Python 中多线程与多处理之间的区别
一、说明
?? 在本文中,我们将学习 Python 中多线程和多处理的内容、原因和方式。在我们深入研究代码之前,让我们了解这些术语的含义。
二、基本术语和概念
?? 程序是一个可执行文件,它由一组执行某些任务的指令组成,通常存储在计算机的磁盘上。
?? 进程就是我们所说的程序,它已与运行所需的所有资源一起加载到内存中。它有自己的内存空间。
?? 线程是进程中的执行单元。一个进程可以有多个线程作为其一部分运行,其中每个线程使用进程的内存空间并与其他线程共享。
?? 多线程是一种技术,其中进程生成多个线程以执行不同的任务,大约在同一时间,一个接一个。这给你一种错觉,即线程是并行运行的,但实际上它们是以并发方式运行的。在 Python 中,全局解释器锁 (GIL) 阻止线程同时运行。
多处理是一种实现最真实形式的并行性的技术。多个进程跨多个 CPU 内核运行,这些内核之间不共享资源。每个进程可以在自己的内存空间中运行许多线程。在 Python 中,每个进程都有自己的 Python 解释器实例,负责执行指令。
?? 现在,让我们进入程序,我们尝试以六种不同的方式执行两种不同类型的函数:IO 绑定和 CPU 绑定。在 IO 绑定函数中,我们要求 CPU 闲置并打发时间,而在 CPU 绑定函数中,CPU 将忙于产生一些数字。
要求:
- 一台 Windows 计算机(我的机器有 6 个内核)。
- 已安装 Python 3.x。
- 任何用于编写 Python 程序的文本编辑器/IDE(我在这里使用 Sublime Text)。
?? 注意:以下是我们程序的结构,它将在所有六个部分中通用。在提到它的地方 # YOUR CODE SNIPPET HERE,将其替换为每个部分的代码片段。
import time, os
from threading import Thread, current_thread
from multiprocessing import Process, current_process
COUNT = 200000000
SLEEP = 10
def io_bound(sec):
pid = os.getpid()
threadName = current_thread().name
processName = current_process().name
print(f"{pid} * {processName} * {threadName} \
---> Start sleeping...")
time.sleep(sec)
print(f"{pid} * {processName} * {threadName} \
---> Finished sleeping...")
def cpu_bound(n):
pid = os.getpid()
threadName = current_thread().name
processName = current_process().name
print(f"{pid} * {processName} * {threadName} \
---> Start counting...")
while n>0:
n -= 1
print(f"{pid} * {processName} * {threadName} \
---> Finished counting...")
if __name__=="__main__":
start = time.time()
# YOUR CODE SNIPPET HERE
end = time.time()
