SQL-分组查询

?🎉欢迎您来到我的MySQL基础复习专栏
☆* o(≧▽≦)o *☆哈喽~我是小小恶斯法克🍹
?博客主页:小小恶斯法克的博客
🎈该系列文章专栏:重拾MySQL
🍹文章作者技术和水平很有限,如果文中出现错误,希望大家能指正🙏
📜 感谢大家的关注!???

目录
DQL-分组查询
语法
注意:括号中的语句是可选的!
SELECT 字段列表 FROM 表名 [ WHERE 条件 ] GROUP BY 分组字段名 [ HAVING 分组后过滤条件 ];在做题之前,大家可以发现这条语句中,有两个地方是指定条件的,一个是where之后的条件,一个是having之后的条件,那么肯定有疑问,where和having之间到底有什么区别?
where与having区别
1.执行时机不同:where是分组之前进行过滤,不满足where条件,则不参与分组;而having是分组之后对结果进行过滤。
2.判断条件不同:where不能对聚合函数进行判断,而having中可以。
?案例:
1.根据性别分组 , 统计男性员工 和 女性员工的数量
首先,我们先写下基础查询的语法
select * from emp group by gender ;1.因为我们根据性别分组,所以后面跟的分组的字段名是gender
2.分组我们知道,我们通常配合着聚合函数来操作,因为having中是可以使用聚合函数进行判断的
3.本题需要统计男性员工和女性员工的数量,此时要统计数量,那么我们要用的聚合函数是count还是sum?这里要统计的是数量,所以我们选用count,因此我们需要讲聚合函数加入进去,这里回顾一下聚合函数的语法
