[论文阅读]Self-Supervised Learning for Videos: A Survey
Schiappa, M. C., Rawat, Y. S., & Shah, M. (2023). Self-Supervised Learning for Videos: A Survey. ACM Comput. Surv., 55(13s), 1–37. https://doi.org/10.1145/3577925
论文中文名称:视频的自监督学习综述
摘要:
深度学习在各个领域取得的显著成功依赖于大规模标注数据集的可用性。然而,获取标注是昂贵且需要巨大努力的,特别是对于视频而言更是具有挑战性。此外,使用人工生成的标注会导致模型学习偏见,并且在领域泛化和稳健性方面效果较差。作为替代方案,自监督学习提供了一种无需标注的表示学习方法,在图像和视频领域都显示出了潜力。与图像领域不同,学习视频表示更具挑战性,因为涉及到时间维度,引入了运动和其他环境动态。这也为在视频和多模态领域推进自监督学习提供了机会。在这份综述中,我们回顾了关于自监督学习在视频领域的现有方法。我们将这些方法总结为四个不同的类别,基于它们的学习目标:(1) 先导任务,(2) 生成式学习,(3) 对比学习,和 (4) 跨模态一致性。我们进一步介绍了常用的数据集、下游评估任务、对现有工作局限性的见解,以及这一领域的潜在未来方向。
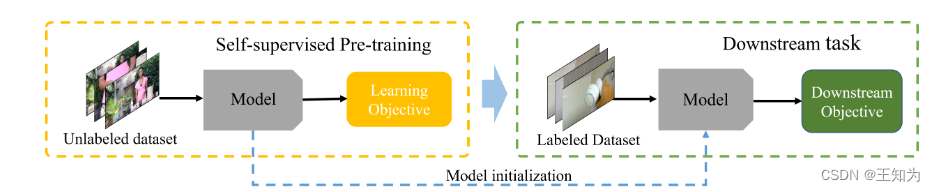
图1:使用通过自监督学习训练的预训练模型进行下游任务的示意图。该过程始于在无标签数据集上使用自监督学习目标对模型进行预训练。一旦训练完成,学到的权重被用作下游任务上一个较小的带标签数据集的模型初始化。
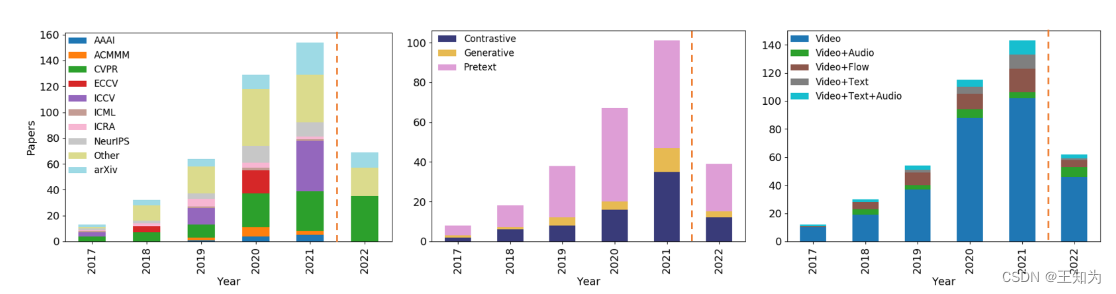
图2:近年来自监督(SSL)视频表示学习研究的统计数据。从左到右,我们显示a) 在顶级会议场馆发表的与SSL相关的论文总数,b) 对SSL研究的主要研究主题进行的分类统计,和c) SSL中使用的主要模态的模态分类统计。2022年仍然不完整,因为大多数会议发生在年底。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 架构与思维:如何应对Redis热Key?
- vue前端开发自学基础,动态切换组件的显示
- TP-GMM
- linux工具脚本
- 传统软件集成AI大模型——Function Calling
- new Promise(resolve => setTimeout(resolve, 5000))
- API接口大全
- 鸿蒙实现年月日十分选择框,支持年月日、月日、日、年月日时分、时分切换
- 1688商品数据API接口调用key和密钥
- SpringBoot打造高效多级缓存体系