KAFKA
KAFKA
kafka 入门
什么是kafaka 应该如何理解?
分布式,分区的,多副本的,消息队列功能
吞吐量高,伸缩性,容错性好(持久化/好几份),一主多备高可用
有流处理的功能
概念
什么是(topic /?tɑ?p?k/)主题?
什么是(partition /pɑ?r?t??n/)分区?
什么是(offset /???fset/)偏移量?
什么是(record /rek??d/)消息格式?
什么是(broker /?bro?k?r/)消息代理?
什么是主(leader)分区-主?
什么是从(followr)分区-从?
什么是(consumer group /k?n?su?m?r ɡru?p/)消费者组?
什么是(producer group /pr??du?s?r ɡru?p/)生产者?
什么是(kafka Cluster /?kl?st?r/)kafka集群?
什么是副本因子?
什么是 acks = -1/0/1区别?
AMQP
AMQP 模型(协议)
队列(queues)
信箱(exchanges)
绑定(bindings)
特点: 支持事务,多用于金融,银行.
典型: RabbitMq
MQTT 模型(协议)
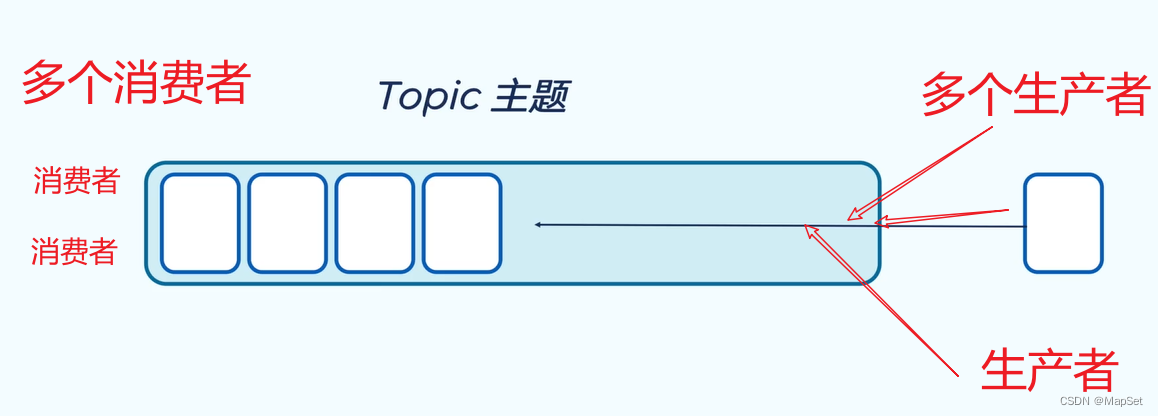
Topic 主题
半结构化的数据
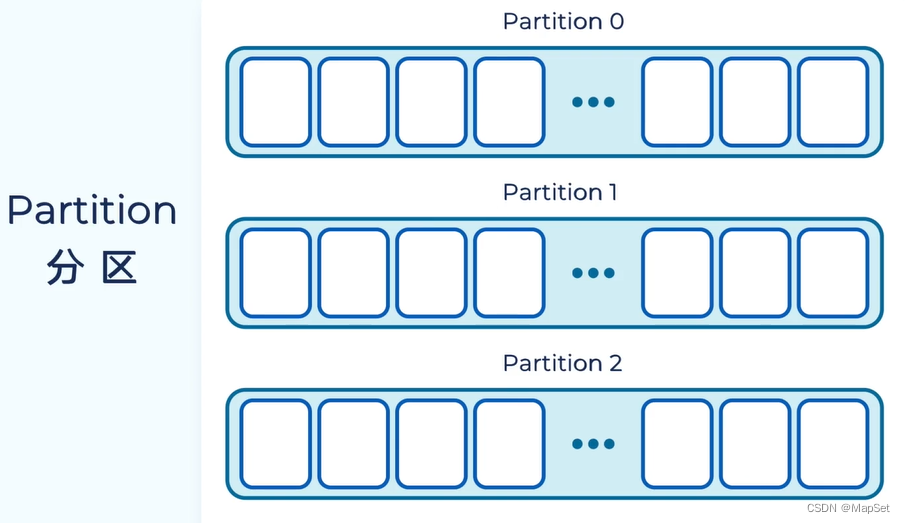
主题包含多个分区
Partion 分区
消息存储到Partin后,不可变,
不同的分区,存于不同的服务器上.(扩展性)
会选举Leader(一个)
其他的为follower(多个)
调整分区数量
可根据偏移量,查询消息,但是不可变更
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
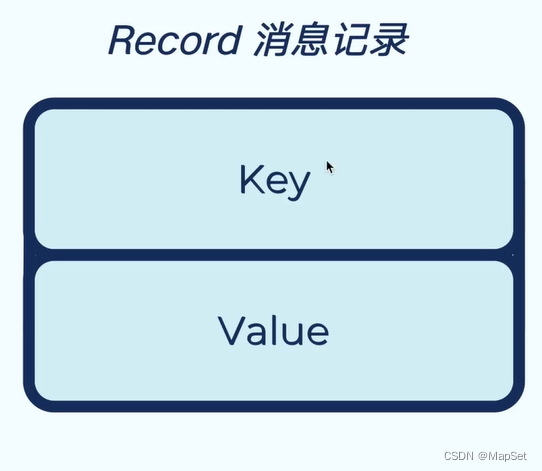
Racord 消息记录
消息Racord 为 k-v
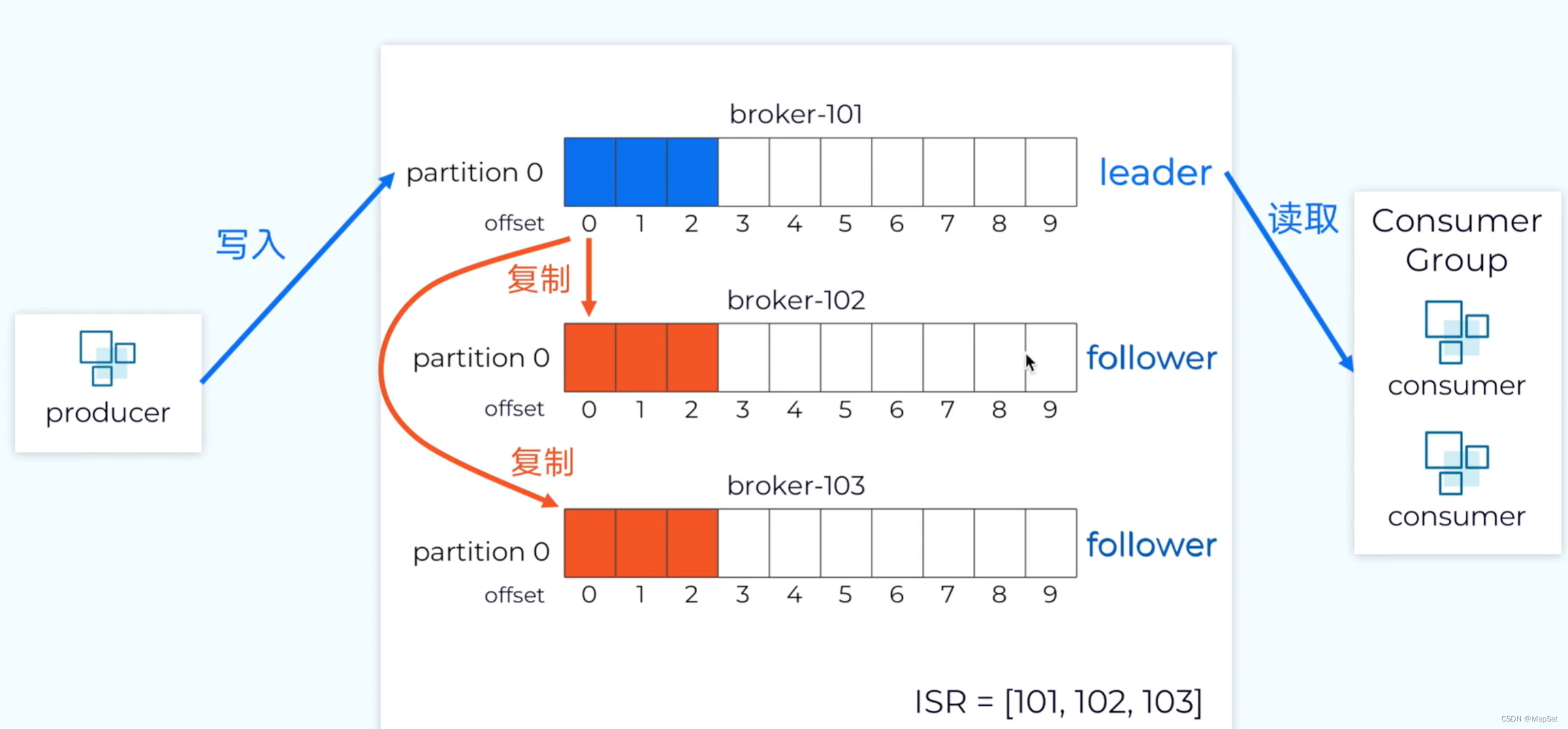
若 kafka通过副本机制,保证数据的副本
replication-factor=3 设置副本因子的数量(包含主分区)
所有数据的写入,都是写入到leader中,
所有数据的读取,也是从leader中.
