深入理解 Hadoop (二)HDFS架构演进
HDFS 分布式集群架构设计实现

核心设计思路:分而治之的思路,实现分散存储 + 冗余存储
元数据管理核心问题:
- 文件系统目录树
- 文件 和 数据块 的映射关系
- 数据块 和 副本存储主机 之间的映射关系
NameNode 内部两个非常重要的组件: - NameNodeRpcServer:RPC 服务端,接收所有客户端的 RPC 请求来执行处理
- FSNamesystem:负责管理元数据
- 内存中有一份完整的:FSDirectory
- 磁盘中也有一份完整的:FSImage
HDFS HA 高可用集群架构设计实现
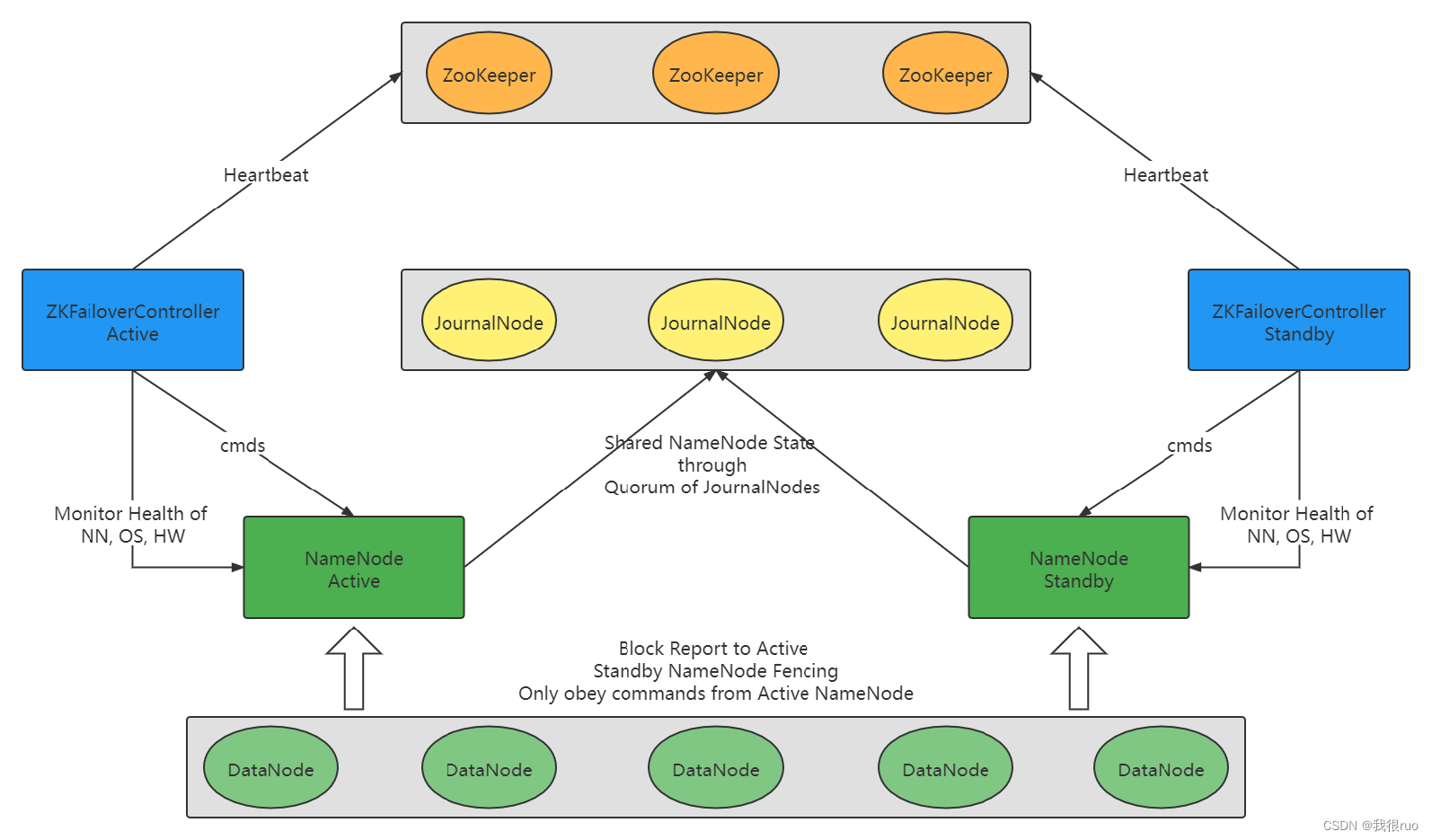
HA 高可用架构的四个问题及解决方案:
1. 同时启动的两个 NameNode 到底谁成为真正的 active ? —— zookeeper 分布式锁
2. 如果 active 死掉,那么 standby 怎么知道,并且切换状态呢? —— zookeeper 分布式锁
3. 既然 standby 能切换自己的状态成为 active 对外提供服务,必须要保证 standby 和 active 的状态是一致的?—— JournalNode 分布式事务
4. active namenode 假死导致脑裂?隔离机制,确保 active 一定要死掉
HDFS 架构复杂的原因 —— namenode 是有状态的
HA HDFS 集群的瓶颈 —— 单 NameNode 维护和管理的 DataNode 必然负载过重
