【2023】hadoop基础介绍
发布时间:2023年12月28日
💻目录
Hadoop组成
hadoop安装教程可以看我这篇文章===> 🍅hadoop通过docker安装
- HDFS组件:是Hadoop内的分布式存储组件,可以构建分布式文件系统用于数据存储。
- MapReduce组件:MapReduce是Hadoop内分布式计算组件。提供编程接口供用户开发分布式计算程序。
- YARN组件:YARN是Hadoop内分布式资源调度组件。可供用户整体调度大规模集群的资源使用。
HDFS
分布式存储:主从架构——架构角色
- 主角色:Master(NameNode)
- 从角色:Slave(DataNode)
- 主角色的辅助角色:(SecondaryNameNode)
- 处理合并edits为fsimage:会通过http从NameNode拉取数据(edits和fsimage),然后合并完成后提供给NameNode使用。
HDFS操作
-
HDFS文件系统基本信息
操作命令添加协议头就会分别是对对应的系统执行,如果不带是会按照
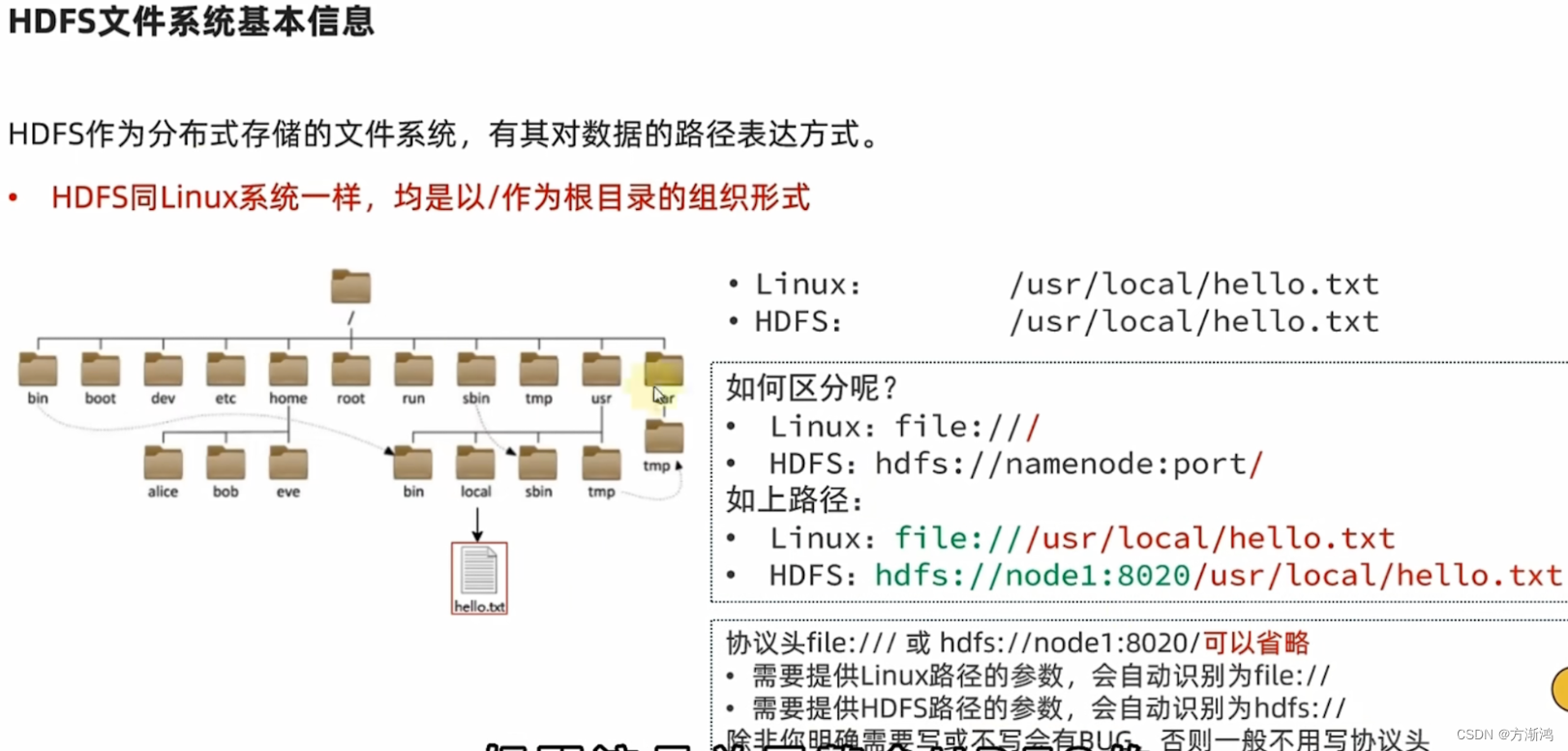
-
操作命令
不同版本命令开头
# 老版本
hadoop fs
# 新版本
hdfs dfs

命令使用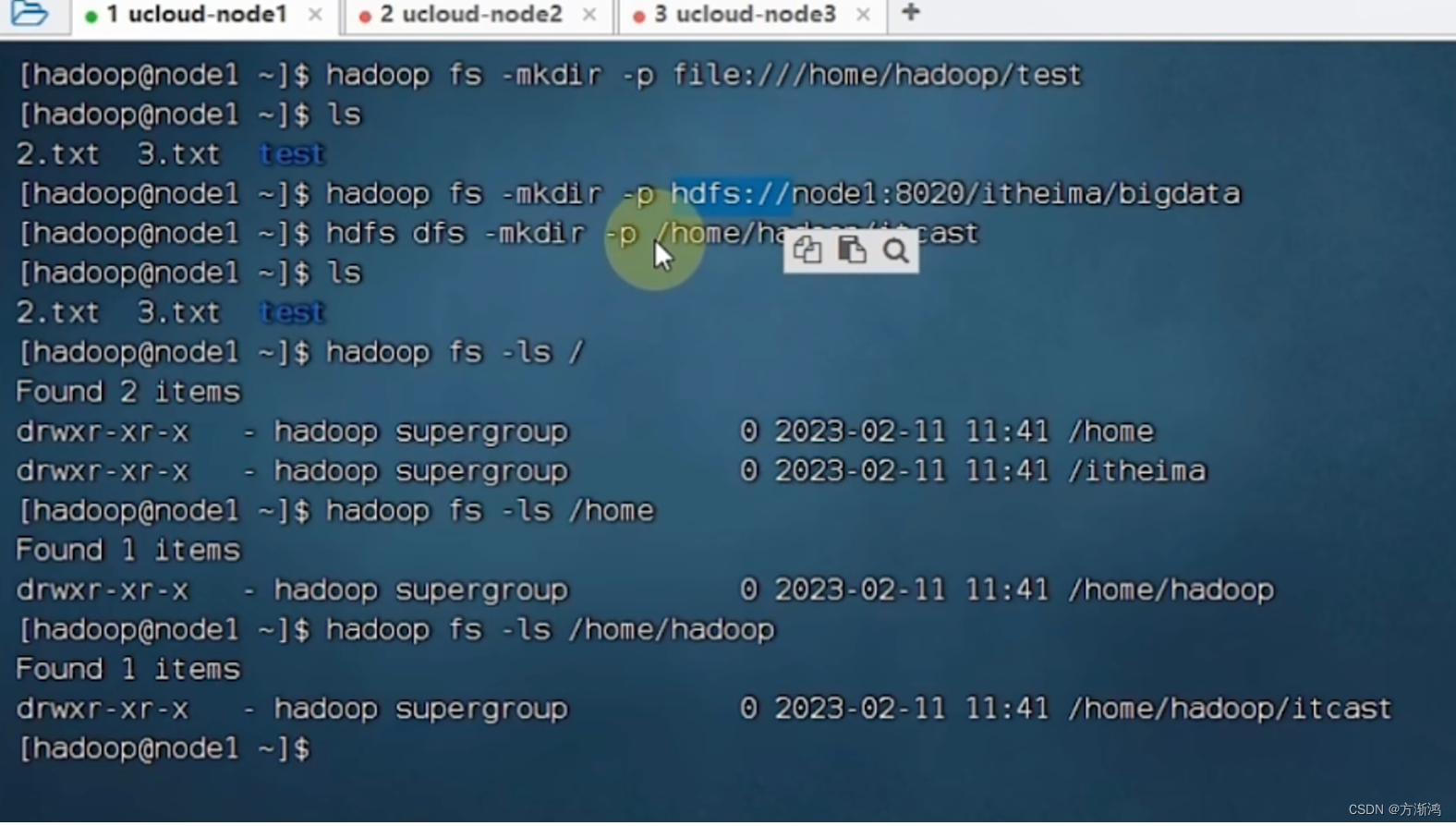
