绝地求生游戏最终排名预测--数据分析实战
介绍
????????绝地求生是一款由蓝洞在 2017 年发行的大逃杀型游戏。一经推出就深受广大游戏玩家的喜欢。而本次实验则是分析怎么样才能在游戏中取得胜利。当然,这不是游戏教程,而是用数据来分析出一些对游戏最终排名有用的信息。
? ? ? ? 博客资源有该分析所用数据
知识点
- 数据读取与预览
- 数据可视化
- 构建随机森林预测模型
绝地求生介绍
????????相信很多都玩过绝地求生这款游戏,其游戏规则主要是将 100 名玩家空手被扔到一个岛上,这些玩家必须探索、寻找、消灭其他玩家,直到只剩下一个玩家活着。绝地求生很受欢迎。这款游戏销量目前超过5000万份,是有史以来销量排名前五的游戏,每月有数百万活跃玩家。而我们本次实验的任务就是根据玩家在游戏中的种种表现来预测出其在最终的排名。
导入数据并预览
首先安装实验需要的 statsmodels 包。
!pip install statsmodels==0.9.0
读取数据并预览前 5 行。
import pandas as pd
df = pd.read_csv('PUBG.csv')
df.head(5)

由上面的输出结果可知,数据主要由 29 列构成。我们所要预测的列为 winPlacePerc 。各列所表示的含义如下。

现在查看一下数据的基本信息。
df.info()

由上可知,该数据集中不含有缺失值,查看数据描述。
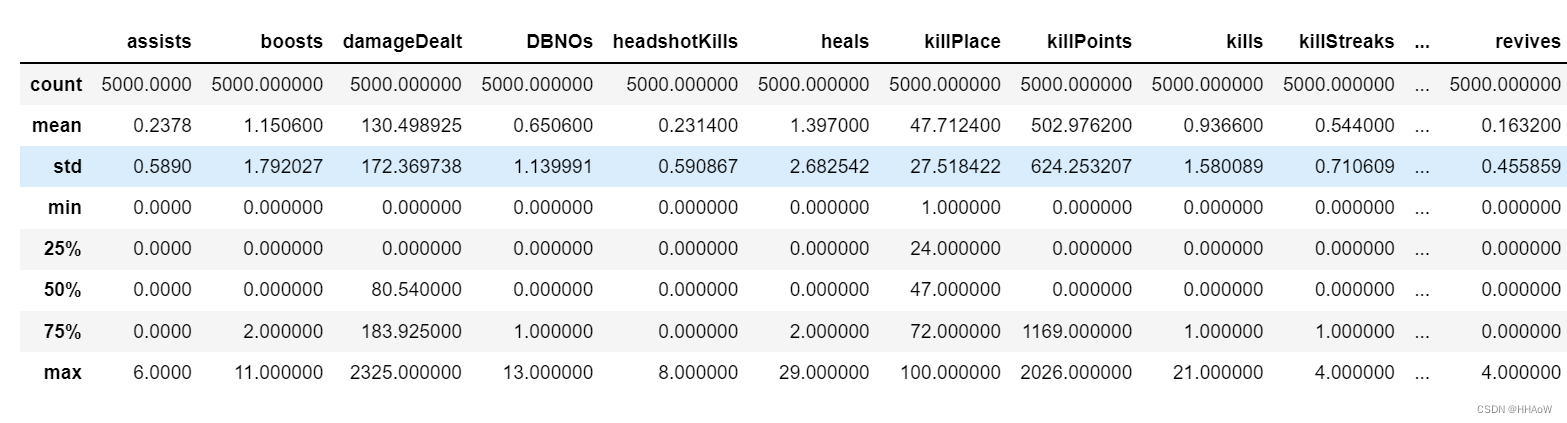
数据可视化
由于我们所要预测的列为 winPlacePerc ,即排名情况,所以先来分析该列。先导入相关的画图工具。
import seaborn as sns
from matplotlib import pyplot as plt
%matplotlib inline
plt.style.use('fivethirtyeight')
游戏排名
winPlacePerc 列是系统给出的游戏排名,而 winPoints 是外部给出的游戏排名,现在画出这两列的数据分布图。
fig, (ax1, ax2) = plt.subplots(1, 2)
fig.set_figwidth(15)
sns.distplot(df['winPlacePerc'], ax=ax1)
sns.distplot(df['winPoints'], ax=ax2)
plt.show()
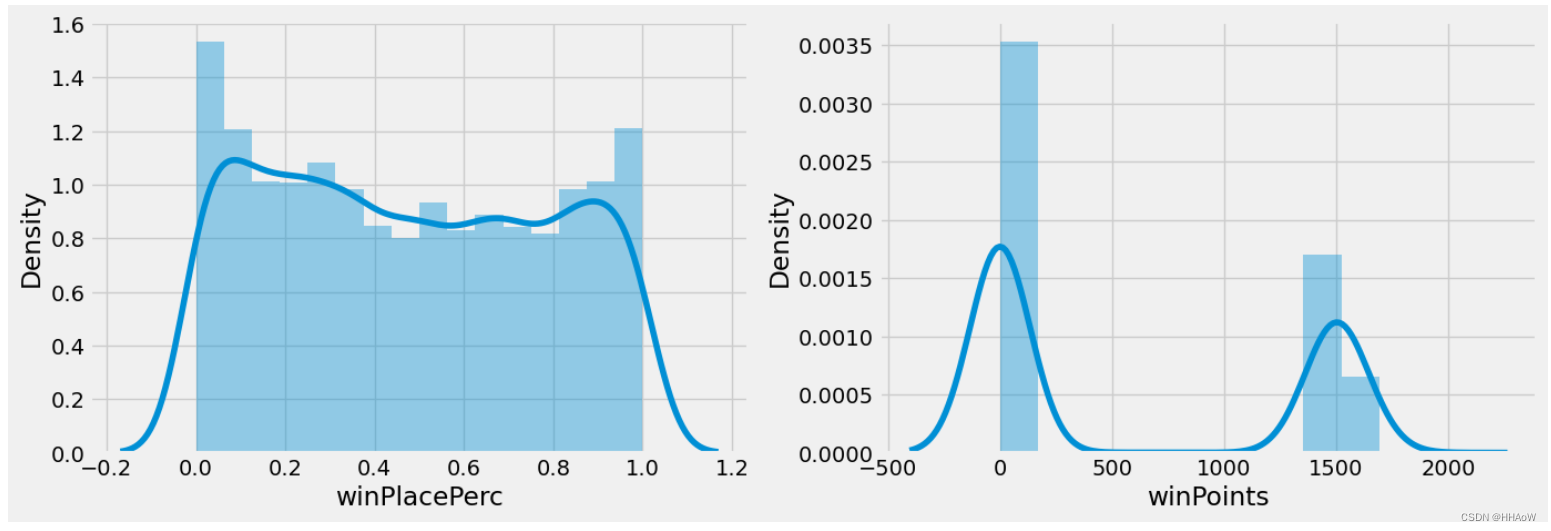
从上的结果可以看到,游戏排名似乎呈两极分化现象,0 和 1 两头的人数都相对多一点。
玩家击倒敌人
现在来看玩家击倒敌人的人数的情况。
train_dbno = pd.DataFrame(df['DBNOs'].value_counts(), columns=['DBNOs'])
