VisualGLM:推理+微调+sat的简单使用
运行的硬件消耗:
- CUDA_VISIBLE_DEVICES=4 python web_demo.py - 显存:15303MiB / 24576MiB
- CUDA_VISIBLE_DEVICES=4 python web_demo.py --share
- CUDA_VISIBLE_DEVICES=4 python web_demo.py --share --quant 4 7731MiB / 24576MiB
VisualGLM,启动 :python web_demo.py
运行
- 可选:如果使用docker
sudo docker run -it --shm-size 8gb --rm --gpus=all -p 8123:8000 -v ${PWD}:/test nvcr.io/nvidia/pytorch:23.02-py3 bash - git clone https://github.com/THUDM/VisualGLM-6B
- cd VisualGLM-6B
- pip install -i https://mirrors.aliyun.com/pypi/simple/ -r requirements.txt
- python web_demo.py
运行过程中出现的问题及处理方法
| ModuleNotFoundError: No module named ‘triton’ | pip install triton |
|---|---|
| OSError: We couldn’t connect to ‘https://huggingface.co’ to load this file, couldn’t find it in the cached files and it looks like THUDM/chatglm-6b is not the path to a directory containing a file named config.json Checkout your internet connection or see how to run the library in offline mode at ‘https://huggingface.co/docs/transformers/installation#offline-mode’. | 手动下载模型,并通过指定路径的方式进行加载 |
| AttributeError: ‘ChatGLMTokenizer’ object has no attribute ‘sp_tokenizer’ | https://github.com/X-D-Lab/LangChain-ChatGLM-Webui/issues/124,reinstall 4.27.1 transformers |
效果
代码
chat
@torch.no_grad()
def chat(self, tokenizer, image_path: str, query: str, history: List[Tuple[str, str]] = None, max_length: int = 1024,
min_length=100, do_sample=True, top_p=0.4, top_k=100, temperature=0.8, repetition_penalty=1.2, logits_processor=None, **kwargs):
# torch.no_grad() 装饰器用于关闭梯度计算,因为在Chat时通常不需要计算梯度。
# 如果没有提供历史记录,初始化为空列表。
if history is None:
history = []
# 如果没有提供 logits_processor,创建一个空的 LogitsProcessorList,并添加一个 InvalidScoreLogitsProcessor。
if logits_processor is None:
logits_processor = LogitsProcessorList()
logits_processor.append(InvalidScoreLogitsProcessor())
# 将生成模型的参数组装成字典。
gen_kwargs = {"max_length": max_length, "min_length": min_length, "do_sample": do_sample, "top_p": top_p,
"top_k": top_k, "temperature": temperature, "repetition_penalty": repetition_penalty,
"logits_processor": logits_processor, **kwargs}
# 使用 build_inputs_with_image 方法构建输入。该方法输入包含图像、文本等信息
inputs = self.build_inputs_with_image(tokenizer, image_path, query, history=history)
# 使用 generate 方法生成对话的输出。
outputs = self.generate(**inputs, **gen_kwargs)
# 从生成的输出中提取模型生成的文本部分。
outputs = outputs.tolist()[0][len(inputs["input_ids"][0]):]
# 将模型生成的文本部分解码为字符串。
response = tokenizer.decode(outputs)
# 对生成的响应进行进一步处理(具体处理方式不在提供的代码中)。
response = self.process_response(response)
# 将查询和生成的响应添加到历史记录中。
history = history + [(query, response)]
# 返回生成的响应和更新后的历史记录。
return response, history
self.generate继承路径:- from transformers.modeling_utils import PreTrainedModel
- class PreTrainedModel(nn.Module, ModuleUtilsMixin, GenerationMixin, PushToHubMixin)
- class GenerationMixin:
图片预处理的方式
from torchvision import transforms
from torchvision.transforms.functional import InterpolationMode
class BlipImageBaseProcessor():
def __init__(self, mean=None, std=None):
if mean is None:
mean = (0.48145466, 0.4578275, 0.40821073)
if std is None:
std = (0.26862954, 0.26130258, 0.27577711)
self.normalize = transforms.Normalize(mean, std)
class BlipImageEvalProcessor(BlipImageBaseProcessor):
def __init__(self, image_size=384, mean=None, std=None):
super().__init__(mean=mean, std=std)
self.transform = transforms.Compose(
[
transforms.Resize(
(image_size, image_size), interpolation=InterpolationMode.BICUBIC
),
transforms.ToTensor(),
self.normalize,
]
)
def __call__(self, item):
return self.transform(item)
def process_dir(image_path):
# from .visual import BlipImageEvalProcessor # /home/ubuntu/.cache/huggingface/modules/transformers_modules/checkpoint/visual.py
from PIL import Image
from io import BytesIO
image = Image.open(image_path)
if image is not None:
processor = BlipImageEvalProcessor(224)
image = processor(image.convert('RGB'))
image = image.unsqueeze(0)
return image
build_inputs_with_image 获取输入数据
def build_inputs_with_image(self, tokenizer, image_path: str, query: str, history: List[Tuple[str, str]] = None):
image_path = image_path.strip()
if image_path:
prompt = "<img>{}</img>".format(image_path)
else:
prompt = ""
for i, (old_query, response) in enumerate(history): # history removes image urls/paths, while query does not.
prompt += "问:{}\n答:{}\n".format(old_query, response)
prompt += "问:{}\n答:".format(query)
prompt, image_position, torch_image = self.process_image(prompt)# 输入prompt='<img>../visglm/VisualGLM-6B-main/PICS/images/Chest X-Ray Case_1.png</img>问:描述这张图片。\n答:' 输出:'<img></img>问:描述这张图片。\n答:',5,[1,3,224,224]
if torch_image is not None:
torch_image = torch_image.to(self.dtype).to(self.device)
input0 = tokenizer.encode(prompt[:image_position], add_special_tokens=False) # 得到[46, 2265, 33]
input1 = [tokenizer.unk_token_id] * self.image_length # [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ...]
