HNU-数据挖掘-实验4-链接预测
数据挖掘课程实验
实验4 链接预测
计科210X 甘晴void 202108010XXX
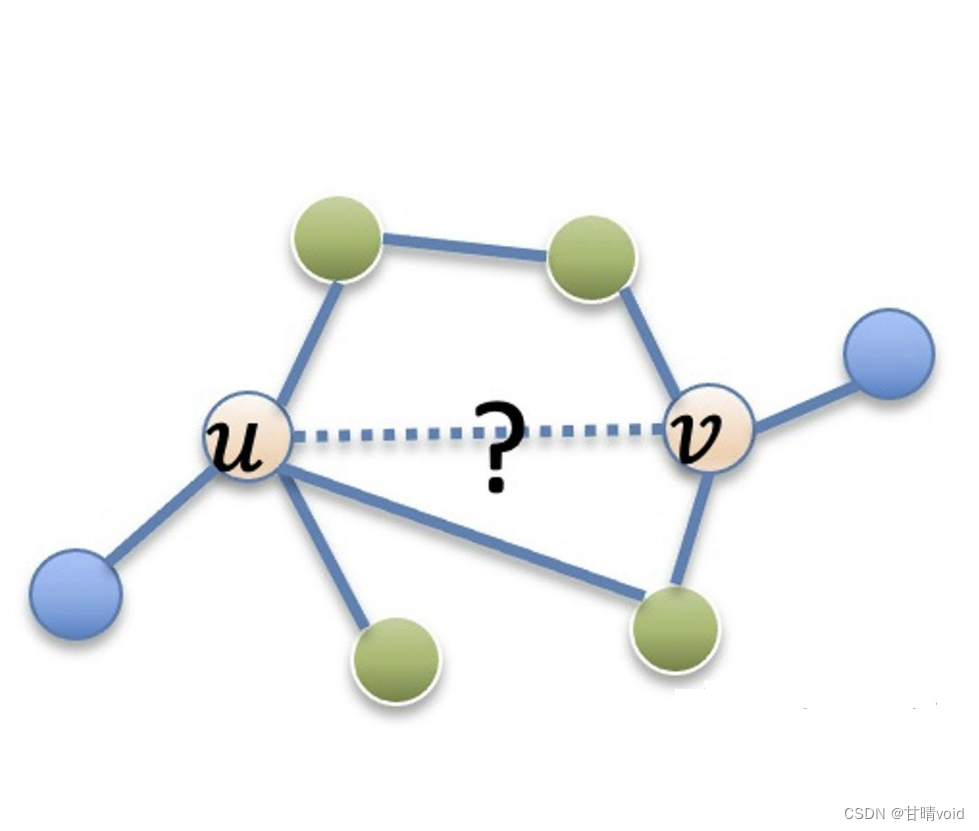
实验背景
节点分类(Node Classification)是图/图谱数据上常被采用的一个学习任务,既是用模型预测图中每个节点的类别。链接预测(Link Prediction)一般指的是,对存在多对象的总体中,每个对象之间的相互作用和相互依赖关系的推断过程。
实验要求
- 利用已经掌握的深度学习方法(比如图卷积网络、图注意力网络、对抗生成网络等),实现相关的半监督分类/预测任务。
- 探索多图联合的深度学习方法(比如多通道卷积网络、多头注意力网络、异构图注意力网络等),实现相关的半监督分类/预测任务。
- 面向上述方法,根据不同的training set和test set的比例,分析算法的性能指标(比如Accuracy、Precision、Recall、F1 Score等)。
- 面向上述方法,根据不同的training set和test set的比例,分析算法性能(比如:ROC、AUC、AUPR等)。
- 面向上述方法,根据不同的正负样本情况(比例),负样本随机选择(正样本除外),分析上述算法性能。
数据集解析
共有7个文件如下
- GeneList为基因列表,
- Positive_LinkSL为基因关系,
- feature1_go和feature2_ppi为两种基因原始特征
- Network1_SL.txt为节点之间的一个已知链接关系(这个与上面的Positive_LinkSL是一样的)
- Network2_CPDB.tsv为另一组节点之间的另一组已知链接关系
- Network3_string.tsv为另一组节点之间的另一组已知链接关系
具体描述如下:
- GeneList.txt:6375个基因,每一行为基因的英文名称。
- Positive_LinkSL.txt:总共有19667对基因关系,可以看作一种基因与基因之间的关联网络。该文件中第一列和第二列分别是基因的英文名称,第三列代表该两个基因的置信分数。(Network2_CPDB.tsv与Network3_string.tsv相仿)
- feature1_go.txt:共有6375行,128列,每一行代表一个基因,每一列代表该基因的一个维度的特征值。
- feature2_ppi.txt:共有6375行,128列,每一行代表一个基因,每一列代表该基因的一个维度的特征值。
可以较为简单地理解如下:
- 对于基因编号i,
GeneList内保存了基因i对应的名称, - 对于基因编号i,j。
Positive_LinkSL内保存了基因i和j的联系,该文件内的每一行都是某两个基因之间的联系以及该联系的置信分数。(Network2_CPDB.tsv与Network3_string.tsv相仿) - 对于基因编号i,剩下两个以“feature”开头的文件的每一行有128列,每一列是刻画该基因的一个维度的特征值。可以理解为对于基因的刻画有两个角度(ppi和go),每个角度有128个维度的特征。这两个文件都各自有6375行,对应6375个基因。
★但是由于Network2_CPDB和Network3_string并没有给出相应的节点特征信息,我认为给出的信息应该是不全的,故没有采用。
实验建模
对于上述信息可以概述如下:
任务1
- GeneList为节点列表,feature1_go和feature2_ppi为节点特征,Positive_LinkSL为边及边权。
- 先构建图,再使用图深度学习方法完成节点表示学习。
- 划分数据集和测试集,进行链接预测。
- 要求给出指标Accuracy、Precision、Recall、F1 Score,ROC、AUC、AUPR。
任务2
- GeneList为节点列表,feature1_go和feature2_ppi为节点特征,Network1_SL为边及边权。
- 先构建图,再使用多图联合的图深度学习方法完成节点表示学习。
- 划分数据集和测试集,进行链接预测。
- 要求给出指标Accuracy、Precision、Recall、F1 Score,ROC、AUC、AUPR。
实验探索过程
失败的探索——DGL库
<0> DGL库简介
DGL(Deep Graph Library)是一个用于图神经网络(GNN)的开源深度学习库。它为研究人员和开发者提供了在图结构数据上进行深度学习的工具和接口。DGL支持多种图神经网络模型,包括GCN(Graph Convolutional Network)、GraphSAGE(Graph Sample and Aggregation)、GAT(Graph Attention Network)等。
DGL的主要特点包括:
- 图抽象: DGL将图抽象为节点和边的集合,允许用户以一种直观的方式操作和处理图数据。
- 多后端支持: DGL支持多个深度学习框架,如PyTorch、TensorFlow和MXNet,使用户能够选择他们喜欢的框架进行图神经网络的开发。
- 灵活性: DGL提供了一系列用于创建、操作和分析图的API,使用户能够自定义模型和操作以满足不同的需求。
- 性能优化: DGL致力于提供高性能的图神经网络计算,通过优化底层实现,使得处理大规模图数据成为可能。
<1> 读取基因并构建图
读取基因数据和构建图:
- 通过
open函数读取基因列表文件(‘GeneList.txt’),将每行的基因名存储在gene_list列表中。 - 创建基因到索引的映射
gene_dict,将基因名映射为索引。 - 读取基因关系和置信分数文件(‘Positive_LinkSL.txt’),提取源节点、目标节点和置信分数。
- 通过
torch.tensor创建包含边索引和置信分数的图数据结构graph。 - 从文件中读取两个特征矩阵(‘feature1_go.txt’和’feature2_ppi.txt’)并用
torch.tensor转换为PyTorch张量。 - 将特征数据添加到图的节点和边数据中。
该部分的代码如下
# 读取基因列表
with open('GeneList.txt', 'r') as f:
gene_list = [line.strip() for line in f]
# 构建基因到索引的映射
gene_dict = {gene: idx for idx, gene in enumerate(gene_list)}
# 读取基因关系和置信分数
with open('Positive_LinkSL.txt', 'r') as f:
edges = [line.strip().split() for line in f]
# 提取基因关系的源节点、目标节点和置信分数
src_nodes = [gene_dict[edge[0]] for edge in edges] + [gene_dict[edge[1]] for edge in edges]
dst_nodes = [gene_dict[edge[1]] for edge in edges] + [gene_dict[edge[0]] for edge in edges]
confidence_scores = [float(edge[2]) for edge in edges] + [float(edge[2]) for edge in edges]
# 读取特征
with open('feature1_go.txt', 'r') as file:
feature1_go = np.array([list(map(float, line.split())) for line in file])
with open('feature2_ppi.txt', 'r') as file:
feature2_ppi = np.array([list(map(float, line.split())) for line in file])
# 构建图
edges = torch.tensor(src_nodes),torch.tensor(dst_nodes)
graph = dgl.graph(edges)
graph.edata['confidence'] = torch.tensor(confidence_scores,dtype=torch.float32)
graph.ndata['feature1_go'] = torch.tensor(feature1_go,dtype=torch.float32)
graph.ndata['feature2_ppi'] = torch.tensor(feature2_ppi,dtype=torch.float32)
"""print(graph)
# 输出边的权值值
edge_weights = graph.edata['confidence'].squeeze().numpy()
print("Edge Weights:")
print(edge_weights)
# 输出节点特征 'feature1_go'
feature1_go_values = graph.ndata['feature1_go'].squeeze().numpy()
print("Node Feature 'feature1_go':")
print(feature1_go_values)
# 输出节点特征 'feature2_ppi'
feature2_ppi_values = graph.ndata['feature2_ppi'].squeeze().numpy()
print("Node Feature 'feature2_ppi':")
print(feature2_ppi_values)"""
print(graph)
运行结果如下:
E:\anaconda\envs\python3-11\python.exe E:\python_files\数据挖掘\exp4\my.py
Graph(num_nodes=6375, num_edges=39334,
ndata_schemes={'feature1_go': Scheme(shape=(128,), dtype=torch.float32), 'feature2_ppi': Scheme(shape=(128,), dtype=torch.float32)}
edata_schemes={'confidence': Scheme(shape=(), dtype=torch.float32)})
该部分是成功的,成功地将我们需要的所有信息加入到图中了。
<2> 构建GNN模型
预处理结束之后,需要构建图神经网络模型
- 导入DGL库和PyTorch库。
