selenium库的使用
来都来了给我点个赞收藏一下再走呗🌹🌹🌹🌹🌹
目录
6)通过元素的Xpath定位(xpath是一种在XML文档中定位元素的语言)
selenium库使用
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google?Chrome,Opera,Edge等。这个工具的主要功能包括:测试与浏览器的兼容性——测试应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成.Net、Java、Perl等不同语言的测试脚本。
功能:
- 框架底层使javaScript模拟真实用户对浏览器进行操作。测试脚本执行时,浏览器自动按照脚本代码做出点击,输入,打开,验证等操作,就像真实用户所做的一样,从终端用户的角度测试应用程序。
- 使浏览器兼容性测试自动化成为可能,尽管在不同的浏览器上依然有细微的差别。
- 使用简单,可使用Java,pyhton等多种语言编写用例脚本。
一、下载需要用到的python库selenium

pip install selnium下载完毕提示

2.下载你对应要使用的浏览器的驱动
我主要用的浏览器是edge,所以我提供edge的下载官网:Microsoft Edge WebDriver - Microsoft Edge Developer,可能有点慢

看自己的浏览器的版本可以进入设置查看浏览器的版本,如何下载对应版本的驱动

下载完解压,把msedgedriver.exe文件复制到你python3的文件夹下然后再复制一份重命名为MicrosoftWebDriver.exe

二、selenium的基本使用
1.在python代码引入库
from selenium import webdriver2.打开浏览器
browser = webdriver.Edge() //这里我的是edge所以就是用.Edge要是是Chrome 就用.Chrome browser.get("http://www.baidu.com")
3.元素定位
元素定位方法包含了2个系列:
- find_element()系列:用于定位单个的页面元素。
- find_elements()系列:用于定位一组页面元素,获取到的是一组列表。
1)通过id定位
- find_element(By.ID,'XX')id定位,根据元素的id属性值定位,最为方便且唯一,但有可能不存在,也可能动态生成。
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
browser = webdriver.Edge()
browser.get("http://www.baidu.com")
browser.find_element(By.ID,"kw").send_keys("123465")
time.sleep(200)结果:
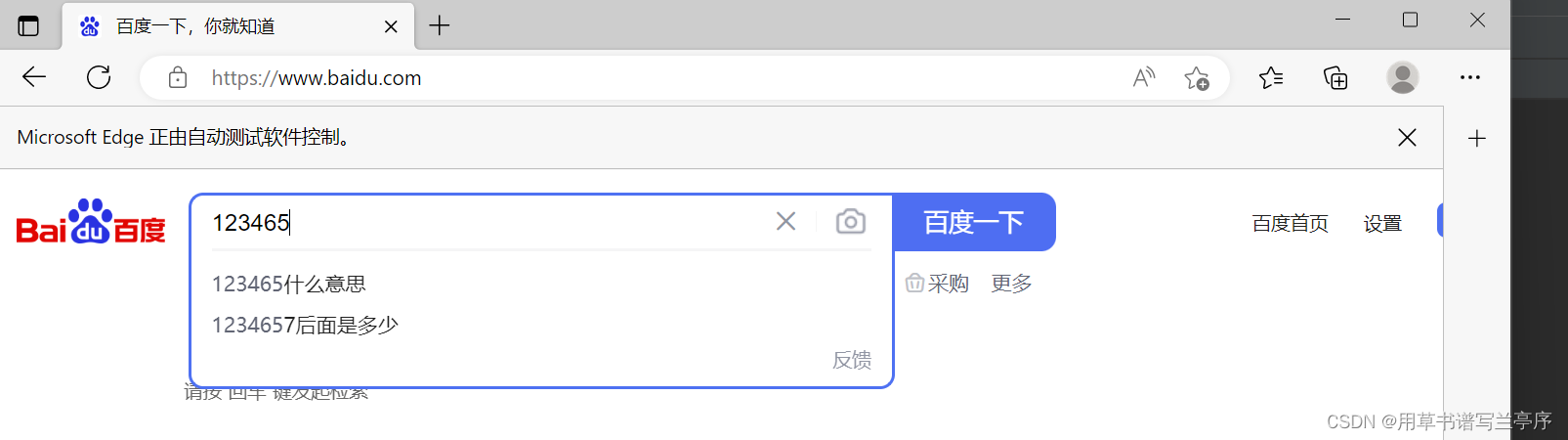
在网页下面圈起来的按钮点击检查查看页面html源代码通过左上角的东西可以选择你要的组件的代码

