Transformer
个人学习总结,如有问题,欢迎大家指出,将不胜感谢。
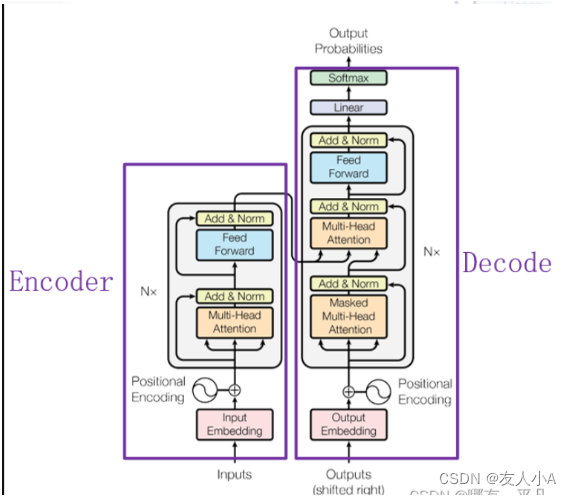
1.Input:分词后的词向量序列

2. Word Embedding
进行词汇位置迁入(按照词汇id迁入对应的词向量),并将原始句子规整成同一长度。
embedding各参数含义:
- input: [batch_size, seq_len], 多个句子的位置信息
input data_range: [0,num_embeddings)
- weight: [num_embeddings, embed_dim]--[词典大小, 向量维度]
weight其实是一个单词查找表,根据id查询对应的"词向量"
- output:?[batch_size, seq_len, embed_dim]
3.?Positional Encoding 位置编码
首先说结论:Transformer 模型本身不具备位置信息的感知能力。
原因:
一般来说,我们会认为nn.Embedding?层将词汇索引映射为词嵌入向量,看似保持了词汇在句子中的顺序,即经过embedding后的输出是按照句子中词汇的顺序排列的。但是我们要结合self-attention的原理。在自注意力机制中,输入序列中的每个元素都会与其他元素进行关联,并且为每对元素分配一个注意力权重,用于指导模型在编码和解码阶段的处理。这使得 Transformer 能够同时考虑到整个序列中的相关信息,而不仅仅是邻近元素之间的关系。
通俗点讲,如果打乱输入序列的顺序进行训练,也不会直接影响最终的训练结果。因为self-attention是基于元素之间的关联性而非顺序性,这个关联性是通过有监督学习方式训练出来的,即给定一组输入序列和相应的目标输出。模型会根据当前输入序列生成预测结果,并与目标输出进行比较。通过计算预测结果与目标之间的差距(通常使用损失函数),模型会使用反向传播算法来调整自己的参数,从而逐步优化预测结果。最终,模型只能学习到元素间的关联性,而不具备感知元素位置信息的能力。
4. Encoder
4.1 attention
- 对输入编码器的每个词向量,都创建3个向量qkv, 词向量Input(如“Thinking")
- q (query):Input * q_weight 查询矩阵
- k (keys): Input * k_weight 键矩阵
- v(values):? Input * v_weight 值矩阵
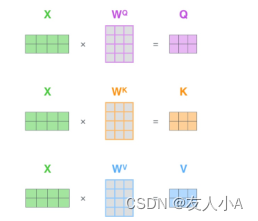
- 计算attention score(注意力分数):q · k_T = score
先验知识:向量A,B方向相同,A·B=|A|·|B|; A和B垂直,A·B=0;A和B相反, A·B=-|A|·|B|。
? ? ? ? ? ? ? ? ? -→?两个向量的点乘可以表示两个向量的相似度。越相似越趋于一致,点乘结果越大。
Qi和每个K的点乘表明当前词向量与每个词向量之间的”相似度“,表示需要对句子中其他位置的每个词放置多少的注意力。 - 把每个分数除以sqrt(k_len)
也可以除以其他数字,除以一个数是为了在反向传播是,计算梯度更加稳定 - Softmax(score)
将分数归一化,使得分数都是正数且相加为1。这些分数决定了在编码当前位置的词时,对所有位置的词分别有多少的注意力。 - score * v → score_vector
对于分数高的位置,相乘后的值就越大,会放置更多的注意力 - 上一步的向量相加,得到attention层在当前位置的输出
这个结果包含了当前位置与所有位置的关联性
multi-head attention
? ? ?
图1 single-head?
? ?
图2? ?2-head attention? ? ? ? ?
?