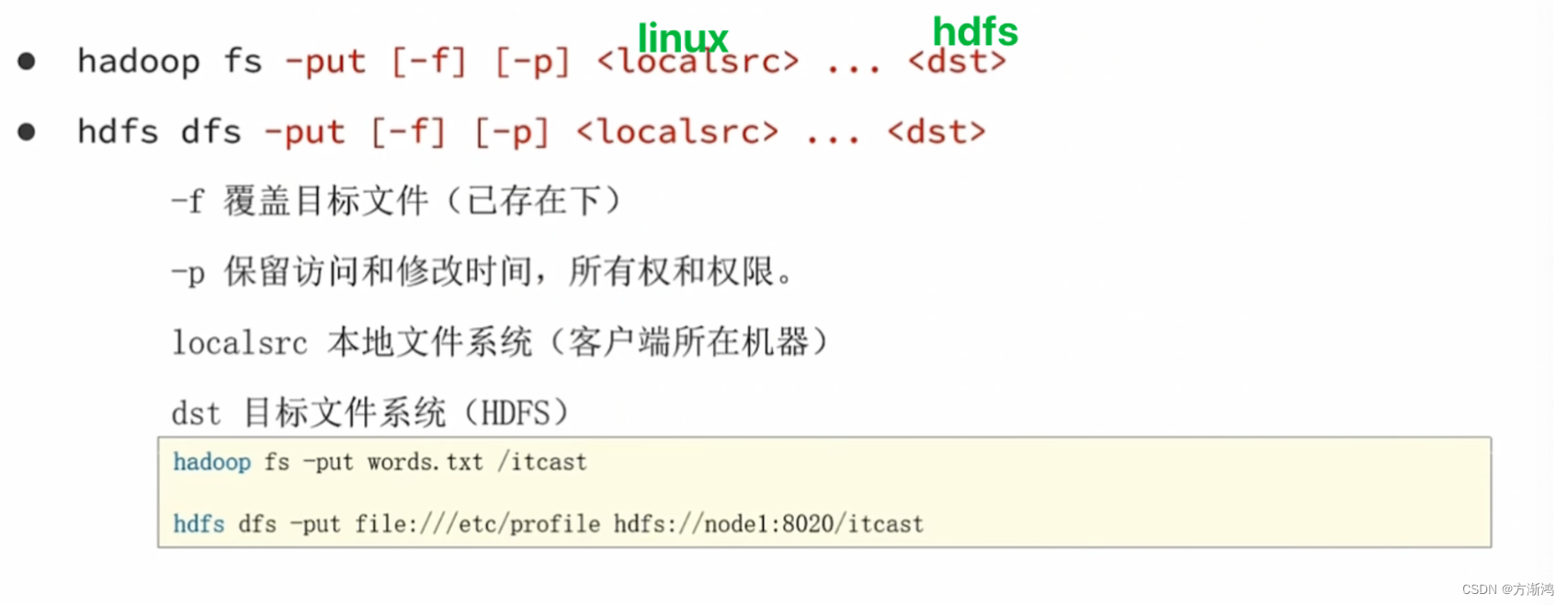
- 上传文件到hdfs文件系统中
# hdfs dfs -put linux路径 HDFS文件路径
hdfs dfs -put ./test2.test /
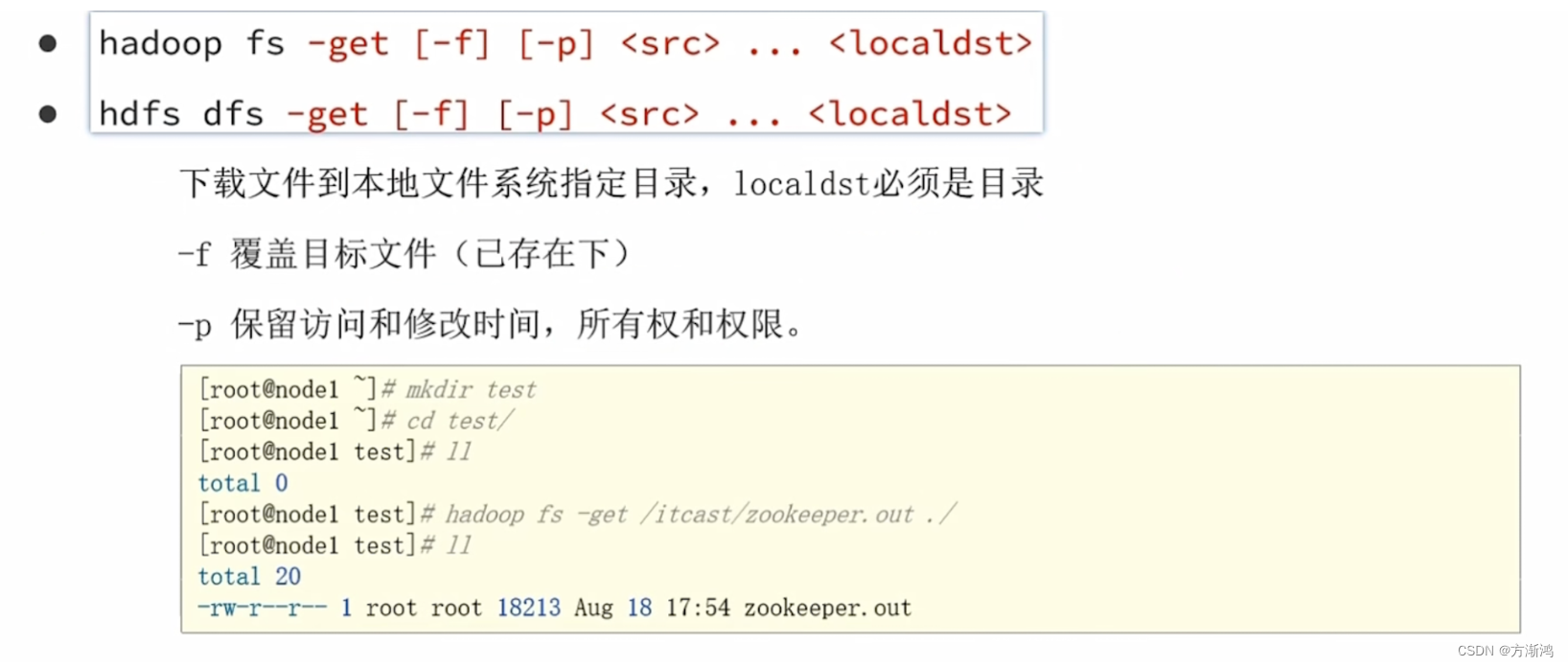
- 下载HDFS文件到linux中
# hdfs dfs -get HDFS文件路径 linux路径
hdfs dfs -get /.test.txt /
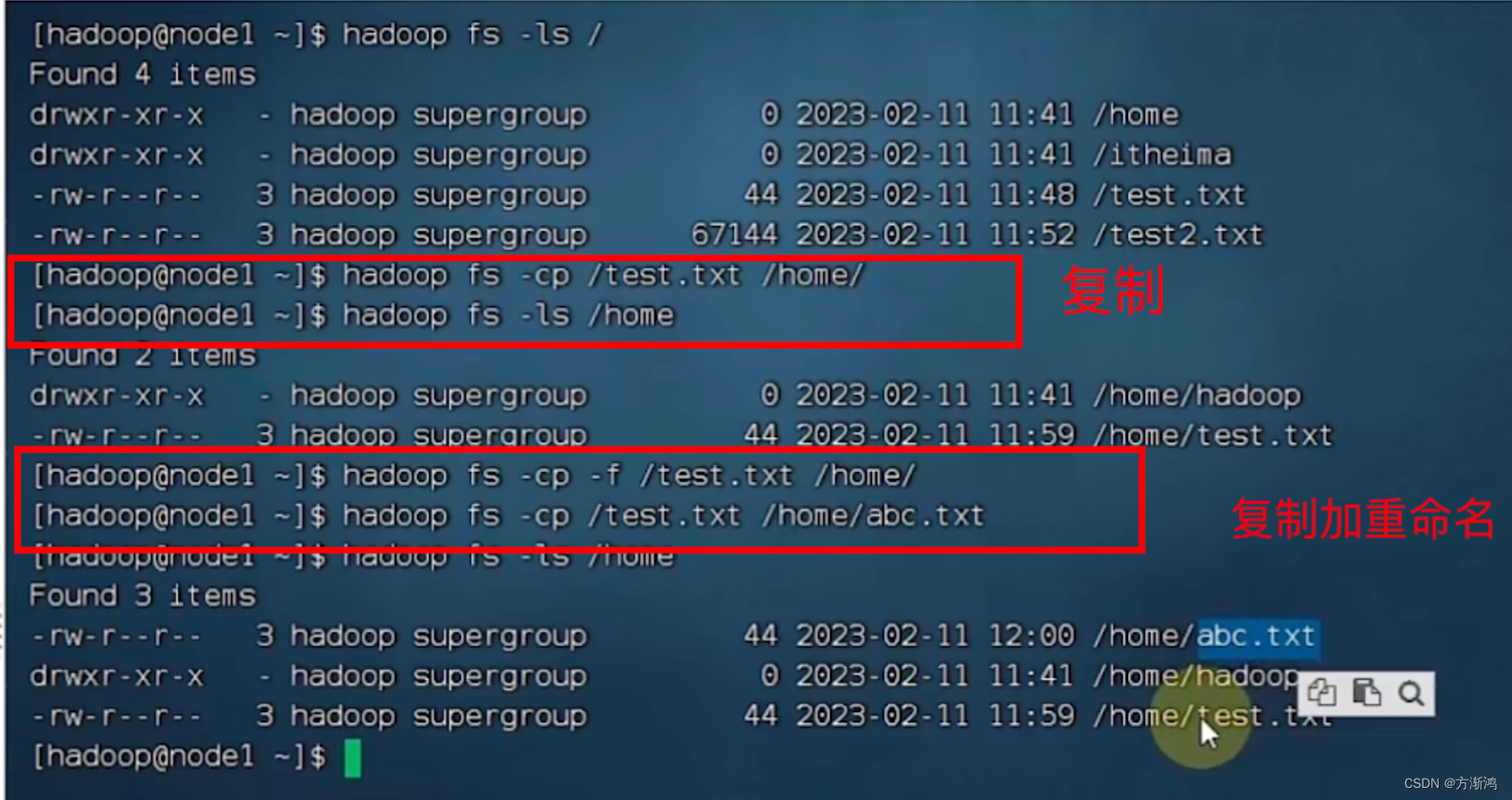
- 拷贝HDFS文件和移动
#拷贝文件
hdfs dfs -cp 源路径 粘贴路径
#移动文件