follower只负责从leader中获取同步.
若follower未同步,ISR会剔除,
直到follower同步同步完毕后,ISR添加
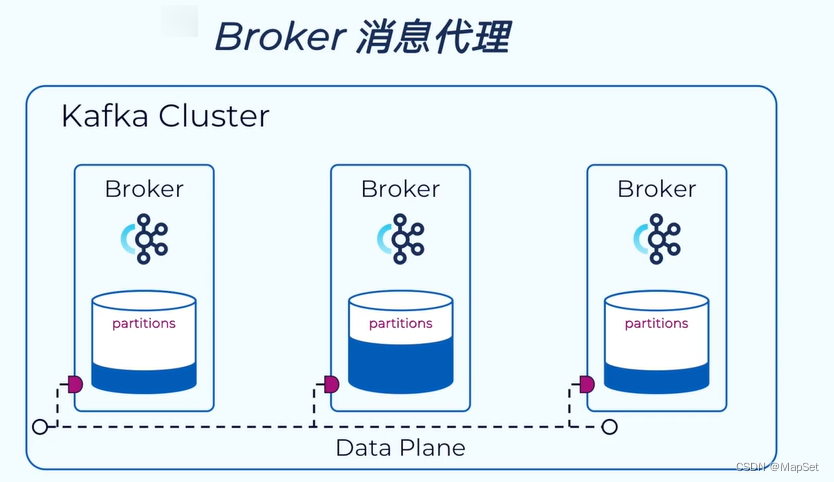
Broker 消息代理
负责将消息写入到磁盘中
Kafka Cluster 集群
broker 代理
partitions 分区
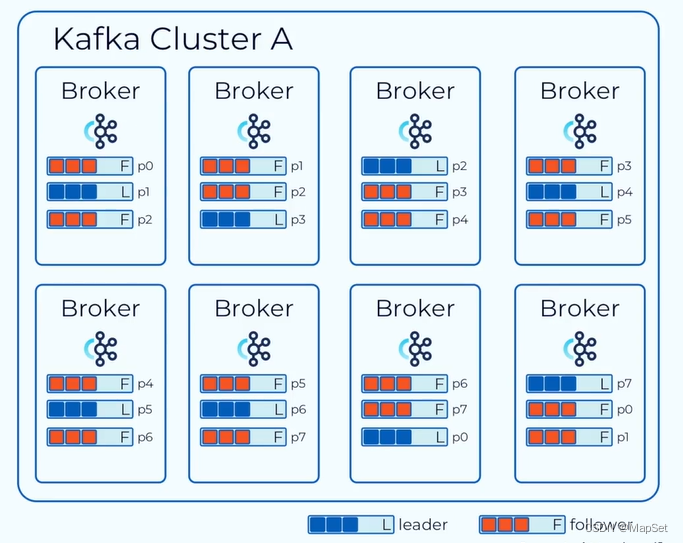
蓝色为Leader
橘红为Follower
这个集群有8个Broker,集群中主题(topic)有8个分区(partition)P0-P7,副本因子3
kafka 本地vm安装集群
建议安装vm
