爬虫工作量由小到大的思维转变---<第三十五章 Scrapy 的scrapyd+Gerapy 部署爬虫项目>
发布时间:2023年12月30日
前言:
项目框架没有问题大家布好了的话,接着我们就开始部署scrapy项目(没搭好架子的话,看我上文爬虫工作量由小到大的思维转变---<第三十四章 Scrapy 的部署scrapyd+Gerapy>-CSDN博客)
正文:
1.创建主机:
首先gerapy的架子,就相当于部署服务器上的;所以,我们先要连接主机(用户名/密码随你填不填)
----ps:我建议你填一下子,养成习惯;别到时候布到云服务上去了,被人给扫了,那不好玩的!
这里ip就填 127.0.0.1 ,端口6800 --->就是你scrapyd的端口!

创建完成,应该会是这样的:
此时他说你的主机没连接上,为啥?
-----因为这是个基于scrapyd的可视化网页架子,你不开scrapyd服务,他基于啥给你可视化?
所以...
2.开启scrapyd服务
(本地127.0.0.1的不用调设置哈,直接开! 布云端服务器以后会另外说的)
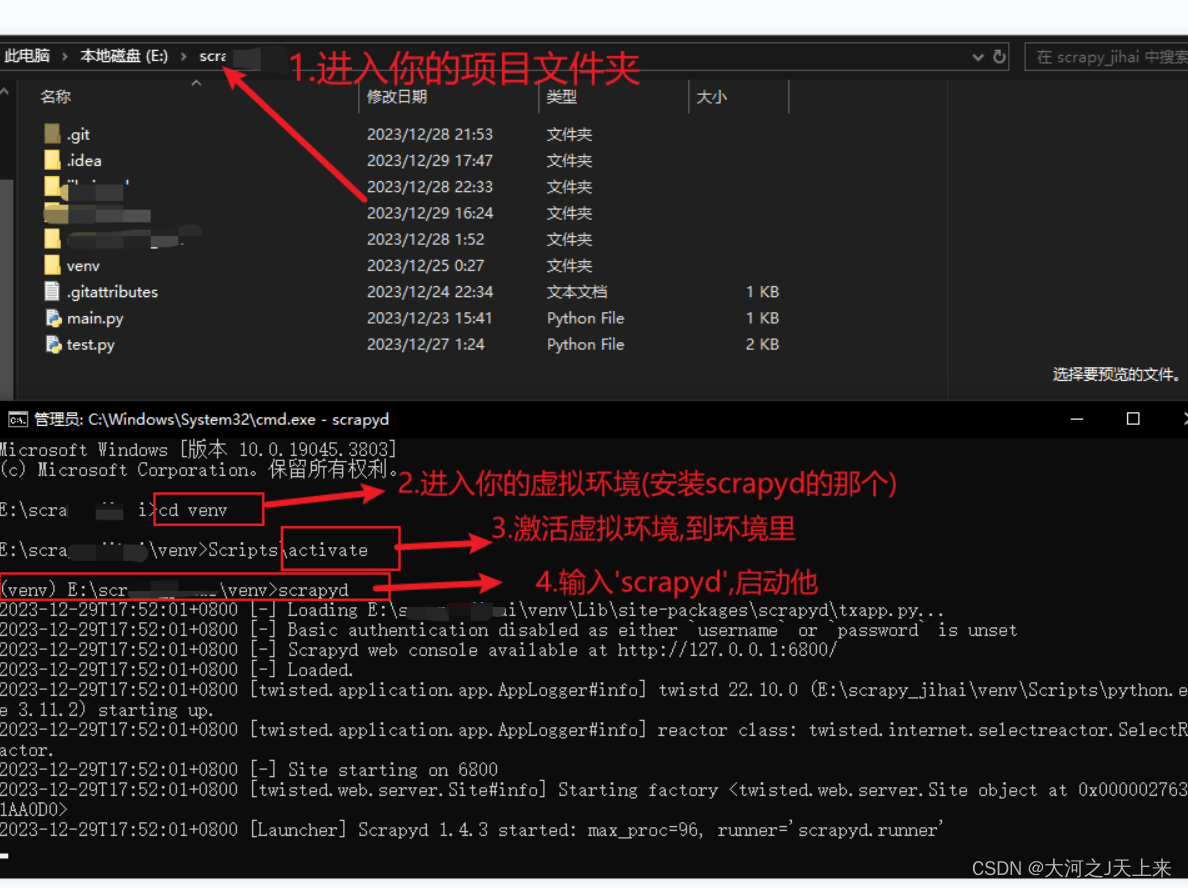
ps:(我这里是拿个项目过来改的,以上一篇爬虫工作量由小到大的思维转变---<第三十四章 Scrapy 的部署scrapyd+Gerapy>-CSDN博客)里面的文件为准; 你哪里装的gerapy和scrapyd,就去那个文件夹;
成功之后,如图:

---你的状态指标,刷新一下:正常!? ?就是成功了~
3.创建项目文件夹(你也可以自己cmd完成,都随意! 看我原理就成):
特别注意:
-
log是日志文件夹,你每开启一次gerapy,他就会在里面生成一个日志文件;报错的话,你就去找对应的ERROR看去~?