select 聚合函数(字段列表) from 表名 ;4.于是在这里需要写入count(*),对分组的男性员工与女性员工进行统计
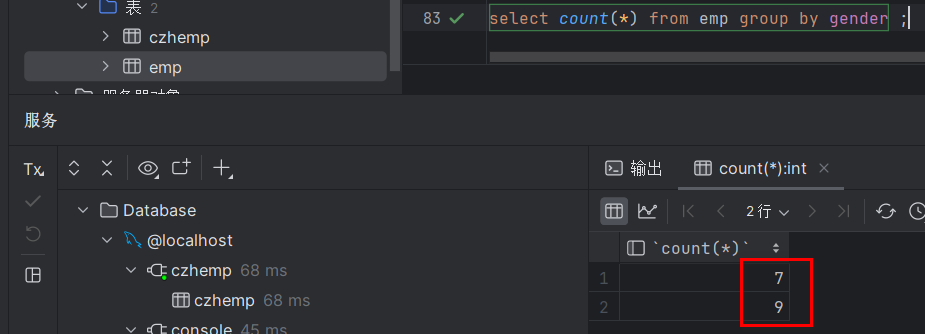
select count(*) from emp group by gender ;此时结果如下:
此时不是很明了,因为我们并不知道到底男性是7还是女性是7?因此我们可以在查询的时候把gender也查询出来,查询多个字段的语法我们回顾一下:
select 字段1,字段2,字段3 ..... from 表名 ;于是我们在count(*)之前再加入gender字段,需要将gender查询出来,代码如下:
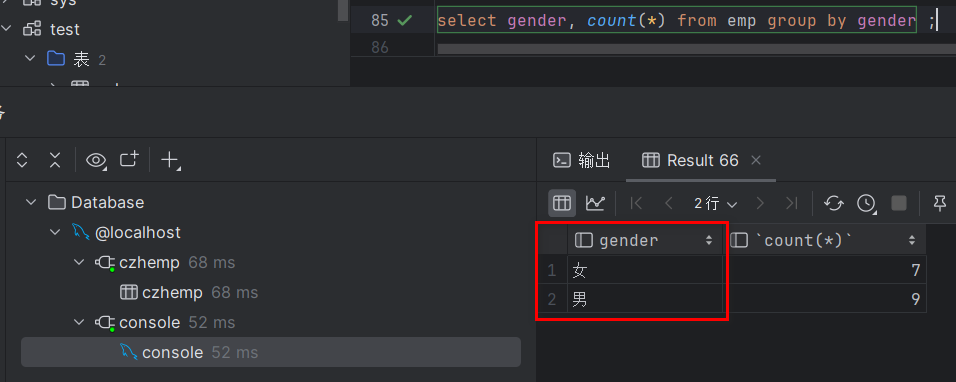
select gender, count(*) from emp group by gender ;执行结果如下:
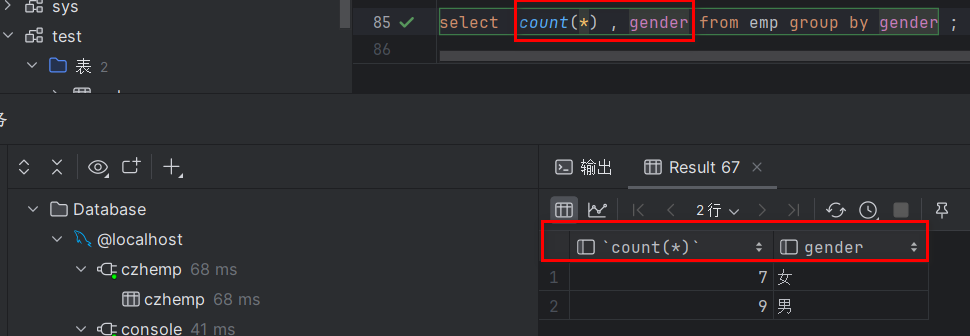
注意!如果gender写在count(*)的后面则查询的结果gender字段就在count(*)后面,执行如下图:
2.根据性别分组 , 统计男性员工 和 女性员工的平均年龄
参照上一案例的思路的话,直接将统计数量的count函数改为平均值avg函数再在括号里将age字段给入即可
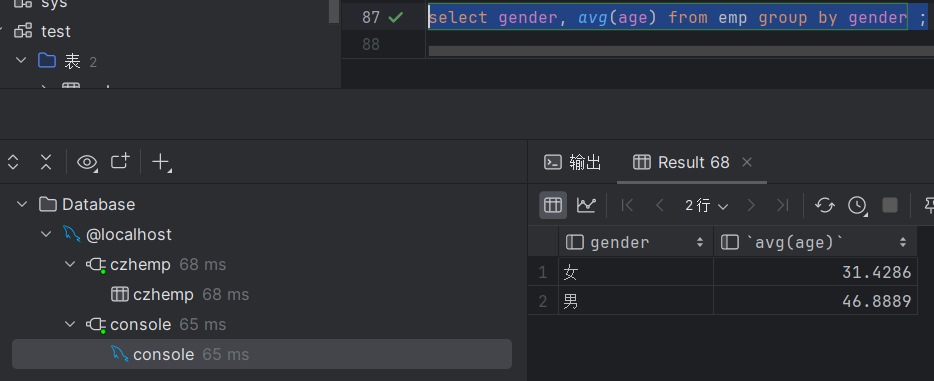
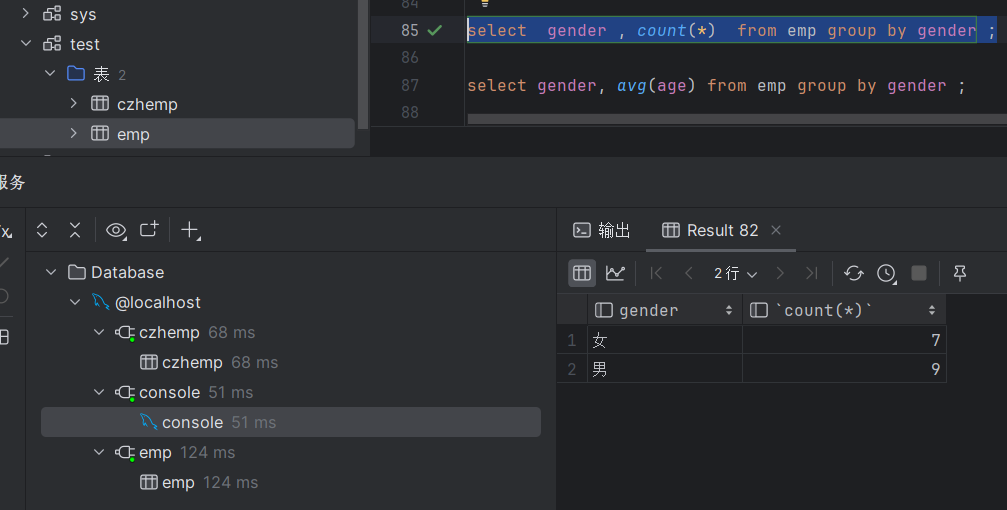
select gender, avg(age) from emp group by gender ;执行结果如下:
?