建议直接docker集群
kafka 理论知识
消费模型
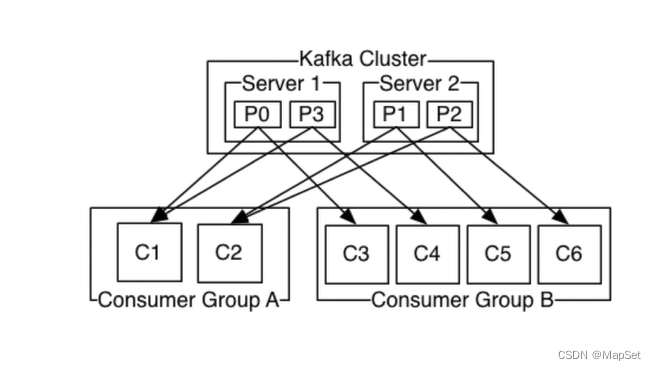
分区是最小的并行单位
一个消费者可以消费多个分区
注意:一个分区不能同时被同一个组的多个消费(P0不能被C1,C2同时消费)
(出于性能和开销,还有锁的考虑)
可以把消费者发一个组里,这样还可以负载均衡,还不会多次消费
点对点
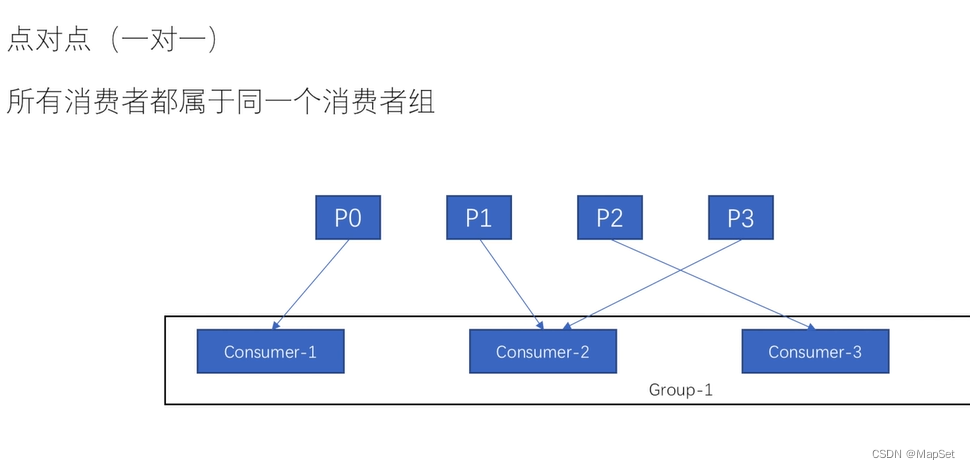
发布订阅
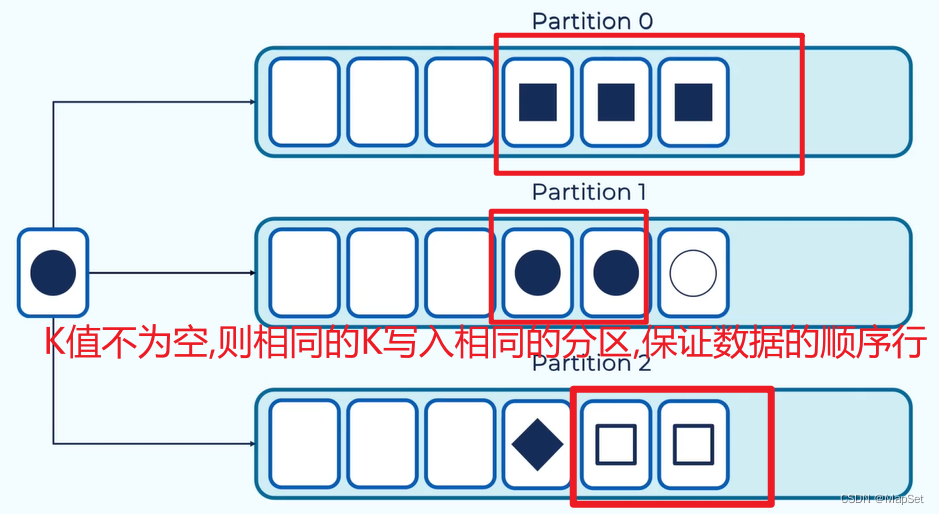
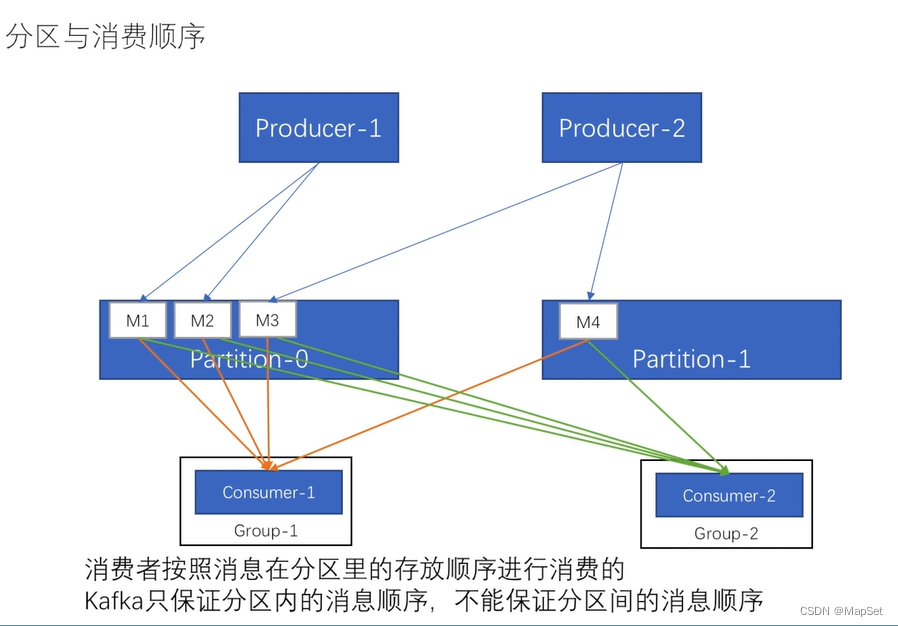
