【办公类-19-02-01】20240119统计班级幼儿姓名的长度、汉字重复、拼音重复(有无声调)Python
发布时间:2024年01月19日
作品展示:

背景需求:
初到中4班,我的首要人物就是记忆幼儿名字。看了一眼点名册,明显感到“王”姓很多。于是总是逮住孩子问:“你叫什么名字?”
“我叫XXX,”
“他是小西瓜”
“我有五个名字!
“我叫小米”
……
于是我想用去年中6班时用过的一个代码,测算一下孩子的“姓“”“名”中的重复频率
?一、准备孩子的EXCEL名册


?二、姓名的字数
了解一下多少孩子是3个名字,多少孩子是2个名字
代码展示
'''
目标:中4班幼儿姓氏与名字的出现频率
作者:阿夏
时间:2024年1月19日'''
from pandas import DataFrame, Series
import pandas as pd
import numpy as np
import xlrd
# 读取列
worksheet = xlrd.open_workbook(r'C:\Users\jg2yXRZ\OneDrive\桌面\中4班分析\中4学生名单.xlsx')
sheet_names= worksheet.sheet_names()
print(sheet_names)
for sheet_name in sheet_names:
sheet = worksheet.sheet_by_name(sheet_name)
rows = sheet.nrows # 获取行数
cols = sheet.ncols # 获取列数,尽管没用到
all_content = []
cols = sheet.col_values(1) # 获取第二列内容, 数据格式为此数据的原有格式(原:字符串,读取:字符串; 原:浮点数, 读取:浮点数)
print(cols)
print(cols[1:]) # 不要第1行的标题的文字
print(type(cols[1])) #查看数据类型
# 名字的长度 3字长度的名字 2字长度的名字
three = []
two=[]
for x in cols[1:]: # 第1行的教职工姓名不要,从1(第二行开始计数)
if len(x)==3: # 如果名字等于3个字
three.append(x)
if len(x)==2: # 如果名字等于2个字
two.append(x)
print(three)
print('3个名字的孩子',len(three),'人\n')
print(two)
print('2个名字的孩子',len(two),'人\n')
# print(b) ["张", "李", "周", "张", "张", "李”]终端显示:

三、姓氏重复率-代码:
'''
目标:中4班幼儿姓氏与名字的出现频率
作者:阿夏
时间:2024年1月19日'''
from pandas import DataFrame, Series
import pandas as pd
import numpy as np
import xlrd
# 读取列
worksheet = xlrd.open_workbook(r'C:\Users\jg2yXRZ\OneDrive\桌面\中4班分析\中4学生名单.xlsx')
sheet_names= worksheet.sheet_names()
print(sheet_names)
for sheet_name in sheet_names:
sheet = worksheet.sheet_by_name(sheet_name)
rows = sheet.nrows # 获取行数
cols = sheet.ncols # 获取列数,尽管没用到
all_content = []
cols = sheet.col_values(1) # 获取第二列内容, 数据格式为此数据的原有格式(原:字符串,读取:字符串; 原:浮点数, 读取:浮点数)
print(cols)
print(cols[1:]) # 不要第1行的标题的文字
print(type(cols[1])) #查看数据类型
# name_list = ["张三", "李四", "周瑜", "张三", "张三", "李四", "王五", "张飞", "张飞", "周瑜"]
#提取第一个姓(目前没有复姓,所以都取第一个姓)
b = []
for i in cols[1:]: # 第1行的教职工姓名不要,从1(第二行开始计数)
a=i[0]
b.append(a)
# print(b) ["张", "李", "周", "张", "张", "李”]
name_dict = {}
for name in b:
# 取出字典中的所有keys值
key_list = name_dict.keys()
# key_list = name_dict[0]
# print(key_list)
if name in key_list:
name_dict[name] += 1
else:
name_dict[name] = 1
# # 根据字典中的value值进行倒序排序
name_dict = sorted(name_dict.items(), key=lambda item:item[1], reverse=True)
print(name_dict )
d=[]
for c in range(0,len(name_dict)):
aa=name_dict[c][0]
bb=name_dict[c][1]
print(aa,bb)
终端显示
虽然只有4个姓氏重复,但是“王”有7人!
