Informer:用于长序列时间序列预测的高效Transformer模型
????????最近在研究时间序列分析的的过程看,看到一篇精彩的文章,名为:《Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting》,特此撰写一篇博客。
????????文章主要研究了一种用于长序列时间序列预测的高效Transformer模型,称为Informer。这个模型的创新点包括三个主要特性:
-
ProbSparse自注意力机制:这种机制通过实现O(L log L)的时间复杂度和内存使用,有效地解决了传统Transformer模型在处理长序列数据时时间复杂度过高的问题。
-
自注意力蒸馏操作:该操作通过减少每一层的输入量来突出主导的注意力,有效地处理极长的输入序列。
-
生成式风格的解码器:它在预测长时间序列时只需要一步前向操作,而非逐步方式,显著提高了长序列预测的推理速度。
论文中还详细讨论了这些创新如何提高模型在长序列时间序列预测方面的效率和准确性。
????????给出Informer的整体网络架构,如下图:
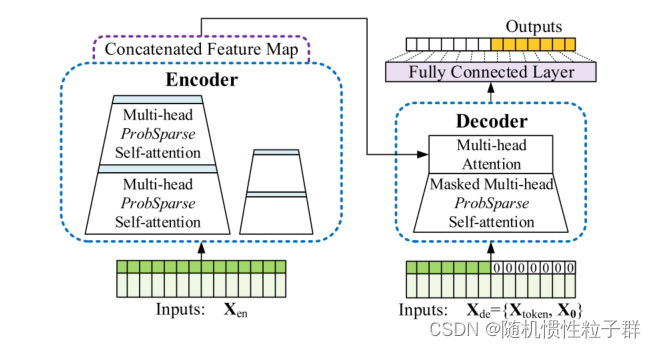
图: Informer模型概述。左图: 编码器接收大量长序列输入(绿色系列)。我们用提出的ProbSparse自注意代替规范自注意。蓝色梯形是自注意力蒸馏操作,提取主导注意力,大幅减小网络规模。层堆叠副本增加了鲁棒性。右图: 解码器接收长序列输入,将目标元素填充为零,测量特征图的加权注意力组成,并以生成方式立即预测输出元素(橙色系列)。
???????Informer的主要改进就是编码和解码器的优化,速度更快,解决长序列问题。
????????给出Informer编码器中的单栈,如下图所示:
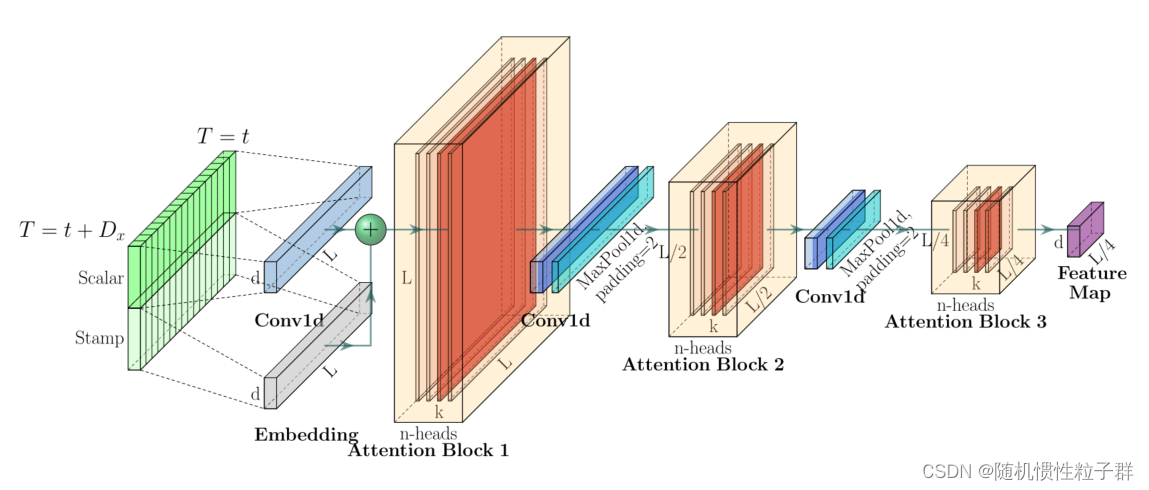
图: Informer编码器中的单个堆栈。(1)水平堆栈代表图(2)中的单个编码器副本之一。(2)本文给出的是接收整个输入序列的主堆栈。然后,第二个堆栈获取输入的一半切片,随后的堆栈重复。(3)红色层为点积矩阵,通过对每一层进行自注意蒸馏得到级联递减。(4)连接所有堆栈的特征映射作为编码器的输出。
????????聚焦于注意力机制方面。ProbSparse自注意力机制,即ProbAttention,是论文《Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting》中提出的一种自注意力机制。这种机制的主要特点和细节如下:
-
主要机制:ProbSparse自注意力允许每个键(key)仅关注最主导的u个查询(query)。这是通过一个稀疏矩阵Q实现的,该矩阵与传统的查询矩阵q大小相同,但只包含根据稀疏性度量M(q, K)选出的Top-u查询。这种自注意力的计算公式是:A(Q, K, V) = Softmax(QK√/d)V,其中A代表注意力函数,Q、K、V分别代表查询、键和值??。
-
采样因子:采样因子c控制了ProbSparse自注意力的信息带宽。在实践中,采样因子通常设置为5。这个因子决定了在每个查询-键查找中需要计算的点积对数量,进而影响模型性能??。
-
时间复杂度和空间复杂度:ProbSparse自注意力机制实现了O(L log L)的时间复杂度和内存使用,这是一个显著改进,因为它比传统Transformer模型中的自注意力机制更加高效。这种效率的提高是通过在长尾分布下随机采样U = LK ln LQ点积对来计算M(qi, K),从而选择稀疏的Top-u作为Q来实现的??。
-
改进的效率:ProbSparse自注意力机制通过减少必须计算的点积对数量,有效地降低了处理长序列时的计算负担。这种机制能够有效地替代传统的自注意力机制,并在长序列依赖对齐上实现了更高的效率和准确性??。
????????总的来说,ProbSparse自注意力机制通过引入稀疏性,大大减少了必须处理的点积对的数量,从而降低了时间和空间复杂度,使得模型在处理长序列数据时更加高效。
下面开始进行源码解读分析:
????????Informer的源码链接:https://github.com/zhouhaoyi/Informer2020
????????下面这段代码是attn.py文件中的源码:
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from math import sqrt
from utils.masking import TriangularCausalMask, ProbMask
class FullAttention(nn.Module):
def __init__(self, mask_flag=True, factor=5, scale=None, attention_dropout=0.1, output_attention=False):
super(FullAttention, self).__init__()
self.scale = scale
self.mask_flag = mask_flag
self.output_attention = output_attention
self.dropout = nn.Dropout(attention_dropout)
def forward(self, queries, keys, values, attn_mask):
B, L, H, E = queries.shape
_, S, _, D = values.shape
scale = self.scale or 1./sqrt(E)
scores = torch.einsum("blhe,bshe->bhls", queries, keys)
if self.mask_flag:
if attn_mask is None:
attn_mask = TriangularCausalMask(B, L, device=queries.device)
scores.masked_fill_(attn_mask.mask, -np.inf)
A = self.dropout(torch.softmax(scale * scores, dim=-1))
V = torch.einsum("bhls,bshd->blhd", A, values)
if self.output_attention:
return (V.contiguous(), A)
else:
return (V.contiguous(), None)
class ProbAttention(nn.Module):
