Linux:完全理解文件系统
文章目录
上一篇,已经总结了磁盘和内存之间的加载关系,也已经对于磁盘有了一个初步的理解,可以由LBA和CHS之间建立起来联系,也有了一个初步的理解,对于存储设备的管理,在操作系统层面转换成了对于数组的增删查改,那么下面的问题是,磁盘是一块很大的空间,想要把整个磁盘和磁盘上的文件管理好,本质上就是把磁盘的空间管理好,磁盘空间假设有500G,这是一个很大的个概念
磁盘的划分
而在实际的运用中,会安装各种各样的软件,例如有系统类别,有操作系统类别,也有一些配置文件和自己安装的应用程序,也就是说,这500G的空间是不需要整体被使用的,太大了,因此要对区域进行划分,假设现在将这500G的空间分成四个模块,也就意味着会把这管理500G的空间这个任务转换成管理100G的空间,那么相同的方法只需要运用到剩下的模块就可以了
那么整个过程,实际上就是一个分区的过程,现在单独拿出来这100G进行管理,再将这个区域划分成组,组的划分在不同的操作系统中有不同的划分方式,以Linux划分为例,会有固定的配比,现在假设划分的标准就是2G为一个组,那么现在就将磁盘的这100G划分成了50个组,一个组占据的内存空间是2G,这样大事化小小事化了的思想,也就是一种分治的体现
具体的调用过程如下所示,现在已经拥有了一个一个的group,现在就是要对这些group进行管理

那么下面要讨论的部分就是,磁盘的组内部是如何划分的?划分的依据是什么?磁盘又是如何和系统之间建立调用的呢?
Boot Block
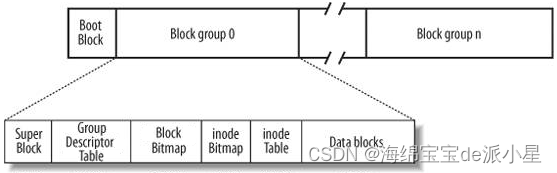
第一个要说的分区就是Boot Block,那么这个分区是做什么的呢?我们把它叫做启动快,一般而言,可以把Boot Block理解成编号为0的磁道,可以理解为第一分区,它的作用是负责启动整个系统,例如在启动电脑前,会对整个的计算机进行一个系统的检查,检查相关的外设信息,而这个分区的意义也是如此,主要是来负责记录整个磁盘被分成了多少个区,这些区从哪开始,从哪结束,有多少分区,对于整个操作系统中的启动块大概是什么位置,如何跳转加载操作系统模块的代码
一般情况来说,笔记本中的扇区是可以进行更换的,这是因为文件系统拥有一定的自我修复能力,但是Boot Block区域不能坏,如果这个区域坏掉了,只能进行重装系统了,重装也就相当于是对于文件系统进行了重新的写入
磁盘信息的管理
磁盘中的信息无非有两种,一种信息是存储的文件信息,一种信息是对于这些文件管理的数据
1. 文件的信息
文件的信息其实就是前面一直提到的,文件 = 内容 + 属性,而内容和属性都是一种数据,要将这两种数据进行分开存储
2. 文件管理的数据
什么是文件管理的数据?例如现在给定一个文件名,操作系统如何能够快速的找到这个文件?当然是要对这些文件进行一些合适的管理,才能在用户需要的时候快速对文件进行定位和查询相关的信息,那查找文件这个过程和文件本身有关系吗?答案显然是没有关系
那么就说明,文件管理过程中产生的数据和文件本身的数据是两个内容,磁盘中要管理的信息其实也就是这两种信息
在正式使用文件系统之前,要将管理的数据提前分配到组中,才能在真正使用文件系统的时候,可以直接对系统进行管理,有多少块被占用了,有多少块没有被使用,这些内容都是要在分区之前,就提前将这些管理的信息写入到文件系统当中,这个过程就叫做格式化
**格式化?**格式化难道不是清楚数据吗?这句话本身是没问题的,因为格式化确实会清楚文件的内容,但是文件的管理数据从来都没有被清空,清除的只是文件的内容
inode编号
在学习Linux指令的时候知道,对于ls命令来说是可以带有选项的,其中有一个选项是-i,调用这样的选项查看目录:

此时会发现前面多了一串数字,那这串数字是干什么的呢?有什么实际的意义价值呢?