input2 = tokenizer.encode(prompt[image_position:], add_special_tokens=False) # [98, 2265, 33, 64286, 12, 67194, 74366, 65842, 63823, 4, 67342, 12]
inputs = sum([input0, input1, input2], []) # [46, 2265, 33, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ...]
inputs = {
"input_ids": torch.tensor([tokenizer.build_inputs_with_special_tokens(inputs)], dtype=torch.long).to(
self.device),
"pre_image_length": len(input0),
"images": torch_image}
else:
inputs = tokenizer([prompt], return_tensors="pt")
inputs = inputs.to(self.device)
inputs["pre_image_length"] = 0
return inputs
{'input_ids': tensor([[ 46, 2265, 33, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 98,
2265, 33, 64286, 12, 67194, 74366, 65842, 63823, 4,
67342, 12, 130001, 130004]], device='cuda:1'), 'pre_image_length': 3, 'images': tensor([[[[1.9307, 1.9307, 1.9307, ..., 1.9307, 1.9307, 1.9307],
[1.9307, 1.9307, 1.9307, ..., 1.9307, 1.9307, 1.9307],
[1.9307, 1.9307, 1.9307, ..., 1.9307, 1.9307, 1.9307],
...,
[1.9307, 1.9307, 1.9307, ..., 1.9307, 1.9307, 1.9307],
[1.9307, 1.9307, 1.9307, ..., 1.9307, 1.9307, 1.9307],
[1.9307, 1.9307, 1.9307, ..., 1.9307, 1.9307, 1.9307]],
[[2.0742, 2.0742, 2.0742, ..., 2.0742, 2.0742, 2.0742],
[2.0742, 2.0742, 2.0742, ..., 2.0742, 2.0742, 2.0742],
[2.0742, 2.0742, 2.0742, ..., 2.0742, 2.0742, 2.0742],
...,
[2.0742, 2.0742, 2.0742, ..., 2.0742, 2.0742, 2.0742],
[2.0742, 2.0742, 2.0742, ..., 2.0742, 2.0742, 2.0742],
[2.0742, 2.0742, 2.0742, ..., 2.0742, 2.0742, 2.0742]],
[[2.1465, 2.1465, 2.1465, ..., 2.1465, 2.1465, 2.1465],
[2.1465, 2.1465, 2.1465, ..., 2.1465, 2.1465, 2.1465],
[2.1465, 2.1465, 2.1465, ..., 2.1465, 2.1465, 2.1465],
...,
[2.1465, 2.1465, 2.1465, ..., 2.1465, 2.1465, 2.1465],
[2.1465, 2.1465, 2.1465, ..., 2.1465, 2.1465, 2.1465],
[2.1465, 2.1465, 2.1465, ..., 2.1465, 2.1465, 2.1465]]]],
device='cuda:1', dtype=torch.float16)}
模型的向前传播outputs = self.generate(**inputs, **gen_kwargs)
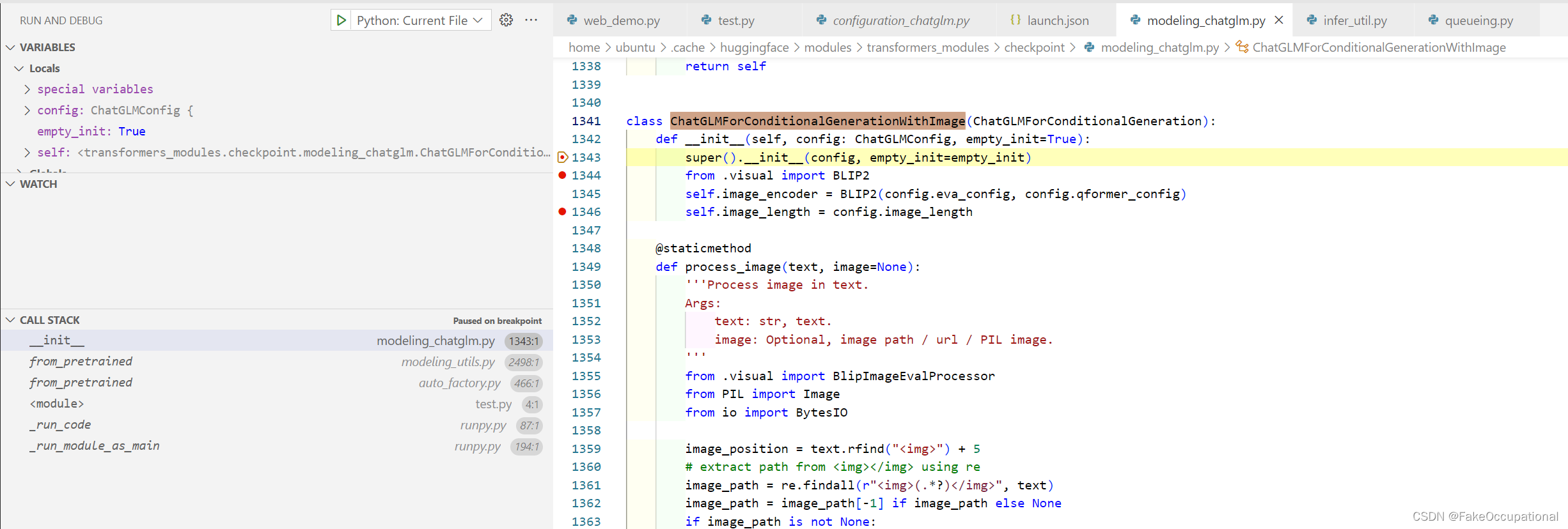
outputs = self.generate(**inputs, **gen_kwargs)会调用forward函数,模型结构如图所示( 图片来自【官方教程】VisualGLM技术讲解:):
# /home/ubuntu/.cache/huggingface/modules/transformers_modules/checkpoint/modeling_chatglm.py
class ChatGLMForConditionalGenerationWithImage(ChatGLMForConditionalGeneration):
def __init__(self, config: ChatGLMConfig, empty_init=True):
super().__init__(config, empty_init=empty_init)
from .visual import BLIP2
self.image_encoder = BLIP2(config.eva_config, config.qformer_config)
self.image_length = config.image_length
def XXXX():
xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
images: Optional[torch.Tensor] = None,
pre_image_length: Optional[int] = None,
past_key_values: Optional[Tuple[torch.FloatTensor]] = None,
inputs_embeds: Optional[torch.Tensor] = None,
labels: Optional[torch.Tensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
):
if inputs_embeds is None and past_key_values is None and images is not None:
image_embeds = self.image_encoder(images) # [1,3,224,224]->[1,32,4096]
pre_id, pads, post_id = torch.tensor_split(input_ids,
[pre_image_length, pre_image_length + self.image_length],
dim=1) # image after [Round 0]\n问:<img>
pre_txt_emb = self.transformer.word_embeddings(pre_id) # [1,3,4096]
post_txt_emb = self.transformer.word_embeddings(post_id) # [1,14,4096]
inputs_embeds = torch.cat([pre_txt_emb, image_embeds, post_txt_emb], dim=1) # [1,49,4096]
return super().forward(
input_ids=input_ids,
position_ids=position_ids,
attention_mask=attention_mask,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
labels=labels,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict
)


m
o
d
e
l
.