dbno = train_dbno.iloc[:9, :]
dbno.iloc[8]['DBNOs'] = train_dbno.iloc[8:, :].sum()['DBNOs']
plt.figure(figsize=(14, 5))
sns.barplot(dbno.index, dbno.DBNOs)
plt.gca().set_xticklabels([0, 1, 2, 3, 4, 5, 6, 7, '8+'])
plt.gca().set_xlabel('No of enemy players knocked')
plt.gca().set_ylabel("count")
plt.show()
plt.savefig("enemy_")
从上图可以看到,许多玩家都是 0 击倒,说明大多数玩家水平可能还是处于初级阶段。
击倒数量与排名的关系
我们来看一下,击倒敌人的数量是否与最后的排名有关。
f, ax1 = plt.subplots(figsize=(15, 5))
sns.pointplot(x='DBNOs', y='winPlacePerc', data=df,)
plt.xlabel('Number of DBNOs', fontsize=15, color='blue')
plt.ylabel('Win Percentage', fontsize=15, color='blue')
plt.title('DBNOs / Win Ratio', fontsize=20, color='blue')
plt.grid()
plt.show()
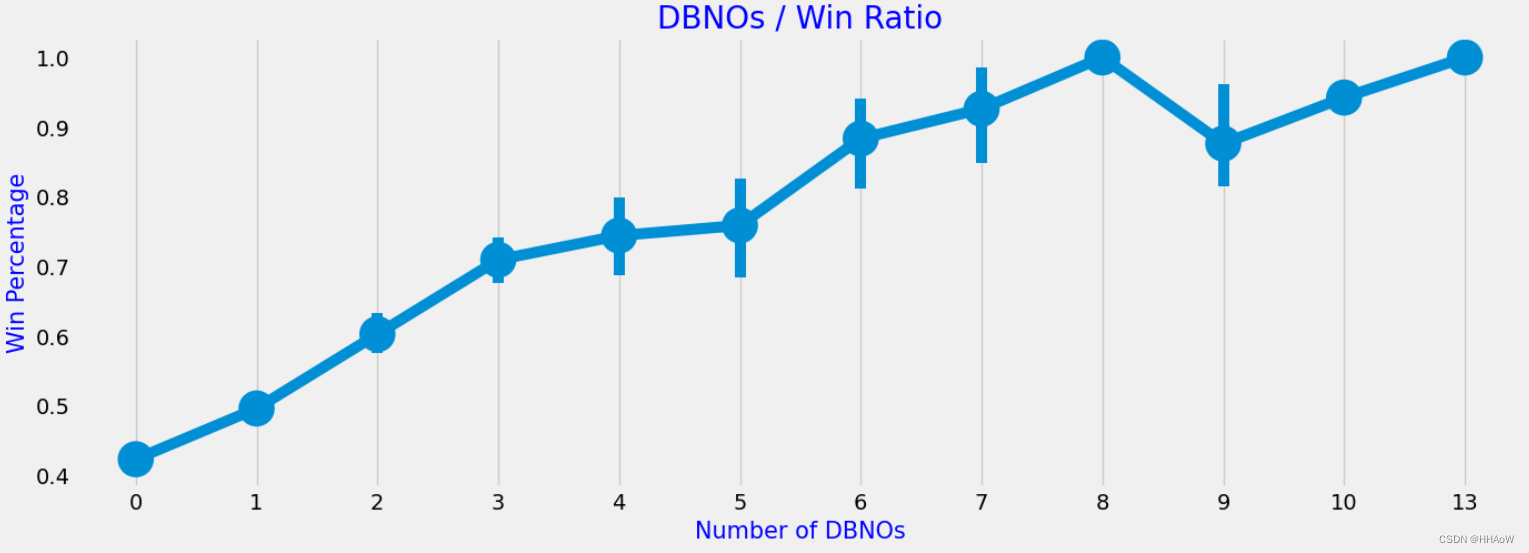
从上图可以看到,击倒敌人的数量越多,排名也就越高。这说明,击倒敌人与排名有很大的关系。
玩家所受伤害
现在看在一局游戏中,玩家自己所受到的伤害。
fig, (ax1, ax2) = plt.subplots(1, 2)
fig.set_figwidth(15)
sns.distplot(df['damageDealt'], ax=ax1)
sns.boxplot(df['damageDealt'], ax=ax2)
plt.show()
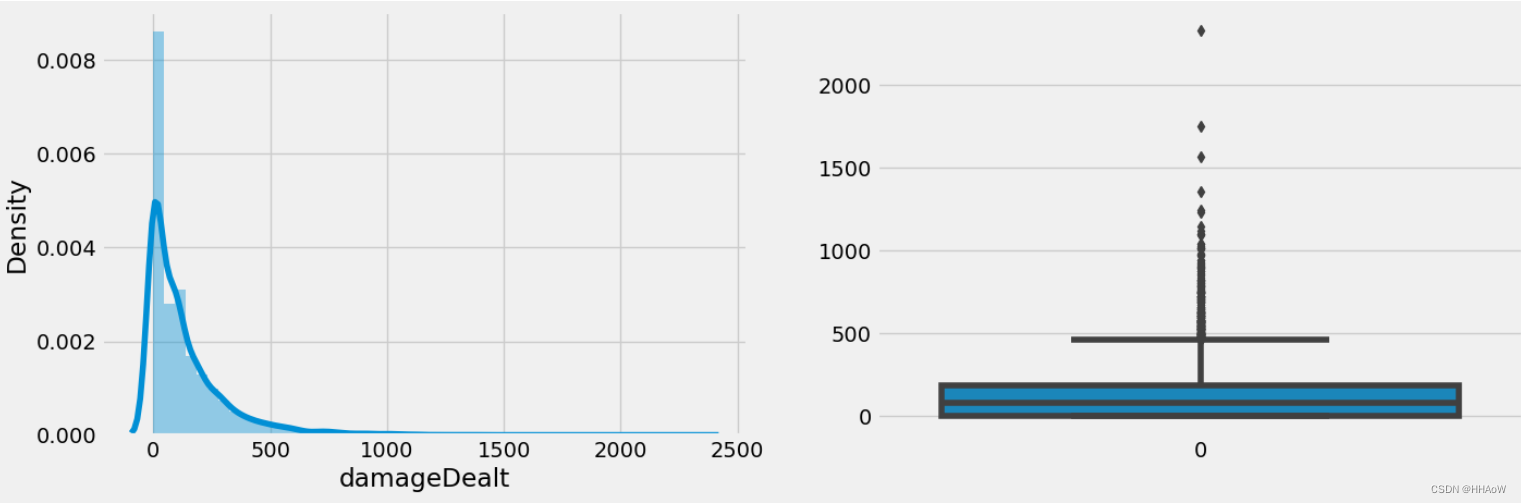
从上图可以看出,大多数人的受到的伤害在 0 到 500 之间。
玩家受伤害值是否与排名有关系
现在来看玩家受伤害值是否与排名有关系。
data = df.copy()
# 将伤害值分为 6 个部分。
data['damageDealt_rank'] = pd.cut(data['damageDealt'],
[-1, 500, 1000, 1500, 2000, 2500, 60000],
labels=['0_500', '500-1000', '1000-1500',