这串数字就叫做文件的inode编号
一般情况而言,一个文件对应的是一个inode编号,每一个inode编号在分区上是具有唯一性的,如何理解唯一性?在Linux内核中,对于识别文件的,识别的本质上是文件的inode编号,而不是什么文件名或是其他,文件系统在操作系统层面上并不关心,它只关心编号是什么,而在每一个分区前都会标记着有start_inode_number,用来表示这个分区的inode是从哪里开始的,这样可以很方便的进行查找
那么下一步,基于上面的这些基础知识,现在我们要对文件系统中的这些分区来进行一定的理解
inode Table
文件包括的是内容和属性,对于这块分区来说这里只谈属性,如何理解属性?
属性有很多点组成,有文件大小,所有者等等,但是这些属性一定是固定的,每一个文件都应该拥有固定的属性集,用来存储对应的信息,在磁盘中保存信息是通过inode进行的,那么inode究竟是一个什么东西呢?
本质上来说,inode其实就是一个文件的属性集,可以把它想象成是一个结构体,一般理论而言,操作系统与会把inode指定为128字节
struct inode
{
// 大小 权限 拥有者所属组...
// inode编号等等
// 数据存储
}
先说定义,inode Table从理论上来说,是用于存放文件的属性,例如文件大小,所有者,最近修改时间等等。从根本上来说,当一个文件要进入文件系统时,就把inode编号,大小权限所属组等等一系列所有的信息都填入到这个inode的结构体中,这样就完成了一个文件的属性存储工作,紧接着就把这个编号结构体放到inode Table中,因此这个inode Table就是用来存放inode结构体的一张表,所以也叫做i节点表
而inode结构体是有固定大小的,在Linux中这个大小是128字节,因此这意味着,操作系统可以根据128字节的大小,再根据偏移量,就能在这块内存中找到具体的想要的某一个inode
换句话说,想给文件分配一个inode是一件很容易的事情,inode Table本质上可以看成是一个数组
struct inode inode_table[N]
在这个数组中存放的就是一个一个的inode结构体,而在这一个一个的inode结构体中又包含了各种各样的关于文件的基本信息,也能知道编号等等,这都是可以找到的,同时也可以佐证一个观点,前面一直在说文件等于内容加属性,那么属性其实就存储在了inode中,那么下一步要保存的就是内容
Data blocks
下面要探讨的分区就是Data blocks分区,inode Table分区已经存储好了文件的属性,那文件的内容自然就是由Data blocks来存储了
现在用户向系统中申请了一个文件,就会为这个文件创建对应的inode信息和inode编号,但是这只是完成了保存属性的工作,而这个Data blocks区域就是一个非常大的数据存储区域,里面每一个单位是4kb,那么就可以理解为,是一个以4kb为基本单元的数据块区域,既然是固定大小,那么就意味着未来在进行寻找的过程也很好寻找,那么是不是可以对于前面的inode结构体进行补充了呢?
struct inode
{
// 大小 权限 拥有者所属组...
// inode编号等等
int blocks[15] // -> 1 2 3...
}
在inode结构体中,就会存储对应在Data blocks内的信息,而存储的就是这当中的下标,这样做的好处也很明显,最终将block数组中找到的数据直接导入到内存中就可以了,这样也就能体现出内容和属性的关联
操作系统是如何找到文件的?
操作系统想要找到文件,实际上就是找到这个文件的inode编号,通过inode编号就能找到inode中对应的各种各样的属性,进而可以与内容建立联系,那inode编号是如何知道的?这就和前面所说的start_inode_number建立起了联系,根据编号可以精准的知道我要找的这个inode编号落在了哪个区间,就可以直接在inode_Table中索引到对应的内容,那么属性和内容就都有了
存储空间的问题
在上面定义的时候写到,block数组中只有15个元素,这并非是随意一写,而是在内核中确确实实是用这样的方式进行存储的,但是问题随之而来的是,不会存储满吗?15个空间,一个空间也就4kb,这够啥呢?
实际上,解决策略也其实很简单,对于下标是0-12的内容来说,采取的是直接映射,一个下标中存储的是一个数据区的小块内容,而对于13这个下标来说,存储的是二级映射,也就是说它当中存储的是很多个小块的地址,一个下标就可以对应很多个空间,而对于下标为14的元素来说,采取的是三级映射,在原来二级映射的基础上又多了一级,也就是说,它会映射很多个二级映射点,每一个二级映射点又会对应很多个数据块,这样就解决了大文件的存储问题,当然这也是有上限的,只不过这个上限通常来说是不会轻易达到的
所以,一个文件也是有存储上限的,操作系统不可能允许你一直存储一个特别特别大的文件,文件的数据量大到一定程度,文件系统也无能为力了
inode Bitmap和block Bitmap
下面来临的问题是,现在用户要访问一个文件,所以现在就在操作系统中用inode去一个一个比对,但是组内有很多很多个inode,这样比对的效率是否太低了呢?在创建一个新的内容时,需要对这个文件重新分配一个inode,操作系统怎么知道应该分配哪个呢?换句话说,操作系统应该如何进行合理的分配呢?