- 内存不够:当前 HDFS 集群中的所有元数据,都需要在内存中,存储一份,企业最佳实践中,一般 NameNode 的内存特别大。
- 单点 NameNode 的并发性能不够:所有客户端的请求,都是发送给 NameNode。
HA HDFS 集群瓶颈解决方案 —— 通过增加 namenode 的个数,来分担原来单 NameNode 的压力。
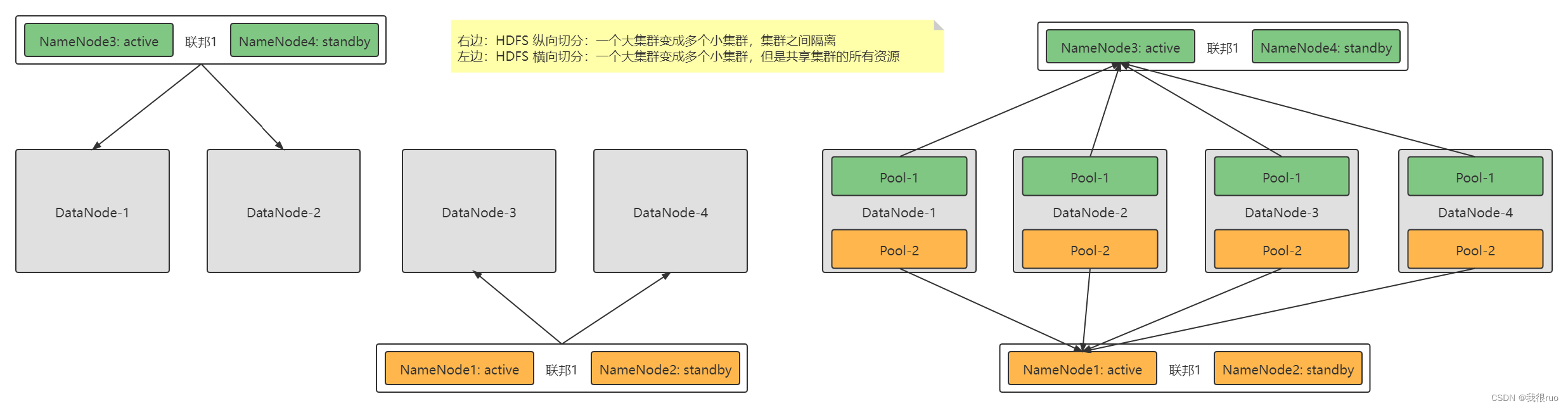
HDFS Federation 联邦集群架构设计实现
HDFS 字节跳动多机房版本架构实现
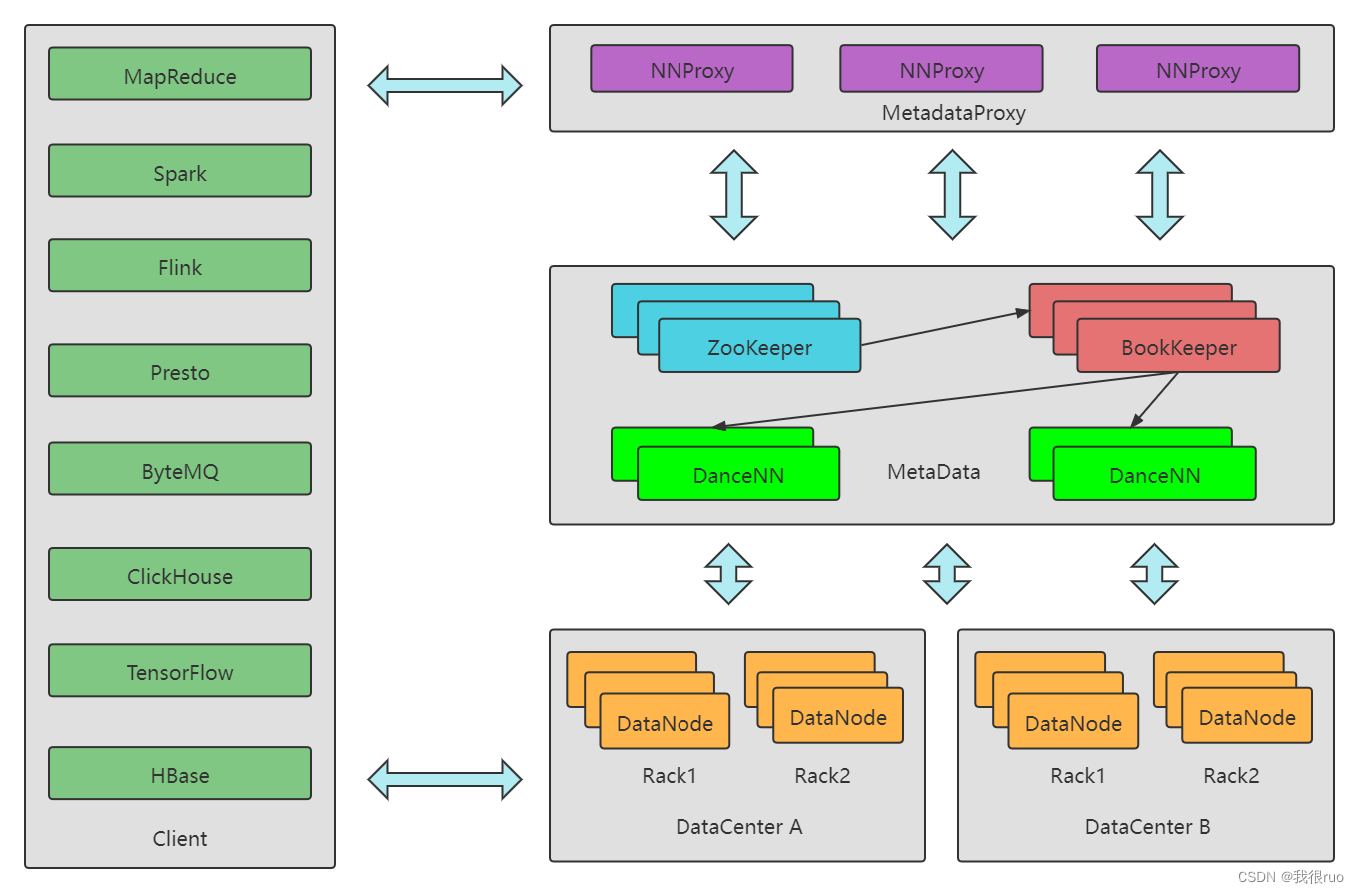
关于上图中的一些解释:
DanceNN:这是 字节跳动用 C++ 重写的 NameNode,完全兼容 NameNode 的通信协议。
NNProxy:即 NameNode Proxy,为 Federation 功能提供统一的 Namespace,类似于 mysql 中间件 mycat。
BookKeeper:即 Apache BookKeeper,其作用是跟社区的 JournaNode 是一样的,就是为 Active 和 Standby NameNode 提供一个共享的 editlog 存储方案,这是实现 NameNode 的 HA 方法的基础。
关于多机房架构,事实上,是多机架的联邦集群的升级版本:
- A/B 机房的 DataNode 直接跨机房组成一个双机房集群,向相同的 NameNode 汇报。
- 每一个文件在写的时候会保证每个机房至少存在一个副本,数据实时写到两个机房。