print('Time taken in seconds -', end - start)
三、进程对CPU绑定
第 1 部分:一个接一个地运行 IO 绑定任务两次…
# Code snippet for Part 1
io_bound(SLEEP)
io_bound(SLEEP)
?? 在这里,我们要求 CPU 执行函数 io_bound(),该函数将整数(此处为 10)作为参数,并要求 CPU 休眠几秒钟。此执行总共需要 20 秒,因为每个函数执行需要 10 秒才能完成。请注意,它是同一个 MainProcess 使用其默认线程 MainThread 一个接一个地调用我们的函数两次。
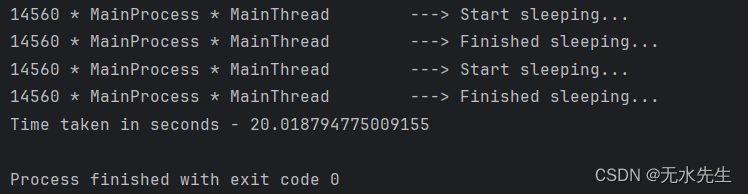
第 2 部分:使用线程运行受 IO 绑定的任务…
# Code snippet for Part 2
t1 = Thread(target = io_bound, args =(SLEEP, ))
t2 = Thread(target = io_bound, args =(SLEEP, ))
t1.start()
t2.start()
t1.join()
t2.join()
?? 在这里,让我们使用 Python 中的线程来加快函数的执行速度。线程 Thread-1 和 Thread-2 由我们的 MainProcess 启动,每个线程几乎同时调用我们的函数。两个线程同时完成休眠 10 秒的工作。这大大缩短了整个程序的总执行时间,减少了 50%。因此,多线程是执行任务的首选解决方案,其中 CPU 的空闲时间可用于执行其他任务。因此,通过利用等待时间来节省时间。

第 3 部分:一个接一个地运行两次 CPU 密集型任务…
# Code snippet for Part 3
cpu_bound(COUNT)
cpu_bound(COUNT)
?? 在这里,我们将调用我们的函数 cpu_bound(),它将一个大数字(此处为 200000000)作为参数,并在每一步将其递减,直到它为零。我们的 CPU 被要求在每次函数调用时进行倒计时,这大约需要 12 秒(这个数字可能因您的计算机而异)。因此,整个程序的执行花了我大约 26 秒才能完成。请注意,MainProcess 再次在其默认线程 MainThread 中一个接一个地调用该函数两次。
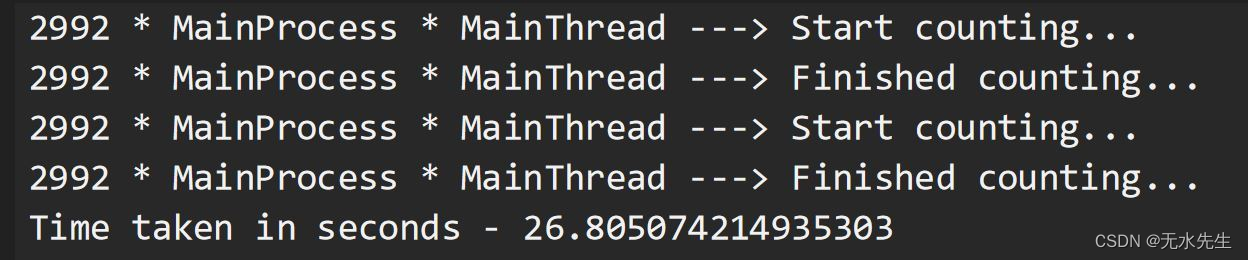
第 4 部分:线程可以加快我们受 CPU 限制的任务吗?
# Code snippet for Part 4
t1 = Thread(target = cpu_bound, args =(COUNT, ))
t2 = Thread(target = cpu_bound, args =(COUNT, ))
t1.start()
t2.start()
t1.join()
t2.join()
?? 好的,我们刚刚证明了线程对于多个 IO 绑定任务的效果非常好。让我们使用相同的方法来执行 CPU 密集型任务。好吧,它最初确实同时启动了我们的线程,但最终,我们看到整个程序执行花费了大约 40 秒!刚刚发生了什么?这是因为当 Thread-1 启动时,它获得了全局解释器锁 (GIL),从而阻止 Thread-2 使用 CPU。因此,Thread-2 必须等待 Thread-1 完成其任务并释放锁,以便它可以获取锁并执行其任务。这种锁的获取和释放增加了总执行时间的开销。因此,我们可以肯定地说,对于需要 CPU 处理某事的任务来说,线程并不是一个理想的解决方案。

第 5 部分:那么,将任务拆分为单独的流程是否有效?