输入框的源码,可以得到id属性名叫kw

2)通过标签name属性定位
- find_element(By.NAME,'xx')name定位,根据元素的name属性值定位,定位到的标签不一定是唯一的。
import time
# 导入selenium包
from selenium import webdriver
from selenium.webdriver.common.by import By
# 启动并打开指定页面
browser = webdriver.Edge()
browser.get("http://www.baidu.com/")
# 通过name属性选择文本框元素,并设置内容
browser.find_element(By.NAME,'wd').send_keys("selenium")
# 通过通过ID属性获取“百度一下”按钮,并执行点击操作
browser.find_element(By.ID,"su").click()
# 停留五秒后关闭浏览器
time.sleep(5)
browser.quit()3)通过标签class属性定位
- find_element_by(By.CLASS_NAME,'xx')class定位,根据元素的class属性值定位,但可能受JS影响动态变化。定位到的标签不一定是唯一的。
import time
# 导入selenium包
from selenium import webdriver
from selenium.webdriver.common.by import By
# 启动并打开指定页面
browser = webdriver.Edge()
browser.get("http://www.baidu.com/")
time.sleep(2)
# 通过class属性选择元素
browser.find_element(By.CLASS_NAME,'s_ipt').send_keys("CSDN")
time.sleep(2)
browser.find_element(By.ID,"su").click()
# 停留三秒后关闭浏览器
time.sleep(3)
browser.quit()4)通过标签tag定位
- find_element(By.TAG_NAME,'xx')tag name定位,根据元素的标签名定位,定位到的标签不一定是唯一的。
import time
# 导入selenium包
from selenium import webdriver
from selenium.webdriver.common.by import By
# 启动并打开指定页面
browser = webdriver.Edge()
browser.get("http://www.csdn.net")
time.sleep(2)
# 选择<button></button>标签(搜索按钮),执行点击操作
browser.find_element(By.TAG_NAME, "button").click()
# 停留三秒后关闭浏览器
time.sleep(3)
browser.quit()5)通过link定位标签
- link表示包含有属性href的标签元素,如:https://www.csdn.net">linktext可以通过LINK_TEXT进行定位。
- find_element(By.LINK_TEXT,'XX')根据链接文本全匹配进行精确定位。
- find_element(By.PARTIAL_LINK_TEXT,'XX')根据链接文本模糊匹配进行定位。
(1)By.LINK_TEXT精确定位
import time
# 导入selenium包
from selenium import webdriver
from selenium.webdriver.common.by import By
# 启动并打开指定页面
browser = webdriver.Firefox()
browser.get("http://www.csdn.net")
# 选择<a href="https://blog.csdn.net/nav/back-end">Python</a>标签,执行点击操作
browser.find_element(By.LINK_TEXT, "Python").click()
