MYSQL练题笔记-子查询-电影评分
一、题目相关内容
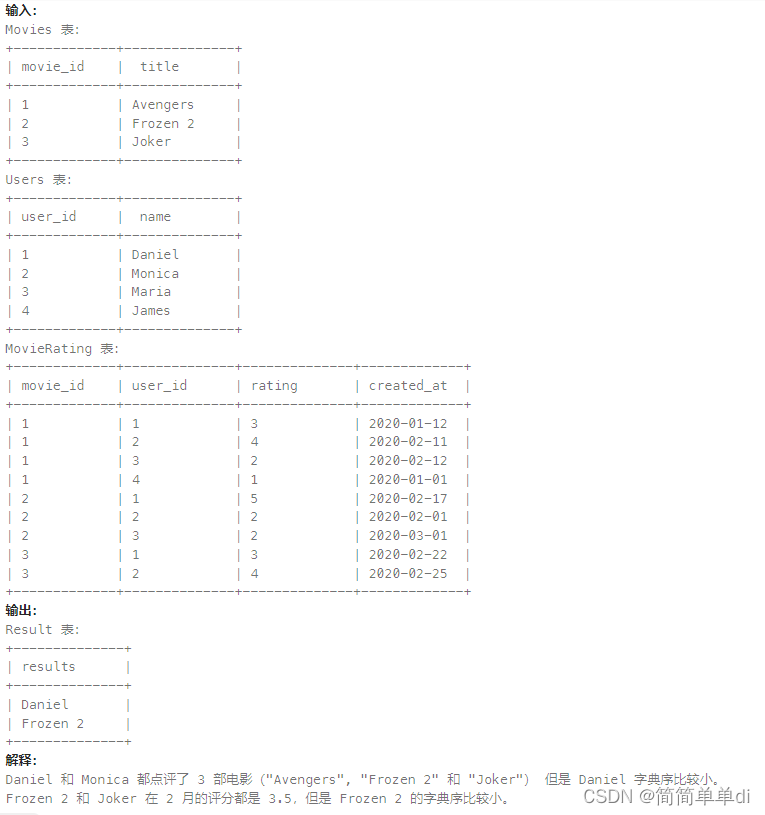
1)相关的表

2)题目

3)帮助理解题目的示例,提供返回结果的格式
二、自己初步的理解
1.字典序是指从前到后比较两个字符串大小的方法。 首先比较第1个字符,如果不同则第1个字符较小的字符串更小,一直这样子比较下去。 比如:s1:ABCDE 和 s2:ABCCE 两个字符串,s1的 D 比 s2的 C要更加大一点,所以s1 > s2。
然后百度到这些的时候我还以为要用到字符串比较的数据。
2.(movie_id, user_id)是唯一值那就是说一个用户只能评论一个电影一次呗,感觉要是是真实情况这样应该是不行的。
3.我思考是认为先解决第一个问题,评论电影数量最多的用户名,但是如果相等,就返回字典序较小的用户名;主要是我对这个部分完全想不到怎么写,所以我还是打算看题解了,我丢居然只需要order by,根本不需要max(),是我该学习啊。
三、题解展示和分析
题解如下,这样分组看比较有可读性。
# 评论电影数量最多且字典序较小的用户名
SELECT sub.name AS results
FROM( SELECT u.name
FROM Users u
JOIN MovieRating mr ON u.user_id = mr.user_id
GROUP BY 1
ORDER BY COUNT(*) DESC, 1
LIMIT 1) sub
UNION ALL
# 2020年2月份平均评分最高且字典序较小的电影名
(SELECT title
FROM Movies m
JOIN MovieRating mr ON m.movie_id = mr.movie_id AND created_at BETWEEN '2020-02-01' AND '2020-02-29'
GROUP BY 1
ORDER BY AVG(rating) DESC, 1
LIMIT 1)
1.既然是用union就先解决第一个问题-评论电影数量最多且字典序较小的用户名
1)这里利用子查询,没有直接查询name,可能是考虑了union里面不能order by 但是子句里可以,但是union all后面的查询语句不在子句里啊,我也不知道为啥能成功,在此留个疑问吧。
2)然后利用自连接把用户名和用户评分表连接起来。
3)然后group by 1就是根据第一列分组,也就是user_id这一列,如果自连接的时候user表放后面就不能这样使用了。
4)Order by 1指的是按select的第一个字段排序,通过order by 进行排序,根据count(*)降序即可,根本不用利用max()。
5)然后利用limit 输出第一条记录即可。
2.然后要使用union all因为有可能电影名和用户名是相同的,所以使用union的时候要思考和判断一下是否要加all
3.解决第二个问题-2020年2月份平均评分最高且字典序较小的电影名
其实这个总的结构和解决第一个问题是差不多的,只是多了个where条件限制在2020年2月份,然后要想到可以利用avg()进行排序,那这个问题就解决了。
四、总结
1.字典序是指从前到后比较两个字符串大小的方法;
2.日期范围可以利用between and或者<= 和>;
3.只需要输出某个值最大的时候可以用排序加上limit 1。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【漏洞复现】Apache Struts CVE-2023-50164
- 【Spark精讲】Spark内存管理
- 用ImageJ处理高斯光束的光斑
- JS 为什么0==““ 会是true
- 1962. 移除石子使总数最小 --力扣 --JAVA
- vm&windowa server2008
- TypeScript
- Python3,Pyecharts,我不会说这是一个不可多得的库。
- 电平设计基础:LVDS&CML 电平
- mysql的索引原理