系统设计 - 我们如何通俗的理解那些技术的运行原理 - 第三部分:缓存
发布时间:2023年12月17日
本心、输入输出、结果
系统设计 - 我们如何通俗的理解那些技术的运行原理 - 第三部分:缓存
编辑:简简单单 Online zuozuo
地址:https://blog.csdn.net/qq_15071263

如果觉得本文对你有帮助,欢迎点赞、收藏、评论
前言
我们使用视觉效果和简单术语来解释复杂的系统是如何运转的,帮助我们理解技术细节
我们使用视觉效果和简单术语来解释复杂的系统是如何运转的,帮助我们理解技术细节

缓存数据存储在什么地方
该图说明了,我们在典型架构设计中,缓存存放的位置
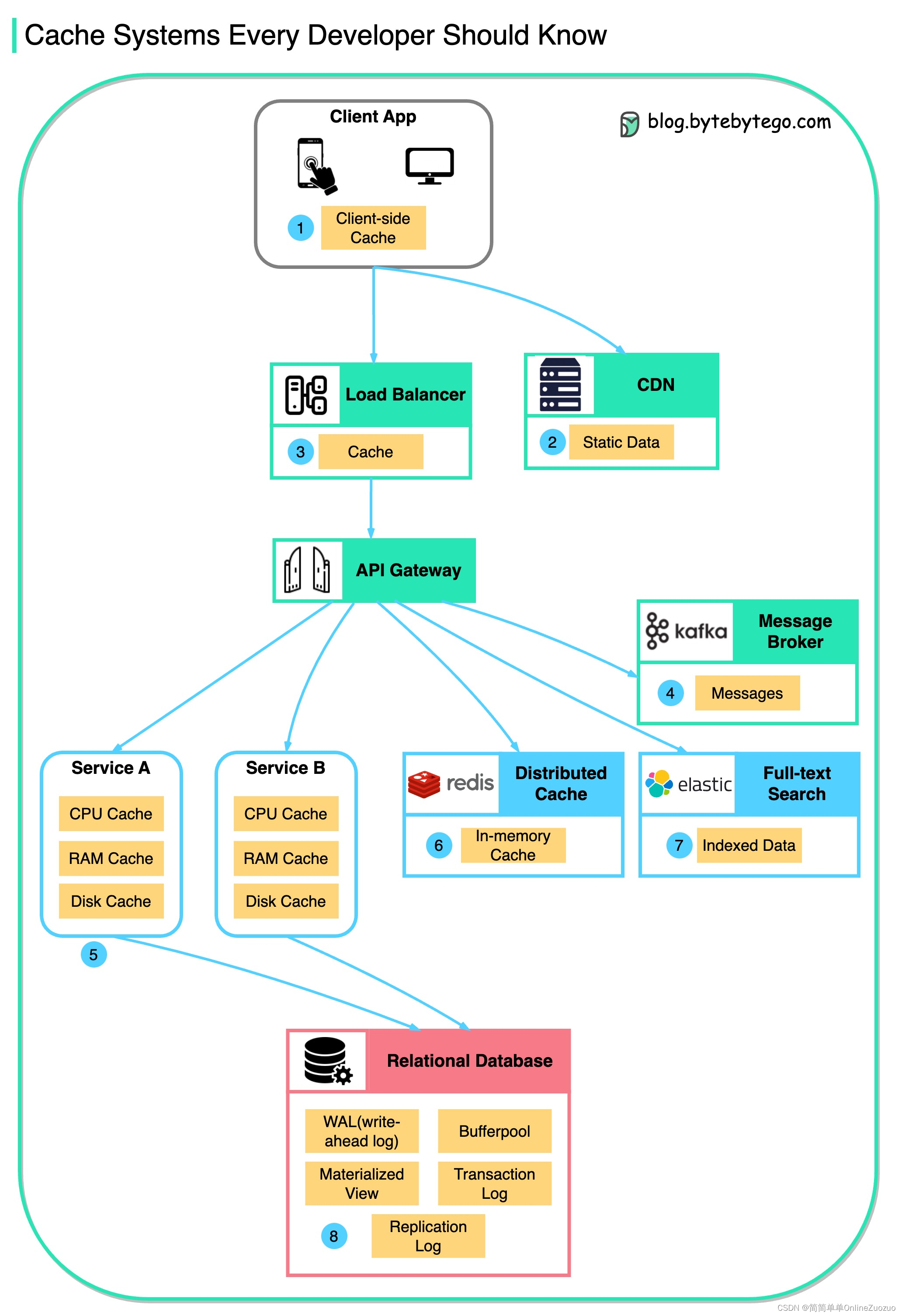
图层说明
有多个图层
