大模型日报-20240109
在大模型(LLM)爆发的当下,我们能不能把不同的模型搭建起来,起到 1+1>2 的效果?

https://mp.weixin.qq.com/s/_V228WbPr3WKhBtIs7icZQ
如今的大语言模型(LLM)仿佛一个全能战士,能进行常识和事实推理、懂得世界知识、生成连贯的文本…… 在这些基础功能的底座上,研究者们又进行了一系列努力对这些模型进行微调,以实现特定于领域的功能,如代码生成、文案编辑以及解决数学问题等。但这些特定于领域的模型开始出现一些棘手的问题,例如,有些模型在标准代码生成方面做得很好,但在一般逻辑推理方面并不精通,反之亦然。为了解决上述训练成本和数据带来的挑战,谷歌提出并研究了进行模型组合的实际设置,这些设置包括:(i)研究者可以访问一个或多个增强模型和 anchor 模型,(ii)不允许修改任一模型的权重,并且(iii)只能访问少量数据,这些数据代表了给定模型的组合技能。
顺着网线爬过来成真了,Audio2Photoreal通过对话就能生成逼真表情与动作

https://mp.weixin.qq.com/s/PASA9353xloSqqEME5mEVA
当你和朋友隔着冷冰冰的手机屏幕聊天时,你得猜猜对方的语气。当 Ta 发语音时,你的脑海中还能浮现出 Ta 的表情甚至动作。如果能视频通话显然是最好的,但在实际情况下并不能随时拨打视频。如果你正在与一个远程朋友聊天,不是通过冰冷的屏幕文字,也不是缺乏表情的虚拟形象,而是一个逼真、动态、充满表情的数字化虚拟人。这个虚拟人不仅能够完美地复现你朋友的微笑、眼神,甚至是细微的肢体动作。你会不会感到更加的亲切和温暖呢?真是体现了那一句「我会顺着网线爬过来找你的」。这不是科幻想象,而是在实际中可以实现的技术了。
谷歌图像生成AI掌握多模态指令

https://mp.weixin.qq.com/s/u8qjCihAFZVVnuP82b-MSQ
在使用大型语言模型(LLM)时,我们都已经见证过了指令微调的重要性。如果应用得当,通过指令微调,我们能让 LLM 帮助我们完成各种不同的任务,让其变成诗人、程序员、剧作家、科研助理甚至投资经理。现在,大模型已经进入了多模态时代,指令微调是否依然有效呢?比如我们能否通过多模态指令微调控制图像生成?不同于语言生成,图像生成一开始就涉及到多模态。我们可否有效地让模型掌握多模态的复杂性?为了解决这一难题,Google DeepMind 和 Google Research 提出可将多模态指令方法用于图像生成。该方法可将不同模态的信息交织在一起来表达图像生成的条件。
专补大模型短板的RAG有哪些新进展?这篇综述讲明白了
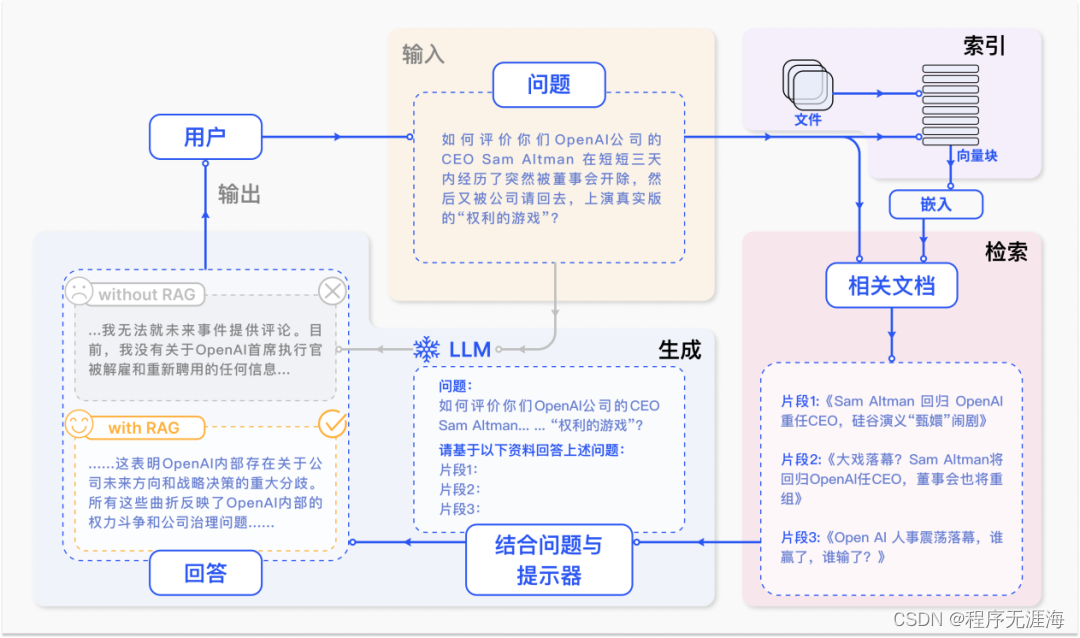
https://mp.weixin.qq.com/s/yZo-HcGuWFQE8B63hZkqVQ