- 定义一个包含两层SAGE卷积的GNN模型
SAGE。 - 使用
construct_negative_graph函数构建负样本图。 - 定义一个用于计算两节点之间得分的
DotProductPredictor模型。 - 定义整体的模型
Model,包括SAGE卷积和得分计算模块。 - 初始化模型和Adam优化器。
代码如下:
# 构建一个2层的GNN模型
import dgl.nn as dglnn
import torch.nn as nn
import torch.nn.functional as F
class SAGE(nn.Module):
def __init__(self, in_feats, hid_feats, out_feats):
super().__init__()
# 实例化SAGEConve,in_feats是输入特征的维度,out_feats是输出特征的维度,aggregator_type是聚合函数的类型
self.conv1 = dglnn.SAGEConv(
in_feats=in_feats, out_feats=hid_feats, aggregator_type='mean')
self.conv2 = dglnn.SAGEConv(
in_feats=hid_feats, out_feats=out_feats, aggregator_type='mean')
def forward(self, graph, inputs):
# 输入是节点的特征
h = self.conv1(graph, inputs)
h = F.relu(h)
h = self.conv2(graph, h)
return h
def construct_negative_graph(graph, k):
src, dst = graph.edges()
neg_src = src.repeat_interleave(k)
neg_dst = torch.randint(0, graph.num_nodes(), (len(src) * k,))
return dgl.graph((neg_src, neg_dst), num_nodes=graph.num_nodes())
import dgl.function as fn
class DotProductPredictor(nn.Module):
def forward(self, graph, h):
# h是从5.1节的GNN模型中计算出的节点表示
with graph.local_scope():
graph.ndata['h'] = h
graph.apply_edges(fn.u_dot_v('h', 'h', 'score'))
return graph.edata['score']
def compute_loss(pos_score, neg_score):
# 间隔损失
n_edges = pos_score.shape[0]
return (1 - pos_score.unsqueeze(1) + neg_score.view(n_edges, -1)).clamp(min=0).mean()
class Model(nn.Module):
def __init__(self, in_features, hidden_features, out_features):
super().__init__()
self.sage = SAGE(in_features, hidden_features, out_features)
self.pred = DotProductPredictor()
def forward(self, g, neg_g, x):
h = self.sage(g, x)
#return self.pred(g, h), self.pred(neg_g, h)
pos_score = self.pred(g, h)
neg_score = self.pred(neg_g, h)
return pos_score, neg_score
该步的图结构模型应该是没有问题的。
<3> 训练模型
完成模型定义之后,可以开始训练模型:
- 在每个训练周期中,使用
construct_negative_graph生成负样本图。 - 通过前向传播计算正样本和负样本的得分,并计算间隔损失。
- 使用Adam优化器进行反向传播和参数更新。
代码如下:
node_features = graph.ndata['feature1_go']
n_features = node_features.shape[1]
k = 5
model = Model(n_features, 10, 5)
opt = torch.optim.Adam(model.parameters())
for epoch in range(1):
negative_graph = construct_negative_graph(graph, k)
pos_score, neg_score = model(graph, negative_graph, node_features)
loss = compute_loss(pos_score, neg_score)
opt.zero_grad()
loss.backward()
opt.step()
print(f'Epoch {epoch + 1}, Loss: {loss.item()}')
其中,k 是用于构建负样本图的参数。具体来说,对于每一对正样本边,会通过construct_negative_graph函数生成 k 个负样本边。构建负样本是为了训练图神经网络(GNN)模型,其中负样本边的目的是提供模型更多的信息,使其能够更好地区分正样本和负样本,从而提高模型的性能。
一般来说,k取值不宜过低,但是,k取值增大会带来计算代价的增加和内存占用的增加。
仅仅对于k=5,我的本地计算机就出现了较大的问题。
首先是内存代价的不可接受,这需要30943271120bytes内存空间,换算过后是大约28.81GB,对于本地计算机的16GB运行内存来说,这已经超出太多了。
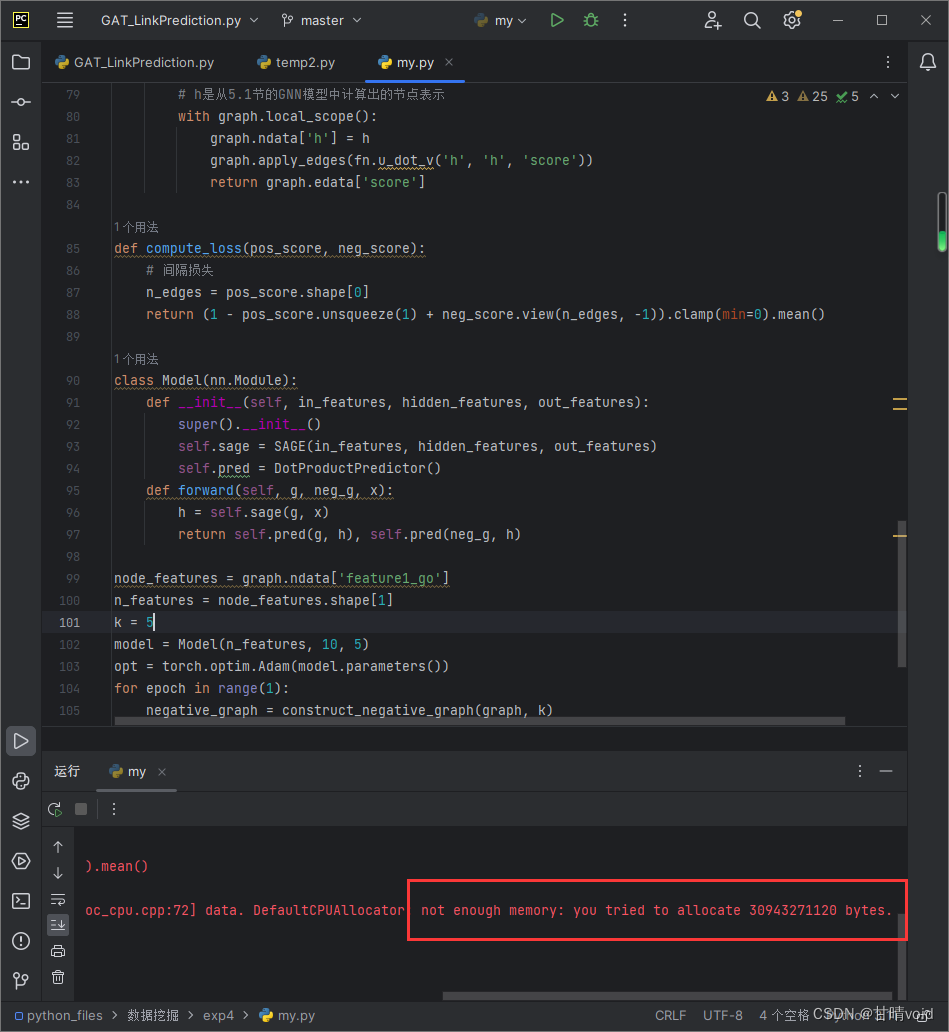
我将k值调整为1,即使仅仅是这样,虽然可以运行,但是资源基本上已经被全部占用了。
此外,我还将深度学习的层数调整为了1,但
<4> 输出结果与可视化
假设上面的步骤都全部正确,接下来进行的是可视化输出。
- 打印每个训练周期的损失。
- 输出正样本的置信度分布。
- 生成随机标签
true_labels。 - 使用模型获取节点表示,并通过t-SNE降维到2D空间。
- 使用NetworkX库构建图结构,节点包括基因名和对应标签,边包括基因关系和得分。
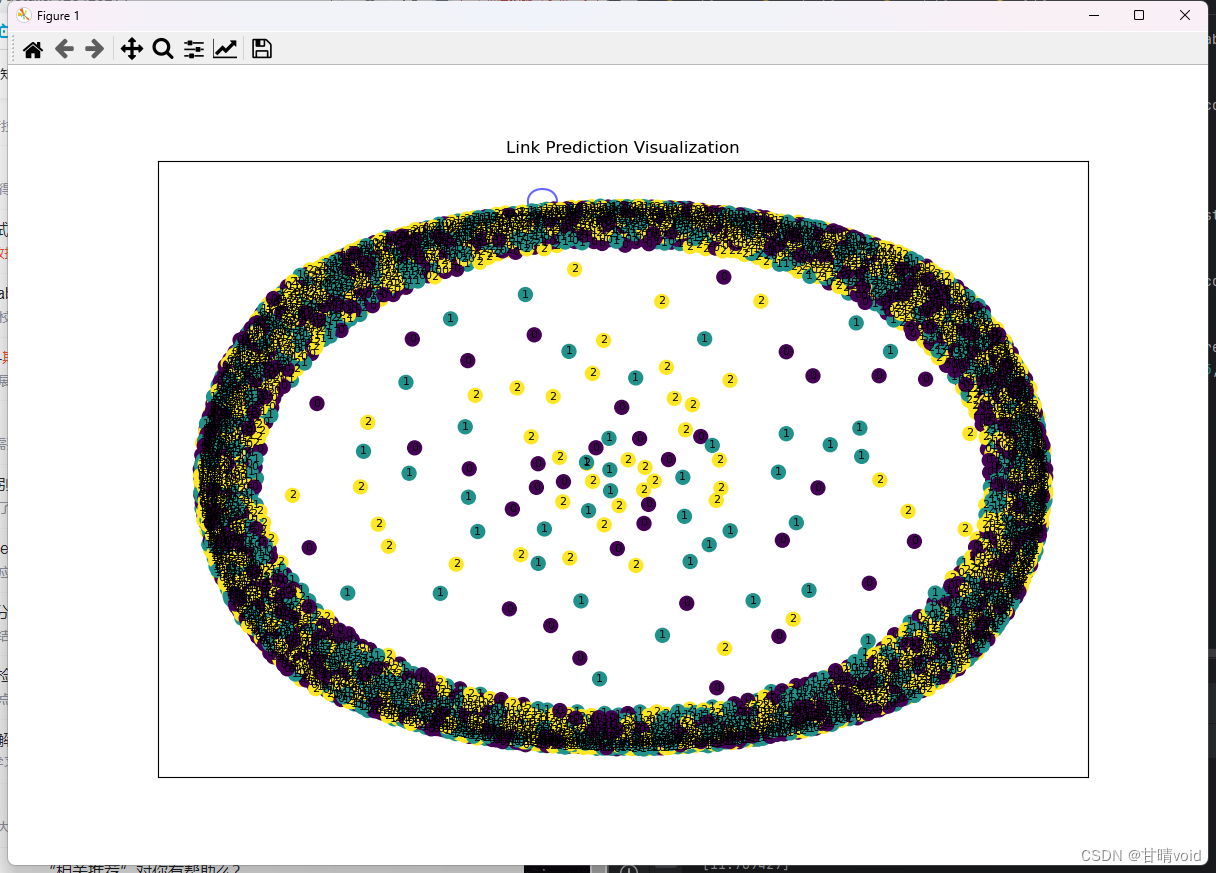
- 绘制图的节点、边和标签,展示链接预测的可视化结果。
# 输出边的置信度分布
print("Edge Confidence Distribution:")
print(pos_score.detach().numpy())
import networkx as nx
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
true_labels = torch.randint(0, 3, (len(gene_list),)) # 0, 1, 2 之间的随机标签
# 获取节点表示
with torch.no_grad():
node_embeddings = model.sage(graph, node_features).numpy()
# 将节点表示降维到二维空间进行可视化
tsne = TSNE(n_components=2, random_state=42)
node_embeddings_2d = tsne.fit_transform(node_embeddings)
# 构建 NetworkX 图
G = nx.Graph()
for i, gene in enumerate(gene_list):
G.add_node(gene, label=true_labels[i].item(), color=true_labels[i].item())
for edge, score in zip(edges, pos_score.detach().numpy()):
G.add_edge(gene_list[edge[0]], gene_list[edge[1]], score=score)
# 绘制图
plt.figure(figsize=(12, 8))
pos = nx.spring_layout(G, seed=42)
node_color = [true_labels[i].item() for i in range(len(gene_list))]
# 绘制节点
nx.draw_networkx_nodes(G, pos, node_size=100, node_color=node_color, cmap='viridis')
# 绘制链接预测的边
edge_color = ['b' if score > 0.5 else 'r' for score in nx.get_edge_attributes(G, 'score').values()]
nx.draw_networkx_edges(G, pos, edge_color=edge_color, width=1.5, alpha=0.6)
# 绘制节点标签
labels = nx.get_node_attributes(G, 'label')
nx.draw_networkx_labels(G, pos, labels=labels, font_size=8)
plt.title('Link Prediction Visualization')
plt.show()
这里为了让节点彼此区分开来,给不同的节点随机分配了颜色。
<5> 模型评估
若之前步骤正确,在这一步可以对于之前的模型进行评估。
对于Accuracy、Precision、Recall、F1 Score
# 模型评估
model.eval() # 切换模型为评估模式,这会影响某些层(如Dropout)
with torch.no_grad():
# 这里的 node_features 为测试集的特征
test_pos_score, test_neg_score = model(graph, negative_graph, node_features)
test_predicted_labels = torch.where(test_pos_score > 0.5, 1, 0).numpy()
