JVM内存管理
一.java程序运行过程
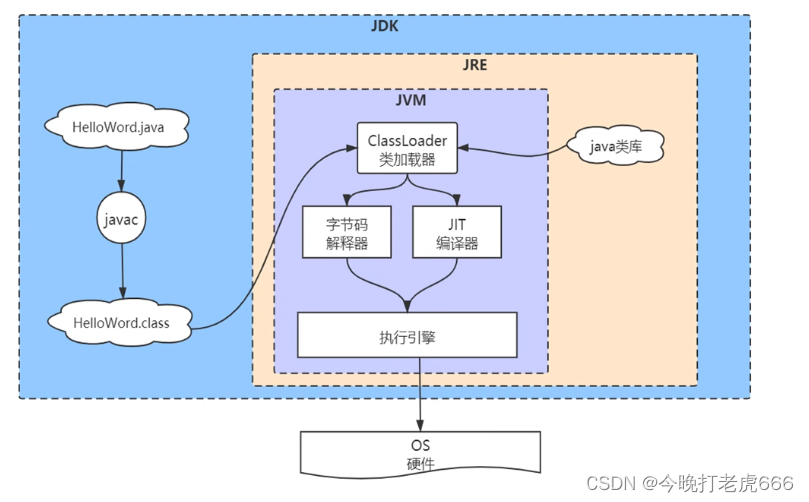
JDK,JRE,JVM?
JVM把我们的字节码翻译成机械能执行的机械码。
JRE除了包含JVM之外,还包含很多java的原生依赖库。
JDK除了包含JRE之外,还包含很多工具,比如javac工具。
.java文件是怎么被执行的
我们的.java文件会被jdk里面的javac工具编译成.class文件,最后在JVM中通过类加载器加载,交给执行引擎来执行,执行有两种方式,一种是通过字节码解释器解释执行,一种事通过JIT编译器执行。
解释执行:JVM是C++语言写的,我们在java语言中new出一个对象,JVM的字节码解释器会帮我我们自动解释成C++,最后new出一个对象。
?解释执行缺点:经过JVM的翻译,速度慢一点。
如果一个方法,一段代码循环次数达到一定次数后,会通过JIT执行(hotsport)。
JIT就是直接把java代码翻译成汇编码(放在JVM的codecache里面),不需要经过解释器处理,好处是比较快,坏处是要对代码进行提前翻译,编译速度会比较长。
JVM的跨平台性:我们写一个类可以在不同的平台运行(windows,linux,android)。并不是说所有平台安装的是一个JVM,官网上对不用操作系统做了不同的JVM包适配。
JVM的语言无关性:与上层使用什么语言无关,只要最后生成的.class文件符合JVM的语法规范就行。
二.运行时数据区域

Java虚拟机在执行Java程序的过程中会把它所管理的内存划分为若干个不同的数据区域。
运行时数据区:JVM把它管理的内存区域虚拟化后就是运行时数据区。
直接内存(堆外内存):假如手机内存是8G,JVM虚拟化后的运行时数据区是5G,还有3G内存是JVM没有虚拟化的,但是在Java里面可以通过某个方法区申请这块内存,使用后需要释放。这块内存就叫直接内存,也叫堆外内存。
运行时数据区按类型区分可以分为线程私有区域和线程共享区域。
线程共享区
方法区和堆
方法区存储信息主要:类型信息,域(Field)信息,方法(Method)信息,常量,静态变量,即时编译器编译后的代码缓存(JIT的缓存)。
在java加载类的时候,第一步就是:Java 虚拟机会根据类的全限定名(Package + Class Name)加载 .class 文件,生成对应的二进制字节码,并将其存储在方法区中。在加载阶段之前,Java 虚拟机会先检查该类是否已经被加载过,如果已经被加载过,则不会再加载该类。
public class ObjectAndClass {
//静态变量,存储在方法区里面
static int age = 18;
//常量,存储在方法区里面
final static int sex = 1;
//成员变量,是一个对象,存储到堆里面,但是person引用存储在栈里面,Person类型存储在方法区里面
Person person = new Person();
//成员变量,基础数据类型,分配在堆里面
private boolean isRight;
/**
* 引用类型总是被分配到“堆”上。不论是成员变量还是局部
* 基础类型总是分配到它声明的地方:成员变量在堆内存里,局部变量在栈内存里。
* @param args
*/
public static void main(String[] args) {
//局部变量,但是是个对象,存储在堆上,但是person引用存储在栈里面,Person类型存储在方法区里面
Person person1 = new Person();
//局部变量
int x = 8;
//局部变量
String a = "aaa";
//局部变量(对象)
ObjectAndClass objectAndClass = new ObjectAndClass();
objectAndClass.isRight = true;
}
static class Person {
private int age;
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
}? * 引用类型总是被分配到“堆”上。不论是成员变量还是局部
? * 基础类型总是分配到它声明的地方:成员变量在堆内存里,局部变量在栈内存里。?