同济大学王昊奋研究员团队联合复旦大学熊赟教授团队发布检索增强生成(RAG)综述,从核心范式,关键技术到未来发展趋势对 RAG 进行了全面梳理。这份工作为研究人员绘制了一幅清晰的 RAG 技术发展蓝图,指出了未来的研究探索方向。同时,为开发者提供了参考,帮助辨识不同技术的优缺点,并指导如何在多样化的应用场景中最有效地利用这些技术。
无需文本标注,TF-T2V把AI量产视频的成本打下来了!华科阿里等联合打造
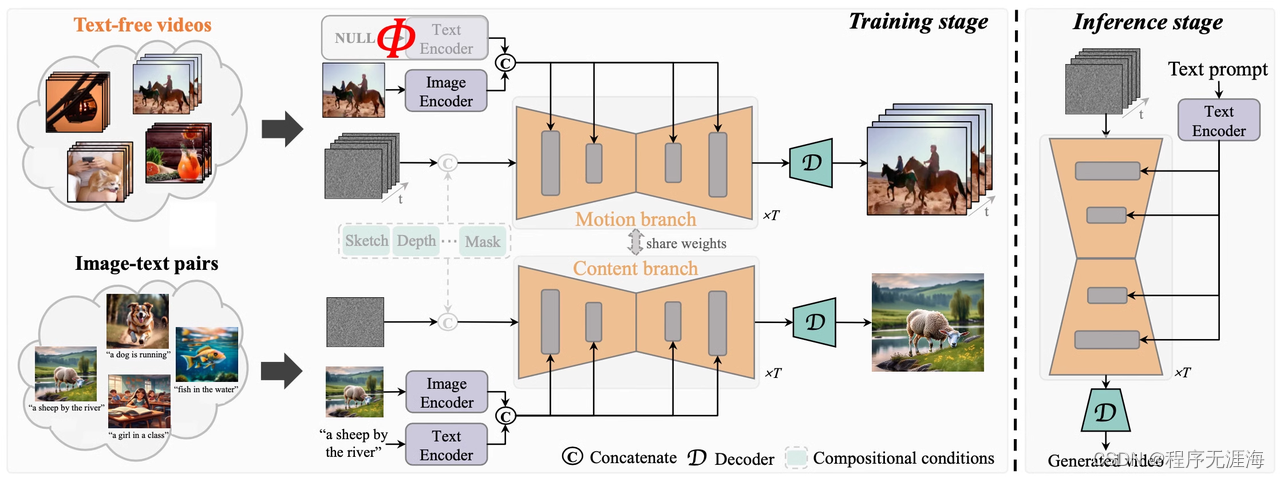
https://mp.weixin.qq.com/s/IQDNnwK4Mikr4s7Qe7Y37A
在过去短短两年内,随着诸如 LAION-5B 等大规模图文数据集的开放,Stable Diffusion、DALL-E 2、ControlNet、Composer ,效果惊人的图片生成方法层出不穷。图片生成领域可谓狂飙突进。然而,与图片生成相比,视频生成仍存在巨大挑战。首先,视频生成需要处理更高维度的数据,考虑额外时间维度带来的时序建模问题,因此需要更多的视频 - 文本对数据来驱动时序动态的学习。然而,对视频进行准确的时序标注非常昂贵。这限制了视频 - 文本数据集的规模,如现有 WebVid10M 视频数据集包含 10.7M 视频 - 文本对,与 LAION-5B 图片数据集在数据规模上相差甚远,严重制约了视频生成模型规模化的扩展。为解决上述问题,华中科技大学、阿里巴巴集团、浙江大学和蚂蚁集团联合研究团队于近期发布了 TF-T2V 视频方案。
语言模型是如何感知时间的?「时间向量」了解一下

https://mp.weixin.qq.com/s/FukJeiDNqI31ETTuuoCkAA
语言模型究竟是如何感知时间的?如何利用语言模型对时间的感知来更好地控制输出甚至了解我们的大脑?最近,来自华盛顿大学和艾伦人工智能研究所的一项研究提供了一些见解。他们的实验结果表明,时间变化在一定程度上被编码在微调模型的权重空间中,并且权重插值可以帮助自定义语言模型以适应新的时间段。
新摩尔时代:2024 LLM 猜想

https://mp.weixin.qq.com/s/s6HQmPXbH_4no9ES3JdEug
未来 5-10 年最重要趋势是什么?ChatGPT 的诞生为这个问题带来了答案,也对未来数字生态带来明确信号:AI 一定是未来技术创新和商业模式变革的核心。关于 LLM 在 2024 年会如何变化,没有人拥有标准答案,唯一可以肯定的是,“新摩尔定律”是不变的:每 1-2 年模型水平就能提升一到两代,模型训练成本每 18个月就会降低至原来的1/4、推理成本每18个月降低至是原来的 1/10。
麻省布里格姆医院:ChatGPT在临床决策中,准确率高达71.7%!