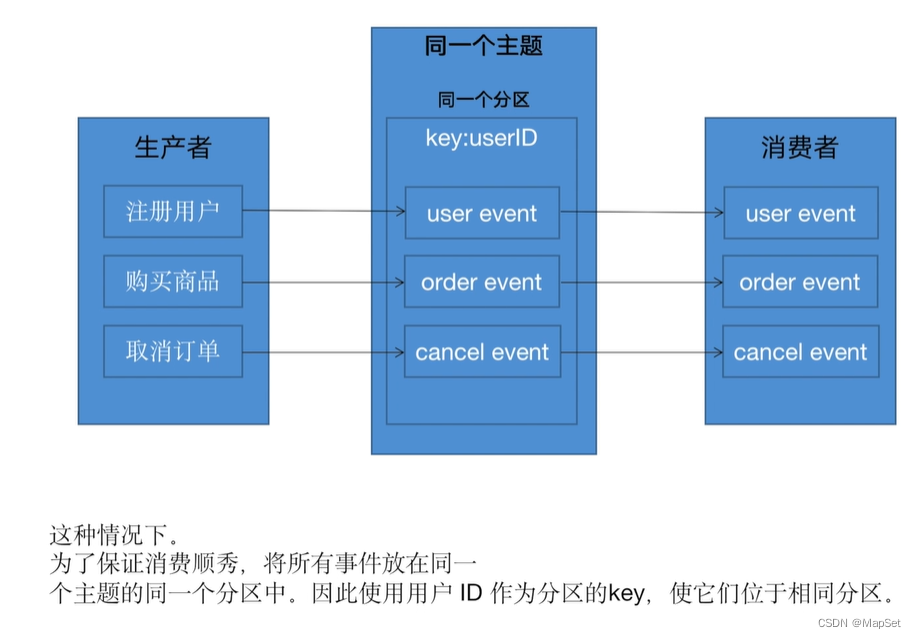
分区和消息顺序
设置一个分区,这样就可以保证所有的消息的顺序,但是失去了拓展性和性能
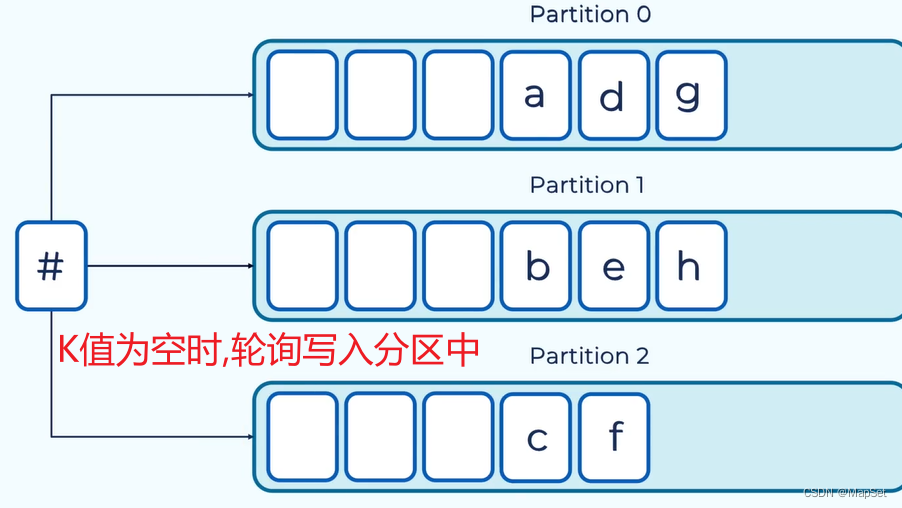
支持通过设置消息的key,相同key的消息会发送的同一个分区.
消息传递语义
acks同步机制
acks=0
不会等待;
生产者在成功写入消息之前不会等待任何来自服务器的响应
acks=1
已经被kafka-leader接受到(不一定是写入成功/不一定同步到followr);
表示只要集群的leader分区副本接收到了消息,就会向生产者发送一个成功响应的ack