i
m
a
g
e
_
e
n
c
o
d
e
r
=
B
L
I
P
2
???????????????????????????????????
=
v
i
t
+
q
f
o
r
m
e
r
+
g
l
m
_
p
r
o
j
e
c
t
model.image\_encoder = BLIP2\\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ = vit +qformer+glm\_project
model.image_encoder=BLIP2???????????????????????????????????=vit+qformer+glm_project
注:模型中有两个mixins,VIT的有参数,qformer的为空。
BLIP2(
(vit): EVAViT(
(mixins): ModuleDict(
(patch_embedding): ImagePatchEmbeddingMixin(
(proj): Conv2d(3, 1408, kernel_size=(14, 14), stride=(14, 14))
)
(pos_embedding): InterpolatedPositionEmbeddingMixin()
(cls): LNFinalyMixin(
(ln_vision): LayerNorm((1408,), eps=1e-05, elementwise_affine=True)
)
)
(transformer): BaseTransformer(
(embedding_dropout): Dropout(p=0.1, inplace=False)
(word_embeddings): Embedding(1, 1408)
(position_embeddings): Embedding(257, 1408)
(layers): ModuleList(
(0): BaseTransformerLayer(
(input_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)
(attention): SelfAttention(
(query_key_value): ColumnParallelLinear()
(attention_dropout): Dropout(p=0.1, inplace=False)
(dense): RowParallelLinear()
(output_dropout): Dropout(p=0.1, inplace=False)
)
(post_attention_layernorm): LayerNorm((1408,), eps=1e-06, elementwise_affine=True)
(mlp): MLP(
(dense_h_to_4h): ColumnParallelLinear()
(dense_4h_to_h): RowParallelLinear()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(1): BaseTransformerLayer(
)
(2): BaseTransformerLayer(
)
(3): BaseTransformerLayer(
)
… …
(38): BaseTransformerLayer(
)
)
)
)
(qformer): QFormer(
(mixins): ModuleDict()
(transformer): BaseTransformer(
(embedding_dropout): Dropout(p=0.1, inplace=False)
(word_embeddings): Embedding(32, 768)
(position_embeddings): None
(layers): ModuleList(
(0): BaseTransformerLayer(
(input_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(attention): SelfAttention(
(query_key_value): ColumnParallelLinear()
(attention_dropout): Dropout(p=0.1, inplace=False)
(dense): RowParallelLinear()
(output_dropout): Dropout(p=0.1, inplace=False)
)
(post_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(cross_attention): CrossAttention(
(query): ColumnParallelLinear()
(key_value): ColumnParallelLinear()
(attention_dropout): Dropout(p=0.1, inplace=False)
(dense): RowParallelLinear()
(output_dropout): Dropout(p=0.1, inplace=False)
)
(post_cross_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(mlp): MLP(
(dense_h_to_4h): ColumnParallelLinear()
(dense_4h_to_h): RowParallelLinear()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(1): BaseTransformerLayer(
(input_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(attention): SelfAttention(
(query_key_value): ColumnParallelLinear()
(attention_dropout): Dropout(p=0.1, inplace=False)
(dense): RowParallelLinear()
(output_dropout): Dropout(p=0.1, inplace=False)
)
(post_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(mlp): MLP(
(dense_h_to_4h): ColumnParallelLinear()
(dense_4h_to_h): RowParallelLinear()
(dropout): Dropout(p=0.1, inplace=False)
)
)
… …
(10): BaseTransformerLayer(
(input_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(attention): SelfAttention(
)
(post_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(cross_attention): CrossAttention(
)
(post_cross_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(mlp): MLP(
)
)
(11): BaseTransformerLayer(
(input_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(attention): SelfAttention(
)
(post_attention_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(mlp): MLP(
)
)
)
(final_layernorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
)
)
(glm_proj): Linear(in_features=768, out_features=4096, bias=True)
)
微调
官方提供的SwissArmyTransformer实现
pip install SwissArmyTransformer // https://pypi.org/project/SwissArmyTransformer/
- unzip fewshot-data.zip
root@f051b80c83eb:/workspace/VisualGLM-6B# ls fewshot-data
2p.png ghost.jpg katong.png man.jpg music.png passport.png pig.png rou.png tianye.png tower.png woman.png
dataset.json justice.png kobe.png meme.png panda.jpg pattern.png push.png rub.png titan.png traf.png
root@f051b80c83eb:/workspace/VisualGLM-6B# cat fewshot-data/dataset.json
[
{"img": "fewshot-data/2p.png", "prompt": "这张图片的背景里有什么内容?", "label": "这张图片的背景是蒙蒙细雨。"},
{"img": "fewshot-data/pig.png", "prompt": "这张图片的背景里有什么内容?", "label": "这张图片的背景是是虚化的。"},
{"img": "fewshot-data/meme.png", "prompt": "这张图片的背景里有什么内容?", "label": "这张图片的背景是蓝色的木质地板。"},