# 计算评估指标
test_true_labels = torch.randint(0, 3, (graph.num_nodes(),)) # 替换为实际的测试集标签
accuracy = accuracy_score(test_true_labels.numpy(), test_predicted_labels)
precision = precision_score(test_true_labels.numpy(), test_predicted_labels)
recall = recall_score(test_true_labels.numpy(), test_predicted_labels)
f1 = f1_score(test_true_labels.numpy(), test_predicted_labels)
print(f"Test Accuracy: {accuracy:.4f}")
print(f"Test Precision: {precision:.4f}")
print(f"Test Recall: {recall:.4f}")
print(f"Test F1 Score: {f1:.4f}")
对于ROC、AUC、AUPR
# 计算 ROC 和 AUC
fpr, tpr, _ = roc_curve(true_labels.numpy(), pos_score.detach().numpy())
roc_auc = roc_auc_score(true_labels.numpy(), pos_score.detach().numpy())
# 绘制 ROC 曲线
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'ROC curve (AUC = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.legend(loc="lower right")
plt.show()
# 计算 AUPR
precision, recall, _ = precision_recall_curve(true_labels.numpy(), pos_score.detach().numpy())
aupr = average_precision_score(true_labels.numpy(), pos_score.detach().numpy())
# 绘制 Precision-Recall 曲线
plt.figure(figsize=(8, 6))
plt.step(recall, precision, color='b', alpha=0.2, where='post')
plt.fill_between(recall, precision, step='post', alpha=0.2, color='b')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.title('Precision-Recall Curve (AUPR = {0:.2f})'.format(aupr))
plt.show()
★<6> 失败总结
由于DGL对于资源的需求实在太大了,本地计算机的内存和算力都不能满足要求,故本实验使用该种方法似乎并不能得到满意的结果。
DGL是一个很好用的工具,但是确实不太适合本地计算机来运行。
以上的代码与推演,照理应该是正确的,在算力和内存等资源充足的地方应该能发挥效果。
任务1
<1> 数据读取与构建图数据
read_data(file_path): 读取文件中的数据,并返回每一行的列表。build_graph_data(gene_list, link_list, feature1, feature2): 构建图数据,包括节点特征 (feature1和feature2),边的索引 (edge_index) 和边的属性 (edge_attr)。同时,构建了一个基因字典gene_dict用于将基因名称映射到索引。
定义读取文件的函数如下
def read_data(file_path):
with open(file_path, 'r') as f:
data = f.read().splitlines()
return data
其中,对于图数据的构建如下:
# 构建图数据
def build_graph_data(gene_list, link_list, feature1, feature2):
edge_index = []
edge_attr = []
x1 = []
x2 = []
gene_dict = {gene: idx for idx, gene in enumerate(gene_list)}
for link in link_list:
gene1, gene2, confidence = link.split('\t')
if gene1 in gene_dict and gene2 in gene_dict:
edge_index.append([gene_dict[gene1], gene_dict[gene2]])
edge_attr.append(float(confidence))
edge_index = torch.tensor(edge_index, dtype=torch.long).t().contiguous()
edge_attr = torch.tensor(edge_attr, dtype=torch.float).view(-1, 1)
for gene in gene_list:
if gene in gene_dict:
x1.append(feature1[gene_dict[gene]])
x2.append(feature2[gene_dict[gene]])
x1 = torch.tensor(x1, dtype=torch.float)
x2 = torch.tensor(x2, dtype=torch.float)
data = Data(x1=x1, x2=x2, edge_index=edge_index, edge_attr=edge_attr)
return data
读取基因列表 (GeneList.txt)、链接列表 (Positive_LinkSL.txt) 以及两个特征文件 (feature1_go.txt 和 feature2_ppi.txt)。然后划分数据集为训练集和测试集,并构建相应的图数据。在主函数中调用的读取代码如下:
# 读取数据
gene_list = read_data('GeneList.txt')
link_list = read_data('Positive_LinkSL.txt')
feature1 = np.loadtxt('feature1_go.txt')
feature2 = np.loadtxt('feature2_ppi.txt')
# 划分数据集和测试集
train_gene_list, test_gene_list = train_test_split(gene_list, test_size=0.2, random_state=42)
# 构建训练集和测试集的图数据
train_data = build_graph_data(train_gene_list, link_list, feature1, feature2)
test_data = build_graph_data(test_gene_list, link_list, feature1, feature2)
<2> GAT 模型定义
GATModel(nn.Module): 定义了一个简单的 GAT 模型,使用了GATConv层。
# GAT 模型定义
class GATModel(nn.Module):
def __init__(self, in_channels, out_channels, heads):
super(GATModel, self).__init__()
self.conv1 = GATConv(in_channels, out_channels, heads=heads)
def forward(self, x, edge_index, edge_attr):
x = self.conv1(x, edge_index, edge_attr)
return x
<3> 训练模型
train(model, data, optimizer, criterion, epochs): 训练 GAT 模型。在每个 epoch 中,计算模型的损失值,并将其记录在losses列表中。训练完成后,通过 Matplotlib 绘制损失曲线图。
# 训练模型
def train(model, data, optimizer, criterion, epochs):
model.train()
losses = [] # 用于记录每个 epoch 的损失值
for epoch in range(epochs):
optimizer.zero_grad()
out = model(data.x1, data.edge_index, data.edge_attr)
loss = criterion(out, data.x2)
loss.backward()
optimizer.step()
losses.append(loss.item()) # 记录当前 epoch 的损失值
print(f'Epoch {epoch + 1}/{epochs}, Loss: {loss.item()}')
# 绘制损失曲线图
plt.plot(losses)
plt.title('Training Loss Over Epochs')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.show()
<4> 评估链接预测结果
evaluate(y_true, y_pred): 使用 sklearn 库中的指标评估链接预测结果,包括准确率、精确度、召回率、F1 分数、ROC AUC 和平均精度 (AUPR)。
def evaluate(y_true, y_pred):
y_true = (y_true > 0.3).int().cpu().numpy()
y_pred = (y_pred > 0.3).int().cpu().numpy()
accuracy = accuracy_score(y_true, y_pred)
precision = precision_score(y_true, y_pred, average='micro')