def __init__(self, mask_flag=True, factor=5, scale=None, attention_dropout=0.1, output_attention=False):
super(ProbAttention, self).__init__()
self.factor = factor
self.scale = scale
self.mask_flag = mask_flag
self.output_attention = output_attention
self.dropout = nn.Dropout(attention_dropout)
def _prob_QK(self, Q, K, sample_k, n_top): # n_top: c*ln(L_q)
# Q [B, H, L, D]
B, H, L_K, E = K.shape
_, _, L_Q, _ = Q.shape
# calculate the sampled Q_K
K_expand = K.unsqueeze(-3).expand(B, H, L_Q, L_K, E)
index_sample = torch.randint(L_K, (L_Q, sample_k)) # real U = U_part(factor*ln(L_k))*L_q
K_sample = K_expand[:, :, torch.arange(L_Q).unsqueeze(1), index_sample, :]
Q_K_sample = torch.matmul(Q.unsqueeze(-2), K_sample.transpose(-2, -1)).squeeze(-2)
# find the Top_k query with sparisty measurement
M = Q_K_sample.max(-1)[0] - torch.div(Q_K_sample.sum(-1), L_K) # 96个Q中每一个选跟其他K关系最大的值,再计算与均匀分布的差异
M_top = M.topk(n_top, sorted=False)[1] # 对96个Q的评分中选出25个,返回值1表示要得到索引
# use the reduced Q to calculate Q_K
Q_reduce = Q[torch.arange(B)[:, None, None],
torch.arange(H)[None, :, None],
M_top, :] # factor*ln(L_q) 取出Q的特征
Q_K = torch.matmul(Q_reduce, K.transpose(-2, -1)) # factor*ln(L_q)*L_k 25个Q和全部K之间的关系
return Q_K, M_top
def _get_initial_context(self, V, L_Q):
B, H, L_V, D = V.shape
if not self.mask_flag:
# V_sum = V.sum(dim=-2)
V_sum = V.mean(dim=-2)
contex = V_sum.unsqueeze(-2).expand(B, H, L_Q, V_sum.shape[-1]).clone() # 先把96个V都用均值来替换
else: # use mask
assert(L_Q == L_V) # requires that L_Q == L_V, i.e. for self-attention only
contex = V.cumsum(dim=-2)
return contex
def _update_context(self, context_in, V, scores, index, L_Q, attn_mask):
B, H, L_V, D = V.shape
if self.mask_flag:
attn_mask = ProbMask(B, H, L_Q, index, scores, device=V.device)
scores.masked_fill_(attn_mask.mask, -np.inf)
attn = torch.softmax(scores, dim=-1) # nn.Softmax(dim=-1)(scores)
context_in[torch.arange(B)[:, None, None],
torch.arange(H)[None, :, None],
index, :] = torch.matmul(attn, V).type_as(context_in) # 对25个有Q的更新V,其余的没变还是均值
if self.output_attention:
attns = (torch.ones([B, H, L_V, L_V])/L_V).type_as(attn).to(attn.device)
attns[torch.arange(B)[:, None, None], torch.arange(H)[None, :, None], index, :] = attn
return (context_in, attns)
else:
return (context_in, None)
def forward(self, queries, keys, values, attn_mask):
B, L_Q, H, D = queries.shape
_, L_K, _, _ = keys.shape
queries = queries.transpose(2,1)
keys = keys.transpose(2,1)
values = values.transpose(2,1)
U_part = self.factor * np.ceil(np.log(L_K)).astype('int').item() # c*ln(L_k)
u = self.factor * np.ceil(np.log(L_Q)).astype('int').item() # c*ln(L_q)
U_part = U_part if U_part<L_K else L_K
u = u if u<L_Q else L_Q
scores_top, index = self._prob_QK(queries, keys, sample_k=U_part, n_top=u)
# add scale factor
scale = self.scale or 1./sqrt(D)
if scale is not None:
scores_top = scores_top * scale
# get the context
context = self._get_initial_context(values, L_Q)
# update the context with selected top_k queries
context, attn = self._update_context(context, values, scores_top, index, L_Q, attn_mask)
return context.transpose(2,1).contiguous(), attn
class AttentionLayer(nn.Module):
def __init__(self, attention, d_model, n_heads,
d_keys=None, d_values=None, mix=False):
super(AttentionLayer, self).__init__()
d_keys = d_keys or (d_model//n_heads)
d_values = d_values or (d_model//n_heads)
self.inner_attention = attention
self.query_projection = nn.Linear(d_model, d_keys * n_heads)
self.key_projection = nn.Linear(d_model, d_keys * n_heads)
self.value_projection = nn.Linear(d_model, d_values * n_heads)
self.out_projection = nn.Linear(d_values * n_heads, d_model)
self.n_heads = n_heads
self.mix = mix
def forward(self, queries, keys, values, attn_mask):
B, L, _ = queries.shape
_, S, _ = keys.shape
H = self.n_heads
queries = self.query_projection(queries).view(B, L, H, -1)
keys = self.key_projection(keys).view(B, S, H, -1)
values = self.value_projection(values).view(B, S, H, -1)
out, attn = self.inner_attention(
queries,
keys,
values,
attn_mask
)
if self.mix:
out = out.transpose(2,1).contiguous()
out = out.view(B, L, -1)
return self.out_projection(out), attn
????????下面是ProbAttention的关键部分的解释:
ProbAttention 类
????????ProbAttention 类继承自 nn.Module,是实现ProbSparse自注意力机制的核心。它包括以下几个重要的方法:
-
__init__方法:初始化模块,设置参数,如factor(用于控制采样的密度)、scale(用于缩放注意力分数)和attention_dropout(注意力层的dropout比率)。 -
_prob_QK方法:这个方法是ProbSparse自注意力的核心。它首先对键(K)进行采样,然后计算查询(Q)和采样后的键(K)之间的点积,以获取注意力分数。这个过程通过选择关键的点积对而非所有可能的组合来减少计算量。 -
_get_initial_context方法:计算初始的上下文表示。这个方法根据是否使用掩码(mask_flag)来处理值(V)的累积和或平均值。 -
_update_context方法:使用选择的Top-k注意力分数更新上下文表示。这个方法考虑了概率掩码,并根据注意力分数更新上下文。 -
forward方法:定义了ProbAttention的前向传播逻辑。它包括将查询、键和值转换为适合的形状,计算并应用ProbSparse自注意力,以及更新上下文表示。
注意事项
-
ProbSparse自注意力的关键在于它如何有效减少计算量。通过只计算和选择关键的点积对,这种机制降低了在处理长序列时的计算复杂度。
-
这种方法特别适合长序列预测任务,因为它减轻了传统注意力机制在处理长序列时的计算负担。
-
在移植这部分代码到其他框架时,要确保对应的数据结构和操作符在目标框架中是可用的。
结论
????????代码中的ProbAttention类有效实现了ProbSparse自注意力机制,通过减少必要的计算量,使模型更适合处理长序列数据。在理解和使用这部分代码时,需要关注其如何选择和处理关键的点积对来降低整体计算复杂度。
????????要移植ProbSparse自注意力机制(ProbAttention)到其他框架,要关注以下主要部分代码:
ProbAttention 类的定义
class ProbAttention(nn.Module):
def __init__(self, mask_flag=True, factor=5, scale=None, attention_dropout=0.1, output_attention=False):
super(ProbAttention, self).__init__()
self.factor = factor
self.scale = scale
self.mask_flag = mask_flag
self.output_attention = output_attention
self.dropout = nn.Dropout(attention_dropout)
def _prob_QK(self, Q, K, sample_k, n_top):
# Implementation details...
def _get_initial_context(self, V, L_Q):
# Implementation details...
def _update_context(self, context_in, V, scores, index, L_Q, attn_mask):
# Implementation details...
def forward(self, queries, keys, values, attn_mask):