方法区具体存储什么可参考:Java虚拟机(JVM)的方法区(Method Area)存储了什么内容?_jvm方法区存放什么-CSDN博客
java类的加载顺序:
Java 类的加载顺序 - 我爱学习网 (5axxw.com)
线程私有
虚拟机栈
每次启动一个线程,就会为当前线程创建一个虚拟机栈。
虚拟机栈:存储当前线程运行java方法所需的数据,指令,返回地址。
大小限制:-Xss

public class MethodAndStack {
public static void main(String[] args) {
A();
}
public static void A(){
B();
}
public static void B(){
C();
}
public static void C(){
}
}现在我们看到上诉代码,当我们启动这个程序,会为当前的线程创建一个虚拟机栈。这个虚拟机栈中存储当前线程运行java方法所需的数据,指令,返回地址。

当我们执行到main方法的时候,会往当前虚拟机栈中压入一个栈帧。

当我们执行main的时候,会跳入A方法,又往虚拟机栈里面压入A方法的栈帧。A方法有调B方法,又会往虚拟机栈里面压入B方法的栈帧。B方法最后调用C方法,会往虚拟机栈里面压入C方法的栈帧。
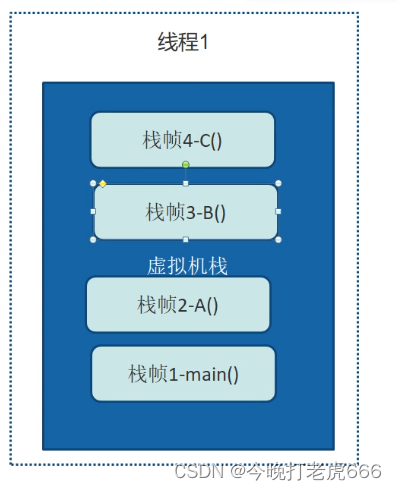
如果C方法执行完毕,C方法的栈帧从虚拟机栈里面退出;B方法,A方法,main方法执行完后,对应的栈帧都要从虚拟机栈里面退出。