recall = recall_score(y_true, y_pred, average='micro')
f1 = f1_score(y_true, y_pred, average='micro')
roc_auc = roc_auc_score(y_true, y_pred)
aupr = average_precision_score(y_true, y_pred)
return accuracy, precision, recall, f1, roc_auc, aupr
<5> 创建并训练 GAT模型
- 创建 GAT 模型,定义优化器和损失函数,然后调用
train函数进行模型训练。
# 创建并训练 GAT 模型
model = GATModel(in_channels=128, out_channels=128, heads=1)
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.MSELoss()
train(model, train_data, optimizer, criterion, epochs=200)
指定训练次数为100次,学习率调为0.001。
<6> 链接预测和结果评估
- 使用训练好的模型对测试集进行链接预测,然后调用
evaluate函数评估预测结果。
# 进行链接预测
pred_scores = model(test_data.x1, test_data.edge_index, test_data.edge_attr)
# 评估链接预测结果
accuracy, precision, recall, f1, roc_auc, aupr = evaluate(test_data.x2, pred_scores)
print(f'Accuracy: {accuracy} \nPrecision: {precision} \nRecall: {recall} \nF1 Score: {f1}')
print(f'ROC AUC: {roc_auc} \nAUPR: {aupr}')
<7> 图数据可视化部分
- 将 PyTorch Geometric 图数据转换为 NetworkX 图,使用 NetworkX 绘制图的布局,并通过 Matplotlib 进行绘制。
import networkx as nx
import torch
from torch_geometric.data import Data
# 将 PyTorch Geometric 图数据转换为 NetworkX 图
G = nx.Graph()
G.add_nodes_from(range(test_data.num_nodes))
G.add_edges_from(test_data.edge_index.t().tolist())
# 使用 NetworkX 绘制图
pos = nx.spring_layout(G)
nx.draw(G, pos, with_labels=True, font_weight='bold', node_color='lightblue', node_size=1000, font_size=8, edge_color='gray')
plt.show()
★<8> 结果展示
使用上述模型进行运行,损失曲线如下。
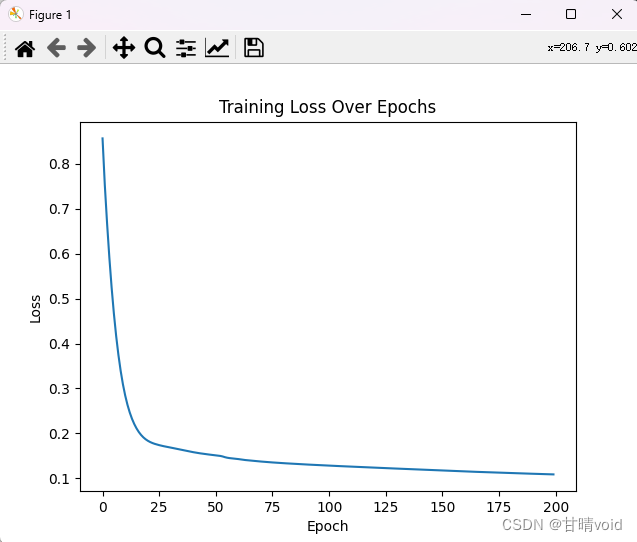
部分损失值如下:
Epoch 1/200, Loss: 0.8566558361053467
Epoch 2/200, Loss: 0.7528260350227356
Epoch 3/200, Loss: 0.6675369143486023
Epoch 4/200, Loss: 0.5916386842727661
Epoch 5/200, Loss: 0.5249260067939758
Epoch 6/200, Loss: 0.46694767475128174
Epoch 7/200, Loss: 0.41712379455566406
Epoch 8/200, Loss: 0.37475287914276123
Epoch 9/200, Loss: 0.3390277028083801
Epoch 10/200, Loss: 0.309112012386322
Epoch 11/200, Loss: 0.284216046333313
Epoch 12/200, Loss: 0.2636083960533142
Epoch 13/200, Loss: 0.2465600073337555
Epoch 14/200, Loss: 0.23244094848632812
……
Epoch 195/200, Loss: 0.10945269465446472
Epoch 196/200, Loss: 0.10929632186889648
Epoch 197/200, Loss: 0.10914068669080734
Epoch 198/200, Loss: 0.1089857891201973
Epoch 199/200, Loss: 0.10883160680532455
Epoch 200/200, Loss: 0.10867814719676971
进行200次之后,大概在0.1左右。
模型评估结果如下
Accuracy: 0.4549019607843137
Precision: 0.8565955895528382
Recall: 0.9963490534849291
F1 Score: 0.9212020532584679
ROC AUC: 0.5012495279165683
AUPR: 0.8531546660454162
解释如下:
- 准确率 (Accuracy): 0.45,表示正确预测的链接占总链接的比例。
- 精确度 (Precision): 0.86,表示在所有模型预测为正的链接中,有 86% 是正确的。
- 召回率 (Recall): 0.996,表示在所有实际为正的链接中,模型成功预测了 99.6%。
- F1 分数 (F1 Score): 0.92,是精确度和召回率的调和平均值,提供了模型在正类别上的综合性能指标。
- ROC AUC: 0.50,表示模型在正例和负例之间的区分能力,ROC AUC 约接近 0.5,说明模型的性能接近随机猜测。
- AUPR (平均精度): 0.85,表示模型在正例上的精度,AUPR 越接近 1 表示性能越好。
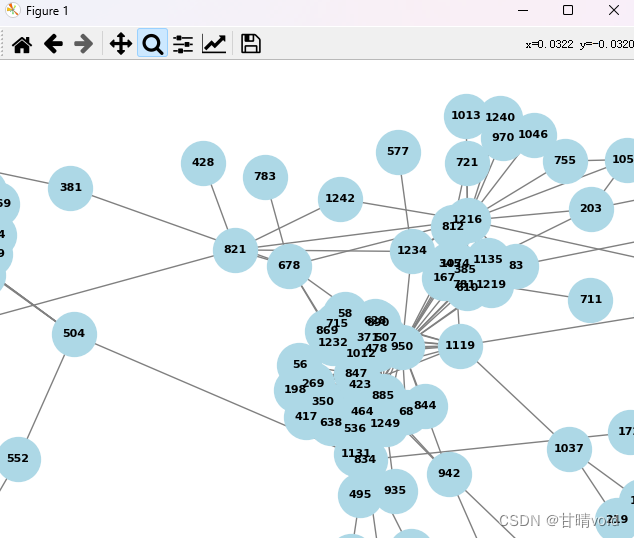
构建基因链接预测图如下
(选取预测分数大于指定阈值的链接作为预测有关的链接)
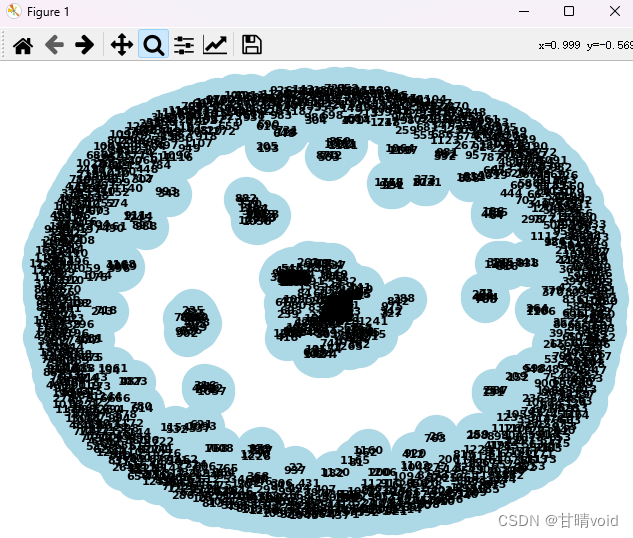
这是整体的趋势图,对于其中的局部放大可以看到目标基因之间的联系。
对于中间部分,与周围联系较多的节点,可以通过节点编号查到基因名

1027 CLDN23
116 ADRB1
740 CBR3
617 C1QBP
下面是一些其它的局部结构

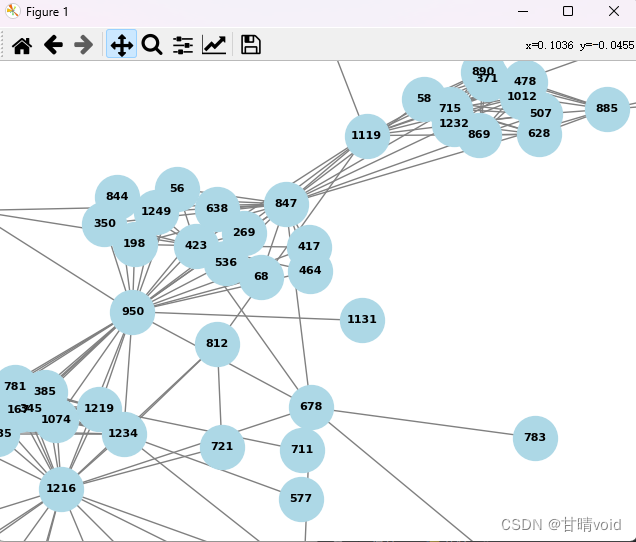
任务2
使用多通道在刚刚的基础上对模型和训练做修改
<1> 修改模型
这里我们使用的多通道卷积网络。所以对于模型的定义需要修改,把原本的单通道扩展成多个,并在适当的地方进行合并。
# Multi-Channel Graph Convolutional Network 模型定义
class MultiChannelGCN(nn.Module):
def __init__(self, in_channels, out_channels):
super(MultiChannelGCN, self).__init__()
self.conv1 = GCNConv(in_channels, out_channels)
self.conv2 = GCNConv(in_channels, out_channels)
def forward(self, x1, x2, edge_index, edge_attr):
x1 = self.conv1(x1, edge_index, edge_attr)
x2 = self.conv2(x2, edge_index, edge_attr)
return x1, x2
除了要在模型定义的地方进行修改,在训练函数以及调用函数也要进行修改。
修改训练函数:
# 训练模型
def train(model, data, optimizer, criterion, epochs):
model.train()
losses = [] # 用于记录每个 epoch 的损失值
for epoch in range(epochs):
optimizer.zero_grad()
out1, out2 = model(data.x1, data.x2, data.edge_index, data.edge_attr)
loss1 = criterion(out1, data.x1)
loss2 = criterion(out2, data.x2)
loss = loss1 + loss2
loss.backward()
optimizer.step()
losses.append(loss.item()) # 记录当前 epoch 的损失值
print(f'Epoch {epoch + 1}/{epochs}, Loss: {loss.item()}')
# 绘制损失曲线图
plt.plot(losses)
plt.title('Training Loss Over Epochs')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.show()
修改调用部分:
# 进行链接预测
pred_scores1, pred_scores2 = model(test_data.x1, test_data.x2, test_data.edge_index, test_data.edge_attr)
pred_scores = (pred_scores1 + pred_scores2) / 2 # 取两个通道的平均值
这样就将其转化为了一个使用双通道的图卷积网络模型。
★<2> 结果展示
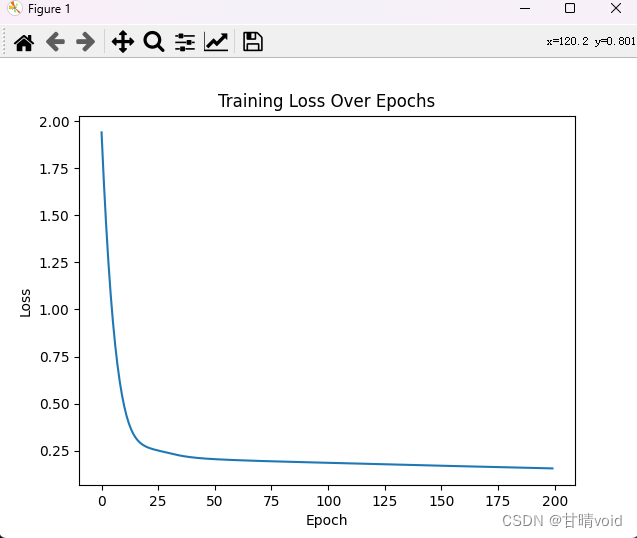
损失率如下:
Epoch 1/200, Loss: 1.9401469230651855
Epoch 2/200, Loss: 1.682145357131958
Epoch 3/200, Loss: 1.4546871185302734
Epoch 4/200, Loss: 1.2563203573226929