'1500-2000', '2000-2500', '2500+'])
f, ax1 = plt.subplots(figsize=(14, 4))
sns.pointplot(x='damageDealt_rank', y='winPlacePerc', data=data, alpha=0.8)
plt.xlabel('damageDealtk', fontsize=15, color='blue')
plt.xticks(rotation=45)
plt.ylabel('Win Percentage', fontsize=15, color='blue')
plt.title('damageDealt / Win Ratio', fontsize=20, color='blue')
plt.grid()
plt.show()
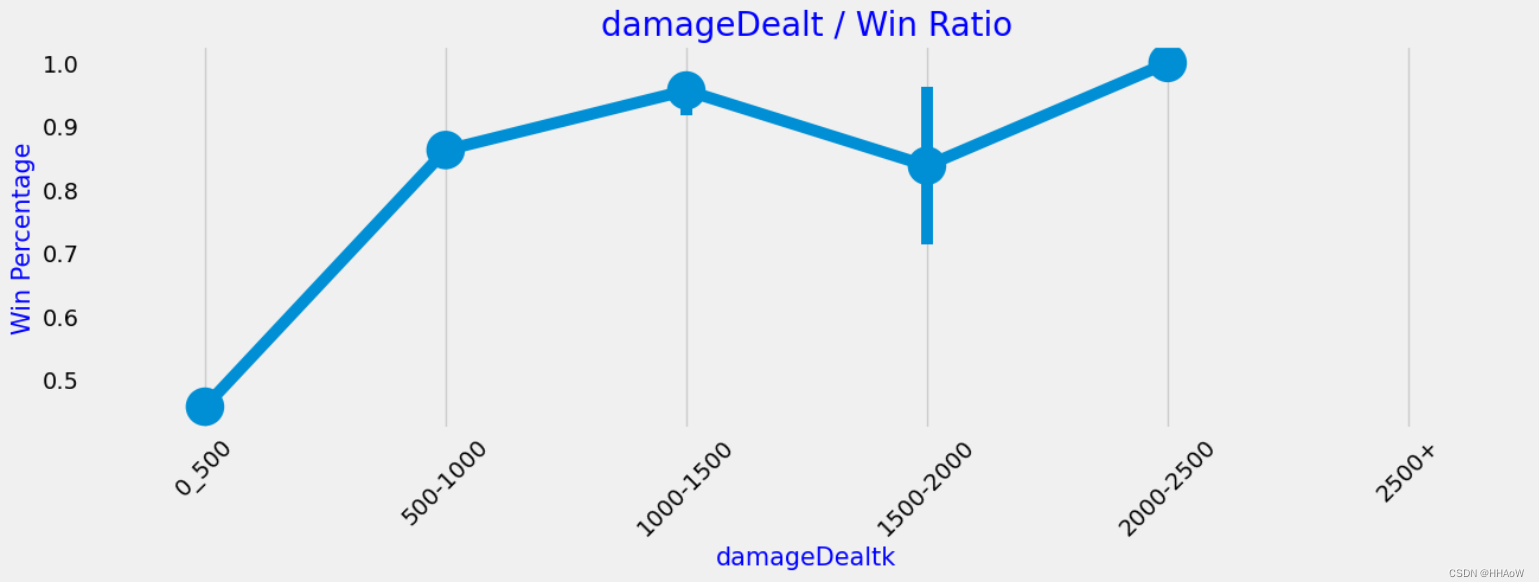
从上图可以看到,玩家排名越靠前,所受到的伤害就越大。
击杀排名
现在来看杀死敌人的排名情况。
plt.figure()
sns.distplot(df['killPlace'], bins=50)
plt.show()
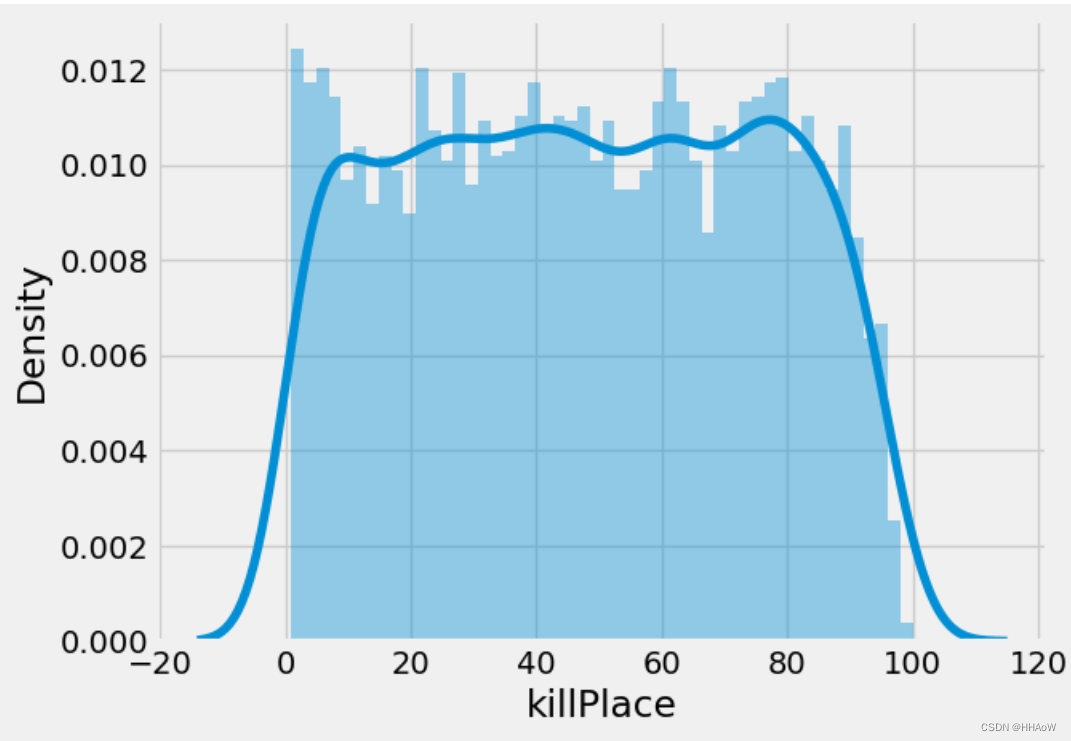
从上图可以看出,在杀死敌人排名中呈现均匀分布的现象。
击杀敌人数量
现看一下杀死敌人的数量。
fig, (ax1, ax2) = plt.subplots(1, 2)
fig.set_figwidth(15)
sns.distplot(df['kills'], kde=False, ax=ax1)
sns.boxplot(df['kills'], ax=ax2)
plt.show()
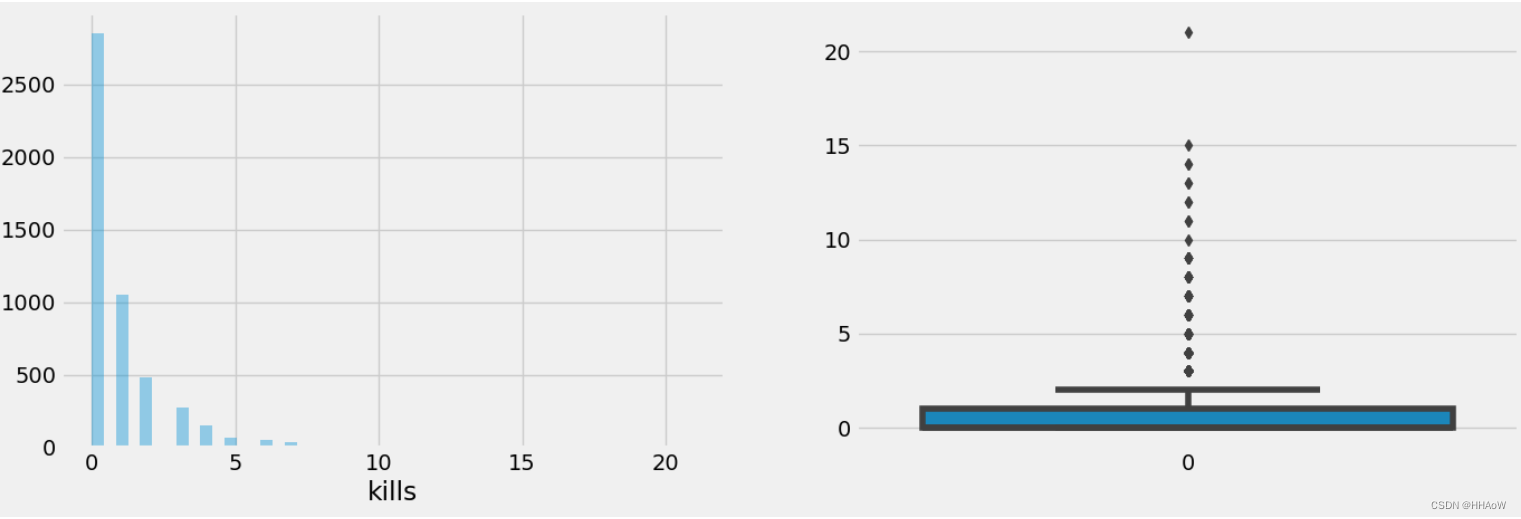
从上图可以看到,大多数玩家杀死敌人的数量都不超过 5 个人。从右图看到,有个别玩家在游戏中杀死敌人的数量超多了 20 人。
击杀敌人与所受伤害关系
我们可以分析一下,游戏玩家杀死敌人的数量与自己所受到的伤害的关系。
plt.figure()
sns.regplot(df['kills'].values, df['damageDealt'].values)
plt.gca().set_ylabel('Damage dealt')
plt.gca().set_xlabel('Total kills')
plt.show()
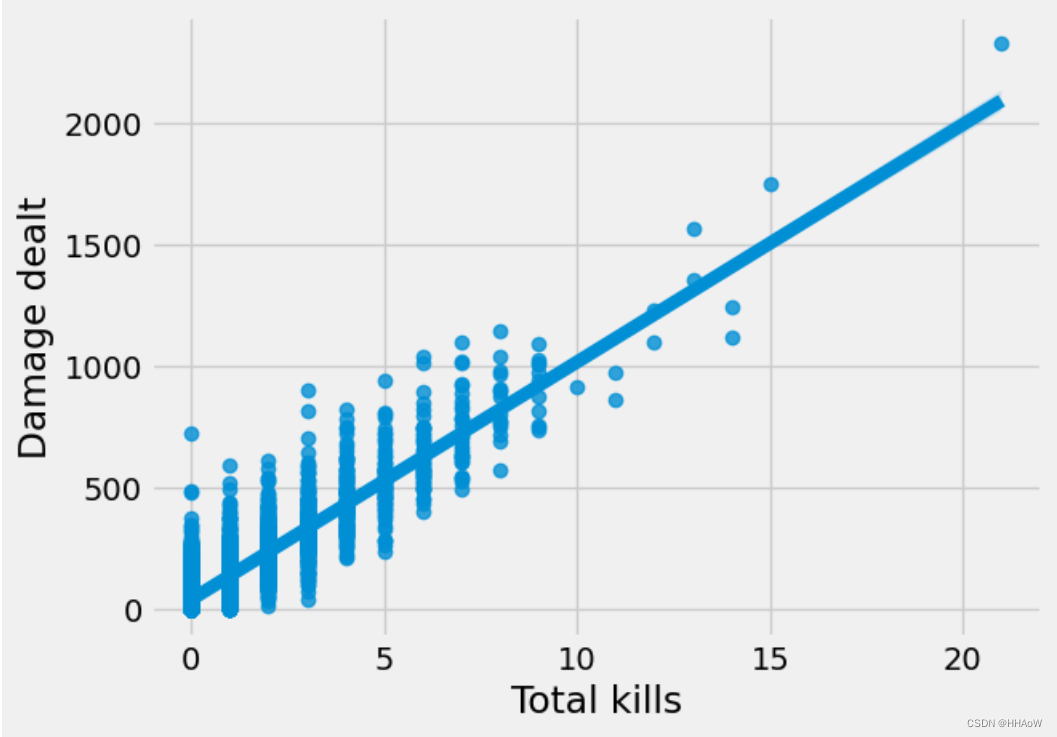
从上图可以看到,一个玩家杀死敌人的数量越多,自己所受到的伤害就越大,基本呈线性关系。
击杀敌人数量与排名的关系
现在分析一下玩家杀死敌人的数量与排名的关系。
data = df.copy()