于是就诞生了inode Bitmap和block Bitmap,这个其实不难理解,就是位图,关于位图其实已经介绍的很充分了,根据0和1的存储规则,可以很清楚的知道这个地方到底存储情况如何,同时也体现出了前面固定内存标号的好处,可以很轻松的找到是第几个文件,进而在位图中进行寻找,这都是可以得到的信息
在有了上述的知识后,对于文件存储到文件系统的这一整个过程已经有了一个基础的认知,那么我们来总结一下:
上层作为用户,新建了一个文件,里面写了一个hello world,在操作系统层面会进行什么操作呢?
首先,新建一个文件,文件就是内容加属性,那么第一步就要申请文件的属性
对于文件的属性,就要用到位图了,在内核中肯定有它对应的位图算法,用来计算最近的没有被使用的比特位,得到这个比特位,经过偏移量的计算,就得到了我需要的inode编号,此时在位图中占据这个空间,紧接着到inode Table中找到刚才的inode编号,向这个位置中写入文件的各种各样的属性,属性就创建好了
对于文件的内容,就需要用到块,和上面类似,也是要找到一个合适的位置,记录它的偏移量,于是这个文件所需要的这个块就有了,之后把hello world这样的内容写到块的内部,这样就把inode编号和块建立起来了对应的关系,再将inode编号返回到上层,这样上层就接收到了这个inode编号,同时操作系统层面就在文件系统中建立起了这样的一套完整的体系
文件的删除
文件的删除需要做什么?需要把块中的内容也全部覆盖掉吗?
其实根本不需要,只需要在位图中把比特位进行修改,这个东西就被删掉了,而文件系统内部到底有没有把东西都删掉?根本不需要,这也就从侧面解释了,为什么用户平时在进行写入新文件的时候相当的慢,但是在进行删除的时候只需要几秒,这就是因为这样的原因,写入信息需要建立一系列复杂的过程和向块中写入信息,而删除只需要把位图更改就可以了
这里简单谈一下数据恢复,所谓数据恢复也和这个原理有关,既然删除只是把位图进行了更改,实际上它内部的信息没有发生改变,那么只要能找到对应的inode编号,就能在文件系统中找到我需要的这个块,进而进行文件修复就可以了,所以,文件丢失后应该做什么呢?答案是什么都不做,因为你的操作可能会导致文件发生了重新写入,当写入的信息把原来块中的信息进行覆盖后,那原来的信息就真正意义上的离你而去了,再也不能进行恢复了,在Linux中有日志等工具会记录删除文件的inode编号,其实也就是防止这样的情况出现,在进行数据恢复的过程就会方便一些
Group Descriptor Table
这个内容简称是GDT,本质上其实是一种数据结构,这样的数据结构就是用来描述块的使用情况,例如会保存inode已经用了多少,还有多少没有被使用等等,总体来说是用来衡量整个块的使用情况的
Super Block
超级块:这个模块比较特殊,并不是每一个块组都有,在超级块中存放的是整个分区的使用情况,包括但不限于有文件系统的类型,有多少个块,数据块的使用情况等等,文件系统中有多个小的磁盘分区,那么操作系统需不需要把这些小的分区里面的信息都管理起来?答案是肯定的,因此在操作系统进行启动的时候,就需要把这些分区都管理起来,如何进行管理,就建立起一张维护他内容的列表,在这个列表中,维护的就是一个结构体对象,然后把整个超级块中的内容都放到内存中
那么达成了什么效果?对整个磁盘的文件系统的管理转换成了在内核中对于若干个超级块的管理
换句话说,超级块中存储的是整个分区的相关信息,并且,由于它管理的区域十分重要,因此在操作系统中会存储多个这样的备份,以备不时之需,当管理总分区的某一个块由于一些意外情况服务挂掉了,此时就会从这些若干个备份超级块中找一个,拷贝到现有的位置上,这样就有利于整个文件系统的稳定性,因此我们说,文件系统是具有一定的稳定性和自我修复能力的
EXT2
在Linux中,把上面的这一套体系称之为EXT2,这套体系是一套可以商用的体系,在这套体系之前的体系都不太适合沿用,而从这套体系之后的部分,都是在这套体系的基础之上,进行的一系列扩展
总结
结合上面的描述过程,对于从操作系统外部拿到整个文件的过程逻辑就可以很清楚的构建出来了:
在一个分区中,只要拿到文件的inode编号,就可以通过查Super block进而找到inode应该落在哪个块组中,紧接着就去查这个分区的GDT,进而去查Bitmap,就能找到inode和对应的数据块内容,这样就又能拿到文件的属性,也能拿到文件的数据,这样就从真正意义上,找到了这个文件
目录的概念
前面说了这么多内容,下一个想讨论的内容是,inode使用场景?对于用户来说,平时也不使用inode,对于用户来说,平时都是使用的文件名,和inode有什么关系呢?