3.查询年龄小于35的员工 , 并根据工作地址分组 , 获取员工数量大于等于3的工作地址
我们是思路是可以一步一步来完善这些条件,那么第一步先查询出年龄小于35岁的员工
select * from emp where age<35 ;然后根据工作地址进行分组,那么就是加入group by
select * from emp where age<35 group by workaddress ;再然后获取员工数量大于等于3的工作地址,要求取员工的数量,所以*此时应该变为一个count(*),注意,肯定有人会疑惑怎么能用count(*)?大家要明白分组时会执行聚合,也就是说age<35的员工分成不同工作地址后执行了聚合,不同的工作地址看成不同的一整个表,所以用*是没有问题的,总结来说就是select gender, count(*) from emp group by gender ; ?select gender首先他会筛选性别这个字段 ,然后通过 group by 进行分组,这个时候他会自动去统计字段里面的类别,分为男和女2个组,然后,再通过,count(*)去统计每个组的人数。此时就能够根据工作地址workaddress分组,然后获取每一个工作地址的员工年龄小于35的员工数量
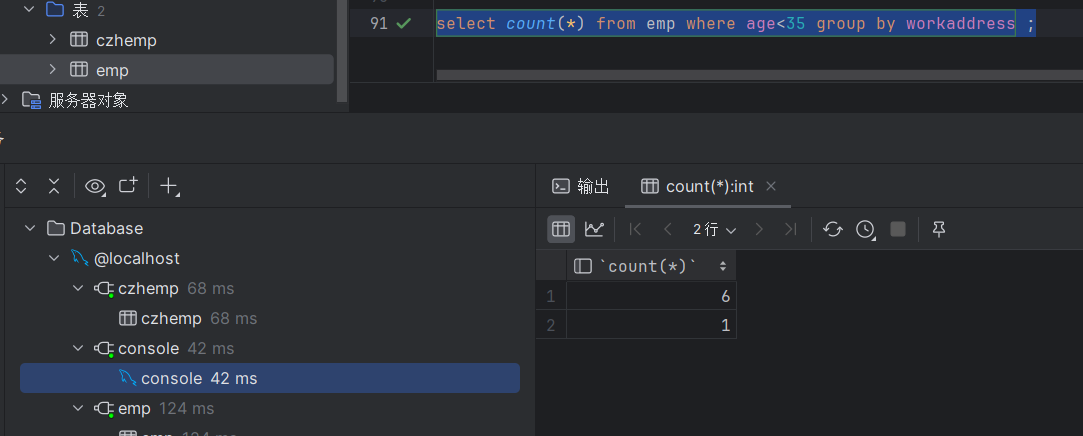