{"img": "fewshot-data/passport.png", "prompt": "这张图片的背景里有什么内容?", "label": "这张图片的背景是棕黄色木质桌子。"},
{"img": "fewshot-data/tower.png", "prompt": "这张图片的背景里有什么内容?", "label": "这张图片的背景是黄昏的天空、云彩和繁华的城市高楼。"},
{"img": "fewshot-data/rub.png", "prompt": "这张图片的背景里有什么内容?", "label": "这张图片的背景是太阳、大树、蓝天白云。"},
{"img": "fewshot-data/push.png", "prompt": "这张图片的背景里有什么内容?", "label": "这张图片的背景是蓝天和沙漠。"},
{"img": "fewshot-data/traf.png", "prompt": "这张图片的背景里有什么内容?", "label": "这张图片的背景是城市街道。"},
- CUDA_VISIBLE_DEVICES=4 bash finetune/finetune_visualglm.sh
- 内存占用:46% 46C P2 346W / 350W| 19839MiB / 24576MiB | 98% Default
- CUDA_VISIBLE_DEVICES=4 bash finetune/finetune_visualglm_qlora.sh
sat的使用例子
????????本段落提供了一个简单且能独立运行的sat模型例子,感觉sat的BaseModel更多还是更关注注意力模型的微调,本段落提供的例子没有很强的逻辑含义,推荐看官方的VIT微调的例子,代码量相对较少。
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import DataLoader, TensorDataset
import os
import torch
import argparse
from sat import mpu, get_args, get_tokenizer
from sat.training.deepspeed_training import training_main
from sat.model.finetune.lora2 import LoraMixin
# class LoraMixin(BaseMixin): # 刚才导入的LoraMixin类定义在https://github1s.com/THUDM/SwissArmyTransformer/blob/main/sat/model/finetune/lora2.py#L169-L189
# def __init__(self,
# layer_num,
# r: int = 0,
# lora_alpha: int = 1,
# lora_dropout: float = 0.,
# layer_range = None,
# qlora = False,
# cross_attention = True):
# super().__init__()
# self.r = r
# self.lora_alpha = lora_alpha
# self.lora_dropout = lora_dropout
# if layer_range is None:
# layer_range = [i for i in range(layer_num)]
# self.layer_range = layer_range
# self.scaling = self.lora_alpha / self.r
# self.qlora = qlora
# self.cross_attention = cross_attention
from sat.model.base_model import BaseMixin, BaseModel
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--model_parallel_size", type=int, default=1)
parser.add_argument("--num_layers", type=int, default=3)
parser.add_argument("--vocab_size", type=int, default=5000)
parser.add_argument("--hidden_size", type=int, default=128)
parser.add_argument("--num_attention_heads", type=int, default=2)
parser.add_argument("--max_sequence_length", type=int, default=1024)
parser.add_argument("--layernorm_order", type=int, default=128)
parser.add_argument("--params_dtype", type=int, default=128)
parser.add_argument("--skip_init", type=bool, default=False)
parser.add_argument("--share", action="store_true")
# self.transformer = BaseTransformer(
# num_layers=args.num_layers,
# vocab_size=args.vocab_size,
# hidden_size=args.hidden_size,
# num_attention_heads=args.num_attention_heads,
# max_sequence_length=args.max_sequence_length,
# layernorm_order=args.layernorm_order,
# **args_dict,
# hooks=self.hooks,
# params_dtype=params_dtype,
# skip_init=args.skip_init,
# device=torch.cuda.current_device() if hasattr(args, 'use_gpu_initialization') and args.use_gpu_initialization else torch.device('cpu'),
# **kwargs
# )
# Namespace(attention_dropout=0.1, batch_from_same_dataset=False, batch_size=4, bf16=False, block_size=10000, checkpoint_activations=False, checkpoint_num_layers=1, checkpoint_skip_layers=0, cuda=True, deepscale=False, deepscale_config=None, deepspeed=True, deepspeed_activation_checkpointing=False, deepspeed_config={'train_micro_batch_size_per_gpu': 4, 'gradient_accumulation_steps': 1, 'gradient_clipping': 0.1, 'fp16': {'enabled': False, 'loss_scale': 0, 'loss_scale_window': 200, 'hysteresis': 2, 'min_loss_scale': 0.01}, 'bf16': {'enabled': False}, 'optimizer': {'type': 'AdamW', 'params': {'lr': 0.0001, 'weight_decay': 0.01}}}, deepspeed_mpi=False, device='cpu', distributed_backend='nccl', drop_path=0.0, epochs=None, eval_batch_size=None, eval_interval=None, eval_iters=100, exit_interval=None, experiment_name='MyModel', fp16=False, gradient_accumulation_steps=1, hidden_dropout=0.1, hidden_size_per_attention_head=None, ignore_pad_token_for_loss=True, inner_hidden_size=None, input_source='interactive', iterable_dataset=False, layer_range=None, layernorm_epsilon=1e-05, length_penalty=0.0, load=None, local_rank=0, log_interval=50, lora_rank=10, lr=0.0001, lr_decay_iters=None, lr_decay_ratio=0.1, lr_decay_style='linear', make_vocab_size_divisible_by=128, master_ip='localhost', master_port='60911', max_inference_batch_size=12, max_source_length=None, max_target_length=None, min_tgt_length=0, mode