设计模式——原型模式(Prototype Pattern)
概述
?????? 原型模式(Prototype? Pattern):使用原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象。原型模式是一种对象创建型模式。原型模式的工作原理很简单:将一个原型对象传给那个要发动创建的对象,这个要发动创建的对象通过请求原型对象拷贝自己来实现创建过程。由于在软件系统中我们经常会遇到需要创建多个相同或者相似对象的情况,因此原型模式在真实开发中的使用频率还是非常高的。原型模式是一种“另类”的创建型模式,创建克隆对象的工厂就是原型类自身,工厂方法由克隆方法来实现。
?????? 需要注意的是通过克隆方法所创建的对象是全新的对象,它们在内存中拥有新的地址,通常对克隆所产生的对象进行修改对原型对象不会造成任何影响,每一个克隆对象都是相互独立的。通过不同的方式修改可以得到一系列相似但不完全相同的对象。原型模式的结构如图所示:
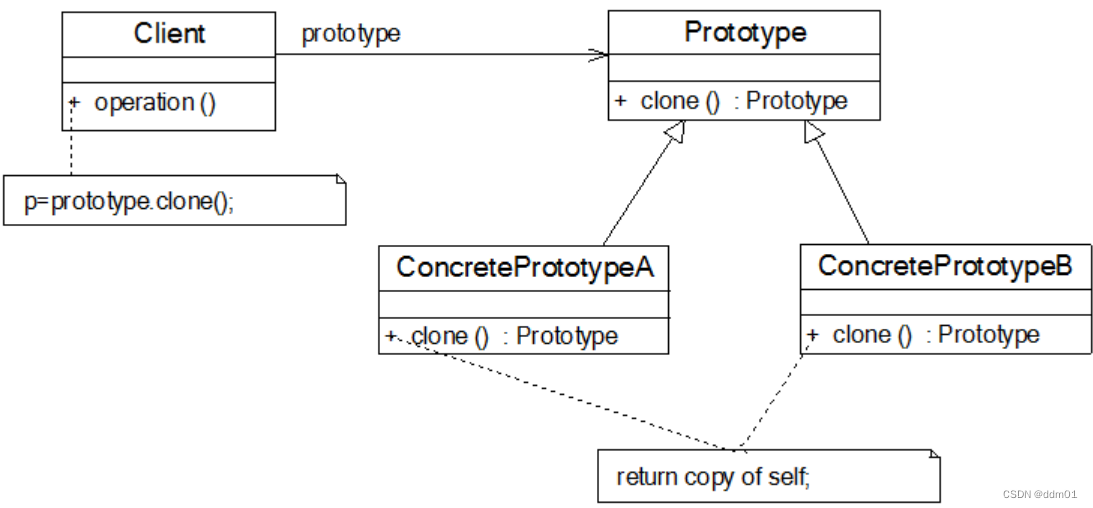
在原型模式结构图中包含如下几个角色:
????? ●Prototype(抽象原型类):它是声明克隆方法的接口,是所有具体原型类的公共父类,可以是抽象类也可以是接口,甚至还可以是具体实现类。
????? ● ConcretePrototype(具体原型类):它实现在抽象原型类中声明的克隆方法,在克隆方法中返回自己的一个克隆对象。