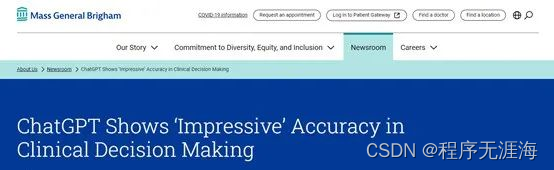
https://mp.weixin.qq.com/s/xKY0wXzHnTx04w_bPFrAHw
美国最大非营利医疗机构之一麻省布里格姆医院发布了,关于ChatGPT在临床医疗决策中应用的研究论文。该医院表示,从提出诊断、推荐诊断检查到最终诊断以及护理管理决策,ChatGPT的准确率为71.7%,在整个临床决策中的表现令人感到惊讶。特别是与初始诊断相比,ChatGPT 在最终诊断任务中表现出了最高的准确率76.9%。
机器人并非全能!斯坦福实验室Zhao发布Aloha失误瞬间
https://x.com/tonyzzhao/status/1743378437174366715?s=20
机器人还没准备好接管世界呢!@zipengfu 和我刚刚剪辑了一段视频,展示了𝐌𝐨𝐛𝐢𝐥𝐞 𝐀𝐋𝐎𝐇𝐀🏄在自动模式下犯的最愚蠢的错误🤣。
我们也计划在休息一段时间后组织一些现场演示。敬请期待!
Matt分享互动式编程体验设计,根据Karpathy‘让我们构建GPT’创造,从零开始构建一个transformer模型

https://x.com/matdmiller/status/1743856339493757262?s=20
在我最新的博客文章中,我尝试根据@karpathy的’让我们构建GPT’,从零开始构建一个transformer模型,利用我从@fastdotai课程中获得的基础知识。想了解transformers是如何工作的吗?可以访问我的博客。这篇文章不只是用来阅读,它被设计成一个互动式编程体验,可以作为Jupyter笔记本下载或直接在GoogleColab中运行。每一个新概念都是在前一个概念的基础上构建的,让你通过实际操作来学习。
Mollick分享“迹象与预兆”:关于未来一年人工智能的一些暗示