- 每个 Client 在读取文件的时候,优先读取本机房的副本,避免产生大量的跨机房读带宽。
这个设计的好处就是存储层对上层应用屏蔽了集群细节,计算资源可以直接无感分配。该设计结合离线数据一写多读的特点,充分考虑跨机房带宽的合理使用。
- 由于写带宽一般不会有突发,机房间的离线带宽可以支撑同步写的需求,因此数据可以两个机房同步放置至少一个副本。
- 离线查询容易有大的突发请求,因此需要确保常规状态下没有突发的跨机房读带宽。

- 常态下,editlog 会以 4 个副本存放到 BookKeeper 上,这 4 个副本的机房分布比例为 1:1。
- 容灾场景下,DanceNN 可以快速切换成单机房模式,editlog 依然以 4 个副本存放,但是存储策略变为单机房存储,历史的 editlog 也能正常消费。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2023年度 热门API 测试工具大盘点
- ssm基于vue.js的连锁干洗店后台管理系统论文
- 面试复盘5——后端开发——一面
- Python科学计算库Numpy
- C++入门学习(一)写一个helloworld
- Unity 编辑器篇|(九)编辑器美化类( GUIStyle、GUISkin、EditorStyles) (全面总结 | 建议收藏)
- ssm/php/node/python公司财务管理系统
- Docker在物联网和边缘计算中的应用
- 一文读懂 $mash 通证 “Fair Launch” 规则(幸运池玩法解读篇)
- C++11新特性:final/override控制