????? ● Client(客户类):让一个原型对象克隆自身从而创建一个新的对象,在客户类中只需要直接实例化或通过工厂方法等方式创建一个原型对象,再通过调用该对象的克隆方法即可得到多个相同的对象。由于客户类针对抽象原型类Prototype编程,因此用户可以根据需要选择具体原型类,系统具有较好的可扩展性,增加或更换具体原型类都很方便。
简单实现
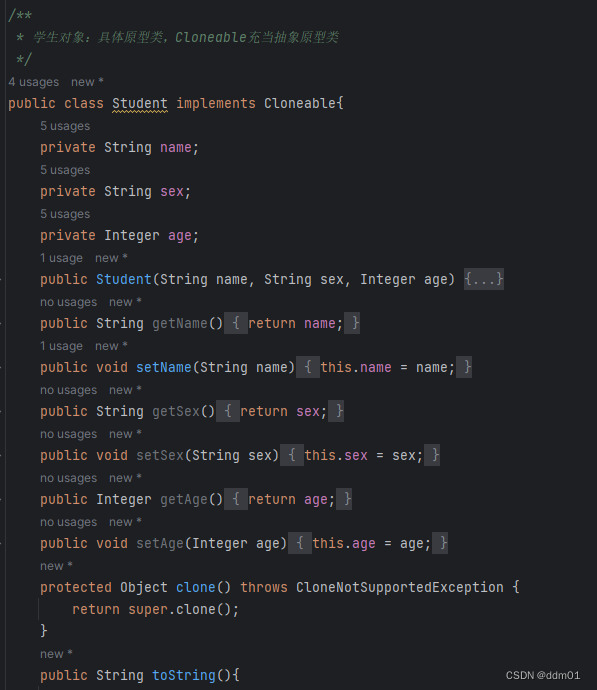
编译并运行如下:
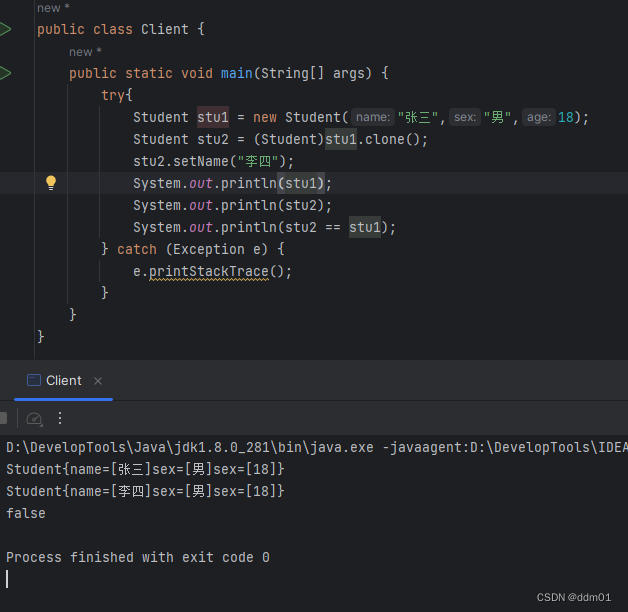
可以看到,把一个学生复制过来,只是改了姓名而已,其他属性完全一样没有改变,但是它们的内存地址发生了变化,说明克隆出了一个新的对象。需要注意的是,一定要在被拷贝的对象上实现Cloneable接口,否则会抛出CloneNotSupportedException异常。
浅克隆
?????? 创建一个新对象,新对象的属性和原来对象完全相同,对于非基本类型属性,仍指向原有属性所指向的对象的内存地址。代码及示例如下:
Student对象同上
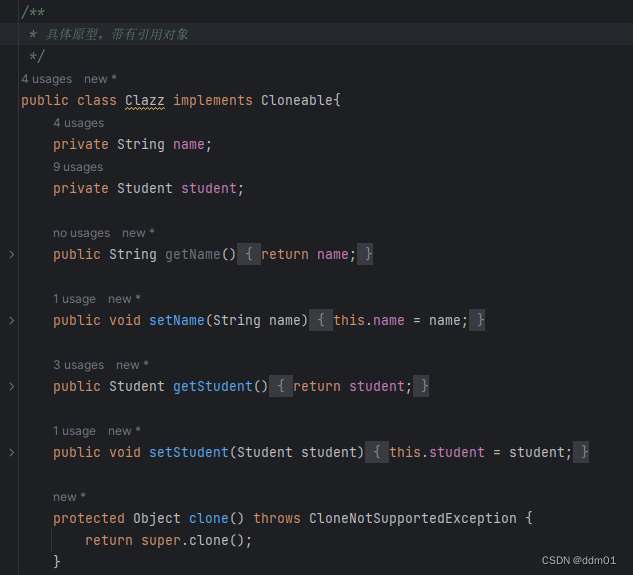
编译并运行如下:
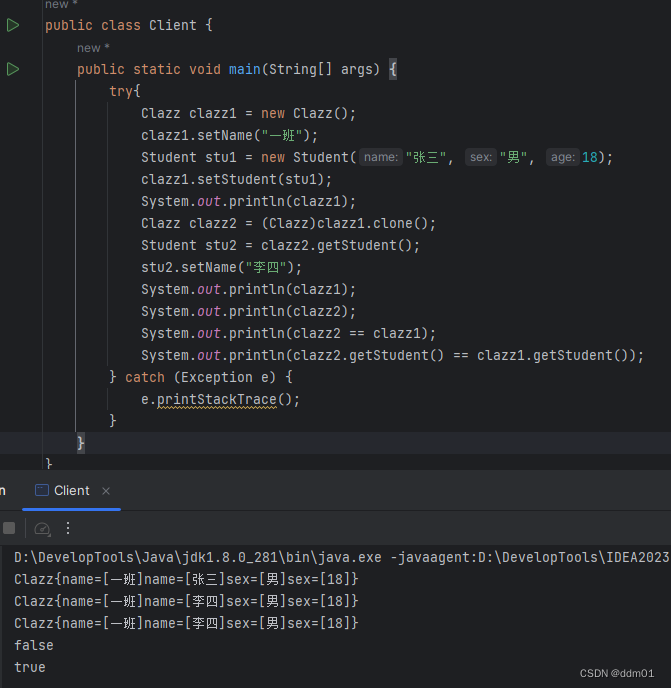