对于用户来说,一般来说是不会使用inode的,所以在操作系统层面上,会对文件名和inode之间建立一层映射关系,而在inode的内部也有inode本身和数据块的一层映射关系,inode有对应的位图,block也有对应的位图,然后就可以进行分配和释放inode和block的内容,映射关系可以始终有紧密的联系,所以最终达成的效果是,只要拥有了inode,就能找到关于文件的所有信息
那么下面就要引入的是关于目录的概念
由于Linux下一切皆文件,那么目录也自然而然的当然是文件,所以上面的这一套文件系统的理论在目录身上也完美使用,所以目录当然是有自己的inode,也有自己的属性,在属性中存储的是各种各样的属性,比如创建时间,拥有者所属组等等一系列信息,但是现在的问题是,既然文件有数据块,那目录自然也有,目录的数据块中存储的是什么信息?
对于一个普通文件来说,数据块中存的是关于这个文件的信息,例如对于视频文件来说,当中存储的就是视频文件的源代码,那对于目录来说,它当中存储的数据块中是什么呢?其实存储的就是文件名和inode之间的映射关系
例如现在有一个main.c程序,它的inode编号是1234,那么在这个目录所在的数据块中存储的就是这两个内容之间的一层映射关系,因此可以得出一个结论,当用户在访问一个文件的时候,只要打开文件所在的目录,根据文件名,就可以在数据块中找到inode编号,就能用上面的那一套逻辑找到这个文件在系统中对应的信息了
目录下不允许存在同名文件
为什么?原因很简单,因为在目录下存在一层文件名到inode编号的一层映射关系,那么这个文件名就是当做key值来使用的,inode编号在整个文件系统中具有唯一性,那么自然文件名也不能重复,它对于inode值要进行一个一一对应的关系
目录也是普通文件
目录和普通文件有区别吗?其实从本质上来说没什么区别,区别就是文件中的数据块存储的是文件本身的内容,而目录的数据块中存储的是文件名到inode的一层映射关系,正是因为它们本质上是一样的,所以在目录中也能进行嵌套目录,可以进行一层一层的嵌套过程,最后达成的效果是,只要打开一个根目录,里面还有一个目录是没有关系的,打开这个目录就能拿到里面文件的文件名和inode之间的映射关系,再从里面进行不断的寻找寻找,直到完成目的,所以就能借助这样的目录结构,形成路径
新建和删除文件
如果想要在目录中新建和删除一个文件,需要做什么呢?为什么在前面的权限中认识到,想要新建删除文件需要目录的写权限呢?原因就在这里,向目录中进行新建和删除,都需要修改目录中文件的一层映射关系,而现在如果没有写的权限,也就意味着不能修改目录文件的数据块中对应的映射信息,这样也就不能新增或者去掉映射信息,也就不能新建和删除了
文件名
inode中没有存储文件名的概念,这意味着,文件名其实并不属于文件的属性,只存储了inode编号,至于文件名的作用,只是在目录中进行匹配inode编号就可以了
如何查找一个文件?
有了上面的概念,现在对于查找要有一个更清楚的认知,现在要找一个文件叫做log,首先要找log文件,就要找到这个文件所在的目录文件,找到文件所在的目录文件,就能从目录文件中找到文件名和inode的映射关系,这样就能拿到inode的值,借助inode的值,可以确定是在哪个分组下,因为存在有start_inode_number这样的数字,可以快速定位到时哪个分组,定位到分组,就可以借助inode Table找表,就能找到inode结构体,于是就能从inode结构体中拿各种各样的属性,内容等等信息,那如何向用户返回信息?
例如用户需要的是文件名,那么就查属性,把文件名拼成一个字符串,返回到上层就可以了,如果用户需要的是文件的内容,那么就根据上面的这层映射关系,找到Data block数据块,把数据块的内容都加载到内存中,用户就能看到这个文件的内容了,这样就是一个整体的概念
但是上面的逻辑有一个问题,那就是借助目录可以找到文件,但是目录该如何进行寻找呢?下面就来补充这个逻辑漏洞
目录是如何被找到的呢
目录中是存在父级目录的,寻找的原理就是借助的是父级目录,可以一层一层的向上寻找,那这样还有止境吗?当然有,Linux中存在根目录,这个就是最终点,然后从根目录中寻找inode编号,然后一层一层向下寻找就可以了!