- 客户端应用:浏览器可以缓存 HTTP 响应。我们第一次通过 HTTP 请求数据,并在 HTTP 标头中返回过期策略;我们再次请求数据,客户端应用首先尝试从浏览器缓存中检索数据。
- CDN:CDN 缓存静态 Web 资源。客户端可以从附近的 CDN 节点检索数据。
- 负载均衡器:负载均衡器也可以缓存资源。
- 消息传递基础结构:消息代理首先将消息存储在磁盘上,然后使用者按照自己的节奏检索它们。根据保留策略,数据会在 Kafka 集群中缓存一段时间。
- 服务:服务中有多个缓存层。如果数据未缓存在 CPU 缓存中,则服务将尝试从内存中检索数据。有时,服务具有二级缓存来在磁盘上存储数据。
- 分布式缓存:像 Redis 这样的分布式缓存在内存中保存多个服务的键值对。它提供了比数据库更好的读/写性能。
- 全文搜索:我们有时需要使用全文搜索(如弹性搜索)进行文档搜索或日志搜索。数据副本也会在搜索引擎中编制索引。
- 数据库:即使在数据库中,我们也有不同级别的缓存:
- WAL(预写日志):在构建 B 树索引之前先将数据写入 WAL
- 缓冲池:分配给缓存查询结果的内存区域
- 物化视图:预先计算查询结果并将其存储在数据库表中,以提高查询性能
- 事务日志:记录所有事务和数据库更新
- 复制日志:用于记录数据库集群中的复制状态

为什么 Redis 这么快?
为什么 Redis 这么快?有如图所示的三个原因
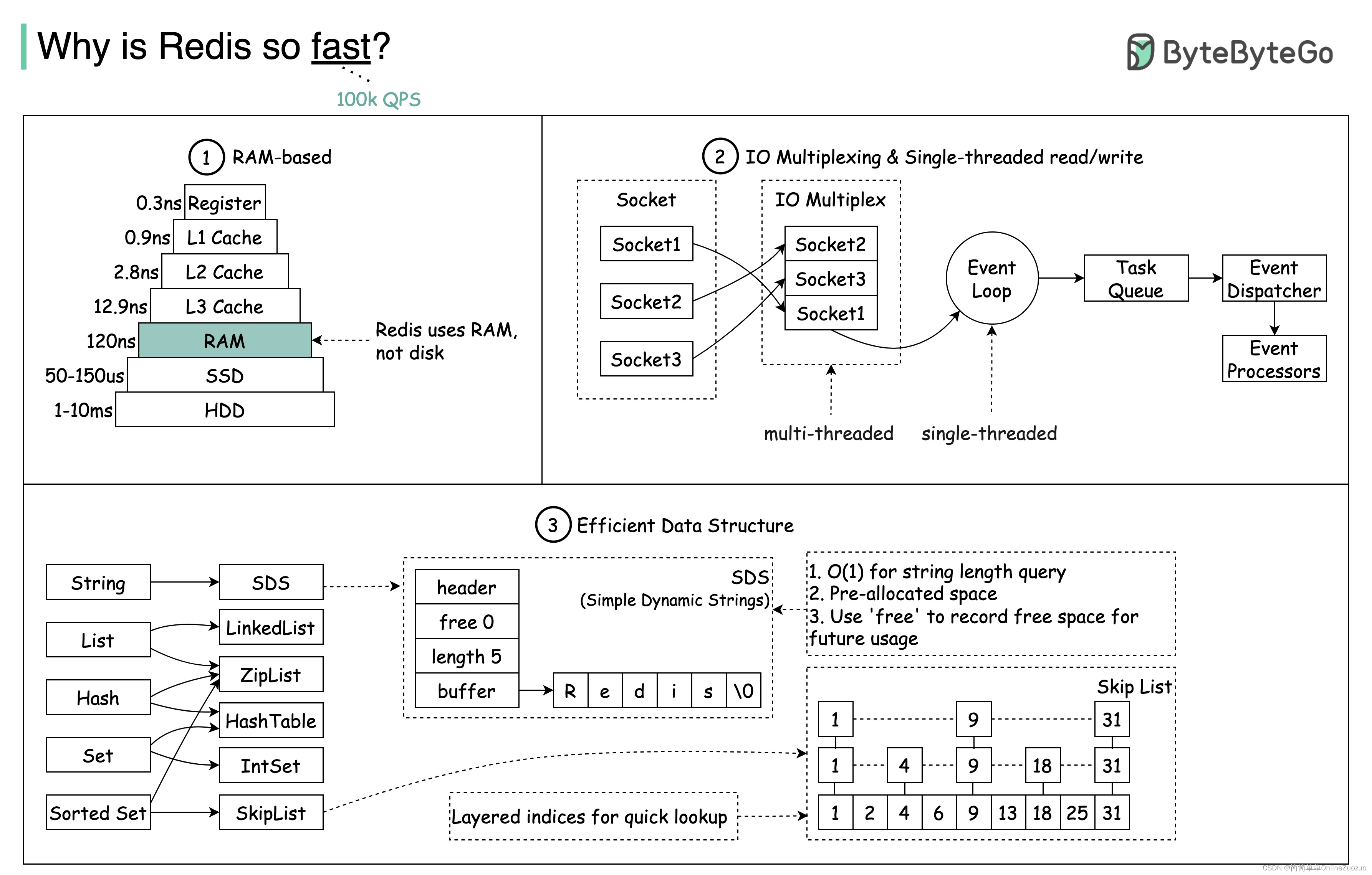
- Redis 是一个基于 RAM 的数据存储。RAM 访问至少比随机磁盘访问快 1000 倍。
- Redis 利用 IO 多路复用和单线程执行循环来提高执行效率。
- Redis 利用了几种高效的低级数据结构

如何使用 Redis
如图所示
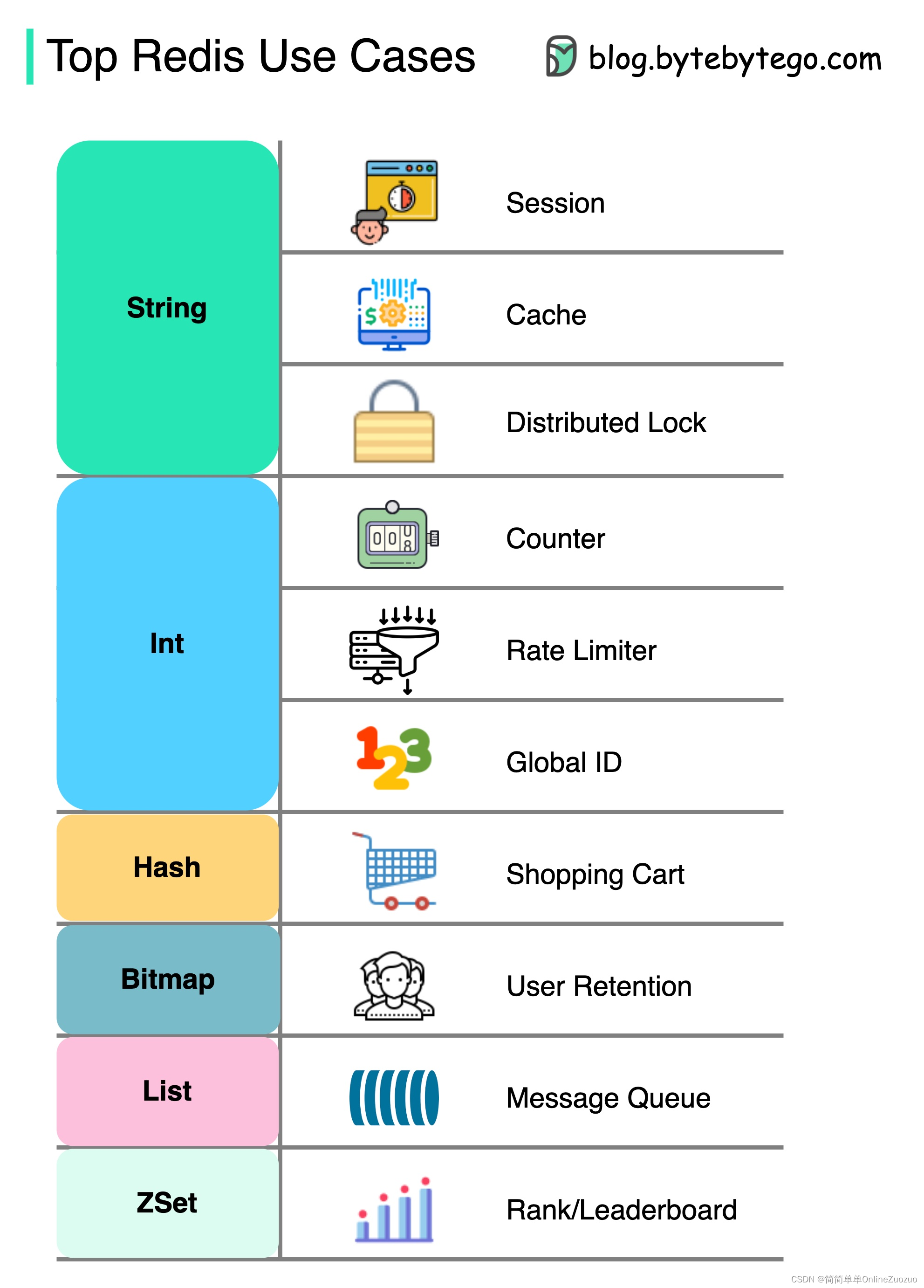
Redis 不仅仅是缓存。