hdfs dfs -mv 源路径 粘贴路径
-
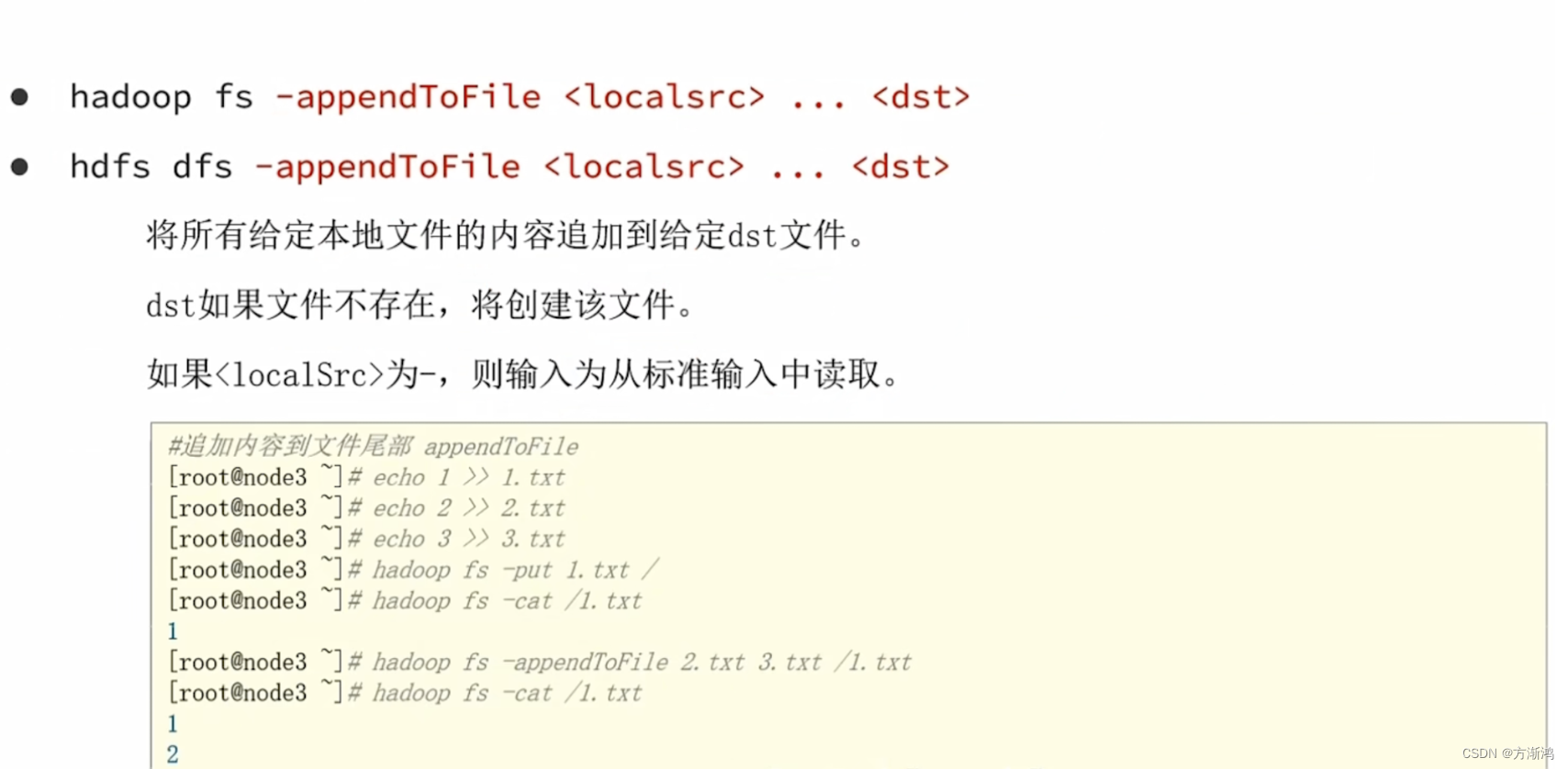
追加数据到HDFS文件
HDFS只能追加和删除,不能修改
htfs -dfs -appendToFile
- 查看文件和删除文件
#查看文件内容
htfs -dfs -cat 文件
#删除文件和文件夹(删除文件不用加-r,删除文件夹需要加-r)
htfs dfs -rm -r 文件路径
删除文件看是否需要添加回收站

html查看文件

产品插件用于使用:Big Data Tools

配置插件

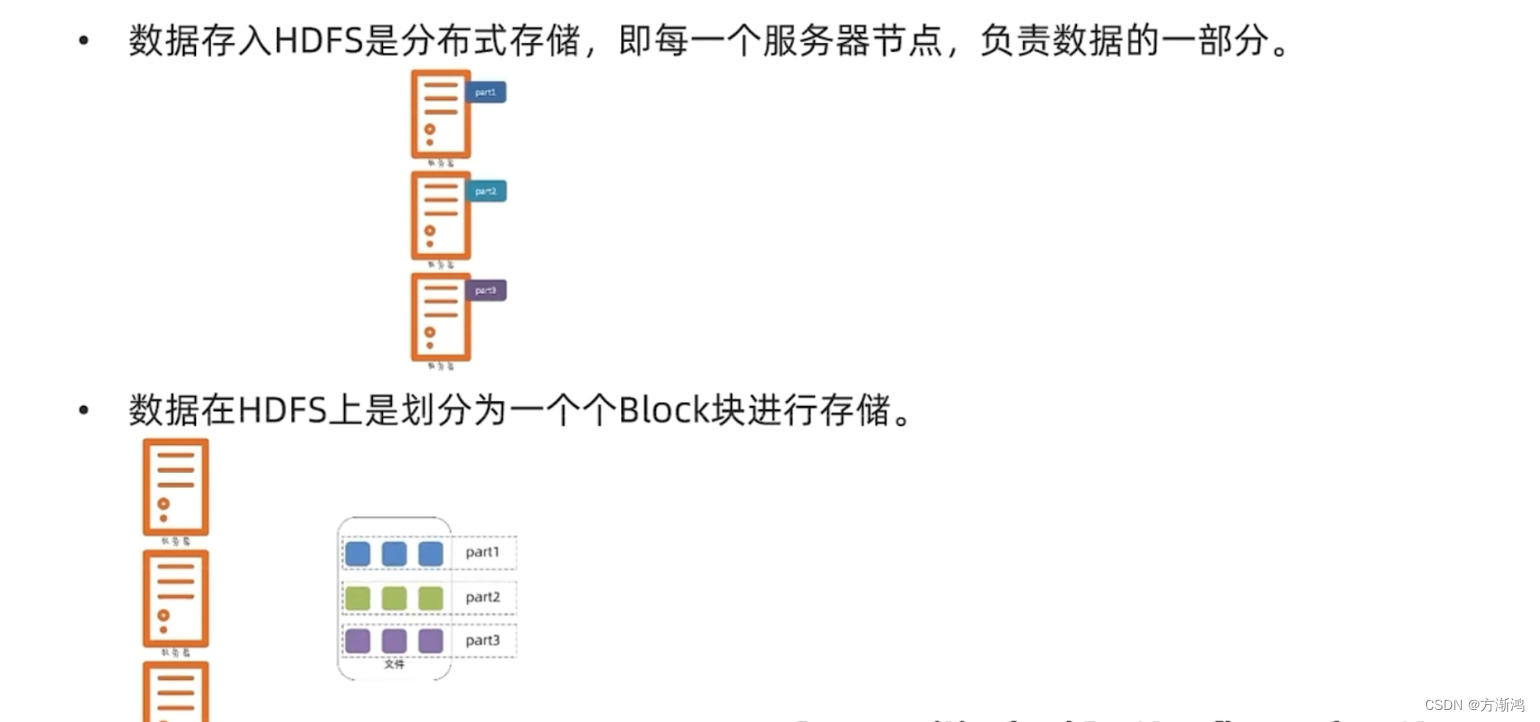
HDFS分布式文件存储
