数据结构:LRU Cache
发布时间:2023年12月18日
什么是LRU Cache
LRU是Least Recently Used的缩写,意思是最近最少使用,它是一种Cache替换算法。 什么是Cache?狭义的Cache指的是位于CPU和主存间的快速RAM, 通常它不像系统主存那样使用DRAM技术,而使用昂贵但较快速的SRAM技术。 广义上的Cache指的是位于速度相差较大的两种硬件之间, 用于协调两者数据传输速度差异的结构。除了CPU与主存之间有Cache, 内存与硬盘之间也有Cache,乃至在硬盘与网络之间也有某种意义上的Cache── 称为Internet临时文件夹或网络内容缓存等。

Cache的容量有限,因此当Cache的容量用完后,而又有新的内容需要添加进来时, 就需要挑选并舍弃原有的部分内容,从而腾出空间来放新内容。LRU Cache 的替换原则就是将最近最少使用的内容替换掉。其实,LRU译成最久未使用会更形象, 因为该算法每次替换掉的就是一段时间内最久没有使用过的内容
LRU Cache的实现
实现LRU Cache的方法和思路很多,但是要保持高效实现O(1)的put和get,那么使用双向链表和哈希表的搭配是最高效和经典的。使用双向链表是因为双向链表可以实现任意位置O(1)的插入和删除,使用哈希表是因为哈希表的增删查改也是O(1)
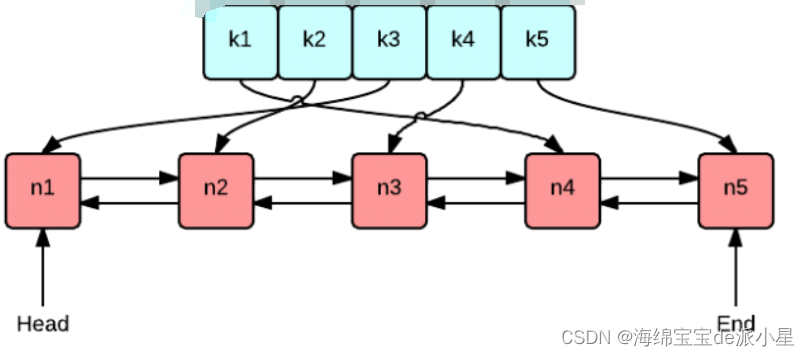
LRU缓存

对于底层逻辑来说,哈希表是必不可少的其次要考虑的是如何找最后一次使用的节点,这里可以借助一个链表来实现
每当使用了一个数据的时候就把这个数据加到最前面,那么链表最后的节点就是最久没有使用的内容了
但是又面临的问题是如何精准的定位到需要更改的位置,因此又需要一个迭代器
因此对于哈希表来说,需要存储的内容多了一个这个元素在链表中的定位,因此哈希表中要存储三个内容
1、Key值 2、Value值 3、Key值在链表中的索引
class LRUCache
{
public:
LRUCache(int capacity)
:_capacity(capacity)
{}
int get(int key)
{
// 对于要得到一个元素,在这个题中需要两步走
// 1、找这个元素
// 2、更换这个元素在链表中的位置
auto it = _HashMap.find(key);
if(it != _HashMap.end())
{
// 说明此时找到了,更新它在链表中的位置
// 这里使用的是list中的一个splice函数
// void splice (iterator position, list& x, iterator i);
auto listit = it->second.second;
pair<int, int> kv = *listit;
_lt.splice(_lt.begin(), _lt, listit);
return kv.second;
}
else
{
return -1;
}
}
void put(int key, int value)
{
// 对于put函数来说有两种场景
// 1、替换
// 2、新增
auto it = _HashMap.find(key);
if(it != _HashMap.end())
{
// 替换
it->second.second->second = value;
auto listit = it->second.second;
_lt.splice(_lt.begin(), _lt, listit);
return;
}
else
{
// 新增:有可能会超过缓存中的容量,此时需要清除缓存中最后一个使用的元素,再新增一个新的元素
if(_lt.size() == _capacity)
{
_HashMap.erase(_lt.back().first);
_lt.pop_back();
}
_lt.push_front(make_pair(key, value));
_HashMap[key] = make_pair(value, _lt.begin());
}
}
private:
// 对于底层逻辑来说,哈希表是必不可少的
// 其次要考虑的是如何找最后一次使用的节点,这里可以借助一个链表来实现
// 每当使用了一个数据的时候就把这个数据加到最前面,那么链表最后的节点就是最久没有使用的内容了
// 但是又面临的问题是如何精准的定位到需要更改的位置,因此又需要一个迭代器
// 因此对于哈希表来说,需要存储的内容多了一个这个元素在链表中的定位,因此哈希表中要存储三个内容
// 1、Key值 2、Value值 3、Key值在链表中的索引
// 因此设计的模式采用下面的设计模式
unordered_map<int, pair<int, list<pair<int, int>>::iterator>> _HashMap;
list<pair<int, int>> _lt;
int _capacity;
};
/**
* Your LRUCache object will be instantiated and called as such:
* LRUCache* obj = new LRUCache(capacity);
* int param_1 = obj->get(key);
* obj->put(key,value);
*/
文章来源:https://blog.csdn.net/qq_73899585/article/details/135066943
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 移动应用开发:揭秘内侧APP封装台的高效
- KBDSL1.DLL文件丢失,软件或游戏无法启动,快速修复方法
- C++系列十一:C++指针
- 【HarmonyOS】深入了解 ArkUI 的动画交互以提高用户体验
- [论文阅读笔记28] 对比学习在多目标跟踪中的应用
- 记一次使用mpvue开发微信小程序动画播放播放完成再播放下一个动画,实现动画队列的实战操作
- 关于分页查询的基础案例
- Python实现员工管理系统(Django页面版 ) 八
- VUE3使用Echarts图表
- Java HashMap在遍历时删除元素