栈溢出:如果我在A方法里面调用A方法,形成死递归的话,就会一直往虚拟机栈里面压入A方法的栈帧。栈帧会有一定的大小,当数量足够多的时候,虚拟机栈的内存就会不够,造成栈溢出。(方法调用层次太深也有可能)
栈帧
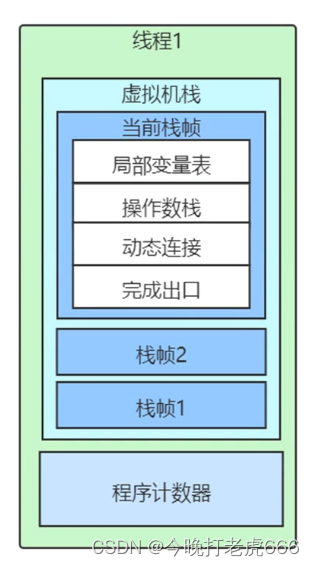
虚拟机栈:存储当前线程运行java方法所需的数据,指令,返回地址。
程序计数器:指向当前线程正在执行的字节码的地址。
栈帧:包括局部变量表,操作数栈,动态连接,完成出口。
我们先写一个Person类:
public class Person {
public int work()throws Exception{
int x =1;
int y =2;
int z =(x+y)*10;
return z;
}
public static void main(String[] args) throws Exception{
Person person = new Person();
person.work();
//方法属于本地方法 ---本地方法龙
person.hashCode();
}
}我们知道当执行到work方法的时候,会往当前线程的虚拟机栈压入一个栈帧,我们来看一下work方法执行的过程,栈帧里面都干了什么。
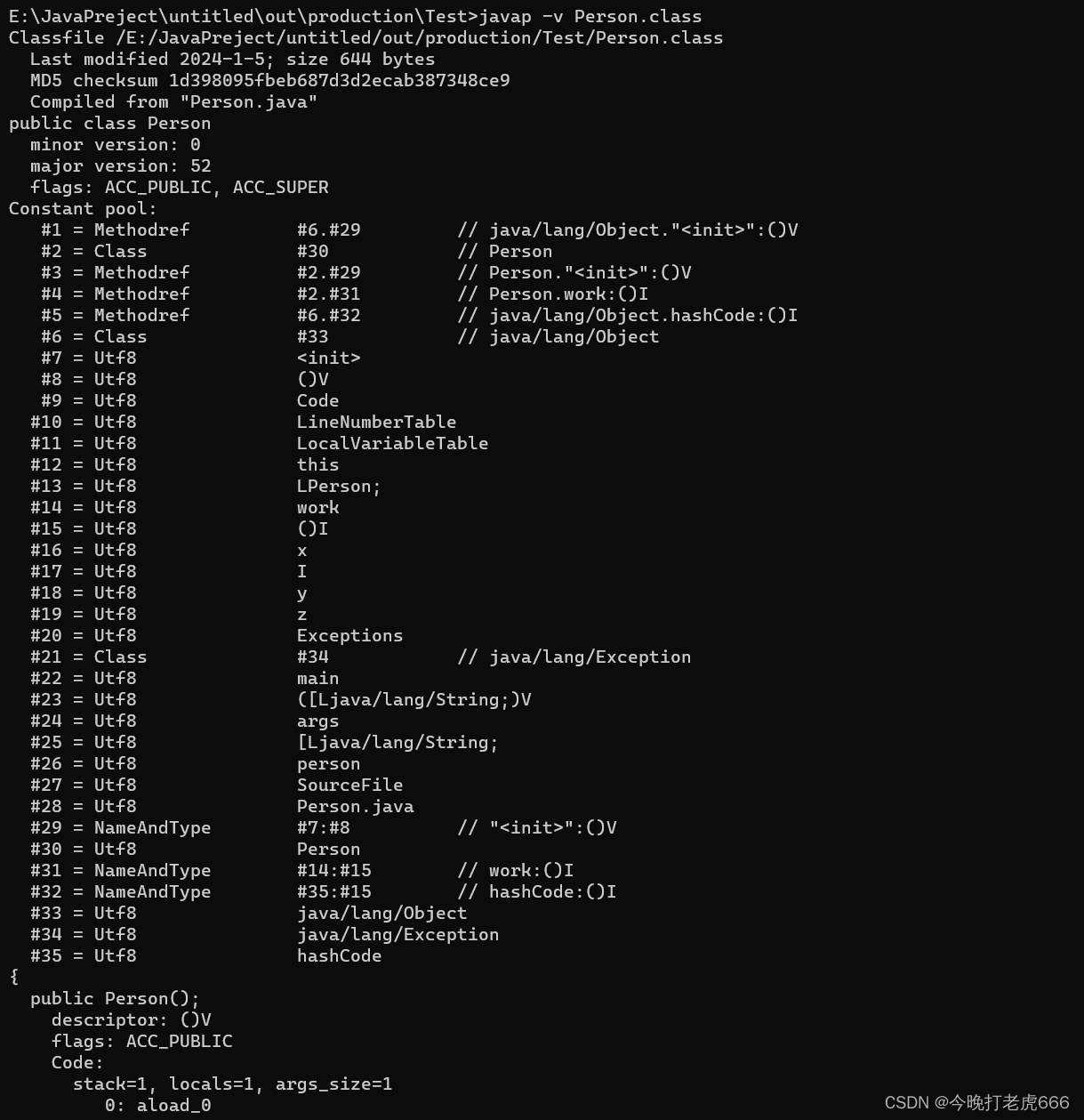
我们知道JVM执行的是.class文件,所以我们先找到.class文件。
?我们cmd到这个文件夹目录下,然后执行javap -v Person.class,生成的就是字节码:
?