可以看到,当修改了stu2的姓名时,stu1的姓名同样也被修改了,这说明stu1和stu2是同一个对象,这就是浅克隆的特点,对具体原型类中的引用类型的属性进行引用的复制。同时,这也可能是浅克隆所带来的弊端,因为结合该例子的原意,显然是想在班级中新增一名叫李四的学生,而非让所有的学生都改名叫李四,于是我们这里就要使用深克隆。
深克隆
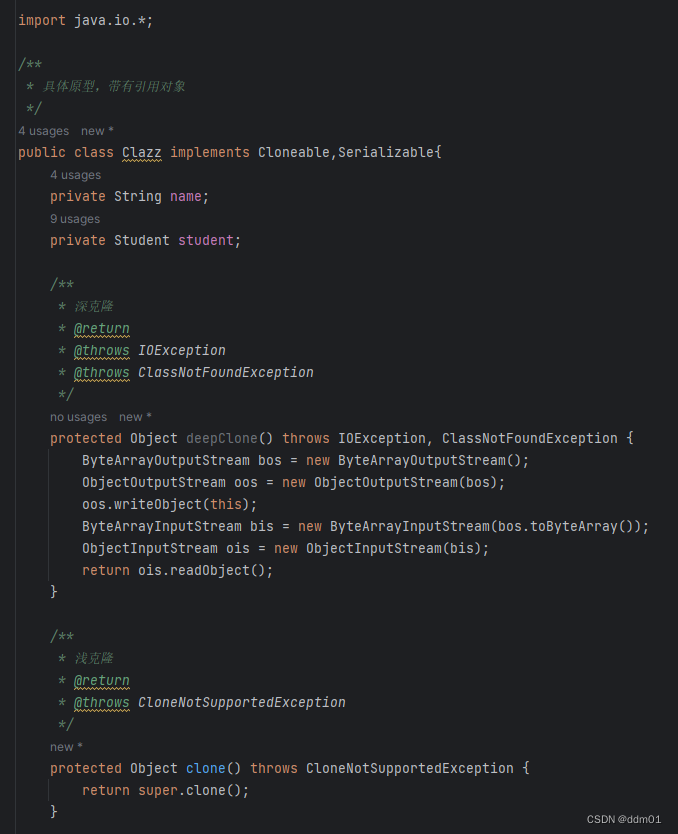
创建一个新对象,属性中引用的其他对象也会被克隆,不再指向原有对象地址。代码及示例如下:
编译并运行如下:
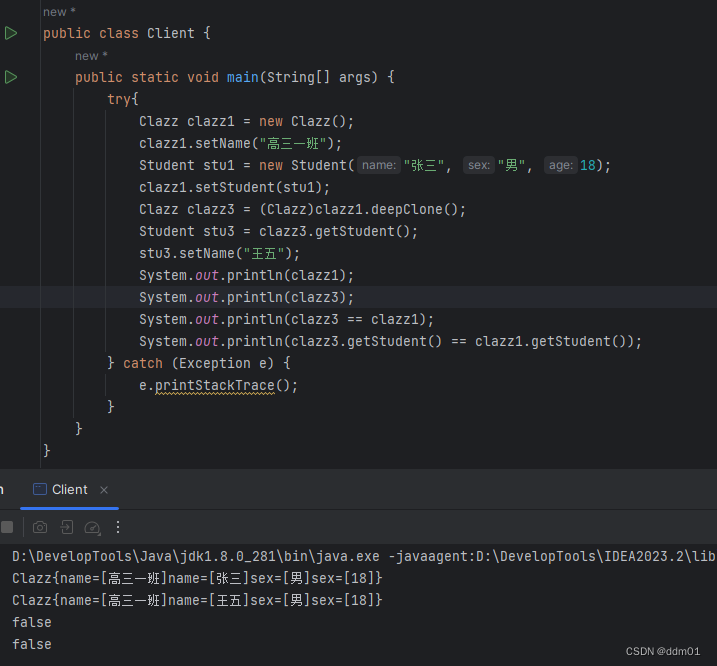
可以看到,当修改了stu3的姓名时,stu1的姓名并没有被修改了,这说明stu3和stu1已经是不同的对象了,说明Clazz中的Student也被克隆了,不再指向原有对象地址,这就是深克隆。这里需要注意的是,Clazz类和Student类都需要实现Serializable接口,因为深克隆是基于流的实现方式,否则会抛出NotSerializableException异常。
克隆对单例模式的破坏
?????? 从以上的例子中可以看到,克隆出的对象的地址都不相同,即产生了新的对象,如果对原型对象既要做单例又要做克隆,那可要权衡一下利弊,即使重写clone方法返回原对象,使之保证对象唯一,那再修改克隆出来的对象则不可以重新修改里面的属性,因为修改以后就会连同克隆对象一起被修改,所以是需要单例还是克隆,在实际应用中需要好好衡量。