select count(*) from emp where age<35 group by workaddress ;执行结果如下:
当然此时我们很难看出是哪个工作地址的员工的数量所以我们再补全一下代码,将workaddress也进行一个查询,当然workaddress要放置于count(*)前面,注意workaddress和count(*)之间的逗号不能省略
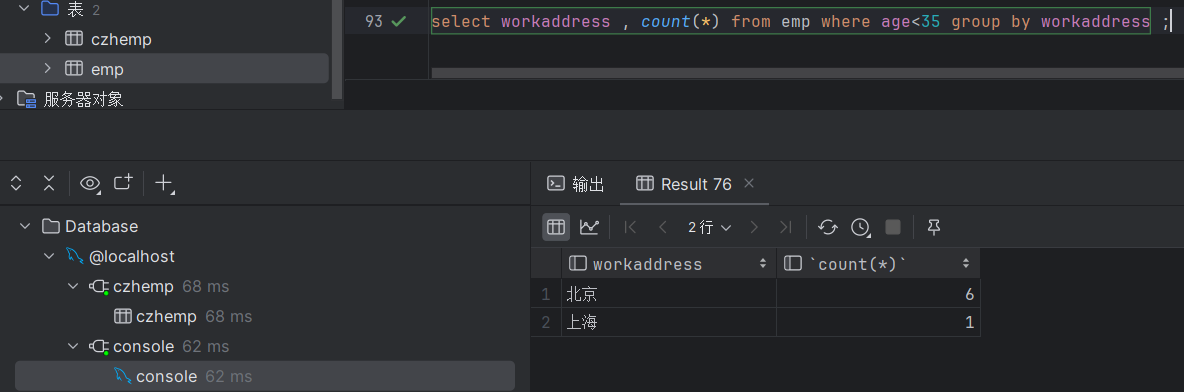
select workaddress , count(*) from emp where age<35 group by workaddress ;执行结果如下:
此时可以看出年龄小于35的员工,在上海的有1人,在北京的有6人,而其他工作地址的数据为什么没有被查询出来,因为它们不满足一个条件就是,它们的年龄没有小于35,所以没有被查询出来
接下来就要考虑查询员工数量大于等于3的工作地址,意思就是要在分组的基础上再进行过滤,我们知道where是分组之前进行过滤,而having是分组之后对结果进行过滤,所以我们肯定要用到having,而且where是不能判断聚合函数的,所以你不能写where count(*) >= 3,我们只能让where去判断age<35,让having去判断count(*) >= 3
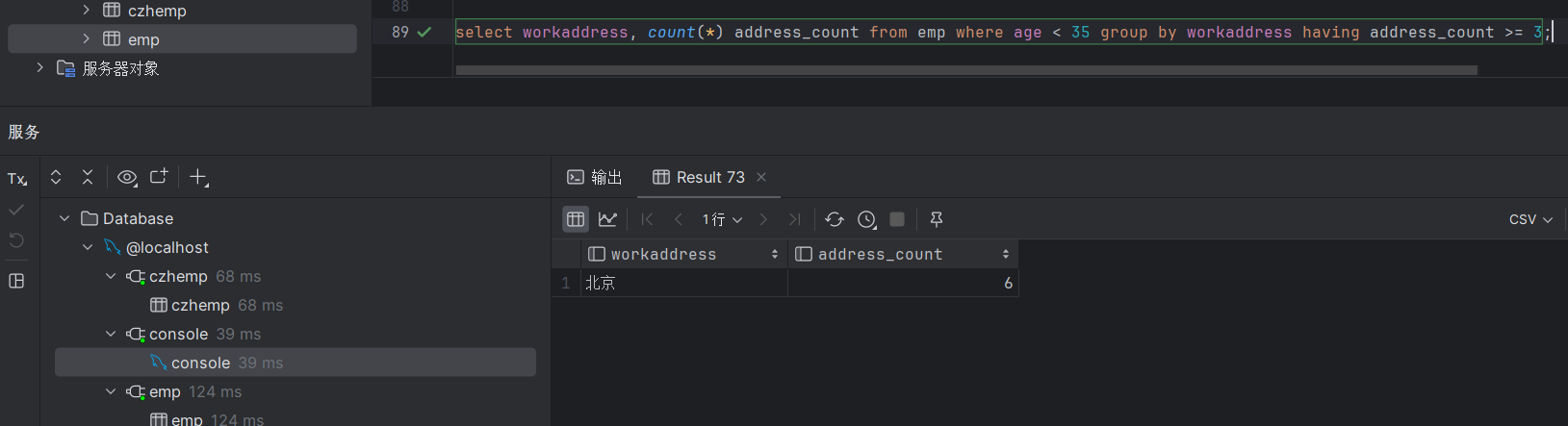