# 将杀死敌人的数量分为 6 个部分。
data['kills_rank'] = pd.cut(data['kills'], [-1, 0, 2, 5, 10, 20, 60],
labels=['0_kills', '1-2_kills', '3-5_kills',
'6-10_kills', '11-20_kills', '20+kills'])
plt.figure(figsize=(10, 4))
sns.boxplot(x='kills_rank', y='winPlacePerc', data=data)
plt.show()
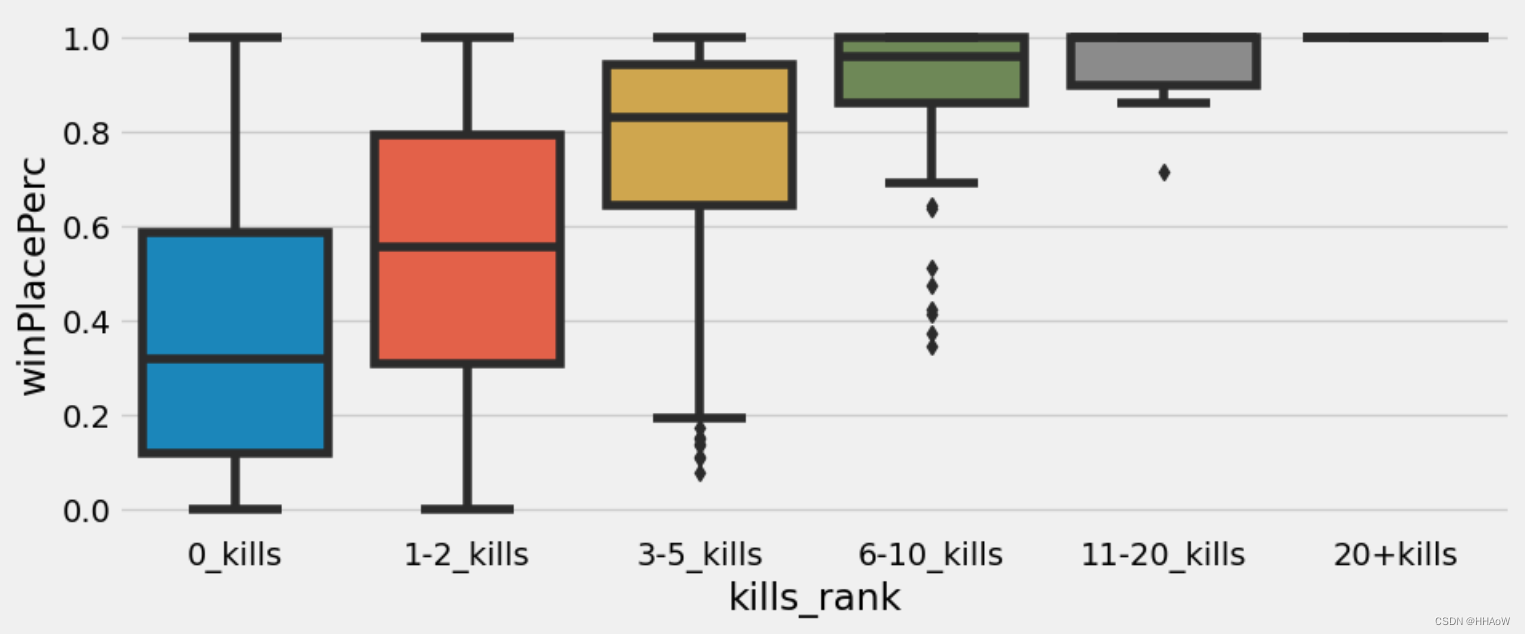
从上图可以看到,玩家杀死敌人的数量越多,其最后的排名也就越高。
一枪爆头数
再来看一下玩家在游戏中,一枪爆头的个数。
fig, (ax1, ax2) = plt.subplots(1, 2)
fig.set_figwidth(15)
sns.distplot(df['headshotKills'], ax=ax1)
sns.boxplot(df['headshotKills'], ax=ax2)
plt.show()
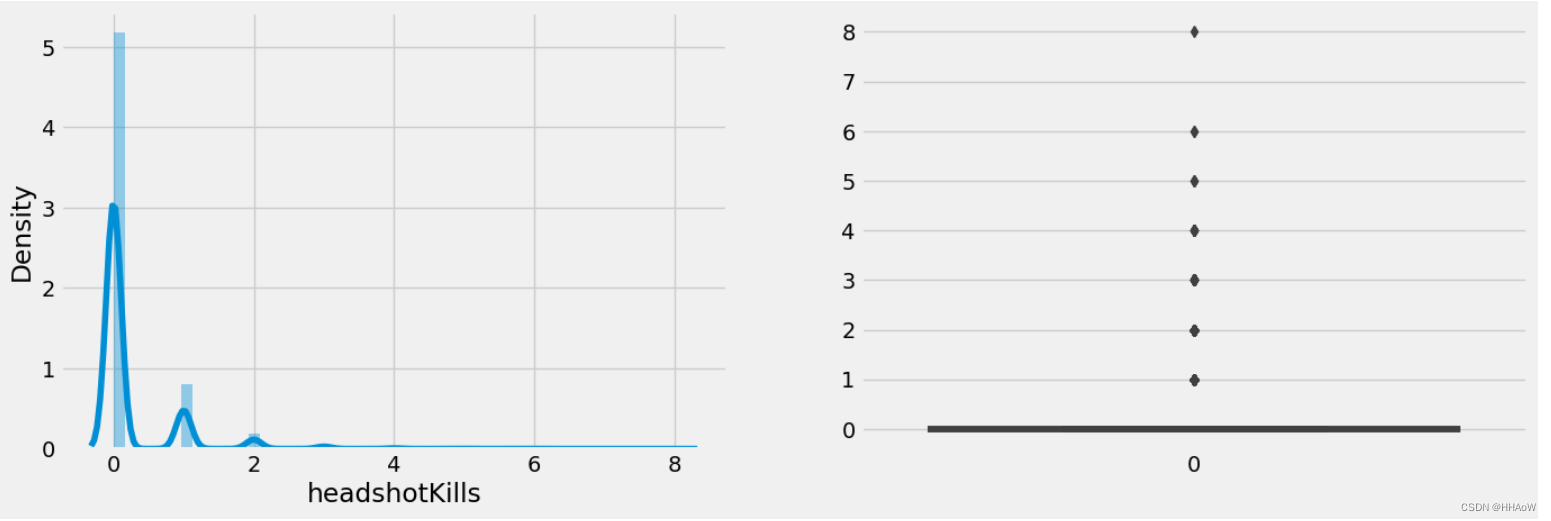
从上图可看到,大多数玩家都没有一枪爆头。但在右图中,有个别玩家一枪爆头的数量到达了 8 人。
爆头人数与排名的关系
现在看一下,爆头人数与排名之间的关系。
f, ax1 = plt.subplots(figsize=(14, 4))
sns.pointplot(x='headshotKills', y='winPlacePerc', data=df, alpha=0.8)
plt.xlabel('Number of headshotKills', fontsize=15, color='blue')
plt.ylabel('Win Percentage', fontsize=15, color='blue')
plt.title('headshotKills/ Win Ratio', fontsize=20, color='blue')
plt.grid()
plt.show()
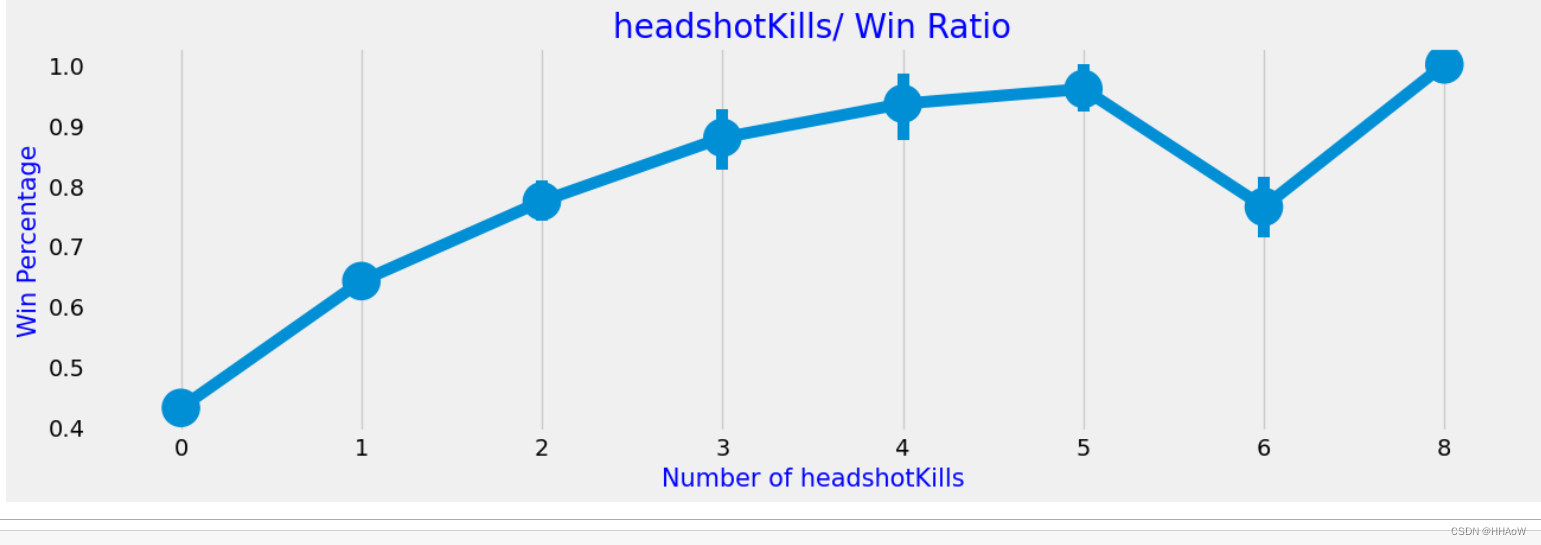
短时间击杀敌人
可以查看一下短时间内杀死敌人的数量。
killstreak = pd.DataFrame(df['killStreaks'].value_counts())
killstreak.iloc[4] = killstreak.iloc[4:].sum()
killstreak = killstreak[:5]
sns.barplot(killstreak.index, killstreak['killStreaks'])
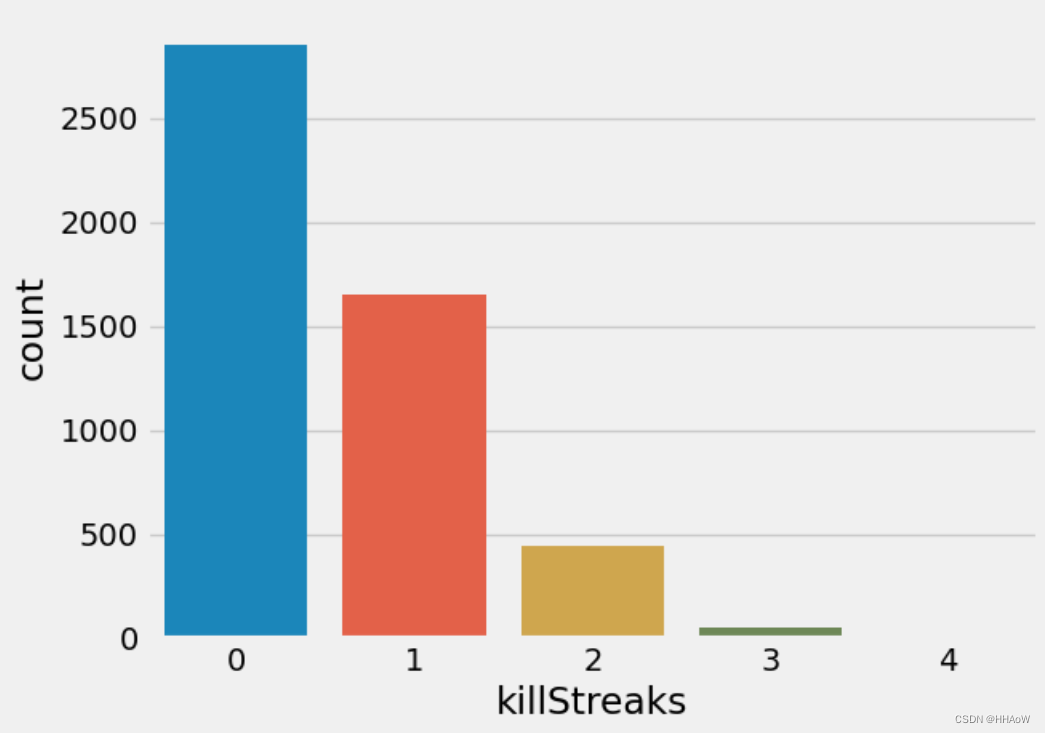