总结
适用场景:
- 类初始化消耗资源较多。
- new产生的一个对象需要非常繁琐的过程(数据准备、访问权限等)。
- 构造函数比较复杂。
??? 循环体中生产大量对象时。
优点:
- 性能优良,Java自带的原型模式是基于内存二进制流的拷贝,比直接new一个对象性能上提升了许多。
- 可以使用深克隆方式保存对象的状态,使用原型模式将对象复制一份并将其状态保存起来,简化了创建的过程。
缺点:
- 必须配备克隆(或者可拷贝)方法。
- 当对已有类进行改造的时候,需要修改代码,违反了开闭原则。
- 深克隆、浅克隆需要运用得当。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- uniapp+vue开发微信小程序,image标签图片IOS可以正常回显,安卓回显不出
- 金智维KRPA问题集锦
- 路由器原理
- 美易平台:东方甄选或与TikTok合作,开拓海外市场
- Python PyInstaller安装和使用教程(详解版)
- 为何软件开发时需要性能测试工具
- 雷盛红酒分享葡萄酒在冬天如何运输和保存
- 2024年六西格玛证书高效备考计划 - 张驰课堂深度解析
- 第一章 引言-HTTP协议基础概念和前后端分离架构请求交互概述
- 嵌入式实时操作系统的设计与开发——移植内核