?里面的Constant pool是静态常量池。
可以看到为我们自动生成了一个Person的构造方法,除此之外还有一个work方法,一个main方法。(就算我们自己不定义类的构造方法,字节码里面也会自动帮我们生成一个)
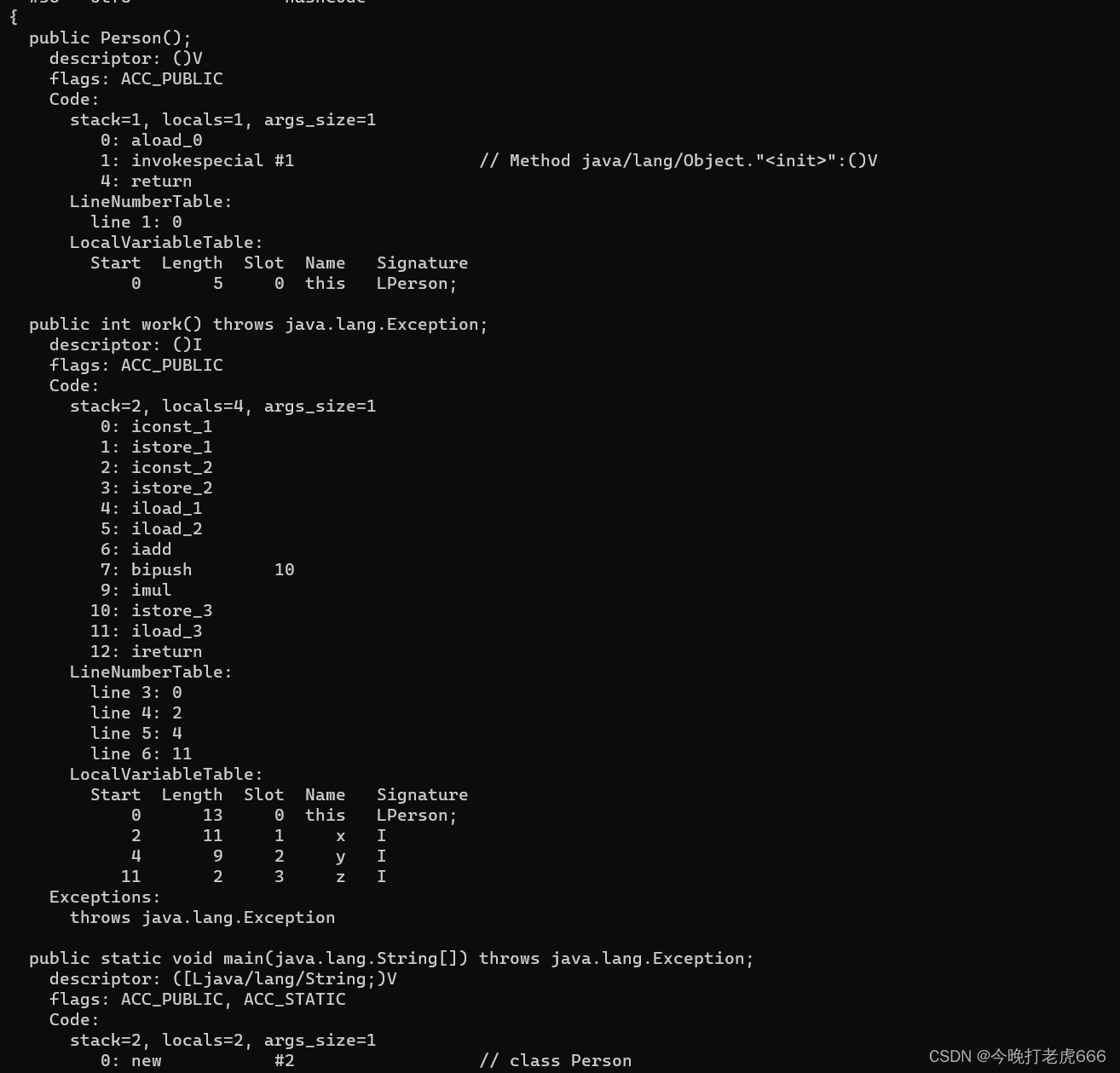
我们这边重点来看work方法里面的代码:

这些代码是什么意思呢?执行这些方法的时候,栈帧又会怎么变化?
