:07:55 | 17245679876 |
| 2 | 赵四 | kmndy | 23 | f | 2024-01-13 17:11:00 | 18976585647 |
| 3 | 王五 | djgnoe | 22 | f | 2024-01-13 17:14:13 | 18976659847 |
| 4 | 可乐 | kmdjron | 23 | m | 2024-01-13 17:14:13 | 16789786756 |
+----+--------+---------+-----+----+---------------------+-------------+
4 rows in set (0.00 sec)
3、delete学习–删除一条信息
mysql> DELETE FROM stu WHERE id=3;
Query OK, 1 row affected (0.00 sec)
mysql> select * from stu;
+----+--------+---------+-----+----+---------------------+-------------+
| id | sname | wechat | age | sg | intime | phone |
+----+--------+---------+-----+----+---------------------+-------------+
| 1 | 张三 | rtsj5k | 22 | m | 2024-01-13 17:07:55 | 17245679876 |
| 2 | 赵四 | kmndy | 23 | f | 2024-01-13 17:11:00 | 18976585647 |
| 4 | 可乐 | kmdjron | 23 | m | 2024-01-13 17:14:13 | 16789786756 |
+----+--------+---------+-----+----+---------------------+-------------+
3 rows in set (0.00 sec)
--全表删除
DELETE FROM stu
truncate table stu;
--区别:
delete: DML操作, 是逻辑性质删除,逐行进行删除,速度慢.
truncate: DDL操作,对与表段中的数据页进行清空,速度快.
--伪删除 用update来替代delete,最终保证业务中查不到(select)即可
1.添加状态列
ALTER TABLE stu ADD state TINYINT NOT NULL DEFAULT 1 ;
SELECT * FROM stu;
2. UPDATE 替代 DELETE
UPDATE stu SET state=0 WHERE id=6;
3. 业务语句查询
SELECT * FROM stu WHERE state=1;
七、sql学习记录—DQL应用
1、select单独使用的情况
mysql> select @@basedir; #查看安装目录
mysql> select database(); #查看当前库
mysql> select now(); #查看当前时间
2、select 通用语法 单表查询
select 列名1,列名2 from 表名 where 条件 group by 条件 having 条件 order by 条件 limit;
示例:
查询表中所有信息
mysql> select id,sname,phone from stu;
where等值查询 -- 查询id=1的数据
mysql> select sname,phone from stu where id=1;
where不等值查询(大于、小于、大于等于、小于等于) -- 查询id大于1的数据
mysql> select sname,phone from stu where id>1;
where配合逻辑连接符(and、or)
-- 查询id为1并且姓名为张三的手机号
mysql> select phone from stu where id=1 and name='张三';
-- 查询id为1或者姓名为张三的手机号
mysql> select phone from stu where id=1 or name='张三';
where配合 like 子句进行模糊查询 查询姓名中 '李' 开头的数据
mysql> select * from stu where sname like '李%';
注意: 不要出现类似于 %xx% 前后都有百分号的语句,因为不走索引,功能上虽然能实现,但性能比较差
where 配合in 语句 查询李四和王五的信息
mysql> select * from stu where sname in ('李四','王五');
3、select 配合group by +聚合函数应用
常用聚合函数
max() 最大值
min() 最小值
avg() 平均值
count() 个数
sum() 总和
group_concat() 列转行
group by
将某列中有共同条件的数据行,分成一组,然后在进行聚合函数操作
示例:
查询每个国家的城市个数
mysql> select countrycode,count(id) from city group by countrycode;
查询每个国家的总人口数
mysql> select countrycode,sum(population) from city group by countrycode;
统计中国每个省城市的名字列表
mysql> select district,group_concat(name ) from city where countrycode='CHN' group by district;
4、select 配合having 应用
示例:
统计每个国家的总人口数量,将总人口数大于1亿的过滤出来
mysql> select countrycode,sum(population) from city group by countrycode having SUM(population)>100000000;
5、select 配合order by子句
desc 从大到小排序
默认就是从小到大排序
示例:
统计每个国家的总人口数量,将总人口数量大于5000w的过滤出来,并且按照从大到小进行排序
mysql> select countrycode,sum(population) from city group by countrycode having SUM(population)>50000000 order by sum(population) desc;
6、select 配合limit子句
示例:
统计每个国家的总人口数量,将总人口数量大于5000w的过滤出来,并且按照从大到小进行排序,显示前3个数据
mysql> select countrycode,sum(population) from city group by countrycode having SUM(population)>50000000 order by sum(population) desc limit 3;
统计每个国家的总人口数量,将总人口数量大于5000w的过滤出来,并且按照从大到小进行排序,显示第4-6名 limit 3 offset 3 跳过3行,显示一共3行
mysql> select countrycode,sum(population) from city group by countrycode having SUM(population)>50000000 order by sum(population) desc limit 3 offset 3;
7、select配合union all 子句
示例;
查询中国或者美国的城市信息
原句 myslq > select * from city where countrycode='CHN' or countrycode='USA';
使用union all 改写
改写后 mysql > select * from city where countrycode='CHN' union all select * from city where countrycode='USA';
注意: 在索引方面,改写后的语句比原句的索引等级要高。
union和union all的区别?
union 会去重复
union all 不会去重复
8、select 配合 distinct 去重复
示例
查找城市属于哪个国家
mysql > SELECT DISTINCT(countrycode) FROM city ;
总结
以上 sql语句和案例仅供参考
文章来源:https://blog.csdn.net/weixin_50902636/article/details/135578296
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Python中的函数
- AI视频-stable-video-diffusio介绍
- process.cwd() 与 __dirname 的区别
- Linux 一键部署grafana
- python中的pprint
- C函数详解 | 函数的作用、定义与声明、函数的调用、函数与指针
- 第38集《佛法修学概要》
- 2023年度回顾
- Newtonsoft.Json.dll关于json字符串转换为类
- stm32f407 bm -> freertos