# 停留三秒后关闭浏览器
time.sleep(3)
browser.quit()(2)By.PARTIAL_LINK_TEXT模糊定位
import time
# 导入selenium包
from selenium import webdriver
from selenium.webdriver.common.by import By
# 启动并打开指定页面
browser = webdriver.Firefox()
browser.get("http://www.csdn.net")
# 选择<a href="href="https://blog.csdn.net/nav/ai">人工智能</a>标签,执行点击操作
browser.find_element(By.PARTIAL_LINK_TEXT, "人工").click()
# 停留五秒后关闭浏览器
time.sleep(3)
browser.quit()6)通过元素的Xpath定位(xpath是一种在XML文档中定位元素的语言)
- find_element(By.XPATH,'XX')根据元素的xpath表达式来完成定位,可以准确定位任何元素。
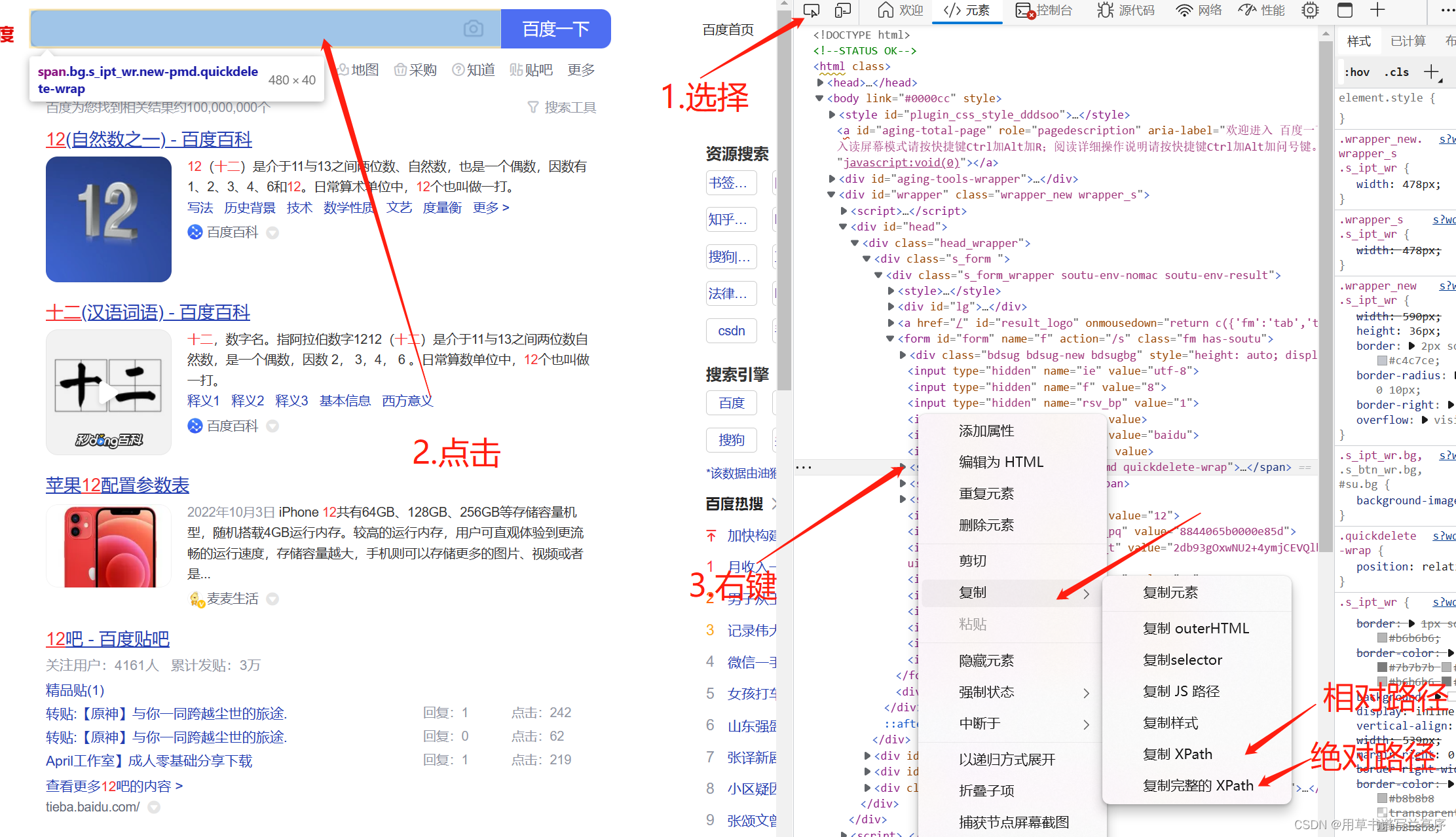
- 使用绝对路径定位
指的是从网页的HTML代码结构的最外层一层层的写到需要被定位的页面元素为止。绝对路径起始于/,每一层都被/所分割。
/html/body/div[2]/form/input[3]
注解: (1)可以用中括号选择分支,div[2]代表的是当前层级下的第二个div标签;
(2)一般情况下较少使用绝对路径的方式做定位,原因在于绝对路径的表达式一般太长,不便于后期的代码维护,代码的微小改变就可能导致这个路径失效,从而无法完成元素定位。
- 使用相对路径定位
不是从根目录写起,而是从网页文本的任意目录开始写。
相对路径起始于//,//所表示的含义是“任意标签下”
//input[@id='kw'] #在当前页面查找任意目录下的input元素,且该元素的id属性取值为kw 注解:
(1)在xpath里,属性以@开头
(2)所选取的属性可以是任意属性,只要其有利于标识这个元素即可
(3)推荐使用相对路径结合属性的这种xpath表达式,它往往更简洁更易于维护
(4)有时候可能会出现一个属性不足以标识某个元素,可以使用逻辑运算符and来连接多个属性进行标识。//input[@xx='aa' and @yy='bb']
(5)有时候一个元素它本身没有可以唯一标识它的属性,这时我们可以找它的上层或者上上层, 然后再往下写。//input[@xx='aa']/p
获取元素的xpath
4.文本输入清除
- send_keys('XXX')文本输入。
- clear()文本清空。
import time
# 导入selenium包
from selenium import webdriver
from selenium.webdriver.common.by import By
# 启动并打开指定页面
browser = webdriver.Edge()
browser.get("http://www.baidu.com/")
# 通过name属性选择文本框元素,并设置内容
input_text=browser.find_element(By.NAME,'wd')
# 输入文本
input_text.send_keys("selenium")
# 停留2秒
time.sleep(2)
# 清空文本
input_text.clear()
# 停留三秒后关闭浏览器
time.sleep(3)
browser.quit()5.获取页面内容
- title页面标题
- page_source?页面源码
- current_url页面连接
- text标签内文本
import time
# 导入selenium包
from selenium import webdriver
from selenium.webdriver.common.by import By
# 启动并打开指定页面
browser = webdriver.Edge()
browser.get("http://www.csdn.net")
# 获取标题
title = browser.title