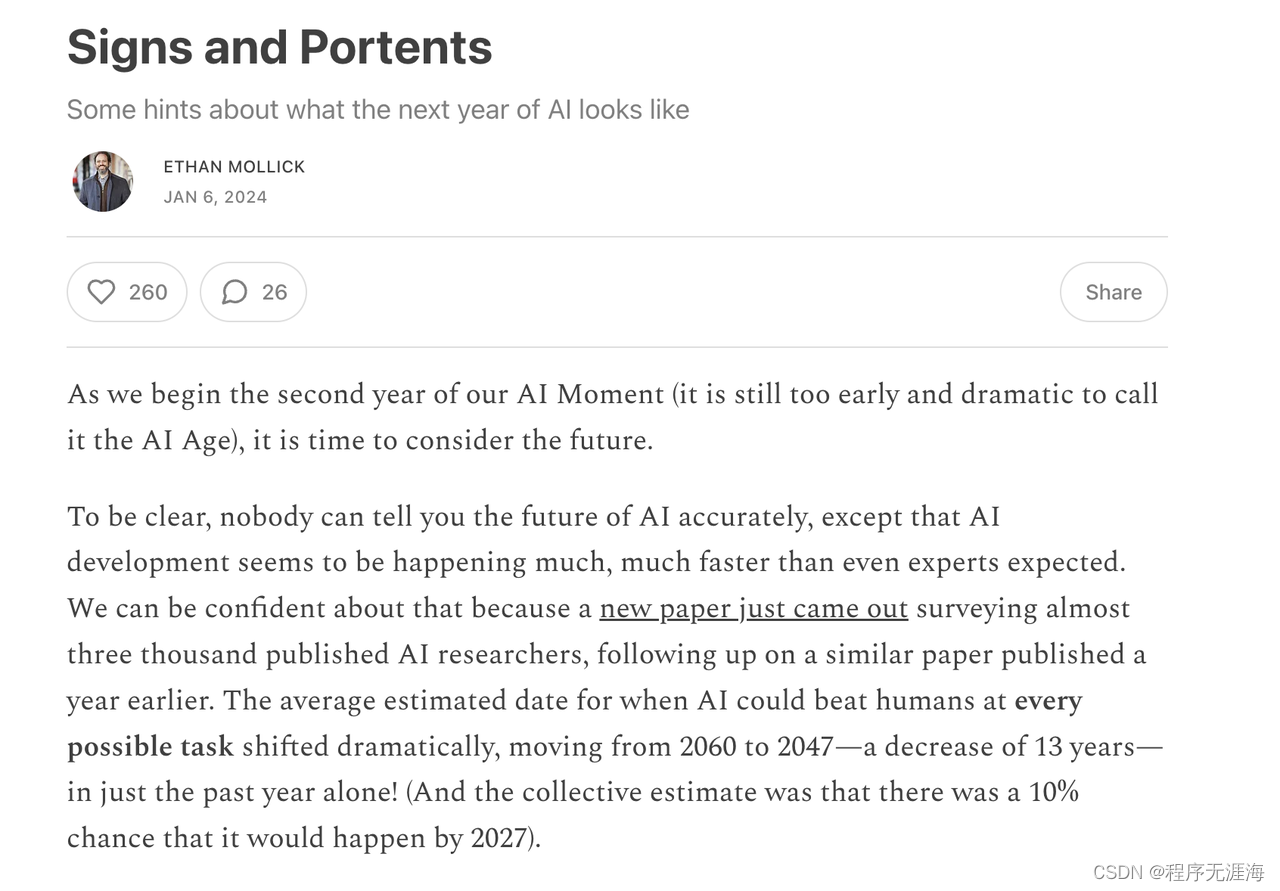
https://x.com/emollick/status/1743667383175139806?s=20
“迹象与预兆”
关于未来一年人工智能的一些暗示
随着我们进入人工智能时刻的第二年(现在称其为人工智能时代还为时过早且太过戏剧化),是时候考虑未来了。
明确的是,没有人能准确告诉你人工智能的未来,除了人工智能的发展似乎比专家们预期的要快得多。我们可以对此感到自信,因为刚刚发布了一篇新论文,调查了近三千名发表过论文的人工智能研究人员,这是继一年前发表的类似论文之后的跟进。平均估计人工智能击败人类在所有可能任务上的日期发生了戏剧性变化,从2060年变为2047年——仅在过去一年内减少了13年!(而且集体估计认为到2027年有10%的可能性发生)。"
Phi-2 允许商用!或成为最好用来微调的模型之一

https://x.com/burkov/status/1743759858539598197?s=20
Phi-2,一款来自@Microsoft的2.7B参数大型语言模型(LLM),现在以MIT许可证发布,允许商业使用。这个模型在大多数基准测试中都超过了最高达13B参数的最强大模型,包括Mistral-7B和Llama 2-13B,尤其是在数学和编码基准测试上。新的MIT许可证使得这个模型成为最好的模型之一(如果不是最好的)来进行微调,以解决规模性商业问题:https://huggingface.co/microsoft/phi-2
PH Deck

https://www.phdeck.com/
专为 Product Hunt 用户量身打造,通过 AI 和 YC 的项目分析方法揭示市场趋势。结合 AI 技术和 YC 见解,为用户突出 Product Hunt 的每日亮点。
Reiki