='pretrain', no_load_rng=False, no_repeat_ngram_size=0, no_save_rng=False, num_beams=1, num_multi_query_heads=0, num_workers=1, out_seq_length=256, output_path='./samples', pre_seq_len=8, prefetch_factor=4, rank=0, resume_dataloader=False, save=None, save_args=False, save_interval=5000, seed=1234, skip_init=False, source_prefix='', split='1000,1,1', strict_eval=False, summary_dir='', temperature=1.0, test_data=None, top_k=0, top_p=0.0, train_data=None, train_data_weights=None, train_iters=10000, use_gpu_initialization=False, use_lora=False, use_ptuning=False, use_qlora=False, valid_data=None, warmup=0.01, weight_decay=0.01, with_id=False, world_size=1, zero_stage=0)
args = parser.parse_args()
# 定义神经网络模型
class SimpleNN(BaseModel):
def __init__(self, input_dim, output_dim):
super().__init__(args=args)
self.fc1 = nn.Linear(input_dim, 2) # 第一个全连接层
self.fc2 = nn.Linear(2, output_dim) # 第二个全连接层
# 如果模型中没有transformer模块,finuting时,Base类会自动添加https://github1s.com/THUDM/SwissArmyTransformer/blob/main/sat/model/base_model.py#L79-L105
def get_position_ids(self, input_ids):
batch_size, seq_length = input_ids.shape
position_ids = torch.arange(seq_length, dtype=torch.long, device=input_ids.device).unsqueeze(0).repeat(batch_size, 1)
return position_ids
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.fc2(x)
# return x
myposition_ids=self.get_position_ids(x)
return super().forward(input_ids=x.long(), attention_mask=None,position_ids=myposition_ids)
class FineTuneModel(SimpleNN):
def __init__(self, input_dim, output_dim):
SimpleNN.__init__(self,input_dim, output_dim)
self.add_mixin("lora", LoraMixin(2, 3), reinit=True)
def disable_untrainable_params(self):
enable = []
enable.extend(['matrix_A', 'matrix_B'])
for n, p in self.named_parameters():
flag = False
for e in enable:
if e.lower() in n.lower():
flag = True
print("can train")
break
if not flag:
p.requires_grad_(False)
# 添加以下方法也会有其他错误,比如AttributeError: 'FineTuneModel' object has no attribute 'mixins',考虑使用多继承
# def add_mixin(self, name, new_mixin, reinit=False):# https://github1s.com/THUDM/SwissArmyTransformer/blob/main/sat/model/base_model.py#L113-L122
# # assert name not in self.mixins
# # assert isinstance(new_mixin, BaseMixin)
# self.mixins[name] = new_mixin # will auto-register parameters
# object.__setattr__(new_mixin, 'transformer', self.transformer) # cannot use pytorch set_attr
# self.collect_hooks_()
# if reinit:
# new_mixin.reinit(self) # also pass current mixins
# 生成一些示例数据
# 这里使用随机生成的数据,实际应用中需要替换为自己的数据集
b =25
num_samples = 100
input_dim = 100
output_dim = 100
input_data = torch.randn(num_samples, input_dim)*num_samples
target_data = torch.randn(num_samples,input_dim,5000)
# 创建神经网络实例
model = FineTuneModel(input_dim, output_dim)
model.disable_untrainable_params()
# 将数据转换为 DataLoader
dataset = TensorDataset(input_data, target_data)
dataloader = DataLoader(dataset, batch_size=b, shuffle=True)
# 定义损失函数和优化器
criterion = nn.MSELoss() # 使用均方误差损失
optimizer = optim.SGD(model.parameters(), lr=0.0001) # 随机梯度下降优化器
# 训练模型
num_epochs = 10
for epoch in range(num_epochs):
for inputs, targets in dataloader:
optimizer.zero_grad() # 梯度清零
outputs = model(inputs)[0] # 正向传播
loss = criterion(outputs, targets) # 计算损失
loss.backward() # 反向传播
optimizer.step() # 更新参数
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
print("当前的模型结构为:",model)
# 输出为:
# [2024-01-12 15:16:11,319] [INFO] [real_accelerator.py:161:get_accelerator] Setting ds_accelerator to cuda (auto detect)
# /home/ubuntu/anaconda3/envs/visglm/lib/python3.8/site-packages/huggingface_hub/utils/_runtime.py:184: UserWarning: Pydantic is installed but cannot be imported. Please check your installation. `huggingface_hub` will default to not using Pydantic. Error message: '{e}'
# warnings.warn(
# [2024-01-12 15:16:13,486] [WARNING] Failed to load bitsandbytes:No module named 'bitsandbytes'
# [2024-01-12 15:16:13,884] [INFO] [RANK 0] > initializing model parallel with size 1
# [2024-01-12 15:16:13,885] [INFO] [RANK 0] You didn't pass in LOCAL_WORLD_SIZE environment variable. We use the guessed LOCAL_WORLD_SIZE=1. If this is wrong, please pass the LOCAL_WORLD_SIZE manually.
# [2024-01-12 15:16:13,885] [INFO] [RANK 0] You are using model-only mode.
# For torch.distributed users or loading model parallel models, set environment variables RANK, WORLD_SIZE and LOCAL_RANK.