select workaddress, count(*) from emp where age < 35 group by workaddress having count(*) >= 3 ;执行结果如下:
当然,这里给大家介绍一下我们也可以这样写,给它起一个别名,address_count,起了别名之后,后面这一块就不用count(*)了,用别名来进行分组之后的过滤是一样的
select workaddress, count(*) address_count from emp where age < 45 group by workaddress having address_count >= 3;
4.统计各个工作地址上班的男性及女性员工的数量
可以按照前面的方式一步步来完善操作,就不赘述这么多了
1.统计各个地址,男性及女性员工的数量,那么肯定是要根据两个方面进行分组的,一个是地址,一个是性别。当然我们需要特别注意的是多个分组字段之间也是要用逗号分隔的,千万不能漏掉
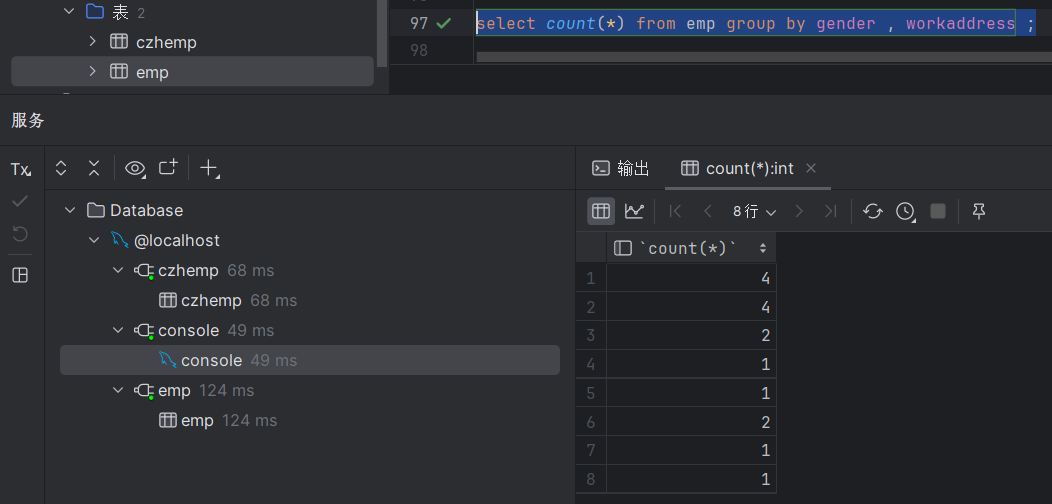
select * from emp group by gender , workaddress ;2.统计员工数量肯定是需要用到count(*)
select count(*) from emp group by gender , workaddress ;执行如下:
3.做到第2部其实条件已经基本完善了,但是不太直观,如果想要查询的数据更好看的话就再添加一下查询字段和别名
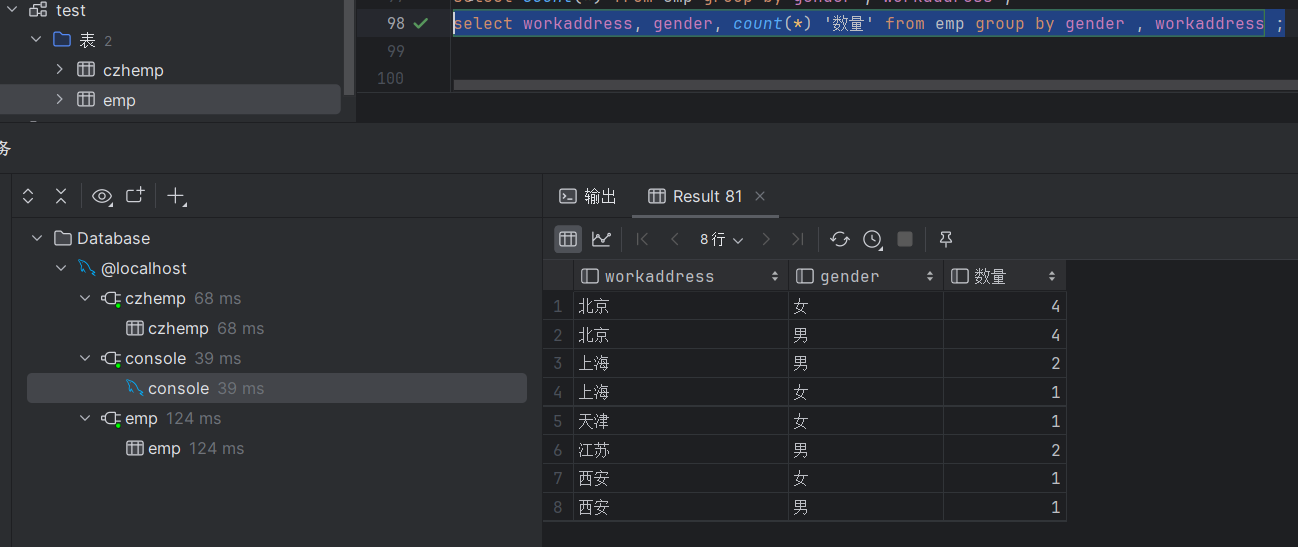
select workaddress, gender, count(*) '数量' from emp group by gender , workaddress ;执行如下:
分组查询注意事项:
执行顺序: where > 聚合函数 > having 。(where在分组之前进行过滤,而分组的时候会执行聚合函数,而having是在分组聚合之后过滤的)
支持多字段分组, 具体语法为 : group by columnA,columnB? ? (注意两个字段中间的逗号不能漏掉)
分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义。
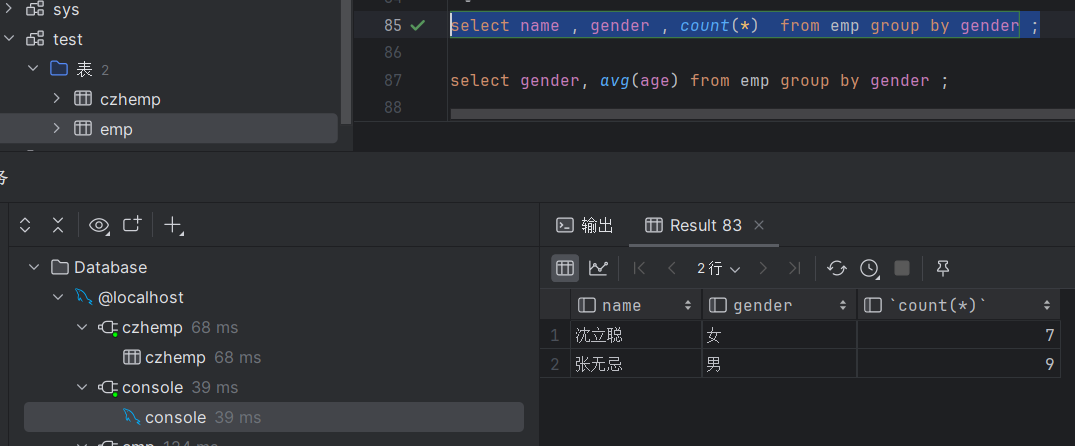
这句话如何理解?如图
大家看,此时我是男9女7,如果我前面加一个name能不能执行?可以,但是执行出来的name值没有任何意义,女性显示一个沈立聪什么含义呢?女性只有沈立聪嘛,女性有很多,它只是展示出来第一个女性的姓名,所以没有任何意义
DQL- 排序查询
排序在日常开发中是非常常见的一个操作,有升序排序,也有降序排序。

语法