?图3 8-head attention
- 多头注意力中,hidden_size * num_attention_heads = embed_dim
- embed_dim可以用于表格词向量的一个隐藏维度,每个维度对应不同的词特征
如:词性特征,位置特征,语法特征,实体特征,情感特征,主题特征等。
这样看,hidden_size个数分别是在不同属性上计算得到的分数特征。具体应用中会根据任务和数据的特点进行定义。注意力机制可以根据输入数据的不同,提取出适合该任务的相关特征。 - 而multi-head attention的作用就是:将特征拆分成多个head,分别训练,得到词向量→ 不同特征的映射关系
- 最终将多个head进行拼接
如上图
- head=1: 当前位置 "it_"只有一个特征空间,表示当前位置对不同词的关注度
- head=2: 当前位置 "it_"有2个特征空间,”it_"对不同词的关注度,在不同特征空间是不同的
- head=3: 当前位置“it_"有8个特征空间,”it_"对不同词的关注维度更大了,每个特征空间最关注的位置不同
4.2 Add &Norm
总的来说,设输入为 x,经过某个网络层后得到的输出为 H(x),那么残差连接会将输入 x 与输出 H(x) 相加,得到最终的输出 F(x)。数学表达式如下:F(x) = H(x) + x
这样,就算中间层H(x)出现了信号衰弱(如weight接近0,计算得到H(x)接近0),由于残差网络的存在,原始输入x能够直接穿过H(x)层并于衰减后的信号相加,保留了原始输入的信息,起到了保护和传递梯度的作用。
4.3 MLP(FFN,?全连接前馈神经网络)
FeedForward做了两次线性线性变换,先将数据映射到高纬度的空间再映射到低纬度的空间(至少做两次Linear,增加了模型的非线性能力),帮助提取输入序列更深层次的特征和信息。
如:FFN(x)= linear(Relu(linear))? = max(0, input * weight1+bias1)? * weight2 + bias2
5. Decoder
Encoder和Decoder都有 multi-head Attention 和FFN,不同的是:
1.?Decoder还有一个带掩码的多头注意力层(masked multi-head Attention block)
掩码操作是为了避免未来信息的泄漏。
在序列生成任务中,Decoder 的每个位置需要根据之前已经生成的部分和来自 Encoder 的输入信息来决定下一个输出。
然而,为了保持模型的自回归性质,也就是确保生成时只依赖于已生成的部分和当前位置之前的输入,需要限制模型只能关注当前位置之前的信息。这就是掩码的作用。
具体来说,掩码操作会将未来位置的相关性分数设置为负无穷大(或一个极小的值),这样在计算注意力权重时,未来位置的权重值就会趋近于零。这样,Decoder 在生成当前位置的输出时就不会受到未来位置的影响。
后面步骤跟multi-head Attention一样,掩码可以使不相关词向量的分数被忽略。
2. QKV的来源不同
在 Transformer 模型中,Encoder 和 Decoder 是相互独立的神经网络模块,它们在处理输入序列和输出序列时具有不同的作用。
- Encoder 负责将输入序列(例如源语言句子)转换为一系列隐藏表示,以捕捉输入序列中的语义和特征。
为了完成这个任务,Encoder 接收源语言句子的嵌入表示,并经过多个自注意力层(self-attention layers)进行处理,输出每个位置的隐藏表示。
因此:QKV都来自word_embedding
? - Decoder 则负责生成目标语言的输出序列(例如目标语言句子),它需要根据输入序列的隐藏表示以及前面预测的部分来生成下一个输出。
为了实现这个目标,Decoder 在每个时间步骤上使用了两组信息:一个是来自上一层 Decoder 的输出表示,一个是来自 Encoder 的隐藏表示KV。
K 矩阵用于计算 Query 向量与 Encoder 输出的相关性,而 V 矩阵则用于对注意力权重加权求和,以获得与 Query 对应的上下文表示。
通过对 Encoder 输出的注意力计算,Decoder 可以从源语言句子中获取相关的信息,并在生成目标语言句子时引入这些信息。
3. 最后有一个 Softmax 层计算下一个翻译单词的概率
Softmax 层会把attention计算出的所有分数转换为概率(把所有的分数转换为正数,并且加起来等于 1)。然后选择最高概率的那个数字对应的词,就是这个时间步的输出单词。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【博客搭建记录贴】使用hexo下载项目文件并启动默认博客网站
- html入门
- Python print()函数高级用法和 len()函数详解:获取字符串长度或字节数
- 如何使用PatchaPalooza对微软每月的安全更新进行全面深入的分析
- Java集合框架的基本接口
- ubuntu18.04安装MySQL
- 采用xlrd和openpyxl库读取excel文件
- HDRplus ——简述(一)
- 基于OpenCV的图像平移
- openharmony应用开发HDC 常用命令