我感觉又回到2年前大8班 7个“张”,“5头yang”的记忆恐惧中了
7个王、3个吴、3个周,2个朱,背起来有点绕
四、名字重复率-代码:
计算孩子姓名中的第2个字 第3个字中的汉字重复情况(排除第一个姓氏)
'''
目标:中4班幼儿姓氏与名字的出现频率
作者:阿夏
时间:2024年1月19日'''
from pandas import DataFrame, Series
import pandas as pd
import numpy as np
import xlrd
# 读取列
worksheet = xlrd.open_workbook(r'C:\Users\jg2yXRZ\OneDrive\桌面\中4班分析\中4学生名单.xlsx')
sheet_names= worksheet.sheet_names()
print(sheet_names)
for sheet_name in sheet_names:
sheet = worksheet.sheet_by_name(sheet_name)
rows = sheet.nrows # 获取行数
cols = sheet.ncols # 获取列数,尽管没用到
all_content = []
cols = sheet.col_values(1) # 获取第二列内容, 数据格式为此数据的原有格式(原:字符串,读取:字符串; 原:浮点数, 读取:浮点数)
print(cols)
print(cols[1:]) # 不要第1行的标题的文字
print(type(cols[1])) #查看数据类型
print('--第3类:名字重复(不考虑声调)-------')
# name_list = ["张三", "李四", "周瑜", "张三", "张三", "李四", "王五", "张飞", "张飞", "周瑜"]
#提取第一个姓(目前没有复姓,所以都取第一个姓)
b1 = []
for i1 in cols[1:]: # 第1行的教职工姓名不要,从1(第二行开始计数)
for i2 in i1[1:]:
b1.append(i2)
# print(b) ["张", "李", "周", "张", "张", "李”]
name_dict1 = {}
for name1 in b1:
# 取出字典中的所有keys值
key_list1 = name_dict1.keys()
# key_list = name_dict[0]
# print(key_list)
if name1 in key_list1:
name_dict1[name1] += 1
else:
name_dict1[name1] = 1
# # 根据字典中的value值进行倒序排序
name_dict1 = sorted(name_dict1.items(), key=lambda item:item[1], reverse=True)
print(name_dict )
d1=[]
for c1 in range(0,len(name_dict1)):
aa1=name_dict1[c1][0]
bb1=name_dict1[c1][1]
print(aa1,bb1)幼儿名字(第2-3个字)中的汉字汉字重复率很低,说明孩子的名字都比较独特。

五、重音姓名代码:
除了汉字的辨识,由于幼儿不识字,所以他们会将同音字一组。
【办公类-19-01-03】办公中的思考——Python,统计孩子名字的同音字(拼音)_python寻找全员姓名拼音的共同点-CSDN博客文章浏览阅读574次。【办公类-19-01-03】办公中的思考——Python,统计孩子名字的同音字_python寻找全员姓名拼音的共同点https://blog.csdn.net/reasonsummer/article/details/129627144所以我试试将姓氏转为拼音,分别设计“考虑声调“和“不考虑声调”两种可能性。
(一)姓氏(一个字)拼音的重复率(不考虑声调)
'''
目标:中4班幼儿姓氏与名字的出现频率(拼音声调版)
作者:阿夏
时间:2024年1月19日'''
from pandas import DataFrame, Series
import pandas as pd
import numpy as np
import xlrd
from xpinyin import Pinyin
# 读取姓氏或名字(考虑声调、不考虑声调)
worksheet = xlrd.open_workbook(r'C:\Users\jg2yXRZ\OneDrive\桌面\中4班分析\中4学生名单.xlsx')
sheet_names= worksheet.sheet_names()
print(sheet_names)
for sheet_name in sheet_names:
sheet = worksheet.sheet_by_name(sheet_name)
rows = sheet.nrows # 获取行数
cols = sheet.ncols # 获取列数,尽管没用到
all_content = []
cols = sheet.col_values(1) # 获取第二列内容, 数据格式为此数据的原有格式(原:字符串,读取:字符串; 原:浮点数, 读取:浮点数)
print(cols[1:])
# ['张三', '李四', '王五刘', '朝气吧'……]
print(type(cols[1:])) #查看数据类型 <class 'list'>
listall=[]
for x in cols[1:]:
for y in x[0]:
p = Pinyin()
result1 = p.get_pinyin('{}'.format(y))
print(result1)
listall.append(result1)
print(listall)
# ['zhang', 'san', 'li', 'si', 'wang'……]
name_dict = {}
for name in listall:
# 取出字典中的所有keys值
key_list = name_dict.keys()
# key_list = name_dict[0]
# print(key_list)
if name in key_list:
name_dict[name] += 1
else:
name_dict[name] = 1
# # 根据字典中的value值进行倒序排序
name_dict = sorted(name_dict.items(), key=lambda item:item[1], reverse=True)
print(name_dict )
d=[]
for c in range(0,len(name_dict)):
aa=name_dict[c][0]
bb=name_dict[c][1]
print(aa,bb)

不考虑拼音声调,姓氏出现18个拼音,wang 7 ==王7? wu3=吴3 zhou3=周3,he 2 在汉字里找不到,其实是“贺”“何”的拼音he被计算在一起,出现2次了。后续的拼音都是1,与汉字数量相等
?(二)姓名(2一3个字)拼音的重复率(不考虑声调)
'''
目标:中4班幼儿姓氏与名字的出现频率(拼音声调版)
作者:阿夏
时间:2024年1月19日'''
from pandas import DataFrame, Series
import pandas as pd
import numpy as np
import xlrd
from xpinyin import Pinyin
# 读取姓氏或名字(考虑声调、不考虑声调)
worksheet = xlrd.open_workbook(r'C:\Users\jg2yXRZ\OneDrive\桌面\中4班分析\中4学生名单.xlsx')
sheet_names= worksheet.sheet_names()
print(sheet_names)
for sheet_name in sheet_names:
sheet = worksheet.sheet_by_name(sheet_name)
rows = sheet.nrows # 获取行数
cols = sheet.ncols # 获取列数,尽管没用到
all_content = []
cols = sheet.col_values(1) # 获取第二列内容, 数据格式为此数据的原有格式(原:字符串,读取:字符串; 原:浮点数, 读取:浮点数)
print(cols[1:])
# ['张三', '李四', '王五刘', '朝气吧'……]
print(type(cols[1:])) #查看数据类型 <class 'list'>
listall=[]
for x in cols[1:]:
for y in x[1:]:
p = Pinyin()
result1 = p.get_pinyin('{}'.format(y))
print(result1)
listall.append(result1)
print(listall)
# ['zhang', 'san', 'li', 'si', 'wang'……]
name_dict = {}
for name in listall:
# 取出字典中的所有keys值
key_list = name_dict.keys()
# key_list = name_dict[0]
# print(key_list)
if name in key_list:
name_dict[name] += 1
else:
name_dict[name] = 1
# # 根据字典中的value值进行倒序排序
name_dict = sorted(name_dict.items(), key=lambda item:item[1], reverse=True)
print(name_dict )
d=[]
for c in range(0,len(name_dict)):
aa=name_dict[c][0]
bb=name_dict[c][1]
print(aa,bb)

不考虑拼音声调,名字出现大量的同音字的组合,yi 、ming、yu、qi、xi、xin、ruo、yue、hao、ai、qing、run 都是有同音字的
?(三)姓氏(1个字)拼音的重复率(考虑声调)
from pandas import DataFrame, Series
import pandas as pd
import numpy as np
import xlrd
from xpinyin import Pinyin
# 读取列
worksheet = xlrd.open_workbook(r'C:\Users\jg2yXRZ\OneDrive\桌面\中4班分析\中4学生名单.xlsx')
sheet_names= worksheet.sheet_names()
print(sheet_names)
for sheet_name in sheet_names:
sheet = worksheet.sheet_by_name(sheet_name)
rows = sheet.nrows # 获取行数
cols = sheet.ncols # 获取列数,尽管没用到
all_content = []
cols = sheet.col_values(1) # 获取第二列内容, 数据格式为此数据的原有格式(原:字符串,读取:字符串; 原:浮点数, 读取:浮点数)
print(cols[1:])
# ['张三', '李四', '王五刘', '朝气吧'……]
print(type(cols[1:])) #查看数据类型 <class 'list'>
listall=[]
for x in cols[1:]:
for y in x[0]:
p = Pinyin()
# result1 = p.get_pinyin('{}'.format(y))
result1 = p.get_pinyin('{}'.format(y), tone_marks='marks')
print(result1)
listall.append(result1)