# Implementation details...
????????此部分包含了ProbAttention类的构造函数(__init__),以及它的私有方法(_prob_QK、_get_initial_context、_update_context)和前向传播方法(forward)。这些方法构成了ProbSparse自注意力机制的核心。
方法实现的关键部分
????????需要将上述方法的实现细节也包含在内。这些实现细节涉及了如何通过采样减少计算的点积对数量,以及如何根据这些采样点更新注意力分数和上下文表示。
注意
????????在移植时,需要注意以下几点:
- 确保您理解了每个方法的工作原理及其在ProbSparse自注意力机制中的作用。
- 检查目标框架是否支持所有必要的操作,例如张量操作和矩阵乘法。
- 考虑到不同框架可能有不同的API和张量操作习惯,因此在移植时可能需要对代码进行适当的调整。
????????在移植过程中,务必保持代码逻辑的一致性,确保新框架中的实现与原始实现在功能上是等效的。
????????下面给出encoder.py文件中的源码:
import torch
import torch.nn as nn
import torch.nn.functional as F
class ConvLayer(nn.Module):
def __init__(self, c_in):
super(ConvLayer, self).__init__()
padding = 1 if torch.__version__>='1.5.0' else 2
self.downConv = nn.Conv1d(in_channels=c_in,
out_channels=c_in,
kernel_size=3,
padding=padding,
padding_mode='circular')
self.norm = nn.BatchNorm1d(c_in)
self.activation = nn.ELU()
self.maxPool = nn.MaxPool1d(kernel_size=3, stride=2, padding=1)
def forward(self, x):
x = self.downConv(x.permute(0, 2, 1))
x = self.norm(x)
x = self.activation(x)
x = self.maxPool(x)
x = x.transpose(1,2)
return x
class EncoderLayer(nn.Module):
def __init__(self, attention, d_model, d_ff=None, dropout=0.1, activation="relu"):
super(EncoderLayer, self).__init__()
d_ff = d_ff or 4*d_model
self.attention = attention
self.conv1 = nn.Conv1d(in_channels=d_model, out_channels=d_ff, kernel_size=1)
self.conv2 = nn.Conv1d(in_channels=d_ff, out_channels=d_model, kernel_size=1)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
self.activation = F.relu if activation == "relu" else F.gelu
def forward(self, x, attn_mask=None):
# x [B, L, D]
# x = x + self.dropout(self.attention(
# x, x, x,
# attn_mask = attn_mask
# ))
new_x, attn = self.attention(
x, x, x,
attn_mask = attn_mask
)
x = x + self.dropout(new_x) # 残差连接
y = x = self.norm1(x)
y = self.dropout(self.activation(self.conv1(y.transpose(-1,1))))
y = self.dropout(self.conv2(y).transpose(-1,1))
return self.norm2(x+y), attn
class Encoder(nn.Module):
def __init__(self, attn_layers, conv_layers=None, norm_layer=None):
super(Encoder, self).__init__()
self.attn_layers = nn.ModuleList(attn_layers)
self.conv_layers = nn.ModuleList(conv_layers) if conv_layers is not None else None
self.norm = norm_layer
def forward(self, x, attn_mask=None):
# x [B, L, D]
attns = []
if self.conv_layers is not None:
for attn_layer, conv_layer in zip(self.attn_layers, self.conv_layers):
x, attn = attn_layer(x, attn_mask=attn_mask)
x = conv_layer(x) # pooling后再减半,还是为了速度考虑
attns.append(attn)
x, attn = self.attn_layers[-1](x, attn_mask=attn_mask)
attns.append(attn)
else:
for attn_layer in self.attn_layers:
x, attn = attn_layer(x, attn_mask=attn_mask)
attns.append(attn)
if self.norm is not None:
x = self.norm(x)
return x, attns
class EncoderStack(nn.Module):
def __init__(self, encoders, inp_lens):
super(EncoderStack, self).__init__()
self.encoders = nn.ModuleList(encoders)
self.inp_lens = inp_lens
def forward(self, x, attn_mask=None):
# x [B, L, D]
x_stack = []; attns = []
for i_len, encoder in zip(self.inp_lens, self.encoders):
inp_len = x.shape[1]//(2**i_len)
x_s, attn = encoder(x[:, -inp_len:, :])
x_stack.append(x_s); attns.append(attn)
x_stack = torch.cat(x_stack, -2)
return x_stack, attns
? ? ? ? 该代码包括了Informer模型中的编码器(Encoder)部分,其中涉及到的关键组件包括ConvLayer、EncoderLayer、Encoder和EncoderStack类。在这些类中,EncoderLayer是实现ProbSparse自注意力机制(ProbAttention)的关键部分。
关键部分分析
-
EncoderLayer 类