Redis 可用于各种方案,如图所示。
- 会话 : 我们可以使用 Redis 在不同服务之间共享用户会话数据。
- 缓存 : 我们可以使用 Redis 来缓存对象或页面,尤其是热点数据。
- 分布式锁 : 我们可以使用 Redis 字符串来获取分布式服务之间的锁。
- 计数器 : 我们可以计算文章有多少喜欢或多少阅读。
- 速率限制器 : 我们可以为某些用户 IP 应用速率限制器。
- 全局 ID 生成器 : 我们可以将 Redis Int 用于全局 ID。
- 购物车 : 我们可以使用 Redis 哈希来表示购物车中的键值对。
- 计算用户留存率 : 我们可以使用位图来表示用户每天的登录并计算用户留存率。
- 消息队列 : 我们可以将 List 用于消息队列。
- 排名 : 我们可以使用 ZSet 对文章进行排序。

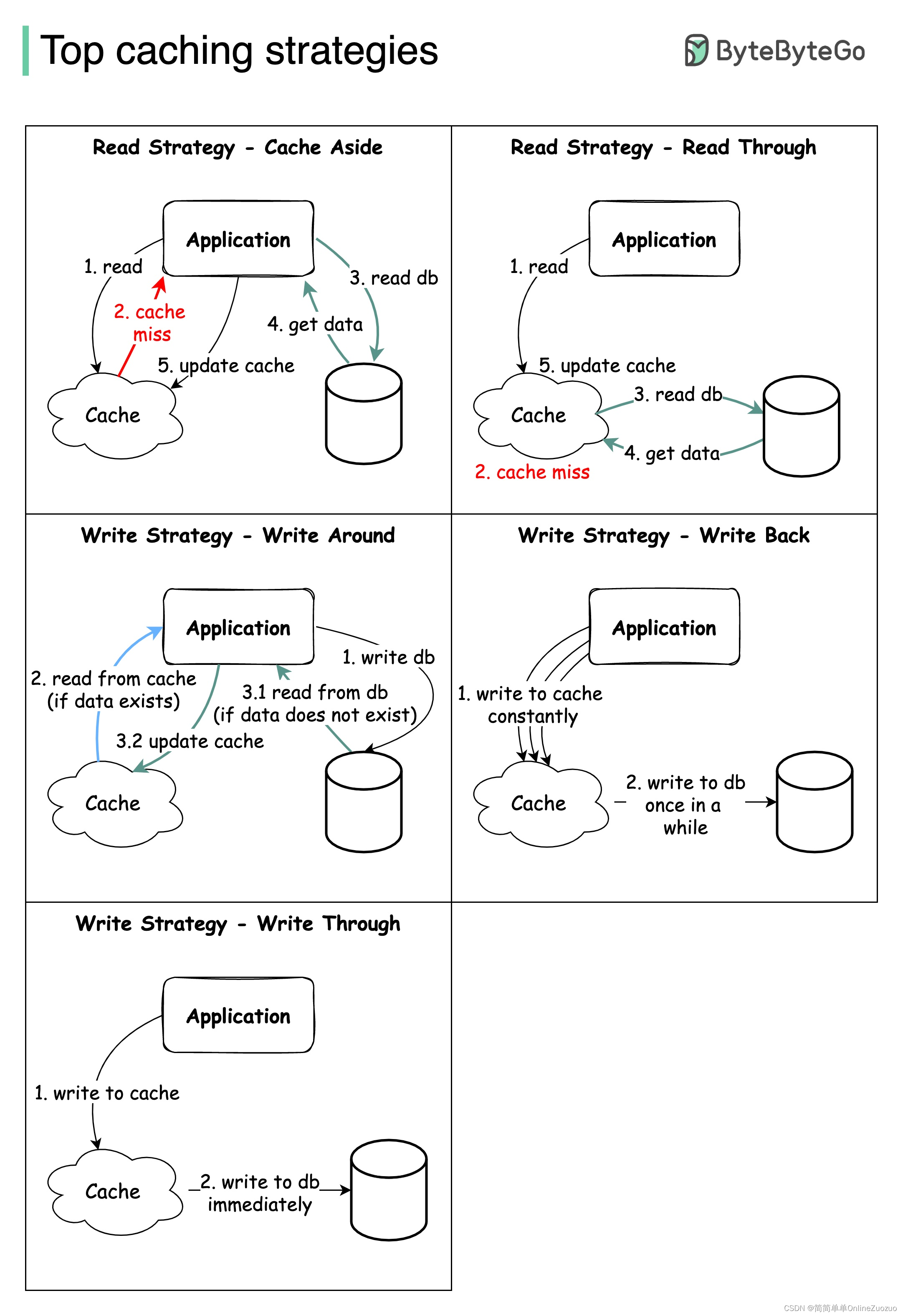
顶级缓存策略
设计大型系统通常需要仔细考虑缓存。 以下是五种经常使用的缓存策略
弘扬爱国精神

文章来源:https://blog.csdn.net/qq_15071263/article/details/133969262
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 利用Pandas进行高效网络数据获取
- 5、C语言:结构
- AI Table应用程序接口表的格式说明和作用
- burpsuite模块介绍之Target(目标)
- 【最新报道】初窥Windows AI 工作室
- MySQL中的ON DUPLICATE KEY UPDATE语句详解
- Visual Studio离线版本下载安装
- 使用vs2019自动生成类图(纯c++项目或者qt项目)
- 数据库的连接池有哪些
- CUDA编程系列之小白通俗学习(一)