Epoch 5/200, Loss: 1.084963083267212
Epoch 6/200, Loss: 0.9381833076477051
Epoch 7/200, Loss: 0.8134356737136841
Epoch 8/200, Loss: 0.708167552947998
Epoch 9/200, Loss: 0.6199674606323242
Epoch 10/200, Loss: 0.5466182827949524
Epoch 11/200, Loss: 0.48613178730010986
Epoch 12/200, Loss: 0.4367343485355377
Epoch 13/200, Loss: 0.39682072401046753
Epoch 14/200, Loss: 0.36491310596466064
……
Epoch 195/200, Loss: 0.15746958553791046
Epoch 196/200, Loss: 0.1571885496377945
Epoch 197/200, Loss: 0.15690799057483673
Epoch 198/200, Loss: 0.15662789344787598
Epoch 199/200, Loss: 0.15634828805923462
Epoch 200/200, Loss: 0.15606917440891266
指标评估如下:
Accuracy: 0.5427450980392157
Precision: 0.8652827615217433
Recall: 0.9757082692501186
F1 Score: 0.9171837684645032
ROC AUC: 0.5324953459502417
AUPR: 0.8606581811658711
整体展示如下:
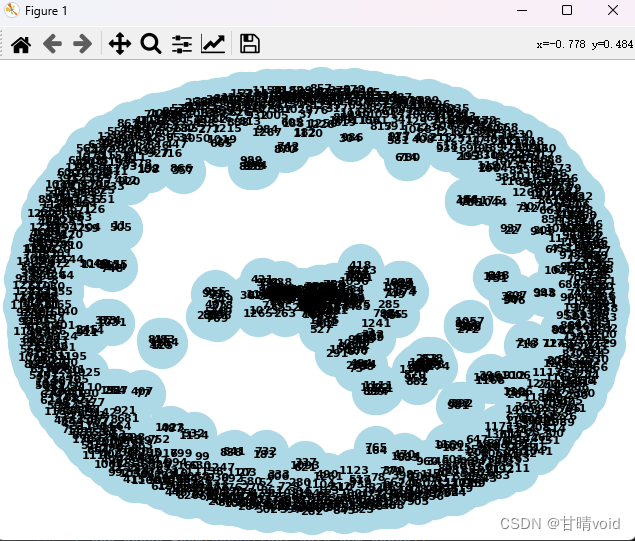
部分局部展示如下:
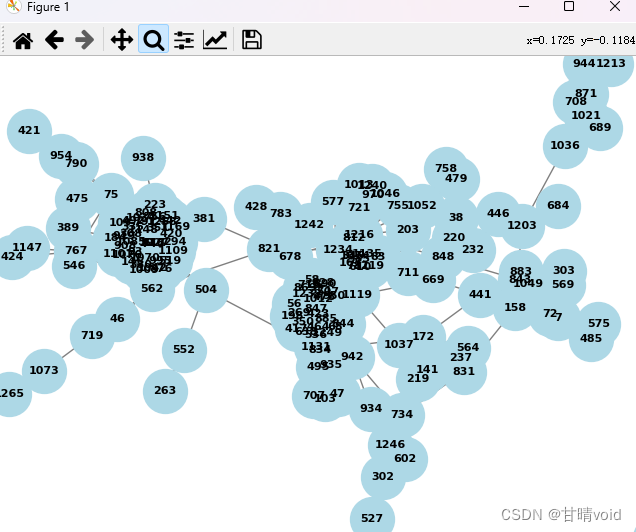
<3> 总结
使用双通道后,由于对于原来的特征彼此之间区分信息的保留变多了,所以链接的预测正确率有明显的上升。所以双通道以及多通道的图神经网络还是有好处的。
<4> 进一步探索,n通道
继续修改刚刚的代码,使用数组替换模型中的x1和x2,达到n通道的效果,如下:
# Multi-Channel Graph Convolutional Network 模型定义
class MultiChannelGCN(nn.Module):
def __init__(self, in_channels, out_channels, num_channels):
super(MultiChannelGCN, self).__init__()
self.channels = nn.ModuleList([GCNConv(in_channels, out_channels) for _ in range(num_channels)])
def forward(self, *inputs):
output_channels = [channel(x, inputs[-2], inputs[-1]) for channel, x in zip(self.channels, inputs[:-2])]
return output_channels
详细代码附在后面,修改代码中的num_channels = ,调整为想要的通道数即可。
发现将通道从1上调至2后,正确率上升效果明显,继续上调后,正确率上升效果不明显。
这是通道数目为10时的结果:
Accuracy: 0.5435294117647059
Precision: 0.8650597497897928
Recall: 0.976010119158845
F1 Score: 0.9171917738830919
ROC AUC: 0.5317604380292384
AUPR: 0.8605590887908858
上升不显著,基本还是在0.54,其余指标基本都略微有变化,但变化不是很多。故认为2通道基本已经能满足要求。
实验感悟
由于老师将收作业的时间延后了,我确实有更多的时间来进行探究,感觉对于图神经网络有了一个更为直观的感悟。但是我还是没有从一个更底层的角度去深究其原理,仅仅停留在代码层面,还是不够的,还有很多需要学习的地方。
本学期在数据挖掘上确实学习到了很多。
附录
使用DGL库进行探索 dgl.py
import dgl
import torch
import numpy as np
# 读取基因列表
with open('GeneList.txt', 'r') as f:
gene_list = [line.strip() for line in f]
# 构建基因到索引的映射
gene_dict = {gene: idx for idx, gene in enumerate(gene_list)}
# 读取基因关系和置信分数
with open('Positive_LinkSL.txt', 'r') as f:
edges = [line.strip().split() for line in f]
# 提取基因关系的源节点、目标节点和置信分数
src_nodes = [gene_dict[edge[0]] for edge in edges] + [gene_dict[edge[1]] for edge in edges]
dst_nodes = [gene_dict[edge[1]] for edge in edges] + [gene_dict[edge[0]] for edge in edges]
confidence_scores = [float(edge[2]) for edge in edges] + [float(edge[2]) for edge in edges]
# 读取特征
with open('feature1_go.txt', 'r') as file:
feature1_go = np.array([list(map(float, line.split())) for line in file])
with open('feature2_ppi.txt', 'r') as file:
feature2_ppi = np.array([list(map(float, line.split())) for line in file])
# 构建图
edges = torch.tensor(src_nodes),torch.tensor(dst_nodes)
graph = dgl.graph(edges)
graph.edata['confidence'] = torch.tensor(confidence_scores,dtype=torch.float32)
graph.ndata['feature1_go'] = torch.tensor(feature1_go,dtype=torch.float32)
graph.ndata['feature2_ppi'] = torch.tensor(feature2_ppi,dtype=torch.float32)
"""print(graph)
# 输出边的权值值
edge_weights = graph.edata['confidence'].squeeze().numpy()
print("Edge Weights:")
print(edge_weights)
# 输出节点特征 'feature1_go'
feature1_go_values = graph.ndata['feature1_go'].squeeze().numpy()
print("Node Feature 'feature1_go':")
print(feature1_go_values)
# 输出节点特征 'feature2_ppi'
feature2_ppi_values = graph.ndata['feature2_ppi'].squeeze().numpy()
print("Node Feature 'feature2_ppi':")
print(feature2_ppi_values)"""
print(graph)
# 构建一个2层的GNN模型
import dgl.nn as dglnn
import torch.nn as nn
import torch.nn.functional as F
class SAGE(nn.Module):
def __init__(self, in_feats, hid_feats, out_feats):
super().__init__()
# 实例化SAGEConve,in_feats是输入特征的维度,out_feats是输出特征的维度,aggregator_type是聚合函数的类型
self.conv1 = dglnn.SAGEConv(
in_feats=in_feats, out_feats=hid_feats, aggregator_type='mean')
self.conv2 = dglnn.SAGEConv(
in_feats=hid_feats, out_feats=out_feats, aggregator_type='mean')
def forward(self, graph, inputs):
# 输入是节点的特征
h = self.conv1(graph, inputs)
h = F.relu(h)
h = self.conv2(graph, h)
return h
def construct_negative_graph(graph, k):
src, dst = graph.edges()
neg_src = src.repeat_interleave(k)
neg_dst = torch.randint(0, graph.num_nodes(), (len(src) * k,))
return dgl.graph((neg_src, neg_dst), num_nodes=graph.num_nodes())
import dgl.function as fn
class DotProductPredictor(nn.Module):
def forward(self, graph, h):
# h是从5.1节的GNN模型中计算出的节点表示
with graph.local_scope():
graph.ndata['h'] = h
graph.apply_edges(fn.u_dot_v('h', 'h', 'score'))