EncoderLayer类实现了编码器层的核心功能,其中包括一个自注意力机制(通过attention参数传入),两个卷积层(conv1和conv2),以及层归一化(norm1和norm2)。- 在
forward方法中,首先通过自注意力机制处理输入x,然后进行残差连接、归一化和卷积操作。
-
ProbAttention 的使用
- 在这个代码段中,
ProbAttention被作为EncoderLayer的一个参数(attention),这意味着ProbAttention的具体实现应该在其他地方定义,并在创建EncoderLayer实例时传入。
- 在这个代码段中,
提取 ProbAttention 用于移植
由于该部分代码没有包含ProbAttention类的定义,因此我们无法直接从这个代码段中提取ProbAttention的实现。但是,可以从前面提供的ProbAttention类的实现中获取代码,并将其与EncoderLayer结合使用。
如果您的目标是将ProbAttention移植到另一个框架,您需要确保以下两点:
-
ProbAttention 类的完整实现:包括之前提供的
ProbAttention类的所有方法和内部逻辑。 -
与 EncoderLayer 的集成:确保在目标框架中创建的
EncoderLayer或等效类能够接收并正确使用ProbAttention实例。
注意事项
????????在移植过程中,请确保目标框架支持所有必要的操作,例如张量操作、矩阵乘法、卷积操作等。此外,由于不同框架可能有不同的API和张量操作习惯,可能需要对代码进行一些调整以适应新框架。
????????下面给出decoder.py文件中的源码:
import torch
import torch.nn as nn
import torch.nn.functional as F
class DecoderLayer(nn.Module):
def __init__(self, self_attention, cross_attention, d_model, d_ff=None,
dropout=0.1, activation="relu"):
super(DecoderLayer, self).__init__()
d_ff = d_ff or 4*d_model
self.self_attention = self_attention
self.cross_attention = cross_attention
self.conv1 = nn.Conv1d(in_channels=d_model, out_channels=d_ff, kernel_size=1)
self.conv2 = nn.Conv1d(in_channels=d_ff, out_channels=d_model, kernel_size=1)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
self.activation = F.relu if activation == "relu" else F.gelu
def forward(self, x, cross, x_mask=None, cross_mask=None):
x = x + self.dropout(self.self_attention(
x, x, x,
attn_mask=x_mask
)[0])
x = self.norm1(x)
x = x + self.dropout(self.cross_attention(
x, cross, cross,
attn_mask=cross_mask
)[0])
y = x = self.norm2(x)
y = self.dropout(self.activation(self.conv1(y.transpose(-1,1))))
y = self.dropout(self.conv2(y).transpose(-1,1))
return self.norm3(x+y)
class Decoder(nn.Module):
def __init__(self, layers, norm_layer=None):
super(Decoder, self).__init__()
self.layers = nn.ModuleList(layers)
self.norm = norm_layer
def forward(self, x, cross, x_mask=None, cross_mask=None):
for layer in self.layers:
x = layer(x, cross, x_mask=x_mask, cross_mask=cross_mask)
if self.norm is not None:
x = self.norm(x)
return x该代码包含了Informer模型中的解码器(Decoder)部分,其中涉及到的关键组件包括DecoderLayer和Decoder类。在这些类中,DecoderLayer使用了两种不同的自注意力机制:自注意力(self-attention)和交叉注意力(cross-attention)。
关键部分分析
-
DecoderLayer 类
DecoderLayer类包含两种注意力机制:self_attention和cross_attention。self_attention是在解码器内部使用的,而cross_attention用于在解码器和编码器之间交换信息。- 类还包括两个卷积层(
conv1和conv2)和三个层归一化(norm1、norm2和norm3)。 - 在
forward方法中,先是应用自注意力机制,然后是交叉注意力机制,最后是卷积层和归一化操作。
-
ProbAttention 的使用
- 在提供的代码中,
self_attention和cross_attention可以是任何注意力机制的实例,包括ProbSparse自注意力机制(ProbAttention)。但是,这取决于在创建DecoderLayer实例时传入的具体注意力实例。
- 在提供的代码中,
提取 ProbAttention 用于移植
由于该代码没有包含ProbAttention类的定义,不能从这个代码段中直接提取ProbAttention的实现。然而,如果想在解码器中使用ProbSparse自注意力机制,可以按照以下步骤操作:
-
确保 ProbAttention 类的可用性:从之前的实现中获取
ProbAttention类的代码,确保它在您的环境中是可用的。 -
在 DecoderLayer 中使用 ProbAttention:在创建
DecoderLayer实例时,将ProbAttention实例作为self_attention和/或cross_attention的参数传入。
注意事项
- 在移植过程中,确保目标框架支持所有必要的操作,如张量操作、矩阵乘法、卷积操作等。
- 考虑到不同框架可能有不同的API和张量操作习惯,您可能需要对代码进行一些调整以适应新框架。
- 确保在新框架中
ProbAttention的功能和原始实现保持一致。
通过这种方式,可以将ProbSparse自注意力机制应用于解码器的自注意力和交叉注意力部分,从而在新的框架中复现Informer模型的关键特性。
????????下面给出model.py文件中的源码:
import torch
import torch.nn as nn
import torch.nn.functional as F
from utils.masking import TriangularCausalMask, ProbMask
from models.encoder import Encoder, EncoderLayer, ConvLayer, EncoderStack
from models.decoder import Decoder, DecoderLayer
from models.attn import FullAttention, ProbAttention, AttentionLayer