https://reiki.web3go.xyz/
这是一个专为 AI 时代的创作者和贡献者设计的 AI 原生数字资产平台。使用 Reiki 的 AI 创作工具包、链上所有权证明、AI 代理市场以及蓬勃发展的社区,提供多种货币化方法,将用户的创造力转化为利润。
QAnything
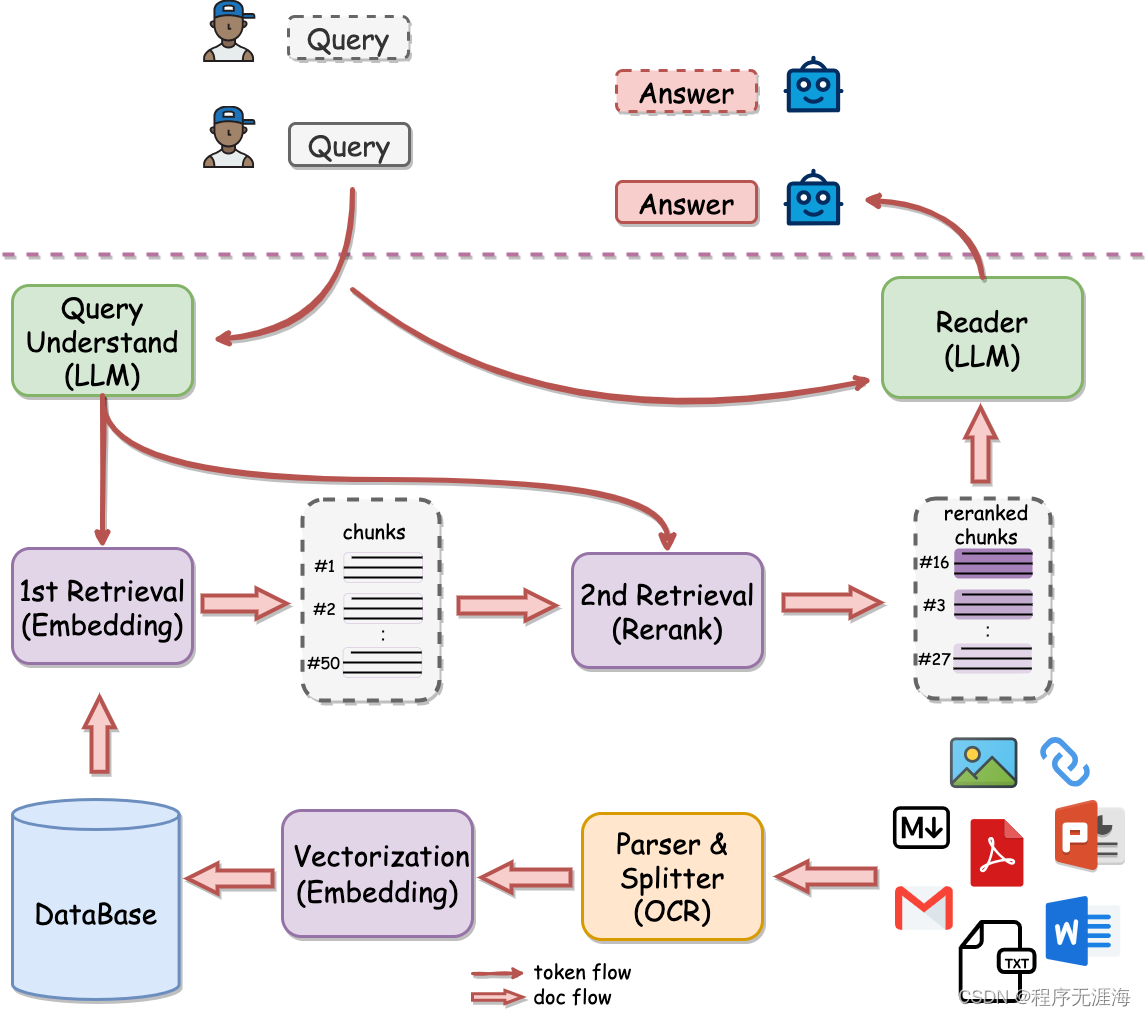
https://github.com/netease-youdao/QAnything
这是一个可以支持任意格式文件或数据库的本地知识库问答系统,可以离线使用。用户的任何格式本地文件都可以往里扔,即可获得准确、快速、靠谱的问答体验。目前已支持格式: PDF,Word(doc/docx),PPT,Markdown,Eml,TXT,图片(jpg,png等),网页链接。
CopilotKit
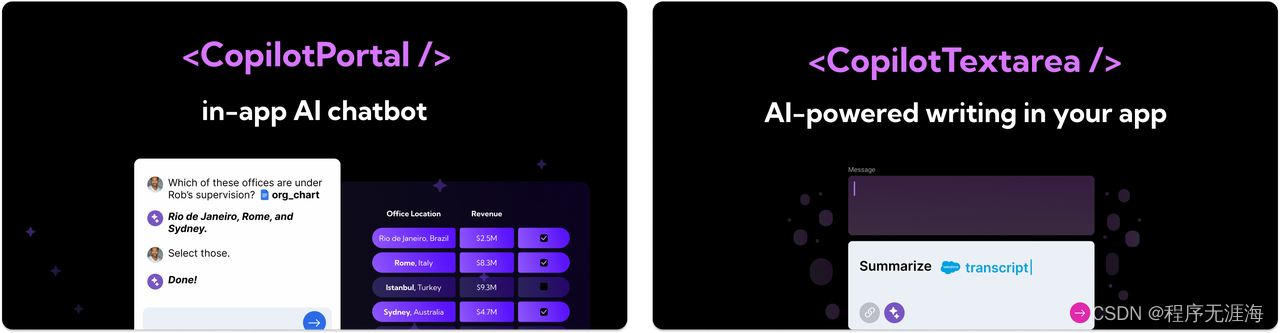
https://github.com/CopilotKit/CopilotKit
帮助用户构建应用内的 AI 聊天机器人,并实现应用中 AI 驱动的文本辅助生成和编辑。
从音频到逼真的具象化:在对话中合成人类形象
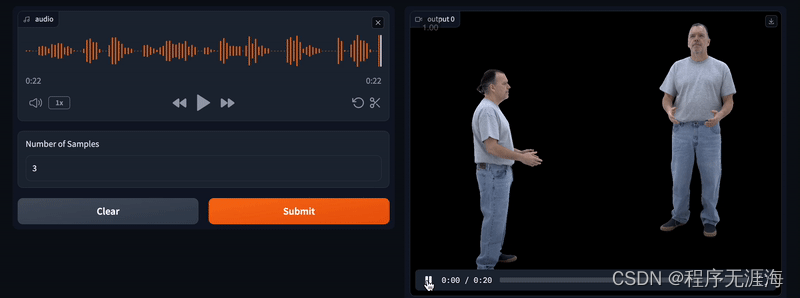
https://github.com/facebookresearch/audio2photoreal?tab=readme-ov-file
这个框架是为了生成更加逼真的全身虚拟形象,这些虚拟形象能根据两人对话的动态来做出手势。简单来说,就是通过分析语音,系统创造出多种可能的手势动作,包括脸部表情、身体动作和手部动作。这个方法的关键在于它结合了两种技术:向量量化(vector quantization)和扩散技术(diffusion)。