行近距离
接下来简单看一下玩家在一局游戏中行走的距离。在游戏中,角色的移动主要通过步行、游泳、和使用交通工具。现在可以通过对三者相加来求出玩家行走的距离。
data = df.copy()
data['move'] = data['rideDistance']+data['swimDistance']+data['walkDistance']
sns.distplot(data['move'])
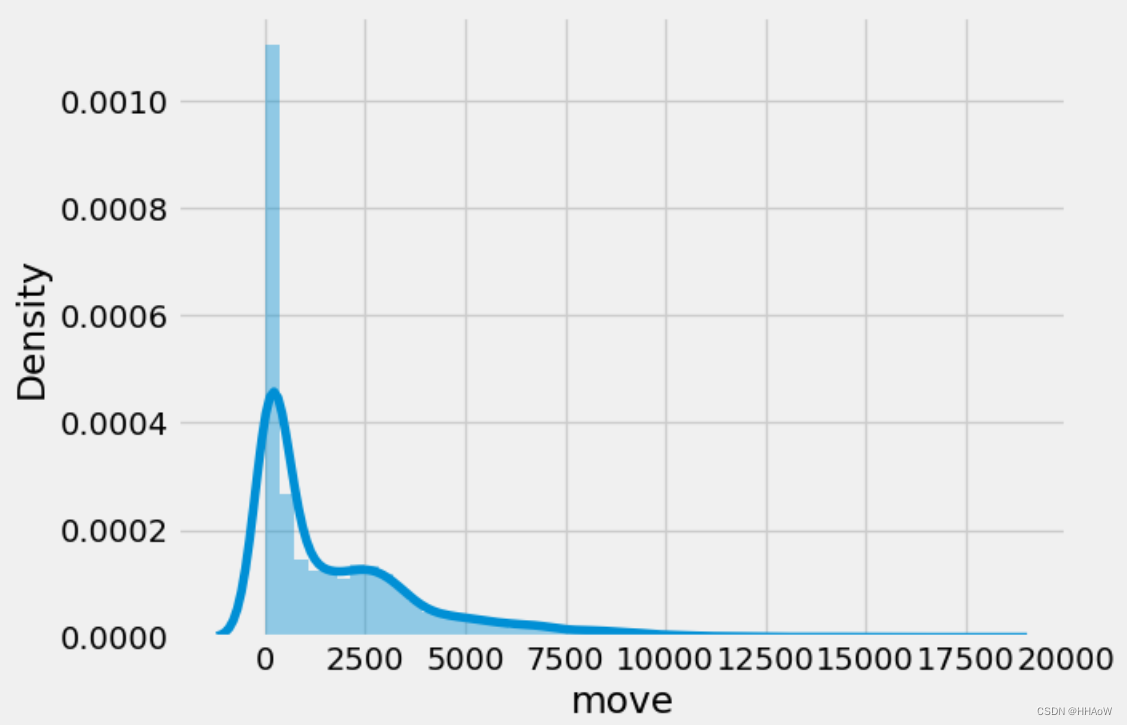
从上图可以看出,大多数玩家行走的距离都在 0 到 5000 区间。只有及其少部分玩家超过了 5000 。
行近距离与排名的关系
查看一下行走距离与排名之间的关系。
data = df.copy()
# 将距离划分为 6 个部分。
data['move'] = data['rideDistance']+data['swimDistance']+data['walkDistance']
data['move_rank'] = pd.cut(data['move'], [-1, 2000, 4000, 6000, 8000, 10000, 60000],
labels=['0_2000', '2000-4000', '4000-6000',
'6000-8000', '8000-10000', '10000+'])
plt.figure(figsize=(10, 4))
sns.boxplot(x='move_rank', y='winPlacePerc', data=data)
plt.show()
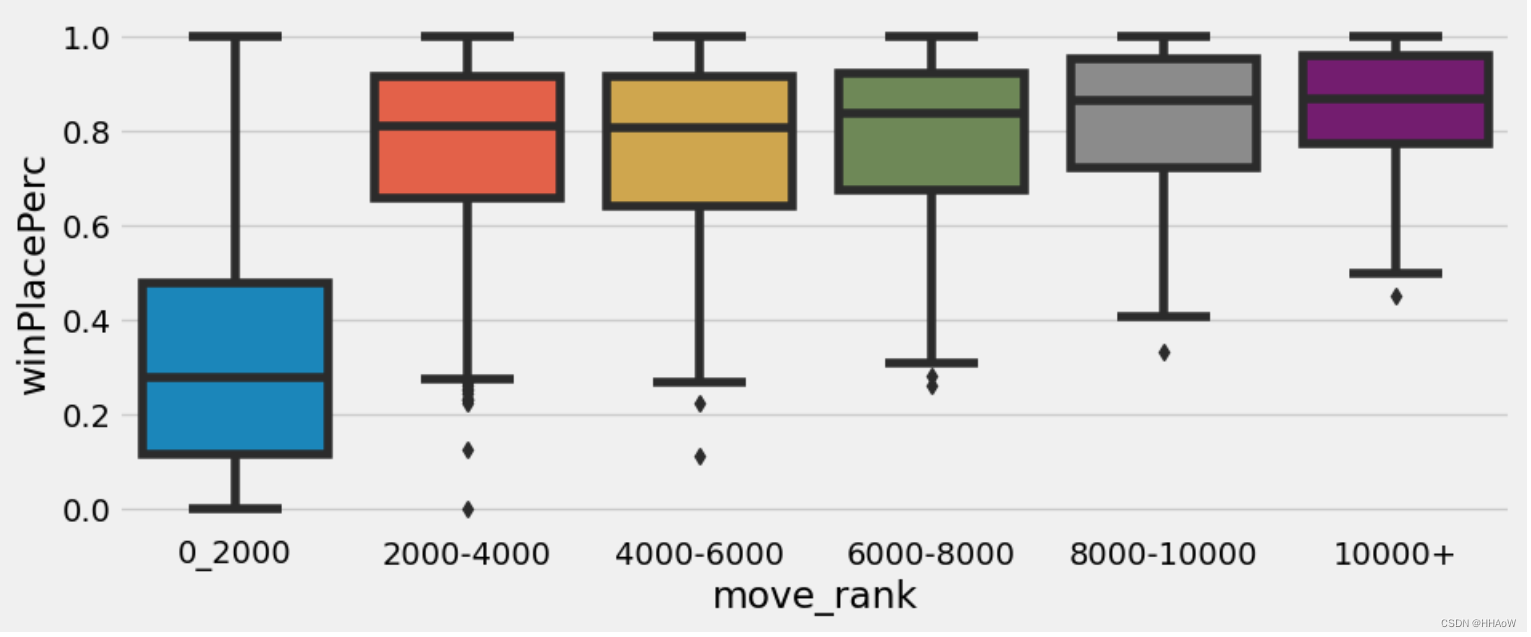
从上图可以看出,玩家行走的距离越远,排名也就越高。
捡枪数量
接下来来看捡枪的数量。
fig, (ax1, ax2) = plt.subplots(1, 2)
fig.set_figwidth(15)
sns.distplot(df['weaponsAcquired'], ax=ax1)
sns.boxplot(df['weaponsAcquired'], ax=ax2)
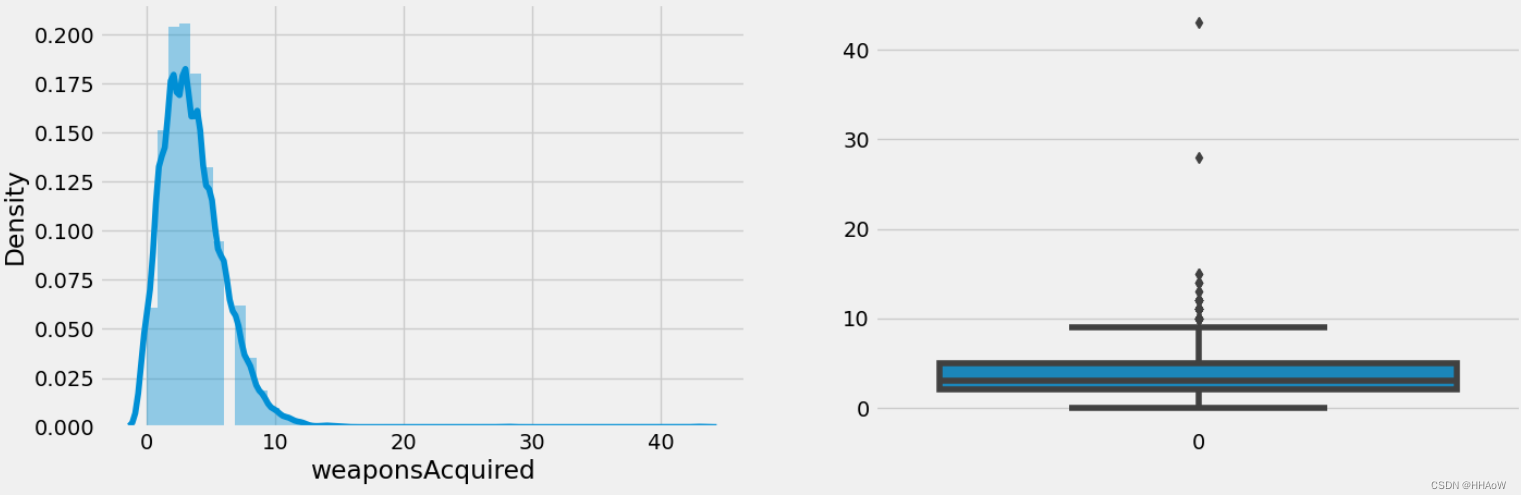
从上图可以看到,大多数玩家在游戏中捡枪的数量都没有超过 10 。但在右图中,有个别玩家捡枪的数量超过了 40。
捡枪数量与排名的关系
查看其与排名的关系。
f, ax1 = plt.subplots(figsize=(15, 5))
sns.pointplot(x='weaponsAcquired', y='winPlacePerc', data=df, alpha=0.8)
plt.xlabel('Number of weaponsAcquired', fontsize=15, color='blue')