我们看到最前面有0,1,2,3等等,这些是字节码的地址,给程序计数器使用的。0后面的iconst_1表示需要内存new出一个int的常量并且把它压入操作数栈。

当执行到1:istore_1的时候,程序计数器里面的count变成1,istore_1表示把操作数栈栈顶的数据放倒局部变量表下标为1的地方。istore_1最后面的表示的是局部变量表的位置。
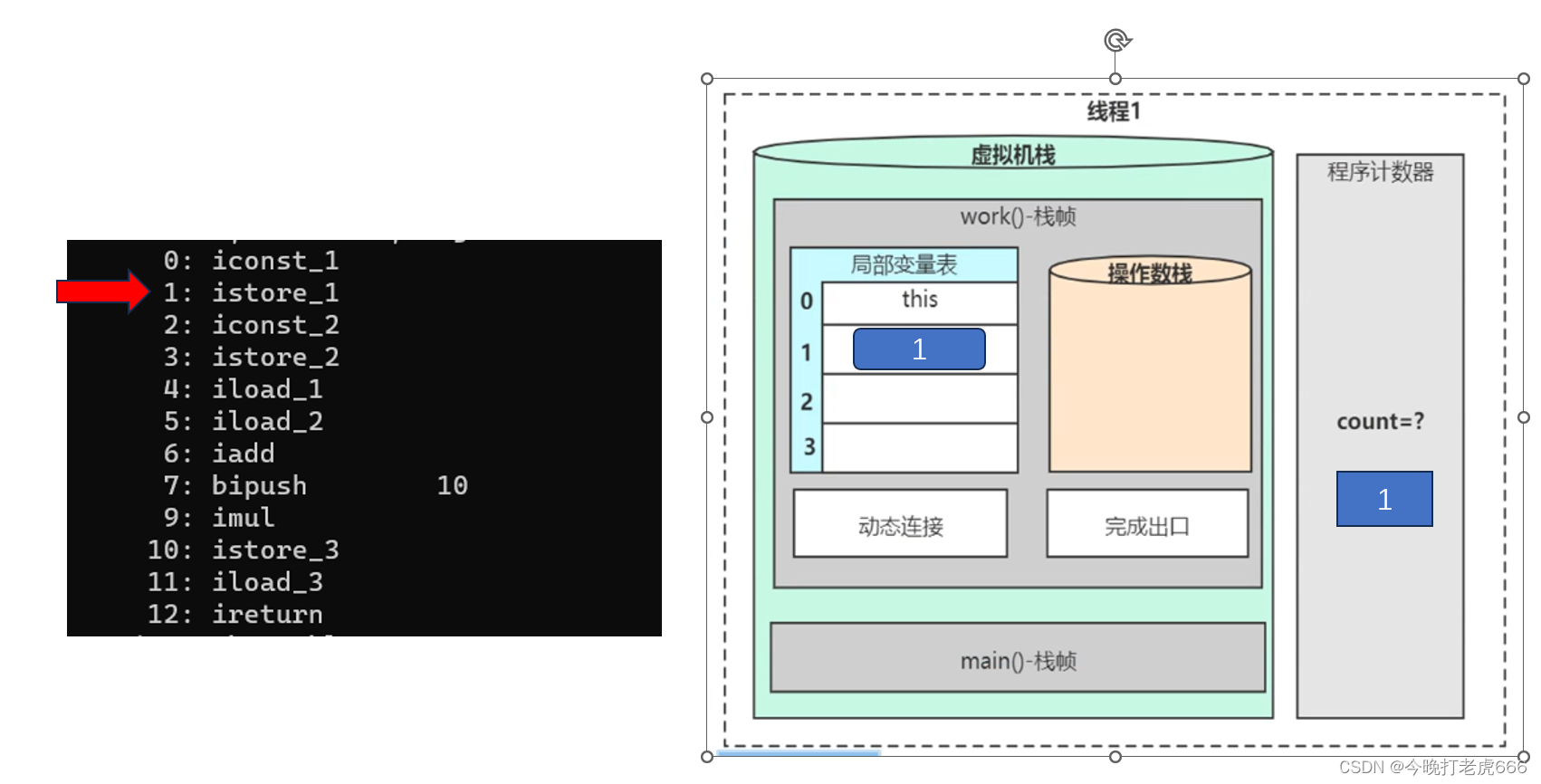
?让我们回到我们的java代码里面,我们int x =1;这一行代码,在字节码里面变成了 :
? ? ? ? ? 0: iconst_1
? ? ? ? ? 1: istore_1
我们的x的值被存到局部变量表中了。
那我们就可以推导得到?