return graph.edata['score']
def compute_loss(pos_score, neg_score):
# 间隔损失
n_edges = pos_score.shape[0]
return (1 - pos_score.unsqueeze(1) + neg_score.view(n_edges, -1)).clamp(min=0).mean()
class Model(nn.Module):
def __init__(self, in_features, hidden_features, out_features):
super().__init__()
self.sage = SAGE(in_features, hidden_features, out_features)
self.pred = DotProductPredictor()
def forward(self, g, neg_g, x):
h = self.sage(g, x)
#return self.pred(g, h), self.pred(neg_g, h)
pos_score = self.pred(g, h)
neg_score = self.pred(neg_g, h)
return pos_score, neg_score
node_features = graph.ndata['feature1_go']
n_features = node_features.shape[1]
k = 1
model = Model(n_features, 10, 5)
opt = torch.optim.Adam(model.parameters())
for epoch in range(1):
negative_graph = construct_negative_graph(graph, k)
pos_score, neg_score = model(graph, negative_graph, node_features)
loss = compute_loss(pos_score, neg_score)
opt.zero_grad()
loss.backward()
opt.step()
print(f'Epoch {epoch + 1}, Loss: {loss.item()}')
任务1 图卷积网络 test1.py
import torch
import torch.nn as nn
import torch.optim as optim
from torch_geometric.data import Data
from torch_geometric.nn import GATConv
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score, average_precision_score, roc_curve, auc
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
# 读取数据
def read_data(file_path):
with open(file_path, 'r') as f:
data = f.read().splitlines()
return data
# 构建图数据
def build_graph_data(gene_list, link_list, feature1, feature2):
edge_index = []
edge_attr = []
x1 = []
x2 = []
gene_dict = {gene: idx for idx, gene in enumerate(gene_list)}
for link in link_list:
gene1, gene2, confidence = link.split('\t')
if gene1 in gene_dict and gene2 in gene_dict:
edge_index.append([gene_dict[gene1], gene_dict[gene2]])
edge_attr.append(float(confidence))
edge_index = torch.tensor(edge_index, dtype=torch.long).t().contiguous()
edge_attr = torch.tensor(edge_attr, dtype=torch.float).view(-1, 1)
for gene in gene_list:
if gene in gene_dict:
x1.append(feature1[gene_dict[gene]])
x2.append(feature2[gene_dict[gene]])
x1 = torch.tensor(x1, dtype=torch.float)
x2 = torch.tensor(x2, dtype=torch.float)
data = Data(x1=x1, x2=x2, edge_index=edge_index, edge_attr=edge_attr)
return data
# GAT 模型定义
class GATModel(nn.Module):
def __init__(self, in_channels, out_channels, heads):
super(GATModel, self).__init__()
self.conv1 = GATConv(in_channels, out_channels, heads=heads)
def forward(self, x, edge_index, edge_attr):
x = self.conv1(x, edge_index, edge_attr)
return x
# 训练模型
def train(model, data, optimizer, criterion, epochs):
model.train()
losses = [] # 用于记录每个 epoch 的损失值
for epoch in range(epochs):
optimizer.zero_grad()
out = model(data.x1, data.edge_index, data.edge_attr)
loss = criterion(out, data.x2)
loss.backward()
optimizer.step()
losses.append(loss.item()) # 记录当前 epoch 的损失值
print(f'Epoch {epoch + 1}/{epochs}, Loss: {loss.item()}')
# 绘制损失曲线图
plt.plot(losses)
plt.title('Training Loss Over Epochs')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.show()
# 评估链接预测结果
def evaluate(y_true, y_pred):
y_true = (y_true > 0.5).int().cpu().numpy()
y_pred = (y_pred > 0.5).int().cpu().numpy()
accuracy = accuracy_score(y_true, y_pred)
precision = precision_score(y_true, y_pred, average='micro')
recall = recall_score(y_true, y_pred, average='micro')
f1 = f1_score(y_true, y_pred, average='micro')
roc_auc = roc_auc_score(y_true, y_pred)
aupr = average_precision_score(y_true, y_pred)
return accuracy, precision, recall, f1, roc_auc, aupr
# 读取数据
gene_list = read_data('GeneList.txt')
link_list = read_data('Positive_LinkSL.txt')
feature1 = np.loadtxt('feature1_go.txt')
feature2 = np.loadtxt('feature2_ppi.txt')
# 划分数据集和测试集
train_gene_list, test_gene_list = train_test_split(gene_list, test_size=0.2, random_state=42)
# 构建训练集和测试集的图数据
train_data = build_graph_data(train_gene_list, link_list, feature1, feature2)
test_data = build_graph_data(test_gene_list, link_list, feature1, feature2)
# 创建并训练 GAT 模型
model = GATModel(in_channels=128, out_channels=128, heads=1)
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.MSELoss()
train(model, train_data, optimizer, criterion, epochs=200)
# 进行链接预测
pred_scores = model(test_data.x1, test_data.edge_index, test_data.edge_attr)
# 评估链接预测结果
accuracy, precision, recall, f1, roc_auc, aupr = evaluate(test_data.x2, pred_scores)
print(f'Accuracy: {accuracy} \nPrecision: {precision} \nRecall: {recall} \nF1 Score: {f1}')
print(f'ROC AUC: {roc_auc} \nAUPR: {aupr}')
import networkx as nx
import torch
from torch_geometric.data import Data
# 将 PyTorch Geometric 图数据转换为 NetworkX 图
G = nx.Graph()