hdfs存储的管理单位是叫 block块
通过分布式的方式进行存储5,为了避免block块丢失,一般会进行冗余备份(通过添加副本块的方式备份),避免文件丢失
NameNode元数据
- edits文件———流水帐文件

- FSlmage文件———最终文件(保存最终结果)
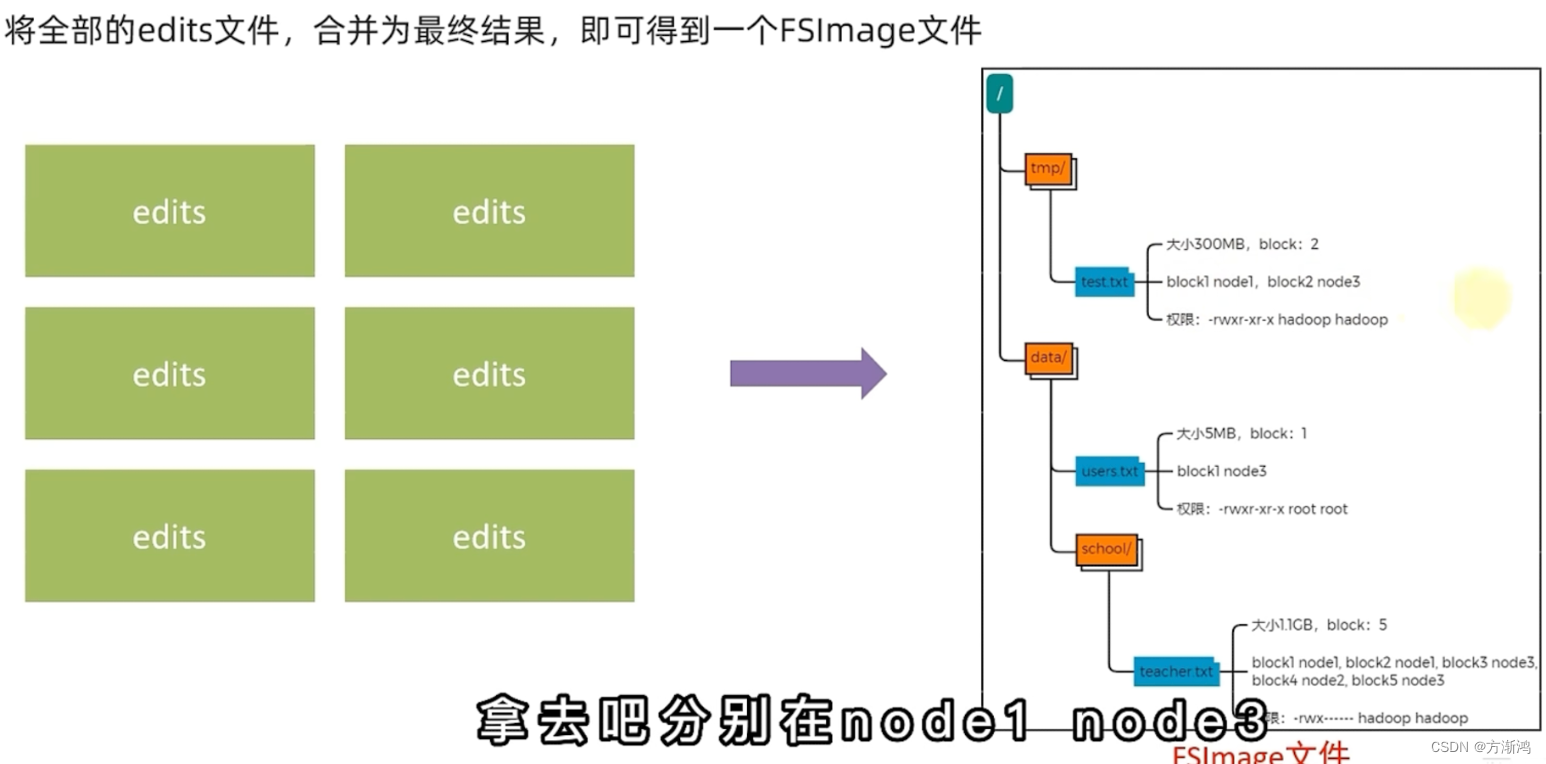
- 执行流程

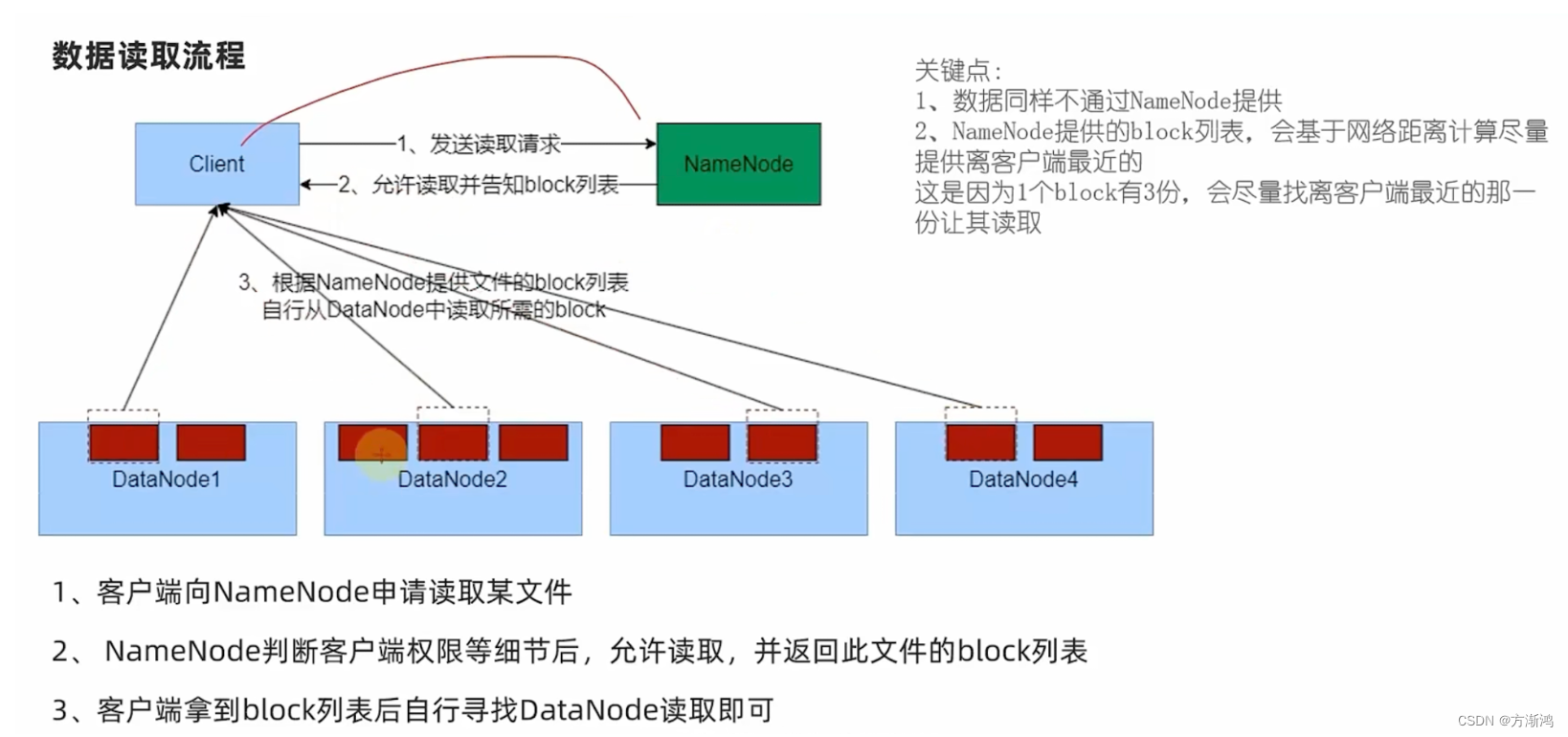
数据读写流程
在进行读写时,会优先读写到网络距离最近的那台dataNode给客户端进行读写,实现读写的最优解。
- 数据写入流程
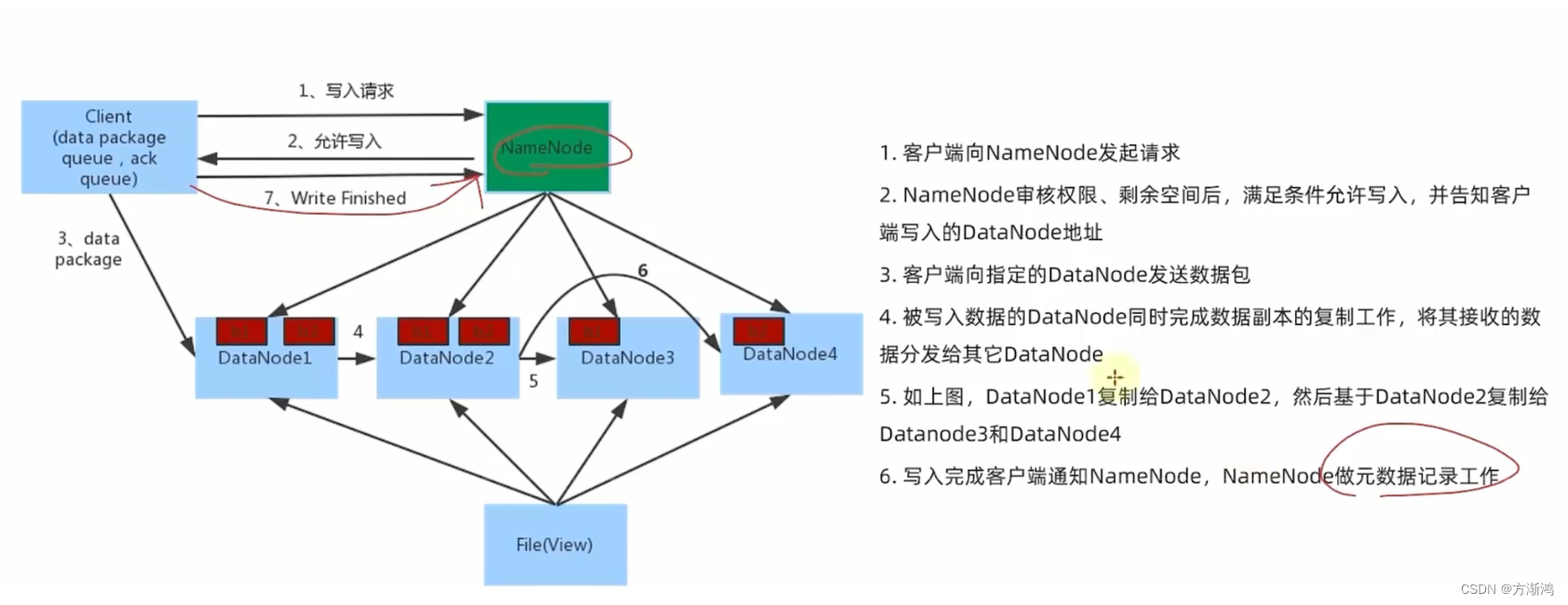