文件的路径
从上面的逻辑中不难看到,文件的路径就异常关键了,只有有了文件的路径,才能从根目录开始一层一层的借助inode进行跳转和访问的过程,那么下面就要讨论的是关于文件的路径这个信息
文件的路径是谁赋予给文件的呢?
为什么这个文件在创建的时候就会拥有文件路径呢?答案是在进程中有一个叫做pwd的内容,路径是用户给的不如换句话说是进程给的,在每一个进程进行启动时,都会把自己所在的路径记录下来,就是要方便去寻找对应的路径
catch缓存技术
这个词也并不陌生,简单一点说就是最近已经加载过的信息都会被存储到这个缓存中,如果最近还会需要用到这里面存储的内容,就直接从这个里面找就可以了,相当于是一个用来提升访问速度的一种技术,因此我们就有了专业的想法,当我需要频繁的查找一个文件的时候,需要一直进行查找吗?答案是不需要的,当第一次查完这个文件后,它就已经被缓存到这个缓存区中了,第二次就直接到内存中去寻找了,寻找的技术其实有一个叫做dentry的数据结构
dentry
dentry是目录项缓存,是一个存放在内存里的缩略版的磁盘文件系统目录树结构,他是directory entry的缩写。我们知道文件系统内的文件可能非常庞大,目录树结构可能很深,该树状结构中,可能存在几千万,几亿的文件
首先假设不存在dentry这个数据结构,我们看下我们可能会面临什么困境
比如我要打开/usr/bin/vim 文件,
- 首先需要去/所在的inode找到/的数据块,从/的数据块中读取到usr这个条目的inode
- 跳转到user 对应的inode,根据/usr inode 指向的数据块,读取到/usr 目录的内容,从中读取到bin这个条目的inode
- 跳转到/usr/bin/对应的inode,根据/usr/bin/指向的数据块,从中读取到/usr/bin/目录的内容,从里面找到vim的inode
Linux提供了page cache页高速缓存,很多文件的内容已经缓存在内存里,如果没有dentry,文件名无法快速地关联到inode,即使文件的内容已经缓存在页高速缓存,但是每一次不得不重复地从磁盘上找出来文件名到VFS inode的关联。
因此理想情况下,需要将文件系统所有文件名到都记录下来,但是这么做并不现实,首先并不是所有磁盘文件的inode都会纪录在内存中,其次磁盘文件数字可能非常庞大,我们无法简单地建立这种关联,耗尽所有的内存也做不到将文件树结构照搬进内存,而有了dentry的帮助,可以帮助建立关系映射
总结
到此,文件系统就基本结束了,那么在这里做一个小小的总结:
用户在外部点开一个文件,在操作系统的层面上讲,会做了什么???
在此之前,这个文件会在磁盘中待着,等待着有人来调用访问它,现在有人要指定访问这个文件,由冯诺依曼体系可以知道,需要把这个文件加载到内存中供CPU对它进行访问,于是现在就要找到它把它打开。进程拥有自己的cwd工作目录,那么也就意味着根据传入的路径,就能定位到这个路径在磁盘中的哪一个具体的位置,根据路径就能找到它的上级目录,再去对应的分区和分组中访问这个文件的inode结构体中的数据块内容,就能拿到这层映射关系,再进行一层一层的寻找,最终就能达到目的,寻找的所需要的inode,就能把这个inode对应的属性加载到内存中,填充到内存为这个文件建立好的struct file结构体,这样就把文件在内存中描述好了
如果用户需要找到数据块,那么就根据这个文件的信息,找到它的Data block,就能拿到它整体的数据,把数据块加载到缓冲区中,当用户需要读取信息的时候,就把缓冲区中的数据拷贝到应用层,这样在上层,用户就找到了这个内容
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Linux常用命令(二)
- 解决:AttributeError: module ‘scipy.misc’ has no attribute ‘imresize’
- Linux poll 和 select 机制
- zabbix其他配置
- sql查找至少连续出现三次的数字
- 手把手教你用GPT写提示词;进行文献综述;论文翻译/润色及写作
- ts学习,,
- 第18集《佛法修学概要》
- Zabbix监控原理概括
- 【Spring Boot】项目端口号冲突解决方法,一步到位