# [2024-01-12 15:16:13,901] [INFO] [RANK 0] replacing layer 0 attention with lora
# [2024-01-12 15:16:13,907] [INFO] [RANK 0] replacing layer 1 attention with lora
# can train
# can train
# can train
# can train
# can train
# can train
# can train
# can train
# can train
# can train
# can train
# can train
# can train
# can train
# can train
# can train
# Epoch [1/10], Loss: 1.0508
# Epoch [2/10], Loss: 1.0510
# Epoch [3/10], Loss: 1.0507
# Epoch [4/10], Loss: 1.0512
# Epoch [5/10], Loss: 1.0517
# Epoch [6/10], Loss: 1.0510
# Epoch [7/10], Loss: 1.0510
# Epoch [8/10], Loss: 1.0512
# Epoch [9/10], Loss: 1.0508
# Epoch [10/10], Loss: 1.0508
# 当前的模型结构为: FineTuneModel(
# (mixins): ModuleDict(
# (lora): LoraMixin()
# )
# (transformer): BaseTransformer(
# (embedding_dropout): Dropout(p=0, inplace=False)
# (word_embeddings): VocabParallelEmbedding()
# (position_embeddings): Embedding(1024, 128)
# (layers): ModuleList(
# (0): BaseTransformerLayer(
# (input_layernorm): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
# (attention): SelfAttention(
# (query_key_value): LoraLinear(
# (original): HackColumnParallelLinear()
# (matrix_A): HackParameterList(
# (0): Parameter containing: [torch.FloatTensor of size 3x128]
# (1): Parameter containing: [torch.FloatTensor of size 3x128]
# (2): Parameter containing: [torch.FloatTensor of size 3x128]
# )
# (matrix_B): HackParameterList(
# (0): Parameter containing: [torch.FloatTensor of size 128x3]
# (1): Parameter containing: [torch.FloatTensor of size 128x3]
# (2): Parameter containing: [torch.FloatTensor of size 128x3]
# )
# )
# (attention_dropout): Dropout(p=0, inplace=False)
# (dense): LoraLinear(
# (original): HackRowParallelLinear()
# (matrix_A): HackParameterList( (0): Parameter containing: [torch.FloatTensor of size 3x128])
# (matrix_B): HackParameterList( (0): Parameter containing: [torch.FloatTensor of size 128x3])
# )
# (output_dropout): Dropout(p=0, inplace=False)
# )
# (post_attention_layernorm): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
# (mlp): MLP(
# (dense_h_to_4h): ColumnParallelLinear()
# (dense_4h_to_h): RowParallelLinear()
# (dropout): Dropout(p=0, inplace=False)
# )
# )
# (1): BaseTransformerLayer(
# (input_layernorm): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
# (attention): SelfAttention(
# (query_key_value): LoraLinear(
# (original): HackColumnParallelLinear()
# (matrix_A): HackParameterList(
# (0): Parameter containing: [torch.FloatTensor of size 3x128]
# (1): Parameter containing: [torch.FloatTensor of size 3x128]
# (2): Parameter containing: [torch.FloatTensor of size 3x128]
# )
# (matrix_B): HackParameterList(
# (0): Parameter containing: [torch.FloatTensor of size 128x3]
# (1): Parameter containing: [torch.FloatTensor of size 128x3]
# (2): Parameter containing: [torch.FloatTensor of size 128x3]
# )
# )
# (attention_dropout): Dropout(p=0, inplace=False)
# (dense): LoraLinear(
# (original): HackRowParallelLinear()
# (matrix_A): HackParameterList( (0): Parameter containing: [torch.FloatTensor of size 3x128])
# (matrix_B): HackParameterList( (0): Parameter containing: [torch.FloatTensor of size 128x3])
# )
# (output_dropout): Dropout(p=0, inplace=False)
# )
# (post_attention_layernorm): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
# (mlp): MLP(
# (dense_h_to_4h): ColumnParallelLinear()
# (dense_4h_to_h): RowParallelLinear()
# (dropout): Dropout(p=0, inplace=False)
# )
# )
# (2): BaseTransformerLayer(
# (input_layernorm): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
# (attention): SelfAttention(
# (query_key_value): ColumnParallelLinear()
# (attention_dropout): Dropout(p=0, inplace=False)
# (dense): RowParallelLinear()
# (output_dropout): Dropout(p=0, inplace=False)
# )
# (post_attention_layernorm): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
# (mlp): MLP(
# (dense_h_to_4h): ColumnParallelLinear()
# (dense_4h_to_h): RowParallelLinear()
# (dropout): Dropout(p=0, inplace=False)
# )
# )
# )
# (final_layernorm): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
# )
# (fc1): Linear(in_features=100, out_features=2, bias=True)
# (fc2): Linear(in_features=2, out_features=100, bias=True)
# )
- 模型输出的其他部分(除00外)为不同层的transforemer的输出。
peft微调方法
peft的学习
- 一篇富有洞察力的博文解释了使用 PEFT 微调 FlanT5-XXL 的优势: https://www.philschmid.de/fine-tune-flan-t5-peft
# install Hugging Face Libraries
!pip install "peft==0.2.0"
!pip install "transformers==4.27.2" "datasets==2.9.0" "accelerate==0.17.1" "evaluate==0.4.0" "bitsandbytes==0.37.1" loralib --upgrade --quiet
# install additional dependencies needed for training
!pip install rouge-score tensorboard py7zr
# 从peft模块导入必要的函数和类
from peft import LoraConfig, get_peft_model, prepare_model_for_int8_training, TaskType
# 定义LoRA配置
# 创建具有特定参数的LoRA配置
lora_config = LoraConfig(
r=16, # 低秩适应(Low-Rank Adaptation)的秩参数
lora_alpha=32, # α参数,平衡loar和原始输出
target_modules=["q", "v"], # 低秩适应的目标模块
lora_dropout=0.05, # LoRA的dropout率
bias="none", # LoRA的偏置类型
task_type=TaskType.SEQ_2_SEQ_LM # LoRA的任务类型,在此为序列到序列语言建模(比如T5),这个还是比较重要的参数
)
# 为训练准备int-8模型,括号中的参数model为需要微调的预训练模型
# 修改模型或其配置,以使用降低的精度(INT8)进行训练
model = prepare_model_for_int8_training(model)
# 添加LoRA适配器到模型
# 使用指定的LoRA配置将低秩适应添加到模型中
model = get_peft_model(model, lora_config)
# 打印有关可训练参数的信息
# 输出可训练参数的数量、总参数数量以及可训练参数的百分比
model.print_trainable_parameters()
# 输出
# trainable params: 18874368 || all params: 11154206720 || trainable%: 0.16921300163961817
# 模型的定义到此为止,后边就能加载数据进行训练了
// TaskType定义在https://github1s.com/huggingface/peft/blob/HEAD/src/peft/utils/peft_types.py#L38-L46
class TaskType(str, enum.Enum):
"""Enum class for the different types of tasks supported by PEFT."""