# Code snippet for Part 5
p1 = Process(target = cpu_bound, args =(COUNT, ))
p2 = Process(target = cpu_bound, args =(COUNT, ))
p1.start()
p2.start()
p1.join()
p2.join()
?? 让我们切入正题。多处理就是答案。在这里,MainProcess 启动了两个子进程,它们具有不同的 PID,每个子进程都负责将数字减少到零。每个进程并行运行,使用单独的 CPU 内核和它自己的 Python 解释器实例,因此整个程序执行只需 12 秒。请注意,输出可能以无序方式打印,因为进程彼此独立。每个进程都在其自己的默认线程 MainThread 中执行函数。在程序执行期间打开任务管理器。您可以看到 Python 解释器的 3 个实例,MainProcess、Process-1 和 Process-2 各一个。您还可以看到,在程序执行期间,两个子进程的功耗为“非常高”,因为它们正在执行的任务实际上正在对它们自己的 CPU 内核造成影响,如 CPU 性能图中的峰值所示。

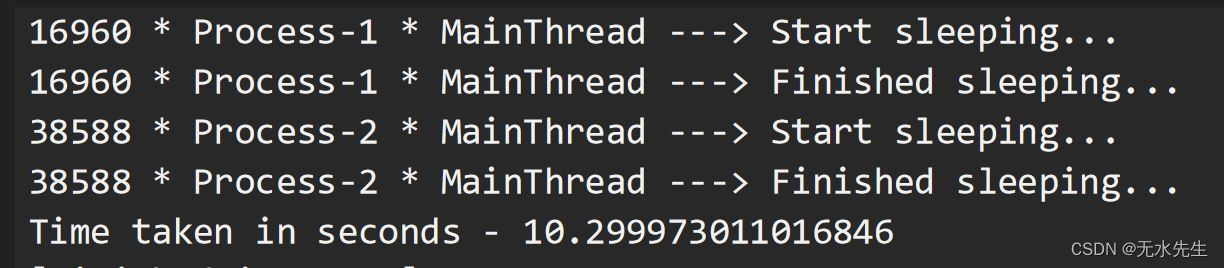
第 6 部分:我们对 IO 绑定任务使用多处理…
# Code snippet for Part 6
p1 = Process(target = io_bound, args =(SLEEP, ))
p2 = Process(target = io_bound, args =(SLEEP, ))
p1.start()
p2.start()
p1.join()
p2.join()
?? 现在我们已经对多处理帮助我们实现并行性有了大致的了解,我们将尝试使用这种技术来运行我们的 IO 绑定任务。我们确实观察到结果是非凡的,就像在多线程的情况下一样。由于进程 1 和进程 2 正在执行要求自己的 CPU 内核闲置几秒钟的任务,因此我们没有发现高功耗。但是,进程的创建本身就是一项 CPU 繁重的任务,并且比创建线程需要更多的时间。此外,进程需要的资源比线程多。因此,最好将多处理作为 IO 绑定任务的第二个选项,多线程是第一个选项。
?? 嗯,那是一段相当长的旅程。我们看到了执行一项任务的六种不同方法,大约需要 10 秒,具体取决于任务对 CPU 的影响是轻还是重。
四、结论
?? 底线:IO 绑定任务的多线程处理。CPU密集型任务的多处理。
| Python 中的多线程 | Python 中的多处理 |
|---|---|
| 它实现了并发性。 | 它实现了并行性。 |
| 在并行计算的情况下,Python 不支持多线程。 | Python 在并行计算的情况下支持多处理。 |
| 在多线程中,单个进程同时生成多个线程。 | 在多处理中,多个线程同时跨多个内核运行。 |
| 无法对多线程进行分类。 | 多处理可以分为对称或非对称。 |
。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- MyBatis中select语句中使用String[]数组作为参数
- 什么是网络数据抓取?有什么好用的数据抓取工具?
- 每日OJ题_算法_滑动窗口⑦_力扣30. 串联所有单词的子串
- 你在为其他知识付费平台做流量吗?
- DEJA_VU3D - Cesium功能集 之 112-获取圆节点(1)
- 中国银行 企业网上银行 相关注意事项合辑 不断更新中...
- JMeter笔记(三)
- 自己造messagebox轮子
- 解决Gitee每次push都需要输入用户名和密码
- 【MySQL】数据库之MMM高可用