plt.ylabel('Win Percentage', fontsize=15, color='blue')
plt.title('weaponsAcquired/ Win Ratio', fontsize=20, color='blue')
plt.grid()
plt.show()
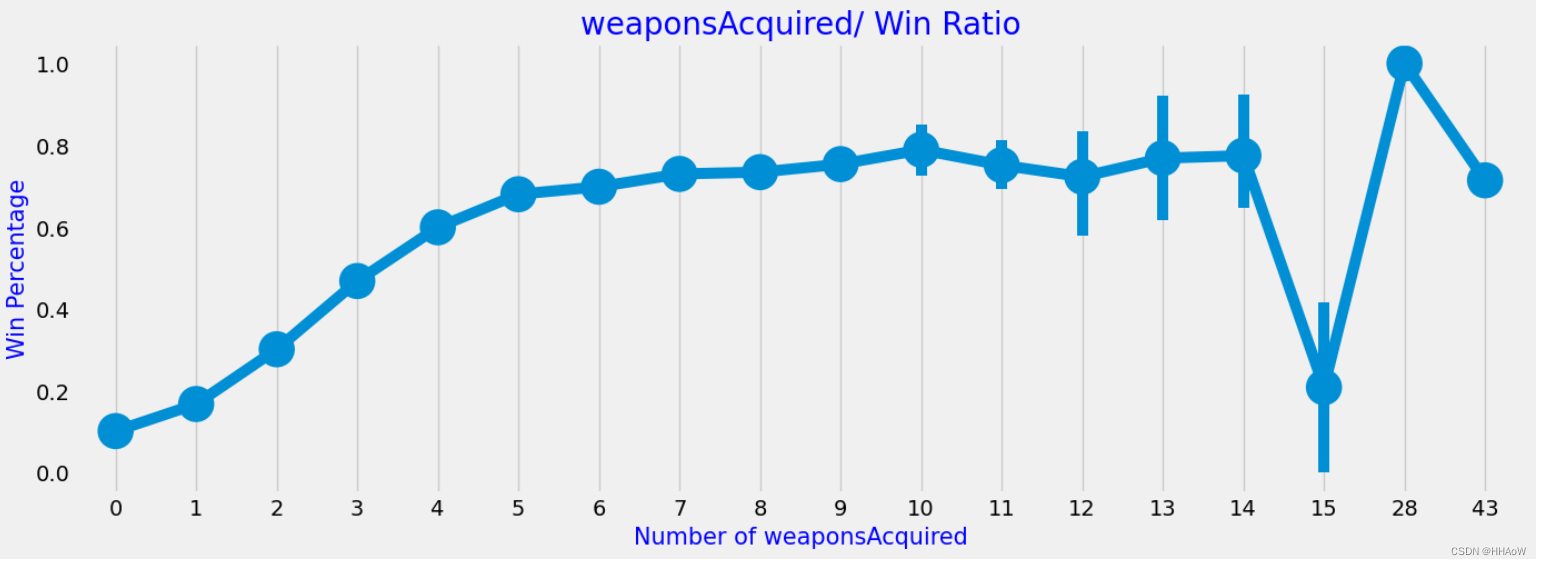
从上图可知,捡枪的数量与排名大致呈正比关系。
救援类物资
接下来看,使用救援类物质的数量与排名的关系,以及使用提升性物品的数量对排名的影响。
data = df.copy()
f, ax1 = plt.subplots(figsize=(14, 4))
sns.pointplot(x='heals', y='winPlacePerc', data=data, color='lime', alpha=0.8)
sns.pointplot(x='boosts', y='winPlacePerc', data=data, color='blue', alpha=0.8)
plt.text(0, 0.9, 'Heals', color='lime', fontsize=17, style='italic')
plt.text(0, 0.85, 'Boosts', color='blue', fontsize=17, style='italic')
plt.xlabel('Number of heal/boost items', fontsize=15, color='blue')
plt.ylabel('Win Percentage', fontsize=15, color='blue')
plt.title('Heals vs Boosts', fontsize=20, color='blue')
plt.grid()
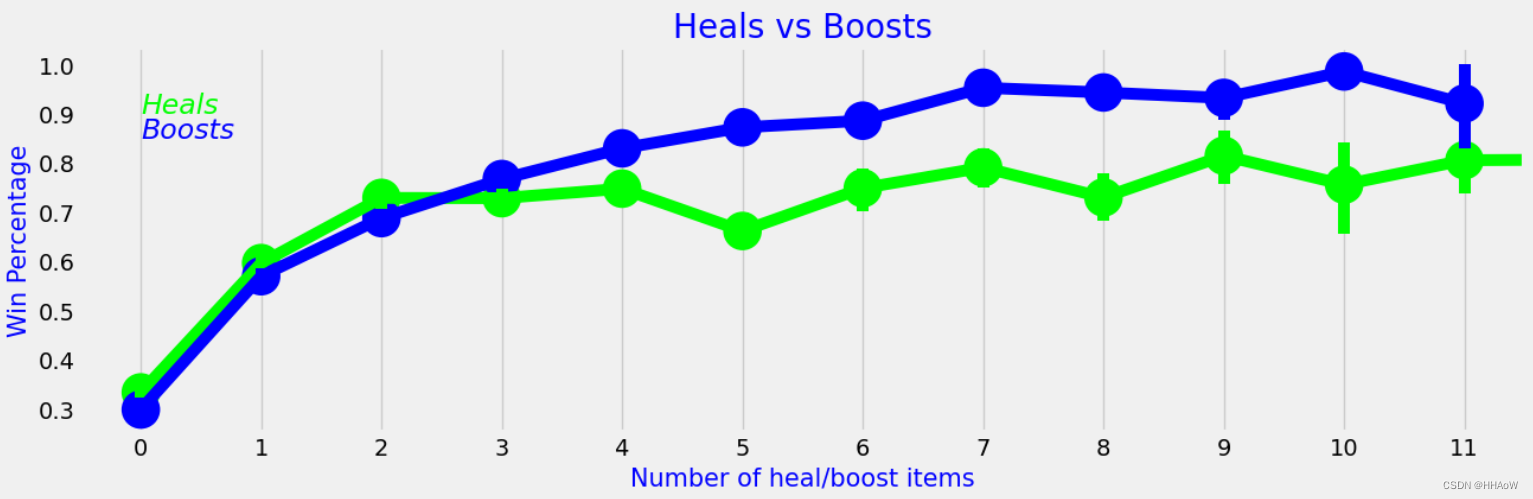
????????从上图可知,救援类物质的数量和使用提升性物品的数量对排名均有一定的影响,但是提升性物品的影响要略大于救援类物质的影响。这与事实是较为相符。
特征工程
????????上面只是对数据集中的一些特征列进行了可视化,以便更好的理解数据。而我们的任务是根据这些特征来预测玩家的排名。现在我们对数据进行手工提取特征。
????????救援类物品和提升性能类物品都可以算作是一类,因此将这两者加起来得到一个新的特征列。同样的方法对距离进行处理。
df['healsAndBoosts'] = df['heals']+df['boosts']
df['totalDistance'] = df['walkDistance']+df['rideDistance']+df['swimDistance']