SEQ_CLS = "SEQ_CLS"
SEQ_2_SEQ_LM = "SEQ_2_SEQ_LM"
CAUSAL_LM = "CAUSAL_LM"
TOKEN_CLS = "TOKEN_CLS"
QUESTION_ANS = "QUESTION_ANS"
FEATURE_EXTRACTION = "FEATURE_EXTRACTION"
使用peft进行visualglm微调可参考https://github.com/mymusise/ChatGLM-Tuning/blob/master/finetune.py
- 以下的代码为ChatGLM的微调,如果对visualglm进行微调可能需要参考peft的底层api。
// https://github.com/mymusise/ChatGLM-Tuning/blob/master/finetune.py
from transformers.integrations import TensorBoardCallback
from torch.utils.tensorboard import SummaryWriter
from transformers import TrainingArguments
from transformers import Trainer, HfArgumentParser
from transformers import AutoTokenizer, AutoModel
from transformers import PreTrainedTokenizerBase
import torch
import torch.nn as nn
from peft import get_peft_model, LoraConfig, TaskType
from dataclasses import dataclass, field
import datasets
import os
@dataclass
class FinetuneArguments:
dataset_path: str = field(default="data/alpaca")
model_path: str = field(default="output")
lora_rank: int = field(default=8)
chatglm_path: str = field(default="model_path/chatglm")
class CastOutputToFloat(nn.Sequential):
def forward(self, x):
return super().forward(x).to(torch.float32)
@dataclass
class DataCollator:
tokenizer: PreTrainedTokenizerBase
def __call__(self, features: list) -> dict:
len_ids = [len(feature["input_ids"]) for feature in features]
longest = max(len_ids)
input_ids = []
labels_list = []
for ids_l, feature in sorted(zip(len_ids, features), key=lambda x: -x[0]):
ids = feature["input_ids"]
seq_len = feature["seq_len"]
labels = (
[-100] * (seq_len - 1)
+ ids[(seq_len - 1) :]
+ [-100] * (longest - ids_l)
)
ids = ids + [self.tokenizer.pad_token_id] * (longest - ids_l)
_ids = torch.LongTensor(ids)
labels_list.append(torch.LongTensor(labels))
input_ids.append(_ids)
input_ids = torch.stack(input_ids)
labels = torch.stack(labels_list)
return {
"input_ids": input_ids,
"labels": labels,
}
class ModifiedTrainer(Trainer):
def compute_loss(self, model, inputs, return_outputs=False):
return model(
input_ids=inputs["input_ids"],
labels=inputs["labels"],
).loss
def save_model(self, output_dir=None, _internal_call=False):
from transformers.trainer import TRAINING_ARGS_NAME
os.makedirs(output_dir, exist_ok=True)
torch.save(self.args, os.path.join(output_dir, TRAINING_ARGS_NAME))
saved_params = {
k: v.to("cpu") for k, v in self.model.named_parameters() if v.requires_grad
}
torch.save(saved_params, os.path.join(output_dir, "adapter_model.bin"))
def main():
writer = SummaryWriter()
finetune_args, training_args = HfArgumentParser(
(FinetuneArguments, TrainingArguments)
).parse_args_into_dataclasses()
# init model
model = AutoModel.from_pretrained(
finetune_args.chatglm_path,
load_in_8bit=True,
trust_remote_code=True,
device_map="auto",
)
tokenizer = AutoTokenizer.from_pretrained(
finetune_args.chatglm_path, trust_remote_code=True
)
model.gradient_checkpointing_enable()
model.enable_input_require_grads()
model.is_parallelizable = True
model.model_parallel = True
# model.lm_head = CastOutputToFloat(model.lm_head)
model.config.use_cache = (
False # silence the warnings. Please re-enable for inference!