from models.embed import DataEmbedding
class Informer(nn.Module):
def __init__(self, enc_in, dec_in, c_out, seq_len, label_len, out_len,
factor=5, d_model=512, n_heads=8, e_layers=3, d_layers=2, d_ff=512,
dropout=0.0, attn='prob', embed='fixed', freq='h', activation='gelu',
output_attention = False, distil=True, mix=True,
device=torch.device('cuda:0')):
super(Informer, self).__init__()
self.pred_len = out_len
self.attn = attn
self.output_attention = output_attention
# Encoding
self.enc_embedding = DataEmbedding(enc_in, d_model, embed, freq, dropout)
self.dec_embedding = DataEmbedding(dec_in, d_model, embed, freq, dropout)
# Attention
Attn = ProbAttention if attn=='prob' else FullAttention
# Encoder
self.encoder = Encoder(
[
EncoderLayer(
AttentionLayer(Attn(False, factor, attention_dropout=dropout, output_attention=output_attention),
d_model, n_heads, mix=False),
d_model,
d_ff,
dropout=dropout,
activation=activation
) for l in range(e_layers)
],
[
ConvLayer(
d_model
) for l in range(e_layers-1)
] if distil else None,
norm_layer=torch.nn.LayerNorm(d_model)
)
# Decoder
self.decoder = Decoder(
[
DecoderLayer(
AttentionLayer(Attn(True, factor, attention_dropout=dropout, output_attention=False),
d_model, n_heads, mix=mix),
AttentionLayer(FullAttention(False, factor, attention_dropout=dropout, output_attention=False),
d_model, n_heads, mix=False),
d_model,
d_ff,
dropout=dropout,
activation=activation,
)
for l in range(d_layers)
],
norm_layer=torch.nn.LayerNorm(d_model)
)
# self.end_conv1 = nn.Conv1d(in_channels=label_len+out_len, out_channels=out_len, kernel_size=1, bias=True)
# self.end_conv2 = nn.Conv1d(in_channels=d_model, out_channels=c_out, kernel_size=1, bias=True)
self.projection = nn.Linear(d_model, c_out, bias=True)
def forward(self, x_enc, x_mark_enc, x_dec, x_mark_dec,
enc_self_mask=None, dec_self_mask=None, dec_enc_mask=None):
enc_out = self.enc_embedding(x_enc, x_mark_enc)
enc_out, attns = self.encoder(enc_out, attn_mask=enc_self_mask)
dec_out = self.dec_embedding(x_dec, x_mark_dec)
dec_out = self.decoder(dec_out, enc_out, x_mask=dec_self_mask, cross_mask=dec_enc_mask)
dec_out = self.projection(dec_out)
# dec_out = self.end_conv1(dec_out)
# dec_out = self.end_conv2(dec_out.transpose(2,1)).transpose(1,2)
if self.output_attention:
return dec_out[:,-self.pred_len:,:], attns
else:
return dec_out[:,-self.pred_len:,:] # [B, L, D]
class InformerStack(nn.Module):
def __init__(self, enc_in, dec_in, c_out, seq_len, label_len, out_len,
factor=5, d_model=512, n_heads=8, e_layers=[3,2,1], d_layers=2, d_ff=512,
dropout=0.0, attn='prob', embed='fixed', freq='h', activation='gelu',
output_attention = False, distil=True, mix=True,
device=torch.device('cuda:0')):
super(InformerStack, self).__init__()
self.pred_len = out_len
self.attn = attn
self.output_attention = output_attention
# Encoding
self.enc_embedding = DataEmbedding(enc_in, d_model, embed, freq, dropout)
self.dec_embedding = DataEmbedding(dec_in, d_model, embed, freq, dropout)
# Attention
Attn = ProbAttention if attn=='prob' else FullAttention
# Encoder
inp_lens = list(range(len(e_layers))) # [0,1,2,...] you can customize here
encoders = [
Encoder(
[
EncoderLayer(
AttentionLayer(Attn(False, factor, attention_dropout=dropout, output_attention=output_attention),
d_model, n_heads, mix=False),
d_model,
d_ff,
dropout=dropout,
activation=activation
) for l in range(el)
],
[
ConvLayer(
d_model