aks=-1/all
所有副本都接受到了信息
表示只有所有参与复制的节点(ISR列表的副本)全部收到消息时,生产者才会接收到来自服务器的响应. 这种模式是最高级别的,也是最安全的,可以确保不止一个Broker接收到了消息. 该模式的延迟会很高
最少一次
acks=-1或all
retries>0
消息不会丢失,但可能会重复
生产者:

消费者:
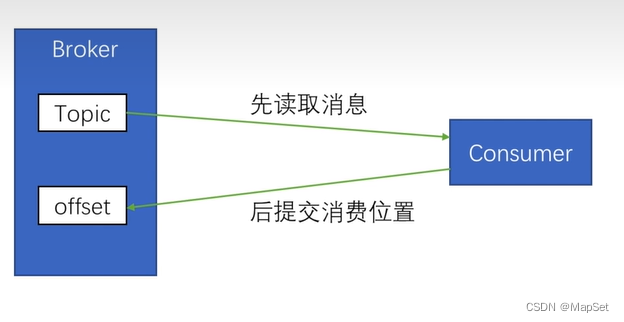
最多一次
acks=0或acks=1
消息可能会丢失,永远不会重复发送
生产者:
消费者:
先提交消费位置
后读取信息
精准一次
保证消息被传递到服务端且在服务端不重复
需要生产者,消费者共同来保障.