# 输出
print(title)
# 获取源代码
source_code = browser.page_source
#输出源代码
print(source_code)
# 获取页面链接
url = browser.current_url
#输出页面链接
print(url)
# 获取标签内文本
text = browser.find_element(By.XPATH, '/html/body/div[1]/div/div/div/div[2]/div/div/button/span').text
print(text)
# 关闭页面
time.sleep(3)
browser.quit()6.调整浏览器窗口尺寸
- maximize_window()窗口最大化。
- minimize_window()窗口最小化。
- set_window_size(width,height)调整窗口到指定尺寸
import time
# 导入selenium包
from selenium import webdriver
from selenium.webdriver.common.by import By
# 启动并打开指定页面
browser = webdriver.Edge()
browser.get("http://www.csdn.net")
# 窗口最大化
browser.maximize_window()7.下拉列表操作
- Select("XX)判断标签元素XX是否为下拉列表元素,是返回Select对象,不是报错
- select_by_value("XX")通过下拉列表value属性的值XX选择选项
- select_by_visible_text("XX")通过下拉列表文本内容XX选择选项
- select_by_index(N)或options[N].click()通过下拉列表索引号N选则选项,从0 开始
- options下拉列表内options标签
from time import sleep
# 导入selenium包
from selenium import webdriver
from selenium.webdriver.common.by import By
# 导入Select类
from selenium.webdriver.support.select import Select
# 启动并打开指定页面
browser = webdriver.Edge()
browser.get("file:///C:/Users/admin/Desktop/select.html")
# 定位下拉列表标签,并创建下拉列表对象
select = Select(browser.find_element(By.TAG_NAME, "select"))
# 通过value属性选择选项 <option value="Python">Python</option>
select.select_by_value("Python")
sleep(2)
# 通过文本内容选择选项 <option>C++</option>
select.select_by_visible_text("C++")
sleep(2)
# 通过选项索引号选择选项
select.select_by_index(0) # 等同于 select.options[0].click()
sleep(2)
# 通过options属性循环选取
for i in select.options:
i.click()
sleep(2)
# 关闭浏览器
sleep(3)
browser.quit()本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 武侠世界【源代码+源码手册+客户端+服务端+数据库+编译说明】
- C++ 并发编程 | 锁
- if else else if 的使用及其嵌套
- java中文乱码浅析及解决方案
- 互联网摸鱼日报(2024-01-22)
- uView picker组件多选
- uniapp地图标记点的点击事件
- C语言-数组(一)
- wxbot 对接谷歌gemini gemini-pro和 GeminiProVision 和Bard模型对比,支持长对话
- Python 对象属性和类属性