????????当使用提升类物品时,游戏玩家可以运行得更快。同时也帮助玩家保持在区外。因此,我们可以创建一个特征列,用来记录游戏玩家没走一步所消耗的提升性物品。救援类物品虽然不会使玩家跑得更快,但也有助于保持远离危险地带。所以让我们也为救援类物品创建相同的特征列。
df['boostsPerWalkDistance'] = df['boosts'] / \
(df['walkDistance']+1) # 加 1 是为了防止分母为 0
df['boostsPerWalkDistance'].fillna(0, inplace=True)
df['healsPerWalkDistance'] = df['heals']/(df['walkDistance']+1)
df['healsPerWalkDistance'].fillna(0, inplace=True)
df['healsAndBoostsPerWalkDistance'] = df['healsAndBoosts'] / \
(df['walkDistance']+1)
df['healsAndBoostsPerWalkDistance'].fillna(0, inplace=True)
df[['walkDistance', 'boosts', 'boostsPerWalkDistance', 'heals',
'healsPerWalkDistance', 'healsAndBoosts', 'healsAndBoostsPerWalkDistance']][40:45]
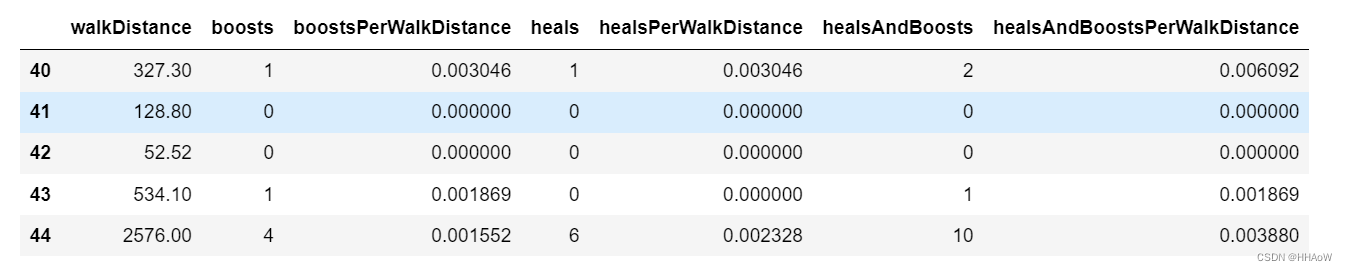
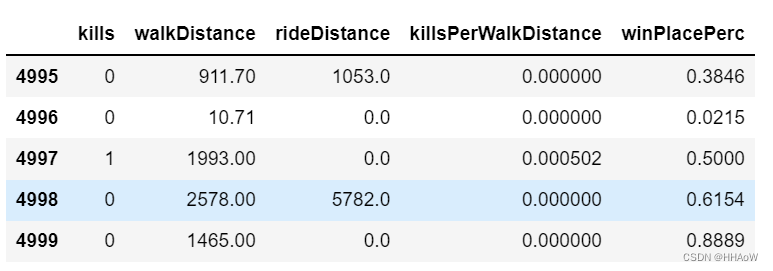
同样的方法,提取杀死敌人的数量与步行距离的关系。
df['killsPerWalkDistance'] = df['kills'] / \
(df['walkDistance']+1) # 加 1 是为了防止分母为 0
df['killsPerWalkDistance'].fillna(0, inplace=True)
df[['kills', 'walkDistance', 'rideDistance',
'killsPerWalkDistance', 'winPlacePerc']].tail(5)
构建模型
此时的数据包含 36 列。但玩家编号(Id)、分组编号(groupId)、游戏局编号(matchId)、游戏的类型(matchType)对预测结果是没有帮助的。因此现在将这四列删除掉。
df_drop = df.drop(['Id', 'groupId', 'matchId', 'matchType'], axis=1)
划分训练集和测试集。
from sklearn.model_selection import train_test_split