print(listall)
# ['zhang', 'san', 'li', 'si', 'wang'……]
# # 'ye-fu-tian'
# # result2 = p.get_pinyin('叶伏天', tone_marks='marks')
# # 'yè-fú-tiān'
name_dict = {}
for name in listall:
# 取出字典中的所有keys值
key_list = name_dict.keys()
# key_list = name_dict[0]
# print(key_list)
if name in key_list:
name_dict[name] += 1
else:
name_dict[name] = 1
# # 根据字典中的value值进行倒序排序
name_dict = sorted(name_dict.items(), key=lambda item:item[1], reverse=True)
print(name_dict )
d=[]
for c in range(0,len(name_dict)):
aa=name_dict[c][0]
bb=name_dict[c][1]
print(aa,bb)
# zhang 1
?(四)名字(2-3个字)拼音的重复率(考虑声调)
from pandas import DataFrame, Series
import pandas as pd
import numpy as np
import xlrd
from xpinyin import Pinyin
# 读取列
worksheet = xlrd.open_workbook(r'C:\Users\jg2yXRZ\OneDrive\桌面\中4班分析\中4学生名单.xlsx')
sheet_names= worksheet.sheet_names()
print(sheet_names)
for sheet_name in sheet_names:
sheet = worksheet.sheet_by_name(sheet_name)
rows = sheet.nrows # 获取行数
cols = sheet.ncols # 获取列数,尽管没用到
all_content = []
cols = sheet.col_values(1) # 获取第二列内容, 数据格式为此数据的原有格式(原:字符串,读取:字符串; 原:浮点数, 读取:浮点数)
print(cols[1:])
# ['张三', '李四', '王五刘', '朝气吧'……]
print(type(cols[1:])) #查看数据类型 <class 'list'>
listall=[]
for x in cols[1:]:
for y in x[1:]:
p = Pinyin()
# result1 = p.get_pinyin('{}'.format(y))
result1 = p.get_pinyin('{}'.format(y), tone_marks='marks')
print(result1)
listall.append(result1)
print(listall)
# ['zhang', 'san', 'li', 'si', 'wang'……]
# # 'ye-fu-tian'
# # result2 = p.get_pinyin('叶伏天', tone_marks='marks')
# # 'yè-fú-tiān'
name_dict = {}
for name in listall:
# 取出字典中的所有keys值
key_list = name_dict.keys()
# key_list = name_dict[0]
# print(key_list)
if name in key_list:
name_dict[name] += 1
else:
name_dict[name] = 1
# # 根据字典中的value值进行倒序排序
name_dict = sorted(name_dict.items(), key=lambda item:item[1], reverse=True)
print(name_dict )
d=[]
for c in range(0,len(name_dict)):
aa=name_dict[c][0]
bb=name_dict[c][1]
print(aa,bb)
# zhang 1
# san 1
# li 1
# si 1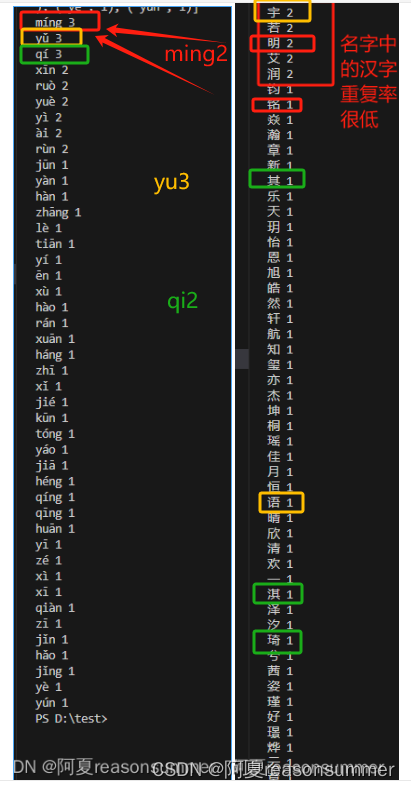
从幼儿的名字部分看,加了拼音声调后,也依旧有ming2、yu3 、qi2出现2-3同音字,虽然他们的汉字外形不同,但是读音声调是相同的。
结语:
运用代码梳理中4班幼儿的姓氏、姓名中的汉字、拼音(读音),主要是为了便于我记忆和区分幼儿的基本信息。还可以利用名字做一次语言类的集体活动,激发幼儿对认识自己及同伴名字(汉字)的兴趣。
文章来源:https://blog.csdn.net/reasonsummer/article/details/135703409
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 预约上门按摩系统开发会涉及哪些关键技术
- 小程序如何设置客服
- 【AIGC】AIGC——真正意义的智能,颠覆性的变革
- 【Android嵌入式开发及实训课程实验】【项目1】 图形界面——计算器项目
- 【已解决】Realtek集成声卡驱动已安装但没有声音,输出设备里只有Realtek Digital Output没有扬声器,扬声器显示未插入
- 乒乓球室计时计费软件,乒乓球馆怎么计时
- centos 防火墙 设置 LTS
- 开始刷Leetcode之前你需要知道的 - The basic is all you need
- PyTorch|构建自己的卷积神经网络——卷积层
- 解析后缀.js、.mjs和.cjs:JavaScript文件类型的区别与使用