G.add_nodes_from(range(test_data.num_nodes))
G.add_edges_from(test_data.edge_index.t().tolist())
# 使用 NetworkX 绘制图
pos = nx.spring_layout(G)
nx.draw(G, pos, with_labels=True, font_weight='bold', node_color='lightblue', node_size=1000, font_size=8, edge_color='gray')
plt.show()
任务2 多通道图卷积网络 test2.py
import torch
import torch.nn as nn
import torch.optim as optim
from torch_geometric.data import Data
from torch_geometric.nn import GCNConv
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score, average_precision_score, roc_curve, auc
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
# 读取数据
def read_data(file_path):
with open(file_path, 'r') as f:
data = f.read().splitlines()
return data
# 构建图数据
def build_graph_data(gene_list, link_list, feature1, feature2):
edge_index = []
edge_attr = []
x1 = []
x2 = []
gene_dict = {gene: idx for idx, gene in enumerate(gene_list)}
for link in link_list:
gene1, gene2, confidence = link.split('\t')
if gene1 in gene_dict and gene2 in gene_dict:
edge_index.append([gene_dict[gene1], gene_dict[gene2]])
edge_attr.append(float(confidence))
edge_index = torch.tensor(edge_index, dtype=torch.long).t().contiguous()
edge_attr = torch.tensor(edge_attr, dtype=torch.float).view(-1, 1)
for gene in gene_list:
if gene in gene_dict:
x1.append(feature1[gene_dict[gene]])
x2.append(feature2[gene_dict[gene]])
x1 = torch.tensor(x1, dtype=torch.float)
x2 = torch.tensor(x2, dtype=torch.float)
data = Data(x1=x1, x2=x2, edge_index=edge_index, edge_attr=edge_attr)
return data
# Multi-Channel Graph Convolutional Network 模型定义
class MultiChannelGCN(nn.Module):
def __init__(self, in_channels, out_channels):
super(MultiChannelGCN, self).__init__()
self.conv1 = GCNConv(in_channels, out_channels)
self.conv2 = GCNConv(in_channels, out_channels)
def forward(self, x1, x2, edge_index, edge_attr):
x1 = self.conv1(x1, edge_index, edge_attr)
x2 = self.conv2(x2, edge_index, edge_attr)
return x1, x2
# 训练模型
def train(model, data, optimizer, criterion, epochs):
model.train()
losses = [] # 用于记录每个 epoch 的损失值
for epoch in range(epochs):
optimizer.zero_grad()
out1, out2 = model(data.x1, data.x2, data.edge_index, data.edge_attr)
loss1 = criterion(out1, data.x1)
loss2 = criterion(out2, data.x2)
loss = loss1 + loss2
loss.backward()
optimizer.step()
losses.append(loss.item()) # 记录当前 epoch 的损失值
print(f'Epoch {epoch + 1}/{epochs}, Loss: {loss.item()}')
# 绘制损失曲线图
plt.plot(losses)
plt.title('Training Loss Over Epochs')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.show()
# 评估链接预测结果
def evaluate(y_true, y_pred):
y_true = (y_true > 0.3).int().cpu().numpy()
y_pred = (y_pred > 0.3).int().cpu().numpy()
accuracy = accuracy_score(y_true, y_pred)
precision = precision_score(y_true, y_pred, average='micro')
recall = recall_score(y_true, y_pred, average='micro')
f1 = f1_score(y_true, y_pred, average='micro')
roc_auc = roc_auc_score(y_true, y_pred)
aupr = average_precision_score(y_true, y_pred)
return accuracy, precision, recall, f1, roc_auc, aupr
# 读取数据
gene_list = read_data('GeneList.txt')
link_list = read_data('Positive_LinkSL.txt')
feature1 = np.loadtxt('feature1_go.txt')
feature2 = np.loadtxt('feature2_ppi.txt')
# 划分数据集和测试集
train_gene_list, test_gene_list = train_test_split(gene_list, test_size=0.2, random_state=42)
# 构建训练集和测试集的图数据
train_data = build_graph_data(train_gene_list, link_list, feature1, feature2)
test_data = build_graph_data(test_gene_list, link_list, feature1, feature2)
# 创建并训练 Multi-Channel GCN 模型
model = MultiChannelGCN(in_channels=128, out_channels=128)
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.MSELoss()
train(model, train_data, optimizer, criterion, epochs=200)
# 进行链接预测
pred_scores1, pred_scores2 = model(test_data.x1, test_data.x2, test_data.edge_index, test_data.edge_attr)
pred_scores = (pred_scores1 + pred_scores2) / 2 # 取两个通道的平均值
# 评估链接预测结果
accuracy, precision, recall, f1, roc_auc, aupr = evaluate(test_data.x2, pred_scores)
print(f'Accuracy: {accuracy} \nPrecision: {precision} \nRecall: {recall} \nF1 Score: {f1}')
print(f'ROC AUC: {roc_auc} \nAUPR: {aupr}')
import networkx as nx
import torch
from torch_geometric.data import Data
# 将 PyTorch Geometric 图数据转换为 NetworkX 图
G = nx.Graph()
G.add_nodes_from(range(test_data.num_nodes))
G.add_edges_from(test_data.edge_index.t().tolist())
# 使用 NetworkX 绘制图
pos = nx.spring_layout(G)
nx.draw(G, pos, with_labels=True, font_weight='bold', node_color='lightblue', node_size=1000, font_size=8, edge_color='gray')
plt.show()
任务2 n通道图卷积网络 test2.2.py
import torch
import torch.nn as nn
import torch.optim as optim
from torch_geometric.data import Data
from torch_geometric.nn import GCNConv
