【Python3】\u字符与中文字串互转
发布时间:2023年12月26日
小水。
encode和decode:
str没有decode函数,但对应的有encode函数,该函数作用是转码为bytes对象bytes通过decode函数转换回对应的str- 对于一些偏激的(可以用过分来形容)的字符串,例如
一二三\\u56db\\u4e94\\u516d,是有相应的解决方法的。至于为什么我用“偏激”来形容,因为正常情况下是不应该出现这种混杂情况的,(出现这种情况多半是哪个煞x忽视字符编码问题直接一股脑字符串连接。
使用str.encode('ascii','backslashreplace')将中文部分全转换为\u字符即可 - 若是出现其他类型的混乱字符串(例如掺杂utf-8编码的中文字串
一二三\\xe5\\x9b\\x9b\\xe4\\xba\\x94\\xe5\\x85\\xad)的话,请先拎清楚到底是哪里造成的问题。这篇博客里不提供对应的解决方法,自己谋生路,写个函数逐字符转换也好,用re正则替换也罢,又或是使用codecs.register_error()注册一个新的编码器,反正能跑就行。
示例代码+运行结果:
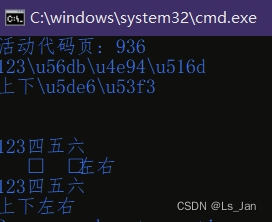
tx1='123\\u56db\\u4e94\\u516d'
tx2='上下\\u5de6\\u53f3'
print(tx1)
print(tx2)
print()
print()
print(tx1.encode().decode("unicode-escape"))#这个encode使用utf-8转码,在遇到非ASCII时直接暴毙
print(tx2.encode().decode("unicode-escape"))#暴毙输出
print(tx1.encode('ascii','backslashreplace').decode('unicode-escape'))#这个encode会无视反斜杠字符的转码,同时对其他非ASCII字符转换为\u字符
print(tx2.encode('ascii','backslashreplace').decode('unicode-escape'))#转换成功
补充:
这里是没有显式提到“中文转\u字符”,
但“中文转\u字符”这操作在上面的示例代码中有出现,
当然,除了str.encode('ascii','backslashreplace')也可以使用str.encode('unicode-escape')进行转换
参考:
str.encode函数参数-backslashreplace: https://www.w3school.com.cn/python/ref_string_encode.aspstr.encode函数参数-codecs.register_error():https://www.runoob.com/python/att-string-encode.htmlcodecs模块:https://cloud.tencent.com/developer/section/1371694
未经本人同意不得私自转载。本文发布于CSDN:https://blog.csdn.net/weixin_44733774/article/details/135211784
文章来源:https://blog.csdn.net/weixin_44733774/article/details/135211784
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 年底总结-基于战略落地的年度经营计划
- Java实现二维码&条形码生成解析
- Linux jinja2模板的使用
- App加固:不同类型和费用对比
- (2023|ICCV,diffusion,transformer,Gflops)使用 Transformer 的可扩展扩散模型
- 服务器带宽有什么用? 带宽不足怎么办?
- 人工智能行业的发展前景如何?
- 一些面试题4
- C++之std::is_object
- java使用jsch处理软链接判断是否文件夹