-
数据读取流程
YARN和MapReduce
- 分布式(数据)计算
- 分散—>汇总模式
- 将数据分片,多台服务器负责一部分数据处理
- 然后将各种的数据进行汇总
- 中心调度—>步骤执行模式
- 由一个节点作为中心调度管理者
- 将任务划分为几个具体步骤
- 管理者安排每个机器执行任务
- 最终得到结果数据
- 分散—>汇总模式
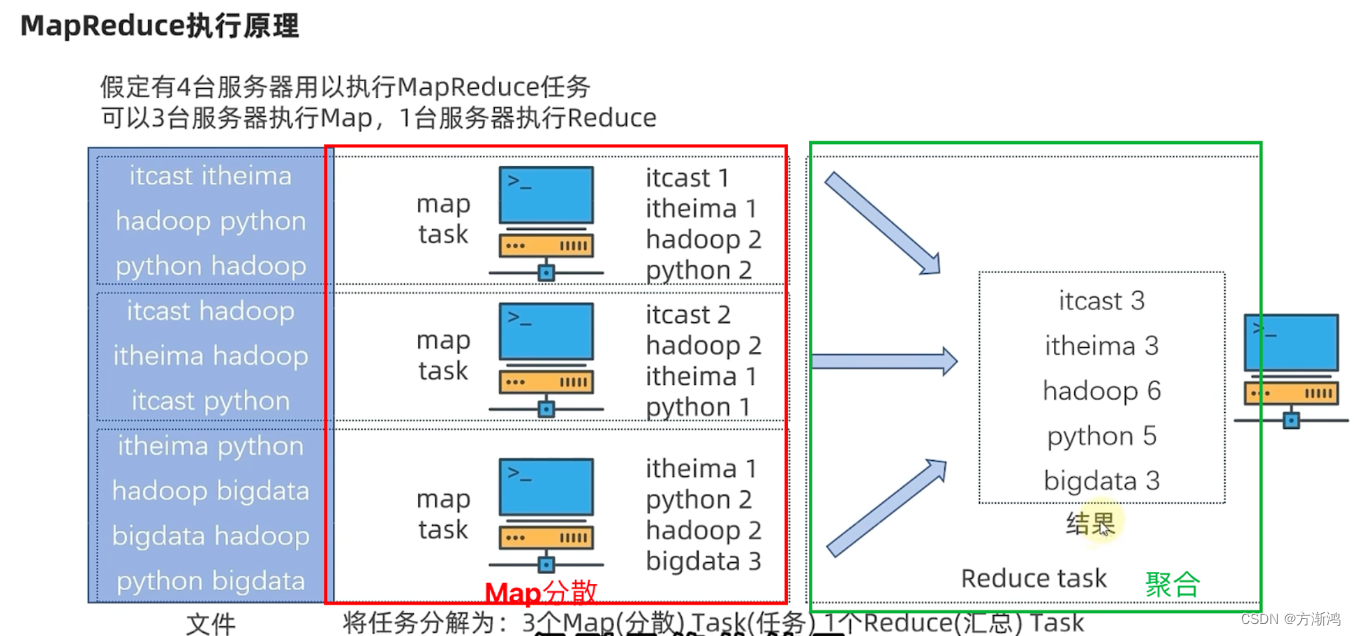
MapReduce:分布式计算
采用的是分散—>汇总模式进行分布式计算
提供了2个编程接口
- Map:分散
- Reduce:汇总