## 启用幂等参数
enable.idempotence=true
retries=Integer.MAX_VALUE
acks=all
通过offset来防止,不好
通常是加入唯一ID,流水ID,来实现精确一次
异步发送
同步太慢,效率太低,使用异步发送
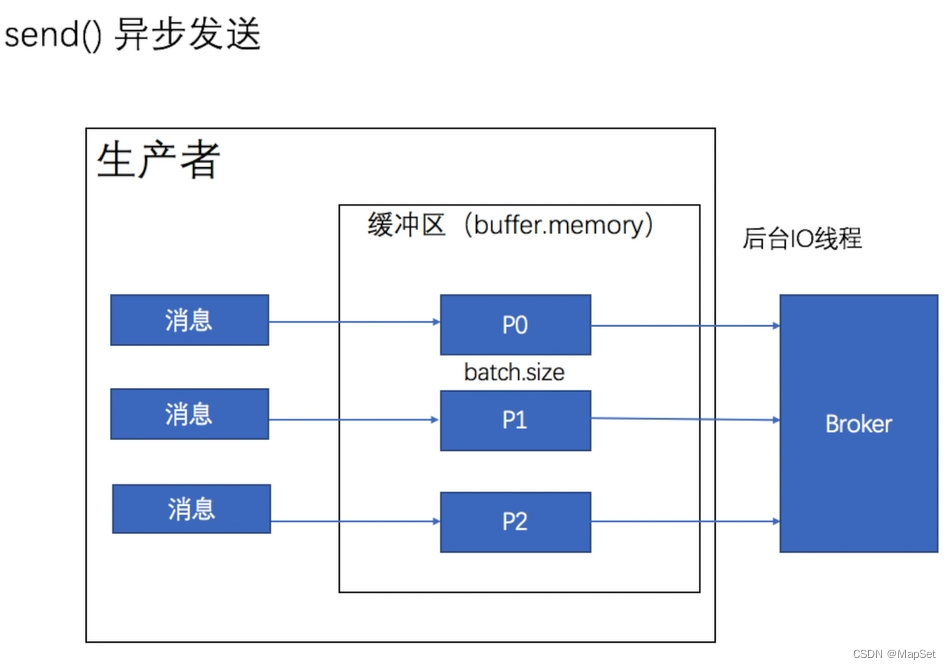
KafkaProducer (kafka 3.2.3 API) (apache.org)
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
public class Test {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("linger.ms", 1);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 100; i++)
producer.send(new ProducerRecord<String, String>("my-topic", Integer.toString(i), Integer.toString(i)));
producer.close();
}
}
自动提交–至多一次
kafka支持批量发送
事务消息
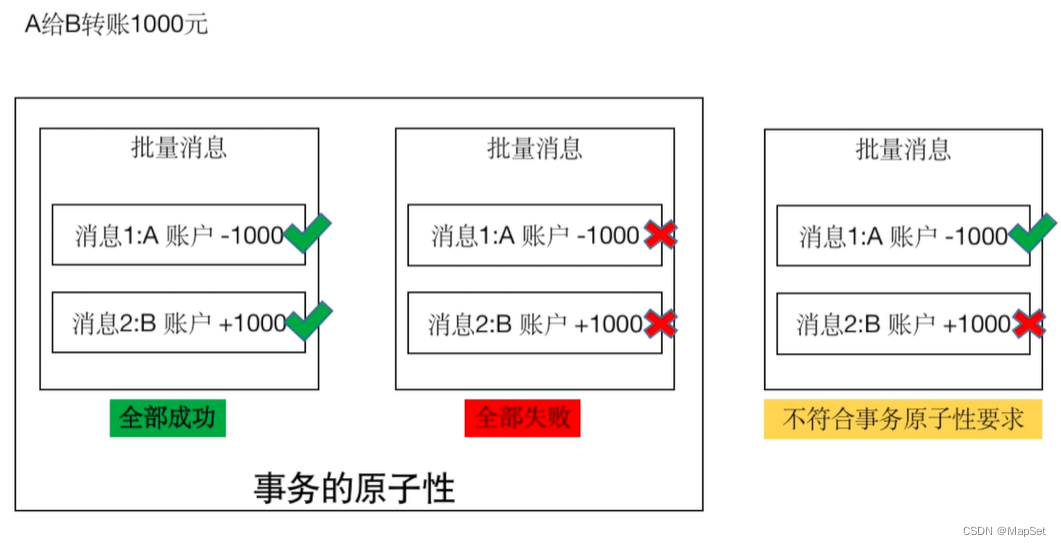
事务
Isolation Level 隔离级别
默认: read_uncommitted 脏读
read_committed 读取成功提交的数据, 不会脏读