SELECT 字段列表 FROM 表名 ORDER BY 字段1 排序方式1 , 字段2 排序方式2 ;大家由此代码可以看出,实际上排序操作是支持多字段排序的,而排序时,第一个就是指定字段名,第二个指定排序方式
排序方式
1.ASC : 升序(默认值)
2.DESC: 降 序
注意事项:
1.如果是升序, 可以不指定排序方式ASC ;
2.如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序 ;
?案例:
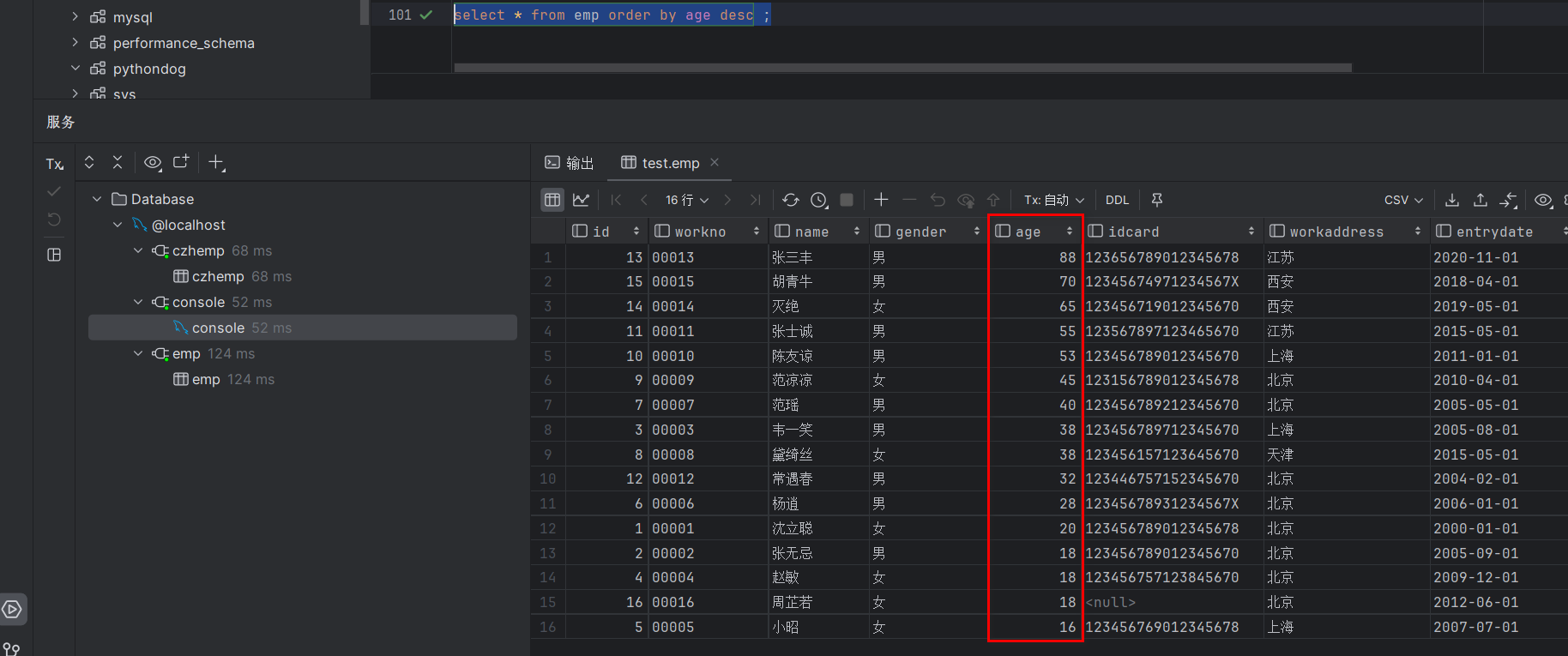
1.根据年龄对公司的员工进行升序排序
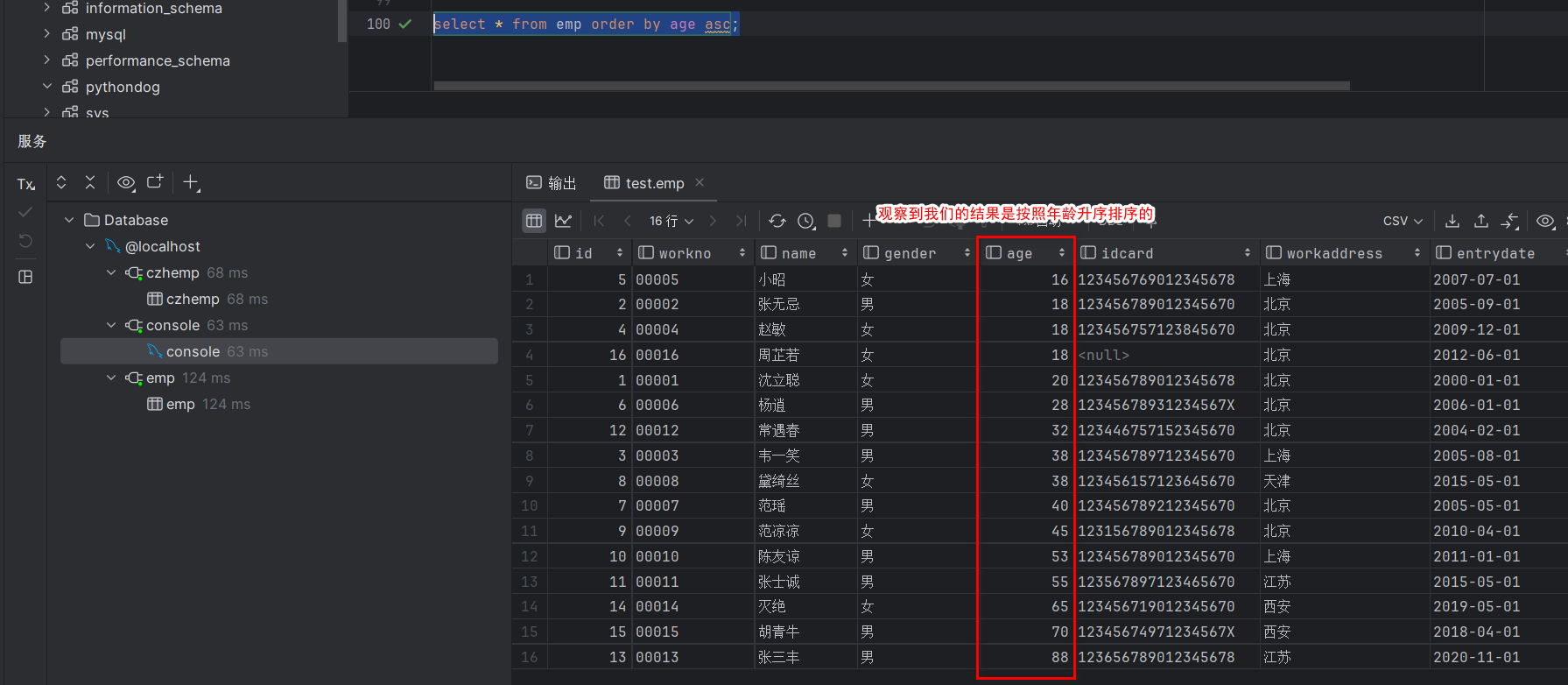
select * from emp order by age asc;
select * from emp order by age;
执行如图 :
 ??
??
?如果要进行降序排序则对asc进行一个替换,替换为desc即可
写法上的一些思考
?1.基础语法先写出来
select * from emp ;2.再写排序关键字order by
select * from emp order by age asc;
2.根据入职时间对员工进行降序排序
select * from emp order by entrydate desc;?执行结果如图:
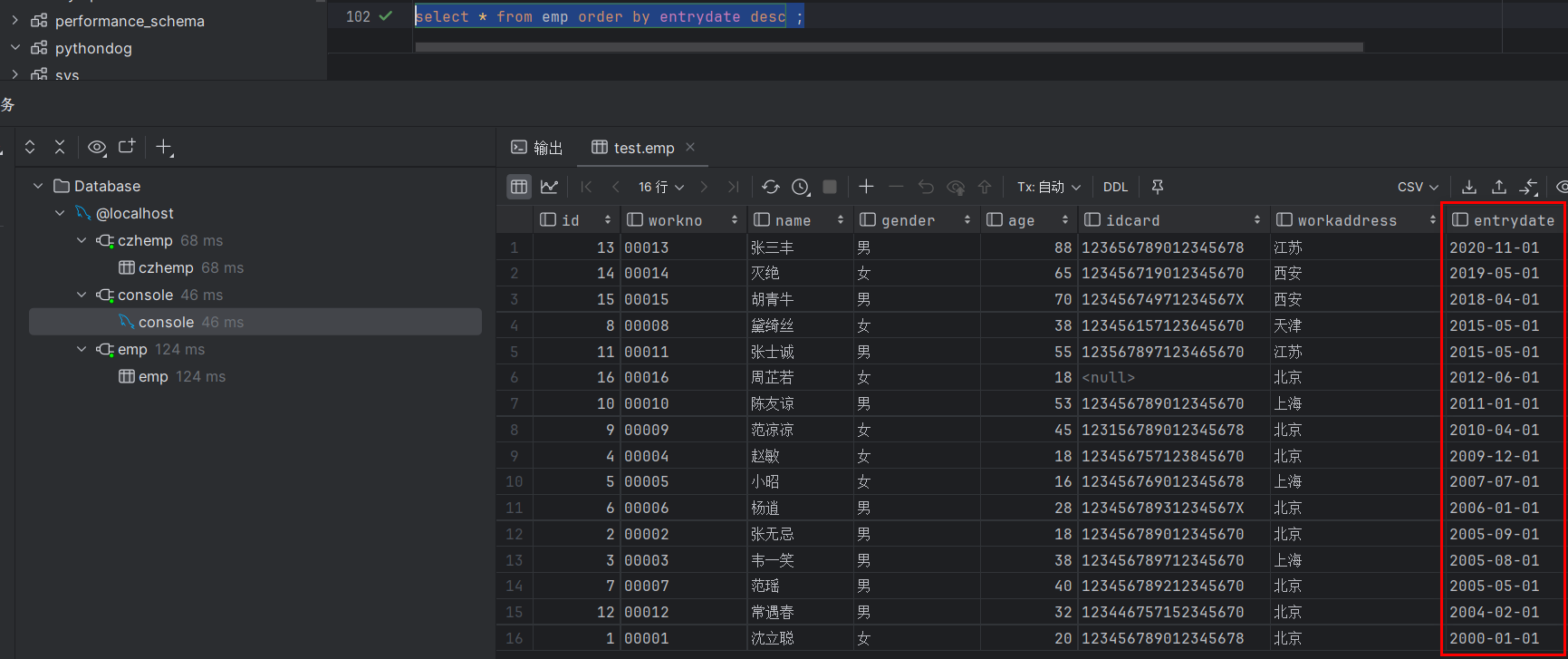
此时可观察到降序?