-
gerapy文件夹里也有一个projects文件夹;? ?他是你装gerapy文件就生成了的; 我目前的版本是gerapy= 0.9.13 ;? 这个版本,是在log同级文件里,创建projects(手动创建 mkdir projects)
-
如果你的projects创建的层级错了,他会报:

----认真看我说的1 2 3条,还有图! 标红的是极为关键的地方(也就是你丢爬虫工程的地方),搞错了你就丢不上去爬虫工程了~
4.丢爬虫工程:
? ? ? ? 1.怎么丢爬虫工程:
? ? ? ? ? ? ? ? -丢你scrapy的根文件,也就是那个含着"scrapy.cfg"文件的包,全部拷贝!
????????????????
? ? ? ? 2.从github上/其他地方拷(后面会讲,这里只谈本地的先带着走一遍)
5.部署到XX服务器(这里是部署本机链接服务):
????????步骤1. 你爬虫项目丢的没问题,这个图就没问题!
????????步骤2: 打包如果有问题,去看log! 很有可能是坏在setting上---按我步骤,一般不会报错;你就反复去看 '4.丢爬虫工程'那个环节!
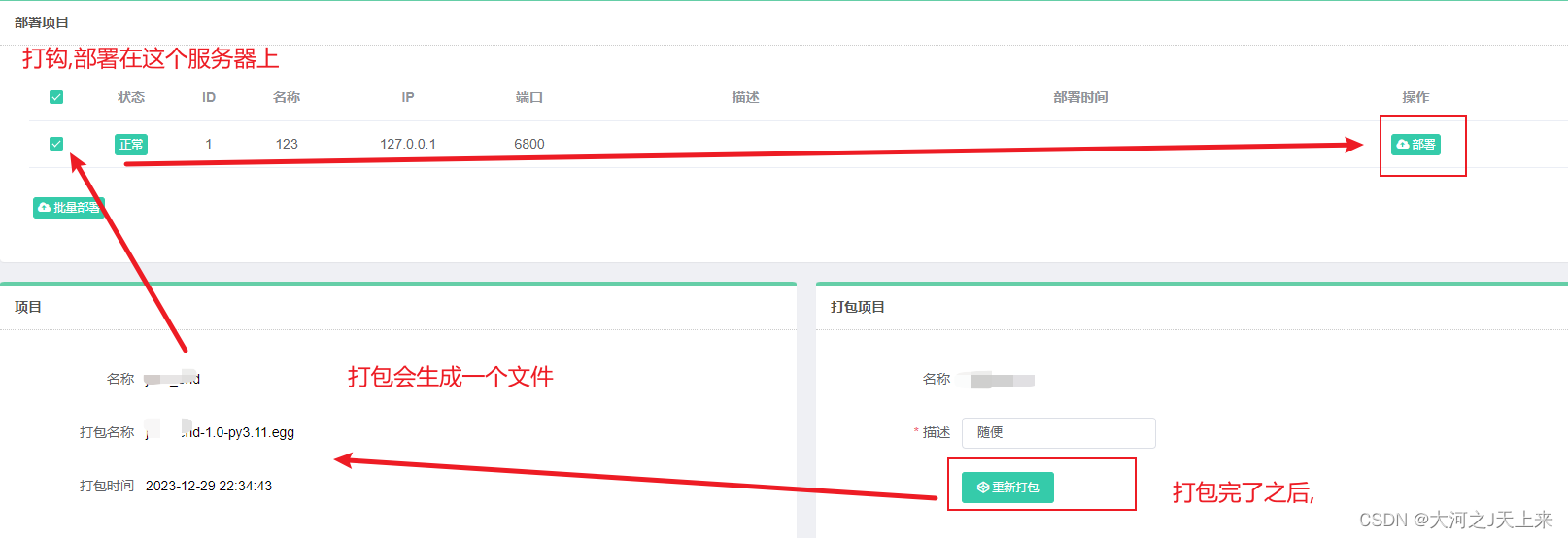
????????
