【Elasticsearch】索引恢复(recovery)流程梳理之副本分片数据恢复
发布时间:2024年01月20日
replica shard重启具体流程
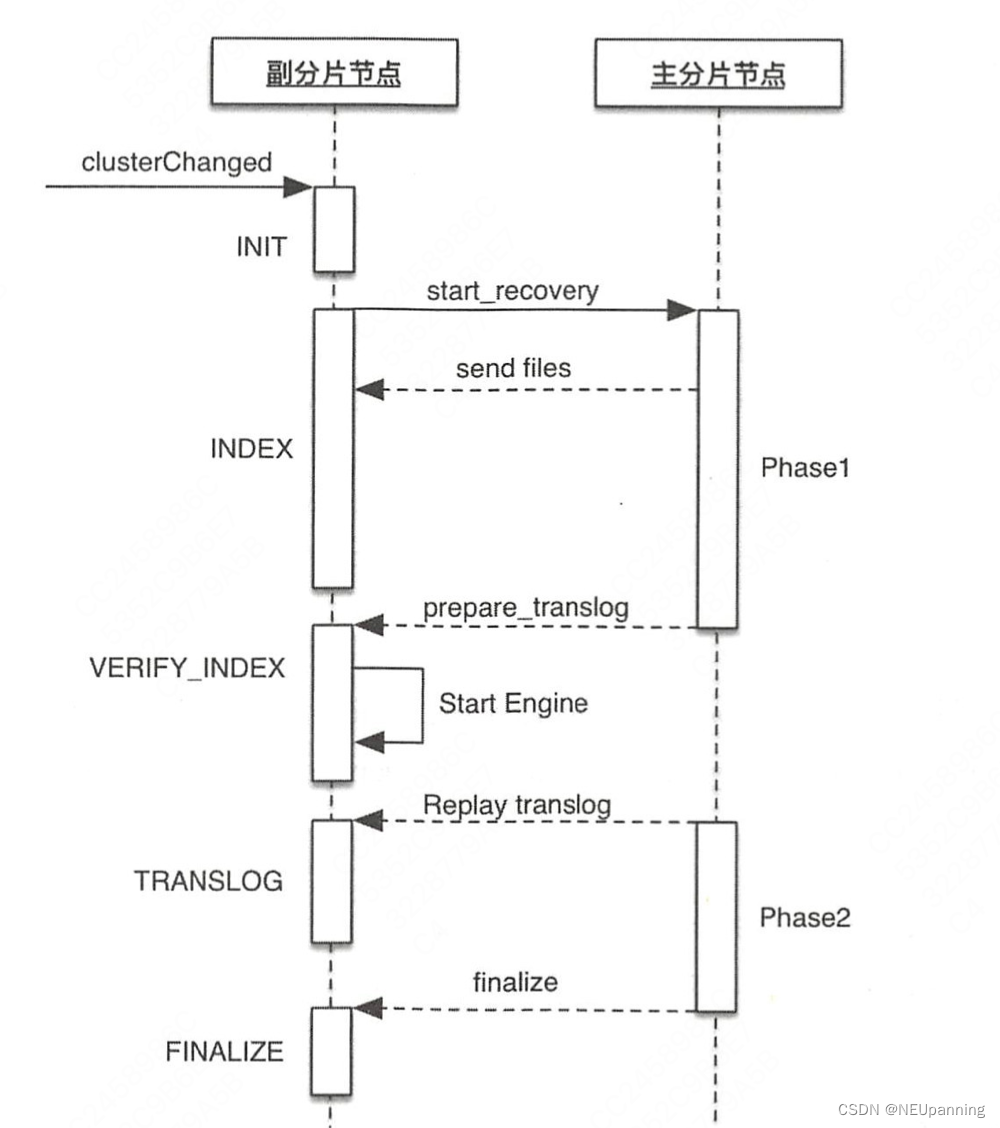
replica shard node (generic threadpool)
- 也是因为应用新的集群状态触发recovery,进入index阶段
- 进入translog 阶段。先尝试重放本地的translog到global checkpoint
- 向primary shard发起start recovery的请求,请求包含replica的localCheckpoint+1。(如果第二步重放translog了,localCheckpoint自然也会增加)
primary shard node
- 如果开启了soft delete并且索引是7.4版本之后创建的(retention lease功能),则使用lucene index作为HistorySource,否则使用translog
- 判断是否可以根据seq no按条恢复数据而不是发送segment file,即跳过phase 1,判断需要满足以下条件(其实就是看能不能使用retention lease/translog回放)
- replica不是没有数据
- primary shard的retention lease或者translog(取决于history source)包含所有要recovery的数据,retention lease会判断soft delete保存的seq no 是否小于 request.startingSeqNo(replica 开始恢复的seq no)
- 对于retention lease,需要包含replica没有的数据,判断retentionLease.seqNo < request.startingSeqNo
- 执行phase 1——sendFileStep。有限速配置indices.recovery.max_bytes_per_sec
- 如果primary和replica的sync id, local checkpoint, maxSeqNo都相同则跳过phase1
- 对比primary和replica的segment file元数据,发送所有replica缺失或者不同的segment file
- 同步发送给replica请求,让他启动engine准备接收translog
- 将replica shard加入replication group,replica将接收到后续的replication request,并确保在下一步中采样最大序列号之前执行此操作,以确保在phase 2发送所有seq No直到 maxSeqNo 的所有文档,保证replica不缺数据。
- 执行phase 2。如果是retention lease则直接从Lucene查询出需要发送的doc,如果是translog则获取一个translog的快照,将数据分批发送到replica
Replica shard node
- replica 会接收primary的segment file,translog,打开engine的请求
- 最后进入进入FINALIZE阶段。执行refresh
一致性问题
因为replica恢复时的phase2阶段既有新写入的replication,也有回放的doc,此时如果针对doc 1有两个更新操作,第一个在回放的操作中,第二个在新的replication,然后replica先执行了replication再执行回放会导致数据不一致,ES通过校验version来解决这个问题,第一个操作的version小于第二个操作,因此即使第一个操作后到达也会被拒绝。
文章来源:https://blog.csdn.net/weixin_45857154/article/details/135651014
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- SQL Server ,使用递归查询具有层级关系的数据。
- uniapp应用内升级
- kubernetes 学习笔记
- CTFshow(web命令执行——炫炫炫)
- 跟一个学霸应该聊些什么?
- 什么是Lambda表达式?Lambda表达式在Java中有哪些应用场景?
- 代码随想录算法训练营第十四天|● 理论基础 ● 递归遍历 ● 迭代遍历 ● 统一迭代
- 基于ssm网络安全宣传网站设计论文
- css原子化的框架Tailwindcss的使用教程(元素html和vue项目的安装与配置)
- 2023年12月GESP认证C++等级考试(三级)真题试卷