) for l in range(el-1)
] if distil else None,
norm_layer=torch.nn.LayerNorm(d_model)
) for el in e_layers]
self.encoder = EncoderStack(encoders, inp_lens)
# Decoder
self.decoder = Decoder(
[
DecoderLayer(
AttentionLayer(Attn(True, factor, attention_dropout=dropout, output_attention=False),
d_model, n_heads, mix=mix),
AttentionLayer(FullAttention(False, factor, attention_dropout=dropout, output_attention=False),
d_model, n_heads, mix=False),
d_model,
d_ff,
dropout=dropout,
activation=activation,
)
for l in range(d_layers)
],
norm_layer=torch.nn.LayerNorm(d_model)
)
# self.end_conv1 = nn.Conv1d(in_channels=label_len+out_len, out_channels=out_len, kernel_size=1, bias=True)
# self.end_conv2 = nn.Conv1d(in_channels=d_model, out_channels=c_out, kernel_size=1, bias=True)
self.projection = nn.Linear(d_model, c_out, bias=True)
def forward(self, x_enc, x_mark_enc, x_dec, x_mark_dec,
enc_self_mask=None, dec_self_mask=None, dec_enc_mask=None):
enc_out = self.enc_embedding(x_enc, x_mark_enc)
enc_out, attns = self.encoder(enc_out, attn_mask=enc_self_mask)
dec_out = self.dec_embedding(x_dec, x_mark_dec)
dec_out = self.decoder(dec_out, enc_out, x_mask=dec_self_mask, cross_mask=dec_enc_mask)
dec_out = self.projection(dec_out)
# dec_out = self.end_conv1(dec_out)
# dec_out = self.end_conv2(dec_out.transpose(2,1)).transpose(1,2)
if self.output_attention:
return dec_out[:,-self.pred_len:,:], attns
else:
return dec_out[:,-self.pred_len:,:] # [B, L, D]
? ? ? ? 该代码是Informer模型的整体架构代码,包括了模型的编码器(Encoder)、解码器(Decoder)和嵌入层(Embedding)。在这个架构中,ProbSparse自注意力机制(ProbAttention)作为一个关键组件被用在编码器和解码器的构建中。
ProbAttention 在 Informer 架构中的使用
-
初始化函数(
__init__):在Informer和InformerStack类中,根据attn参数的值('prob'表示使用ProbAttention,否则使用FullAttention)来初始化注意力机制。 -
编码器和解码器的构建:
- 编码器(
Encoder)和解码器(Decoder)使用EncoderLayer和DecoderLayer,其中包含AttentionLayer。 AttentionLayer使用Attn作为注意力机制,这里Attn根据上述初始化函数中的选择是ProbAttention或FullAttention。
- 编码器(
ProbAttention 的具体实现
虽然该代码中没有直接包含ProbAttention类的实现,但从架构中可以看出,ProbAttention是通过AttentionLayer在EncoderLayer和DecoderLayer中使用的。为了获取ProbAttention的具体实现,您需要查看models.attn模块中的ProbAttention类定义。
提取 ProbAttention 用于移植
-
获取 ProbAttention 类的实现:需要从
models.attn中提取ProbAttention类的实现代码。 -
理解 ProbAttention 的工作机制:了解其如何在输入序列上进行稀疏采样,以及如何计算稀疏自注意力权重。
-
确保与编码器和解码器的兼容性:在将
ProbAttention移植到其他框架时,确保它能与编码器和解码器中的其他组件(如EncoderLayer、DecoderLayer、AttentionLayer)正确集成。
注意事项
在移植ProbAttention时,请确保目标框架支持所有必要的操作,如张量操作、矩阵乘法等。此外,由于不同框架可能有不同的API和数据处理方式,您可能需要对代码进行一定的调整以适应新框架。
总结来说,需要从models.attn中提取ProbAttention类的代码,并确保它能在新框架中与编码器和解码器的其他组件协同工作。
????????最后给出?embed.py?文件中的源码:
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class PositionalEmbedding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEmbedding, self).__init__()
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, d_model).float()
pe.require_grad = False
position = torch.arange(0, max_len).float().unsqueeze(1)
div_term = (torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model)).exp()
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
return self.pe[:, :x.size(1)]
class TokenEmbedding(nn.Module):
def __init__(self, c_in, d_model):
super(TokenEmbedding, self).__init__()
padding = 1 if torch.__version__>='1.5.0' else 2
self.tokenConv = nn.Conv1d(in_channels=c_in, out_channels=d_model,
kernel_size=3, padding=padding, padding_mode='circular')
for m in self.modules():
if isinstance(m, nn.Conv1d):
nn.init.kaiming_normal_(m.weight,mode='fan_in',nonlinearity='leaky_relu')