向量量化可以产生多样的样本,而扩散技术则用于捕捉高频的细节,这样可以生成更加生动、富有表现力的动作。团队用非常逼真的虚拟形象来展示这些动作,这些形象能够表达非常细微的手势变化,比如嘲笑和微笑。为了支持这项研究,还引入了一个全新的、多视角的对话数据集,它允许进行逼真的重建。实验表明,这个模型在生成合适且多样的手势方面,比仅使用扩散或向量量化方法的模型表现得更好。
从传Synopsys收购Ansys聊起:真正的星辰大海
https://mp.weixin.qq.com/s/NTnuGK57Iymz4MVPfmbX9g
文章探讨了Synopsys可能收购Ansys的潜在影响。如果收购成功,Synopsys将成为首家实现从材料到工艺全产品生命周期软件的公司,不仅在芯片领域,还将扩展到能源、化工等工业领域。这将推动工业智能的发展,并可能实现首个工业大模型。此外,收购将完善Synopsys在多物理场和工艺仿真方面的能力,并可能促进材料基因组的商业化。作者认为,国内工业软件公司在技术积累和人才培养方面面临挑战,而这样的收购可能会推动行业标准的发展。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 市政井盖智能管理系统“一盖一码”
- Vue.set 方法原理
- 案例系列:美国人口普查_预测收入超过50K_TabTransformer二分类
- 在若依项目中,如何实现注册一个用户,系统自动为其分配角色
- flutter constraintLayout设置textField高度之后hintText不局中
- 图片编辑软件,图片美化之旅
- 最新能让老外对口型讲中文的AI 视频教程,免费开源AI工具——Wav2Lip
- 【AIOT】 IMU&Pose&Trajectory
- 鸭厂养殖废水处理厂家解决方案
- 防蓝光护眼台灯哪个牌子好?2024护眼灯315合格产品