什么是网络数据抓取?有什么好用的数据抓取工具?
?一、什么是网络数据抓取
网络数据抓取(Web Scraping)是指采用技术手段从大量网页中提取结构化和非结构化信息,按照一定规则和筛选标准进行数据处理,并保存到结构化数据库中的过程。目前网络数据抓取采用的技术主要是对垂直搜索引擎(指针对某一个行业的专业搜索引擎)的网络爬虫(或数据采集机器人)、分词系统、任务与索引系统等技术的综合运用。
二、网络数据抓取有什么作用
?科学研究离不开详实可靠的数据,互联网的发展提供了新的获取数据的手段。面对海量的互联网数据,网络数据抓取技术被视为一种行之有效的技术手段。相比于传统的数据采集方法,网络抓取数据无论时效性,还是灵活性均有一定的优势。利用网络数据抓取技术,可以在短时间内快速地抓取目标信息,构建大数据集以满足分析研究需要。
三、网络数据抓取流程
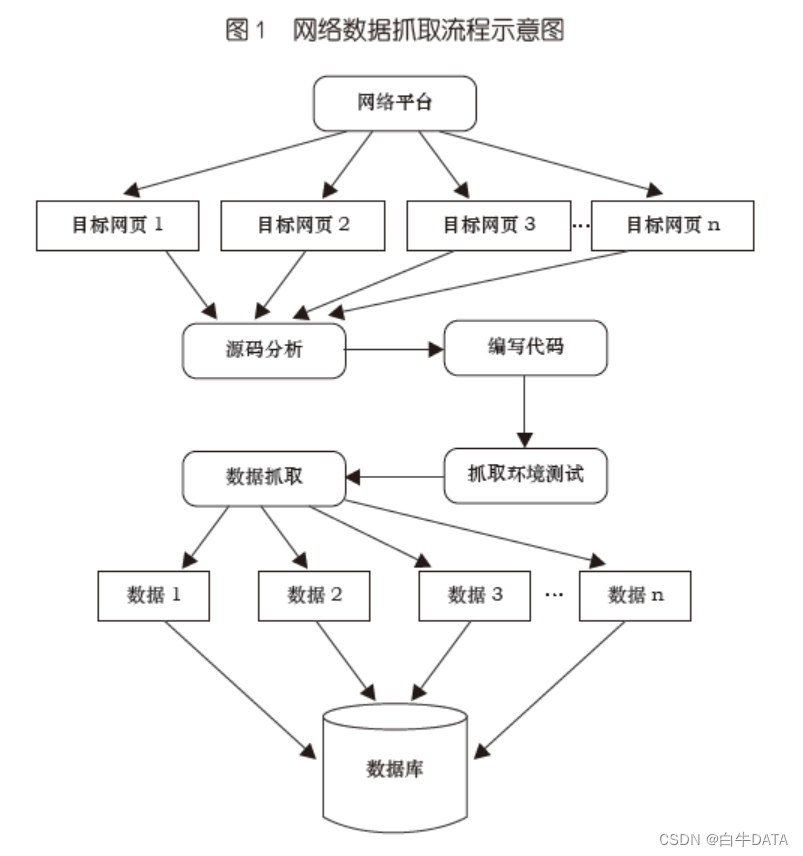
?如上图所示,网络数据抓取的一般步骤包括:
(一)确定数据抓取的目标网站。
根据研究需求确定所需信息的来源网站。
(二)网站的源代码分析。
逐个分析各来源网站的数据信息组织形式,包括信息的展示方式以及返回方式,比如在线校验格式化的工具(JSON),在线格式化美化工具(XML)等, 根据研究需求确定抓取字段。
(三)编写代码。
?分析时尽量找出各来源网站信息组织的共性,这样更便于编写服务器端和数据抓取端的代码。
(四)抓取环境测试。
对抓取端进行代码测试,根据测试情况对代码进行修改和调整。
(五)数据抓取。
将测试好的代码在目标网站进行正式数据抓取。
(六)数据存储。
将抓取的数据以一定格式存储,比如将文本数据内容进行过滤和整理后, 以 excel、csv 等格式存储,如果数据量较大也可以存储在关系型数据库(如MySQL,Oracle 等),或非关系型数据库(如 MongoDB)中来辅助随后的信息抽取和分析。若抓取积累的数据量大到一定程度,即达到大数据的级别,为了将来分析的效率性和方便性,可以将其直接存储于各类分布式大数据框架 ( 如Hadoop 和 Spark 等 ) 提供的分布式文件系统中。数据存储完成后,基于整理好格式的数据,可以根据分析目标执行各类数据挖掘和机器学习算法,如分类、建模、预测等等。
四、有什么好用的数据抓取工具?
(1)八爪鱼
一款知名度较高的软件,对小白用户友好。
(2)webscraper
一款浏览器插件,用于简单的数据爬取。
(3)AnyPapa
一款开源的免费数据爬虫工具,支持多种网站。
(4)抓包工具
Fiddler:可以用于抓取http/https的数据包,常用于Windows系统的抓包,免费
Charles:常用于MacOS用户,收费。
Proxyman:MacOS系统,免费。
Wireshark:超好用,Windows Linux macOS 都可以使用。
浏览器自带的“开发者工具”
(5)公抓抓(gongzhuazhua)
是一款专门用于爬取最新企业公示系统的平台,不需要写代码,帮助用户快速获取所需的企业信息。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 2024年问界M5、M7、M9全文理性分析【伸手党福利】
- 网址链接的二维码如何制作?扫码怎么跳转其他网页?
- 微信小程序promise封装
- 华为eNSP点到点IP隧道实验GRE--VPN
- 芯课堂 | SWM341 I2C 接口应用
- 学习JavaEE的日子 day16 抽象类,接口,多态,对象转型,内部类
- dubbo--03--- dubbo 支持的9种协议
- 十五届蓝桥杯分享会(一)
- 车载软件易受攻击,如何规避嵌入式软件漏洞
- 脚本执行权限——chmod +x、chmod -x