def forward(self, x):
x = self.tokenConv(x.permute(0, 2, 1)).transpose(1,2)
return x
class FixedEmbedding(nn.Module):
def __init__(self, c_in, d_model):
super(FixedEmbedding, self).__init__()
w = torch.zeros(c_in, d_model).float()
w.require_grad = False
position = torch.arange(0, c_in).float().unsqueeze(1)
div_term = (torch.arange(0, d_model, 2).float() * -(math.log(10000.0) / d_model)).exp()
w[:, 0::2] = torch.sin(position * div_term)
w[:, 1::2] = torch.cos(position * div_term)
self.emb = nn.Embedding(c_in, d_model)
self.emb.weight = nn.Parameter(w, requires_grad=False)
def forward(self, x):
return self.emb(x).detach()
class TemporalEmbedding(nn.Module):
def __init__(self, d_model, embed_type='fixed', freq='h'):
super(TemporalEmbedding, self).__init__()
minute_size = 4; hour_size = 24
weekday_size = 7; day_size = 32; month_size = 13
Embed = FixedEmbedding if embed_type=='fixed' else nn.Embedding
if freq=='t':
self.minute_embed = Embed(minute_size, d_model)
self.hour_embed = Embed(hour_size, d_model)
self.weekday_embed = Embed(weekday_size, d_model)
self.day_embed = Embed(day_size, d_model)
self.month_embed = Embed(month_size, d_model)
def forward(self, x):
x = x.long()
minute_x = self.minute_embed(x[:,:,4]) if hasattr(self, 'minute_embed') else 0.
hour_x = self.hour_embed(x[:,:,3])
weekday_x = self.weekday_embed(x[:,:,2])
day_x = self.day_embed(x[:,:,1])
month_x = self.month_embed(x[:,:,0])
return hour_x + weekday_x + day_x + month_x + minute_x
class TimeFeatureEmbedding(nn.Module):
def __init__(self, d_model, embed_type='timeF', freq='h'):
super(TimeFeatureEmbedding, self).__init__()
freq_map = {'h':4, 't':5, 's':6, 'm':1, 'a':1, 'w':2, 'd':3, 'b':3}
d_inp = freq_map[freq]
self.embed = nn.Linear(d_inp, d_model)
def forward(self, x):
return self.embed(x)
class DataEmbedding(nn.Module):
def __init__(self, c_in, d_model, embed_type='fixed', freq='h', dropout=0.1):
super(DataEmbedding, self).__init__()
self.value_embedding = TokenEmbedding(c_in=c_in, d_model=d_model)
self.position_embedding = PositionalEmbedding(d_model=d_model)
self.temporal_embedding = TemporalEmbedding(d_model=d_model, embed_type=embed_type, freq=freq) if embed_type!='timeF' else TimeFeatureEmbedding(d_model=d_model, embed_type=embed_type, freq=freq)
self.dropout = nn.Dropout(p=dropout)
def forward(self, x, x_mark):
x = self.value_embedding(x) + self.position_embedding(x) + self.temporal_embedding(x_mark)
return self.dropout(x)该代码包括了Informer模型中的数据嵌入部分,主要包含以下几个模块:PositionalEmbedding、TokenEmbedding、FixedEmbedding、TemporalEmbedding、TimeFeatureEmbedding 和 DataEmbedding。这些模块共同构成了模型输入数据的嵌入表示。
关键部分分析
-
PositionalEmbedding
- 用于生成位置嵌入。利用正弦和余弦函数的变化生成每个位置的唯一表示。
-
TokenEmbedding
- 将输入数据的每个特征转换为高维表示。使用一维卷积网络(Conv1d)进行特征提取。
-
FixedEmbedding 和 TemporalEmbedding
- 生成时间相关的嵌入。
FixedEmbedding用于生成固定的时间嵌入,TemporalEmbedding根据输入的时间特征生成动态的时间嵌入。
- 生成时间相关的嵌入。
-
TimeFeatureEmbedding
- 用于处理不同时间频率(如小时、分钟等)的时间特征。
-
DataEmbedding
- 综合
TokenEmbedding、PositionalEmbedding和TemporalEmbedding/TimeFeatureEmbedding,将它们的输出相加以生成最终的嵌入表示。
- 综合
提取 ProbSparse 自注意力机制相关代码
在这部分代码中,没有直接涉及到ProbSparse自注意力机制(ProbAttention)。这些代码主要用于数据的嵌入处理,而不是注意力机制的实现。ProbAttention 通常在模型的编码器(Encoder)和解码器(Decoder)部分使用,特别是在构建注意力层(AttentionLayer)时。
如果想将ProbAttention移植到其他框架,需要关注之前提供的ProbAttention类的实现,并确保在目标框架中的编码器和解码器正确使用它。此外,这部分代码可以帮助您在新框架中准备和处理模型的输入数据。
~~~~~~~~~~~~~~~~~~~~~~~~~~好了,源码的分析到此结束~~~~~~~~~~~~~~~~~~~~~~~~~~
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!