? ? ? ? ? ?2: iconst_2
? ? ? ? ? ?3: istore_2
这两行字节码,首先程序计数器的count变成2,然后在操作数栈里面压入一个2的常量,然后程序计数器的count变成3,最后把操作数栈栈顶的2移出到局部变量表下标为2的位置。

接下来我们java代码执行int z =(x+y)*10,我们的x和y已经定义出来了;查看字节码发现
? ? ? ? 4:iload_1
? ? ? ? 5:iload_2
这两行字节码的意思是把局部变量下标为1,局部变量下标为2的数据压入操作数栈中。

? ? ? ?6:iadd表示从操作数栈里面取两个数,出栈相加,把结果入栈。

7:bipush? ? ? ? ?10? ?这行字节码表示往操作数栈里面推入一个10,因为iconst命令只能压入-1到5的数字,大于5就压不动了,需要使用bipush来推入操作数栈。
接下来执行9:imul,我们可以推理出这个是把操作数栈里面的两个数字先取出来,然后做乘法,最后把得到的值重新压入操作数栈。
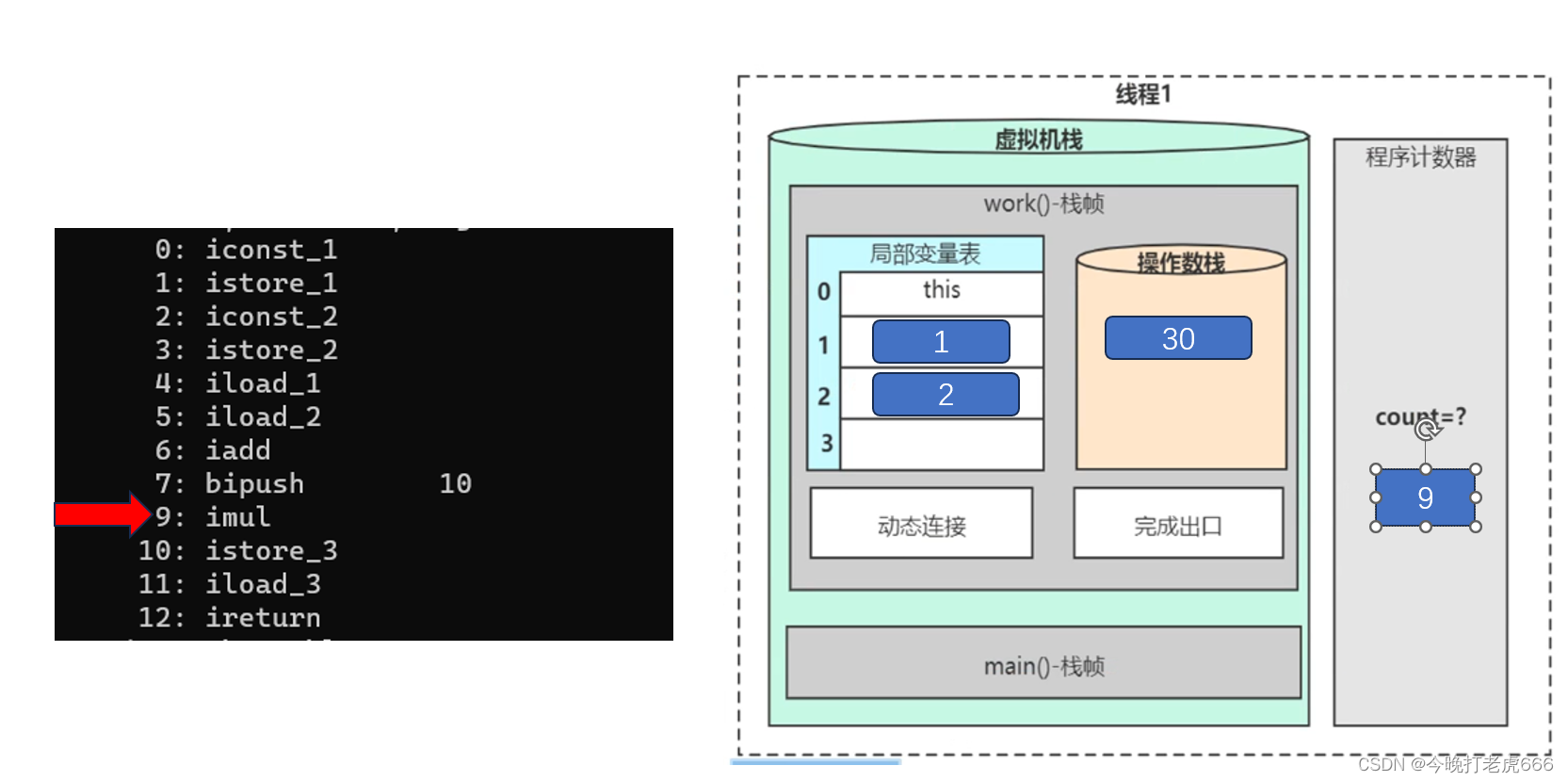
10:istore_3就是把位于操作数栈栈顶的30,移动到局部变量表下标为3的地方。这里也就是给z赋值。
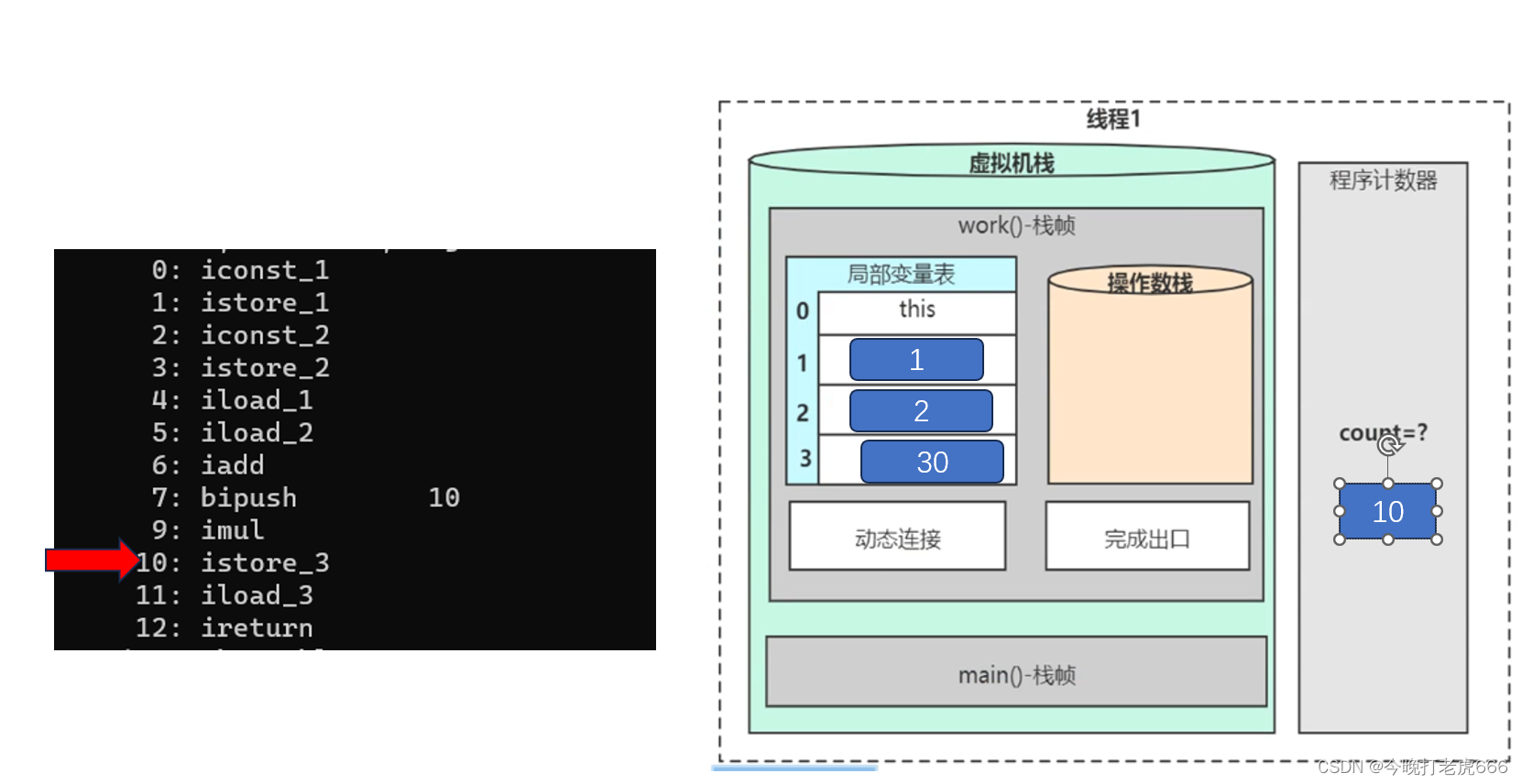
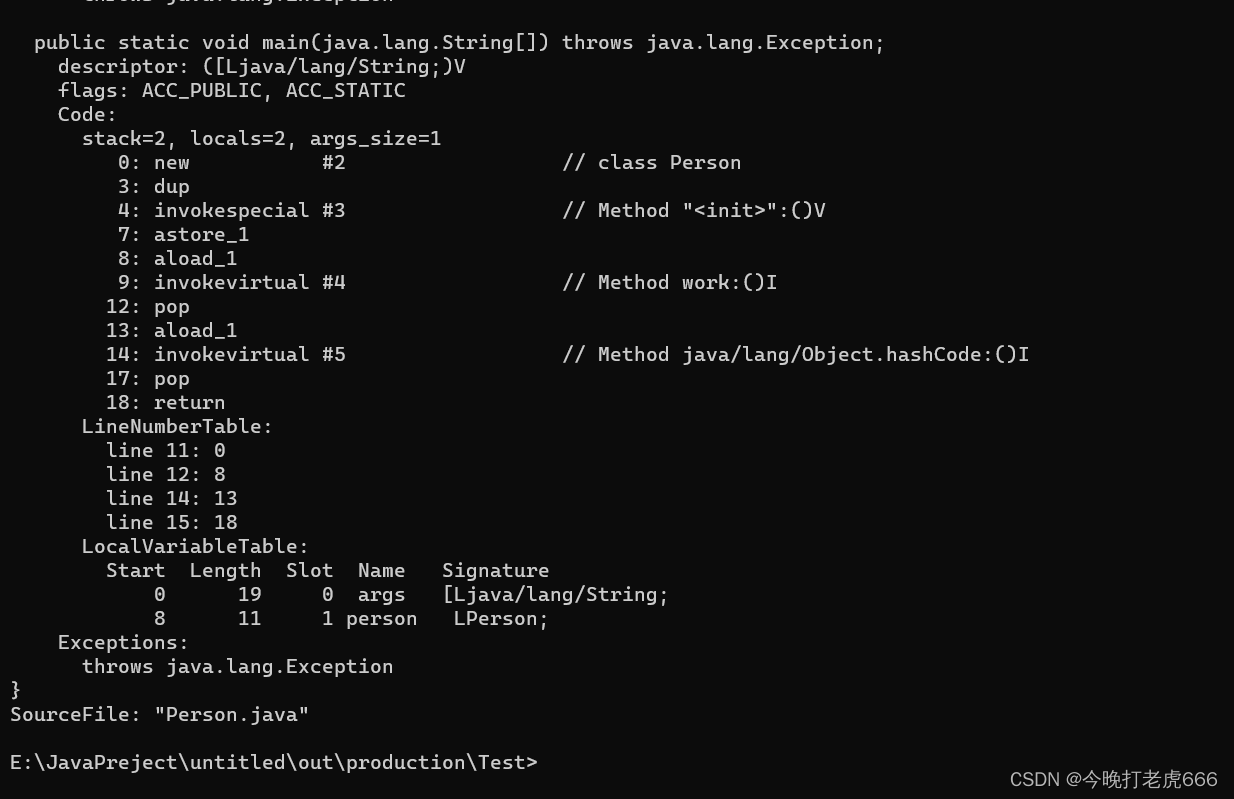
因为我们定义的方法是有返回值的,所以接下来执行11:iload_3把局部变量表下标为3的数字压入操作数栈。

最后执行12:ireturn,带着操作数栈里面的30返回到main方法里面继续执行。
以上就是work方法在执行过程中栈帧的变化,但是为什么0到12中间少了一个8呢?
我们在cmd里面得到的是字节码的指令,0到12是针对work方法字节码的偏移量,有的指令比较大就会大于1行。所以我们程序计数器记录的是当前方法的偏移量。
完成出口:我们执行main方法的时候,拿到字节码也会看到和work方法一样的0...12,这表示的是字节码的行号(针对本方法的偏移量)。我们从main方法执行person.work()跳到work方法,假如person.work()的行号是3,跳转到work方法,work的栈帧的完成出口就是3。当work方法执行完成后,通过完成出口回到main方法相应的行数继续执行。
动态连接:与多态有关。
注意:程序计算器记录的东西可能会重复,因为我在main方法里面会记录0,1,2,3,4。当跳到work方法的时候也会记录0,1,2,3,4。但是没关系,虚拟机栈同时只会执行一个方法,只会执行一个栈帧。
程序计数器的作用:当CPU切到另外一个线程的时候,当前线程暂停执行,当回到当前线程的时候,可以从程序计数器记录的行号继续执行。
问题:匿名内部类使用局部引用为什么要用final?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!