序列化/反序列化
序列化


自定义序列化

常用消息格式
CSV: 逗号分割(数据简单)
JSON: 可读性高,占用空间大; (Elastic Search支持)
序列号消息–Avro(Hadoop,Hive支持)
序列化消息–Protobuf
保证先后顺序
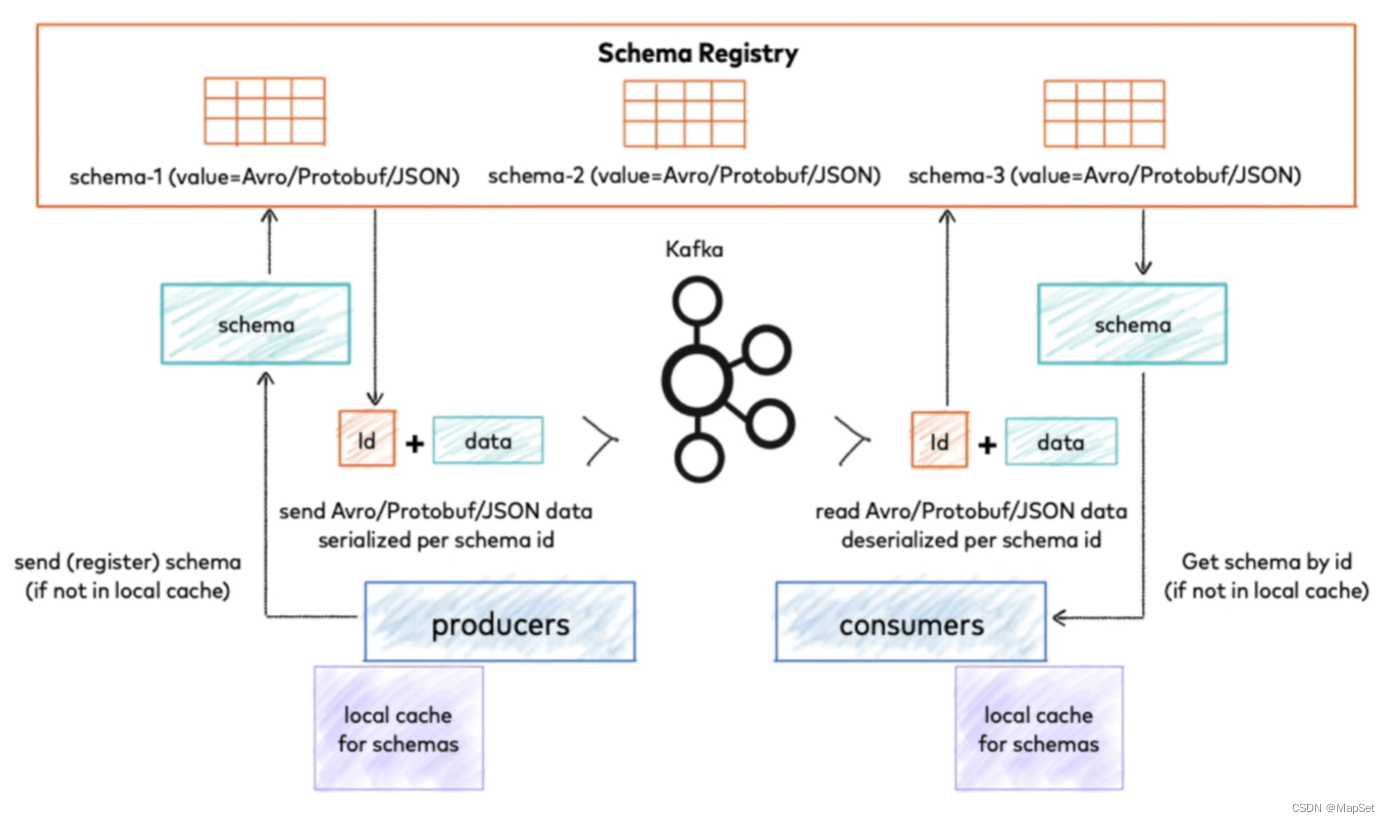
Confluent Schema Registry
汇流架构注册表
/kɑn?flu?nt/ /?ski?m?/ /?red??stri/
1.数据解析强依赖 schema registry
2.破坏数据本身
Record Header


kafka 面试点
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【设计模式之美】面向对象分析方法论与实现(一):需求分析方法论
- 改进YOLO系列 | YOLOv5/v7 引入高效的混合特征编码器 AIFI
- 【力扣 445】两数相加 II C++题解(链表+模拟+数学+头插法)
- unity HoloLens2开发,使用Vuforia识别实体 触发交互(二)(有dome)
- React-路由进阶
- 接口自动化测试实战教程
- 嵌入式培训机构四个月实训课程笔记(完整版)-Linux系统编程第十天-source insight快捷键(物联技术666)
- jquery Tab切换,CSS3制作发光字
- 家具建材类网站pb的前端html页面
- 【一个中年程序员的独白】