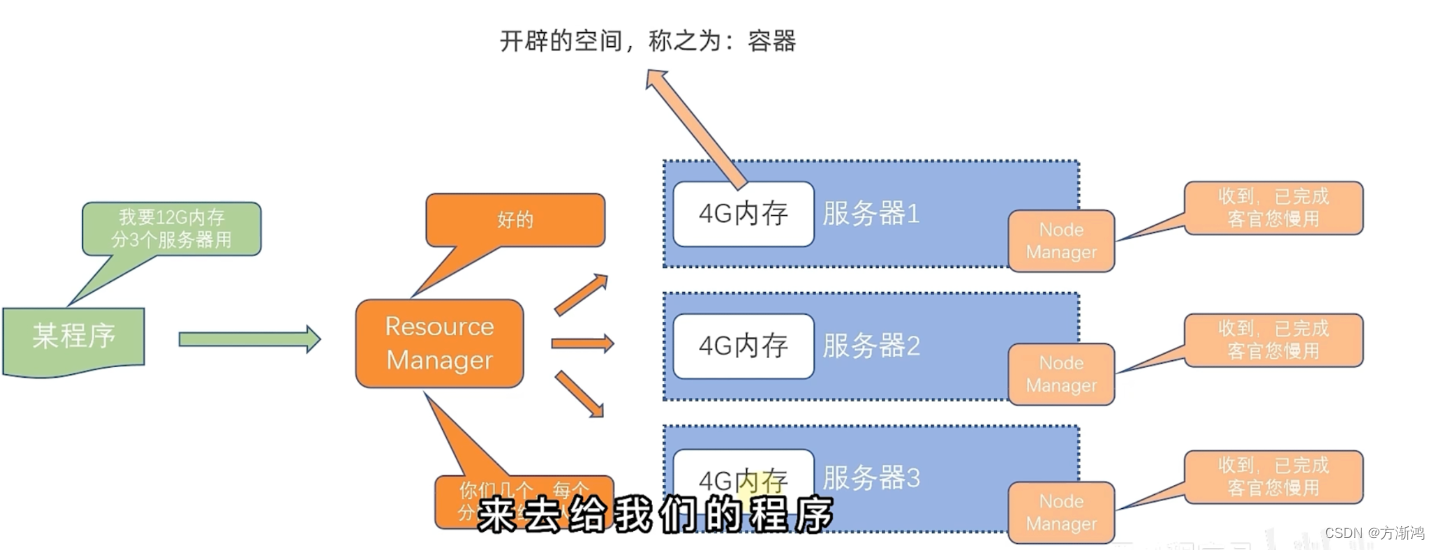
YARN:资源管控调度
将资源统一管控进行分配可以提供资源利用率
MapReduce和YARN的关系
- YARN用来调度资源给MapReduce分配和管理运行资源
- 所以,MapReduce需要YARN配合使用
YARN架构
YARN采用的也是主从架构
核心角色
- ResourceManager:整个集群的资源调度者,负责协调调度各国程序所需要的资源。
- NodeManager:单个服务器的资源调度者,负责调度单个服务器上的资源提供给应用程序使用
辅助角色
- ProxyServer:代理服务器
- JobHistoryServer:历史服务器
YARN集群启动和停止命令(mapReduce无需启动任何进程)
#一键启动:
$HADOOP_HOME/sbin/start-yarn.sh
#一键关闭
$HADOOP_HOME/sbin/stop-yarn.sh
#历史服务器启动和停止
mapred --daemon start|stop historyserver
查看YARN的web页面通过8088端口

提交任务到YARN中运行

文章来源:https://blog.csdn.net/weixin_52315708/article/details/135279405
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!