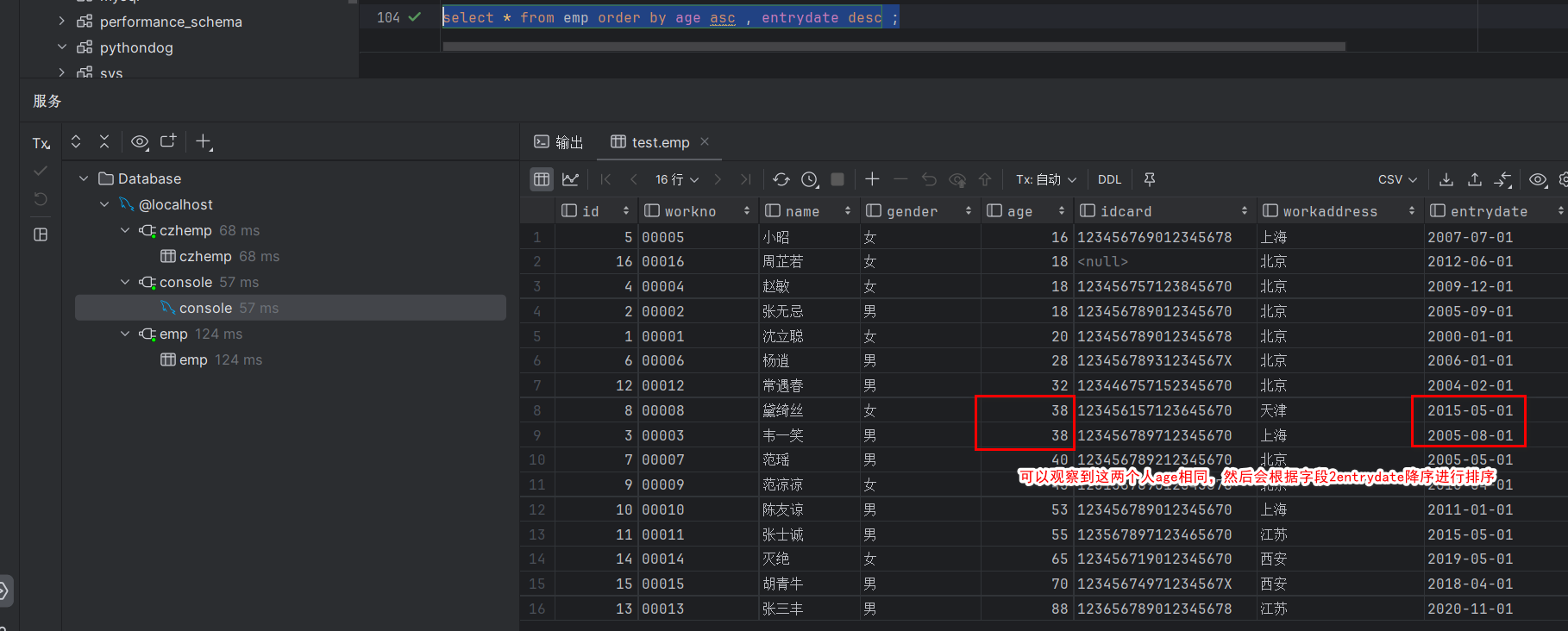
3.根据年龄对公司的员工进行升序排序 , 年龄相同 , 再按照入职时间进行降序排序
select * from emp order by age asc , entrydate desc ;注意,这里多字段排序的意思是,如果前一个字段信息相同了,排序不了之后,才会根据第二个字段进行排序,不是说字段1可以进行升序,字段2可以进行降序
多字段排序,多字段之间使用逗号分隔
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- CTF之逆向入门
- 深入解析C语言中void (*signal(int ,void(*)(int) ) ) (int)
- 网工内推 | 保险业网工,有绩效奖金,CISP认证优先,最高16K
- 华为vrrp+mstp+ospf+dhcp+dhcp relay配置案例
- 多项创新技术加持,汉威科技危化品企业、化工园区两大智能化管控平台重磅发布
- 【数模百科】常用的用于美赛中收集数据的数据库网站
- HCIP实验5-mpls实验
- 为什么西拉和设拉子的味道如此不同?
- Description:Failed to configure a DataSource:‘url‘Reason:Failed to determine a suitable driver class
- openCV图像SIFT特征