data_X = df_drop.drop(['winPlacePerc'], axis=1)
data_y = df_drop['winPlacePerc']
train_X, test_X, train_y, test_y = train_test_split(
data_X, data_y.values, test_size=0.1)
构建预测模型。这里我们使用随机森林回归的方法来构建模型。模型训练耗时约 2 分钟。
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor(n_estimators=40) # 构建模型
model.fit(train_X, train_y) # 训练模型
y_pred = model.predict(test_X) # 预测
y_pred[:10]

????????上面我们完成了预测模型的构建预训练,并对测试集进行预测。为了直观的看出模型预测的好坏,现在通过画图的方法来对比。
f, ax1 = plt.subplots(figsize=(15, 5))
plt.plot(test_y[:100])
plt.plot(y_pred[:100])
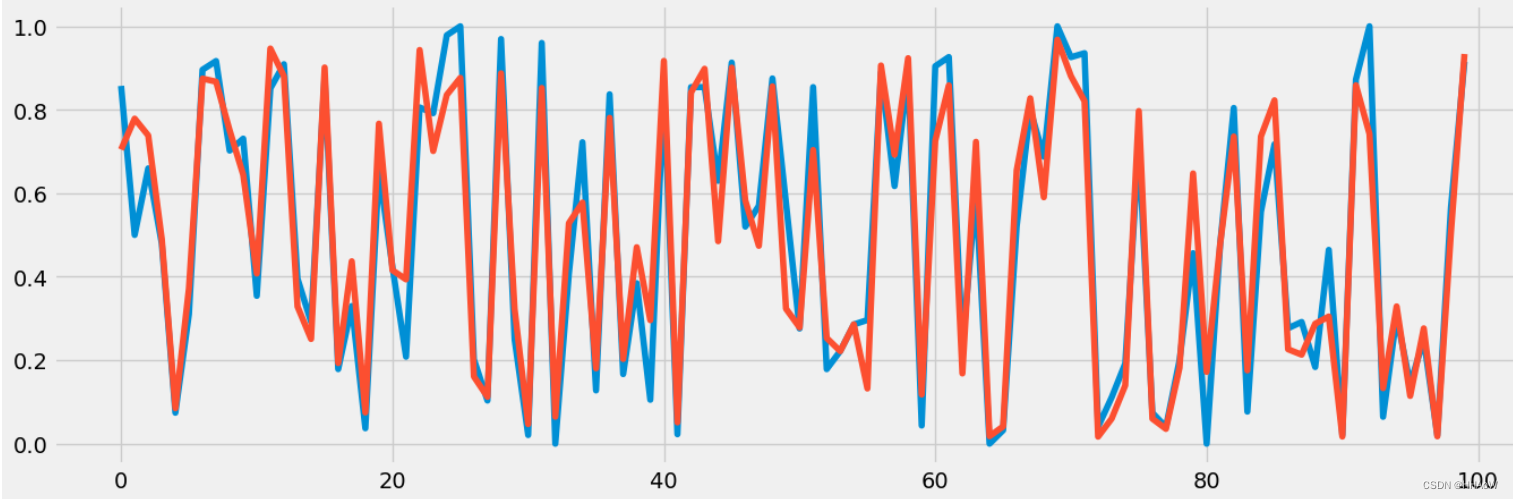
????????在上图中,蓝色线条表示测试数据的真实值,而红色线条表示预测的数据。从图中可以看出,我们所构建的模型基本能够预测正确。现在查看一下均方误差。
from sklearn.metrics import mean_squared_error
mean_squared_error(y_pred, test_y)
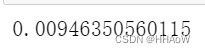
实验总结
????????本次分析主要是对绝地求生的数据进行分析,主要分析的是玩家的各种行为对游戏最终排名的影响。因为本次实验所使用的的数据都相对干净,因此省去了许多复杂的数据预处理操作。但为了能够使预测效果更好,实验中也提取了一些新的特征。最后选择随机森林模型来预测。当然,如果你有兴趣,你也可以使用其他的回归方法来进行预测。
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- linux vim命令操作汇总
- STM32WB55开发(6)----FUS更新
- 直播带货2024:洗牌、阵痛和暗流涌动
- 期货日数据维护与使用_日数据维护_模块运行演示
- 【昕宝爸爸小模块】浅谈之创建线程的几种方式
- 任务8:安装大数据统计分析工具Hive
- Azure VM安装docker
- kotlin filter 过滤集合(filterIndexed,filterNot,filterIsInstance,filterNotNull)
- Linux软件包管理器yum
- 分布式(9)