)
# setup peft
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
r=finetune_args.lora_rank,
lora_alpha=32,
lora_dropout=0.1,
)
model = get_peft_model(model, peft_config)
# load dataset
dataset = datasets.load_from_disk(finetune_args.dataset_path)
print(f"\n{len(dataset)=}\n")
# start train
trainer = ModifiedTrainer(
model=model,
train_dataset=dataset,
args=training_args,
callbacks=[TensorBoardCallback(writer)],
data_collator=DataCollator(tokenizer),
)
trainer.train()
writer.close()
# save model
model.save_pretrained(training_args.output_dir)
if __name__ == "__main__":
main()
参考与更多
VisualGLMgithub地址
https://github.com/microsoft/LoRA
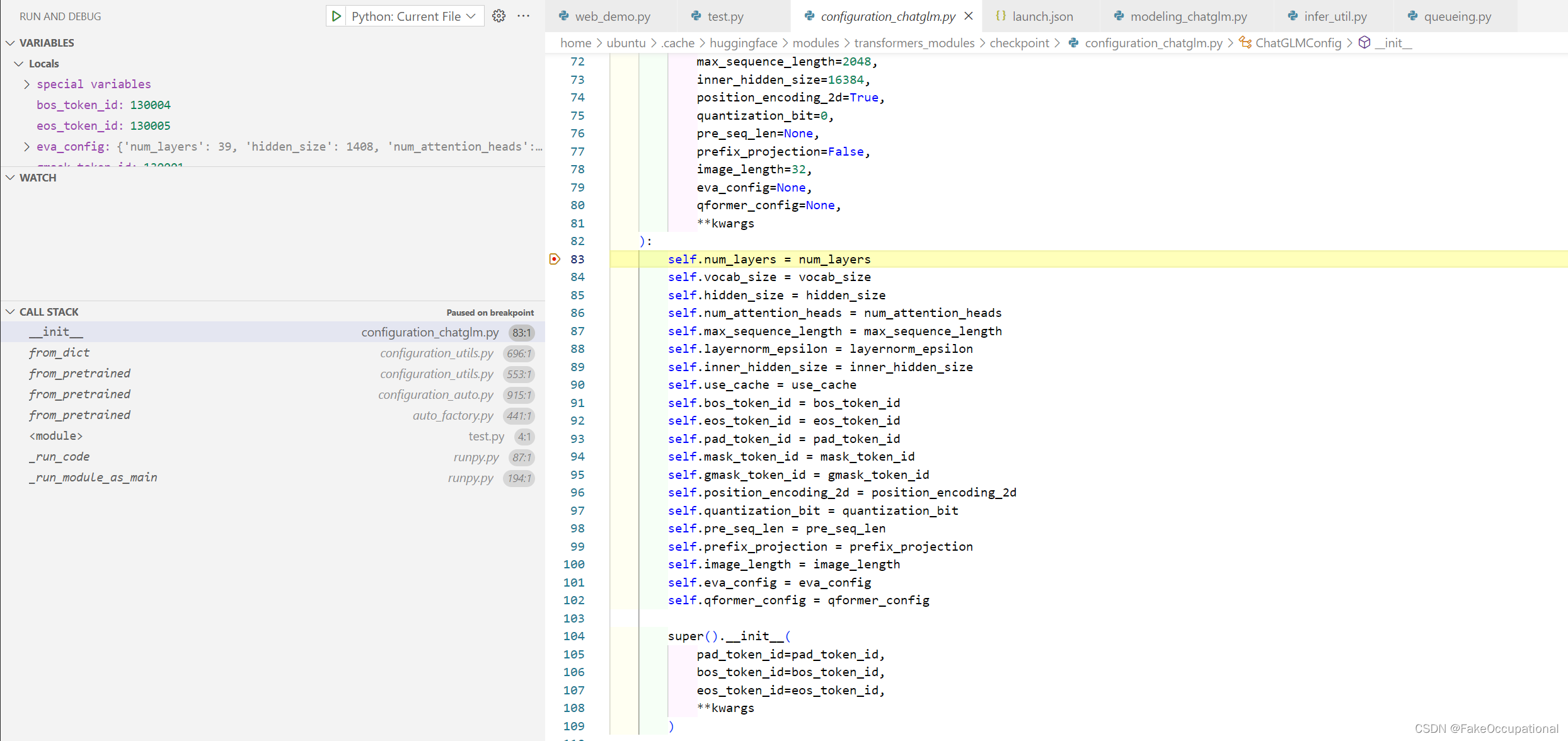
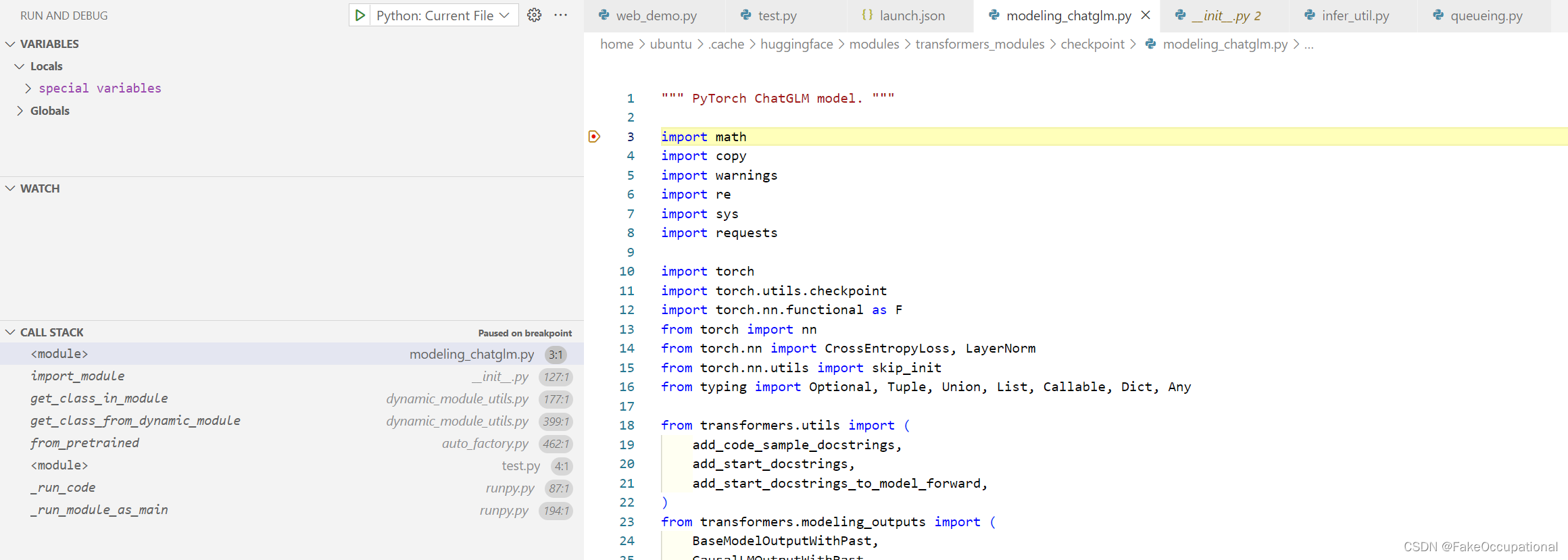
AutoModel.from_pretrained的加载过程
大模型可视化 https://bbycroft.net/llm
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!