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, roc_auc_score, \
average_precision_score
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
# 读取数据
def read_data(file_path):
with open(file_path, 'r') as f:
data = f.read().splitlines()
return data
# 构建图数据
def build_graph_data(gene_list, link_list, feature1, feature2):
edge_index = []
edge_attr = []
x1 = []
x2 = []
gene_dict = {gene: idx for idx, gene in enumerate(gene_list)}
for link in link_list:
gene1, gene2, confidence = link.split('\t')
if gene1 in gene_dict and gene2 in gene_dict:
edge_index.append([gene_dict[gene1], gene_dict[gene2]])
edge_attr.append(float(confidence))
edge_index = torch.tensor(edge_index, dtype=torch.long).t().contiguous()
edge_attr = torch.tensor(edge_attr, dtype=torch.float).view(-1, 1)
for gene in gene_list:
if gene in gene_dict:
x1.append(feature1[gene_dict[gene]])
x2.append(feature2[gene_dict[gene]])
x1 = torch.tensor(x1, dtype=torch.float)
x2 = torch.tensor(x2, dtype=torch.float)
data = Data(x1=x1, x2=x2, edge_index=edge_index, edge_attr=edge_attr)
return data
# Multi-Channel Graph Convolutional Network 模型定义
class MultiChannelGCN(nn.Module):
def __init__(self, in_channels, out_channels, num_channels):
super(MultiChannelGCN, self).__init__()
self.channels = nn.ModuleList([GCNConv(in_channels, out_channels) for _ in range(num_channels)])
def forward(self, *inputs):
output_channels = [channel(x, inputs[-2], inputs[-1]) for channel, x in zip(self.channels, inputs[:-2])]
return output_channels
# 训练模型
def train(model, data, optimizer, criterion, epochs):
model.train()
losses = [] # 用于记录每个 epoch 的损失值
for epoch in range(epochs):
optimizer.zero_grad()
output_channels = model(data.x1, data.x2, data.edge_index, data.edge_attr)
# Assuming that data.x1 and data.x2 are the target values for each channel
loss = sum(criterion(output, data.x1 if i == 0 else data.x2) for i, output in enumerate(output_channels))
loss.backward()
optimizer.step()
losses.append(loss.item()) # 记录当前 epoch 的损失值
print(f'Epoch {epoch + 1}/{epochs}, Loss: {loss.item()}')
# 绘制损失曲线图
plt.plot(losses)
plt.title('Training Loss Over Epochs')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.show()
# 评估链接预测结果
def evaluate(y_true, y_pred):
y_true = (y_true > 0.3).int().cpu().numpy()
y_pred = (y_pred > 0.3).int().cpu().numpy()
accuracy = accuracy_score(y_true, y_pred)
precision = precision_score(y_true, y_pred, average='micro')
recall = recall_score(y_true, y_pred, average='micro')
f1 = f1_score(y_true, y_pred, average='micro')
roc_auc = roc_auc_score(y_true, y_pred)
aupr = average_precision_score(y_true, y_pred)
return accuracy, precision, recall, f1, roc_auc, aupr
# 读取数据
gene_list = read_data('GeneList.txt')
link_list = read_data('Positive_LinkSL.txt')
feature1 = np.loadtxt('feature1_go.txt')
feature2 = np.loadtxt('feature2_ppi.txt')
# 划分数据集和测试集
train_gene_list, test_gene_list = train_test_split(gene_list, test_size=0.2, random_state=42)
# 构建训练集和测试集的图数据
train_data = build_graph_data(train_gene_list, link_list, feature1, feature2)
test_data = build_graph_data(test_gene_list, link_list, feature1, feature2)
# 创建并训练 Multi-Channel GCN 模型
num_channels = 150 # Set the number of channels (adjust as needed)
model = MultiChannelGCN(in_channels=128, out_channels=128, num_channels=num_channels)
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.MSELoss()
train(model, train_data, optimizer, criterion, epochs=200)
# 进行链接预测
pred_scores_list = model(test_data.x1, test_data.x2, test_data.edge_index, test_data.edge_attr)
pred_scores = torch.stack(pred_scores_list).mean(dim=0) # Take the mean across channels
# 评估链接预测结果
accuracy, precision, recall, f1, roc_auc, aupr = evaluate(test_data.x2, pred_scores)
print(f'Accuracy: {accuracy} \nPrecision: {precision} \nRecall: {recall} \nF1 Score: {f1}')
print(f'ROC AUC: {roc_auc} \nAUPR: {aupr}')
import networkx as nx
import torch
from torch_geometric.data import Data
# 将 PyTorch Geometric 图数据转换为 NetworkX 图
G = nx.Graph()
G.add_nodes_from(range(test_data.num_nodes))
G.add_edges_from(test_data.edge_index.t().tolist())
# 使用 NetworkX 绘制图
pos = nx.spring_layout(G)
nx.draw(G, pos, with_labels=True, font_weight='bold', node_color='lightblue', node_size=1000, font_size=8,
edge_color='gray')
plt.show()
参考文献
使用图神经网络进行链接预测
-
https://docs.dgl.ai/tutorials/blitz/4_link_predict.html
-
https://docs.dgl.ai/en/0.8.x/guide_cn/training-link.html
-
https://github.com/Giantjc/LinkPrediction
-
https://zhuanlan.zhihu.com/p/599510610?utm_id=0
-
https://docs.dgl.ai/en/latest/guide_cn/training-node.html
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!