6.部署成功!?


7.随便玩了
敞开了玩~~ 鼠标点点点,各种乱造...every body 造坏了再来一遍!!吼吼!!!
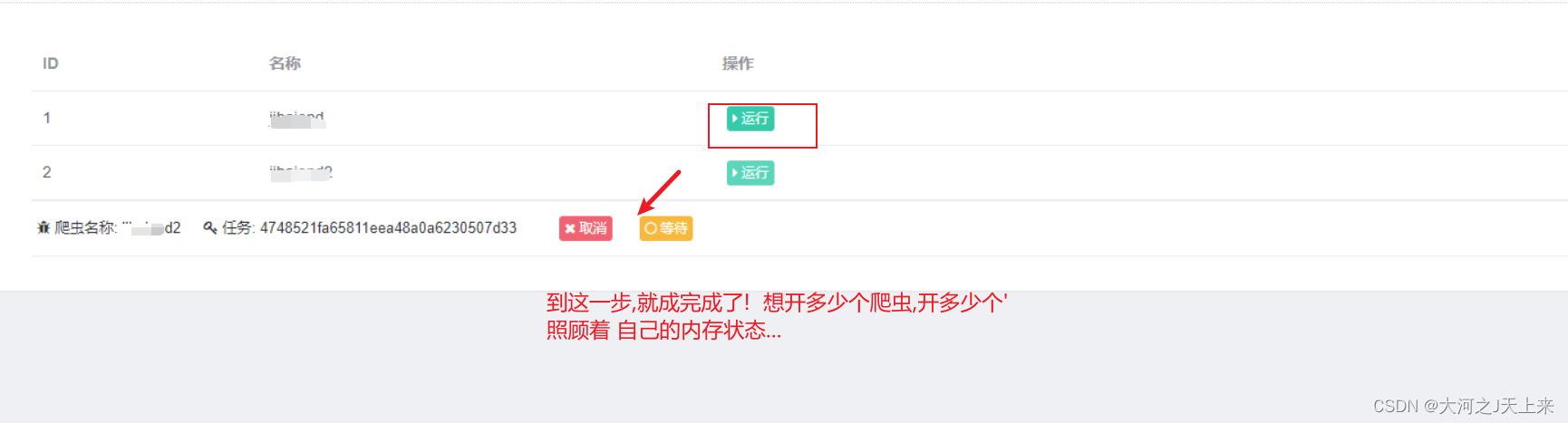
-----------恭喜大家,部署了自己第一个爬虫项目!? 是不是瞬间感觉其他都不香了....
所以我就说嘛.爬虫没意思. 趁早散伙....
文章来源:https://blog.csdn.net/m0_56758840/article/details/135299905
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 关于‘ Mybatis中的动态SQL语句 ‘解析
- 【前端】Nodejs与Webpack(学习笔记)
- 采用Vscode进行ssh连接远程服务器并实现代码运行和调试
- 本地部署生成式AI,选显卡or笔记本电脑?!新款酷睿Ultra举票
- 广播测试信令记录一文全解
- Cesium中圆柱和圆锥Entity绘制
- 食用醋生产加工污废水如何处理排放
- 2024年MySQL学习指南(五),探索MySQL数据库,掌握未来数据管理趋势
- 面试__Java常见异常有哪些?
- 如何测试开关电源的功率?ATECLOUD开关电源自动化测试系统能否测试?