只需三步,开发文心一言应用帮你建立情感纽带!
本期文心开发者说邀请到飞桨开发者技术专家李龙老师,分享自己与文心一言之间的故事,故事从一个应用——“文心一言情感关怀之旅”开始。本期分享将从应用介绍、技术路径拆解以及如何实现功能的应用三个方面,对“文心一言情感关怀之旅”应用进行详细的讲解。作者希望通过本项目探讨如何用文心一言做好情感关怀,让AI更有温度。

在飞桨星河社区,我曾经开发过的四个应用。第一个,文心一言情感关怀之旅;第二个,一站式求职小助理,提供职业发展规划、简历生成、简历匹配和面试问题推荐等服务,为求职者带来便利,提高求职的针对性和成功率;第三和第四个应用分别是AI艺术二维码的生成和AI艺术字与logo生成,这些都应用了PPDiffusers中的Stable Diffusion和ControlNet技术,可以个性化生成个人艺术二维码以及更美观的AI艺术字和logo;此外,用户还可以加入自己的创意,打造个人独特标识。
本次主要分享“文心一言情感关怀之旅”应用的开发心得和技术路线。
“文心一言情感关怀之旅”是什么?
应用介绍
“文心一言情感关怀之旅”本质是一个创新性人工智能应用,旨在通过图像信息提取、大语言模型生成和语音合成等技术为用户提供情感支持和温暖的故事体验。

在现代社会中,人们常常会感到孤独、压力和困惑。尤其是在面对工作、学习和生活中的挑战时,很多人缺乏情感上的支持和鼓励。通过人工智能技术的应用,“文心一言情感关怀之旅”应用旨在为用户提供温暖、慰藉和希望。

应用价值
情感支持与慰藉
该应用致力于为用户提供情感支持和慰藉。通过提供温暖的故事,并以富有感情的声线读出,帮助用户减轻压力和焦虑,舒缓孤独感和抑郁情绪,保持积极的情感状态和健康的心理状态。
社交互动和情感共享
“文心一言情感关怀之旅”应用不仅为个体提供情感支持,还能鼓励用户之间的社交互动。用户可以通过分享故事和体验与他人交流,建立情感纽带,从而感受互助和合作的力量,增强社会联结。
技术应用创新
“文心一言情感关怀之旅”项目在人工智能和情感关怀领域进行了技术创新。该项目通过整合图像处理、自然语言生成和语音合成等技术,为人工智能技术在情感关怀方面的应用拓展了新的可能性,为相关领域的发展做出了贡献。
应用亮点
图像关键信息提取
该应用采用CLIP和BLIP模型进行图像关键信息提取。这两个模型能够结合图像处理和语言理解的能力,准确提取上传图片中的关键信息,包括场景、人物、物品等,为后续故事生成和语音合成提供可靠基础。
情感故事生成
该应用通过调用ERNIE SDK,充分利用文心大模型能力,生成富有情感和温暖的故事。文心大模型具备学习和模仿文学作品风格的能力,能够根据关键信息创作出打动人心的故事,给用户以积极向上的情感支持。
自然语音合成
情感关怀是多个维度的,多模态技术的利用可以让情感关怀拓展到视觉、听觉等多个形态,让情感关怀更加生动。该应用通过语音合成技术,将生成的故事转化为自然流畅的语流,使用户能够通过听故事的方式,沉浸式地感受AI的温暖与关怀。
“文心一言情感关怀之旅”怎么做?
技术全景
在介绍具体步骤之前,我们先总体了解一下该应用是如何实现的。首先,通过图像理解大模型CLIP和BLIP对用户输入的场景图像进行理解,获得图像中的关键信息,如场景、人物等。用户也可以手动添加关键信息,或者对模型输出的关键信息进行修正和优化。通过百度翻译API将所获得的关键信息进行翻译为中文。接着,使用ERNIE SDK调用文心大模型能力,获得图像关键信息,生成合乎逻辑、适用于不同年龄段、不同兴趣受众的生动且正能量的精彩故事。最后,使用长文本语音合成API完成对生成故事的语音合成,提供多种语音角色,满足不同受众需求。总的来说,整个过程分为图片关键信息提取、故事生成和语音合成三个步骤。除此之外,凭借ERNIE SDK提供的文生图功能,还可以对用户提供的图片进行二次创作。
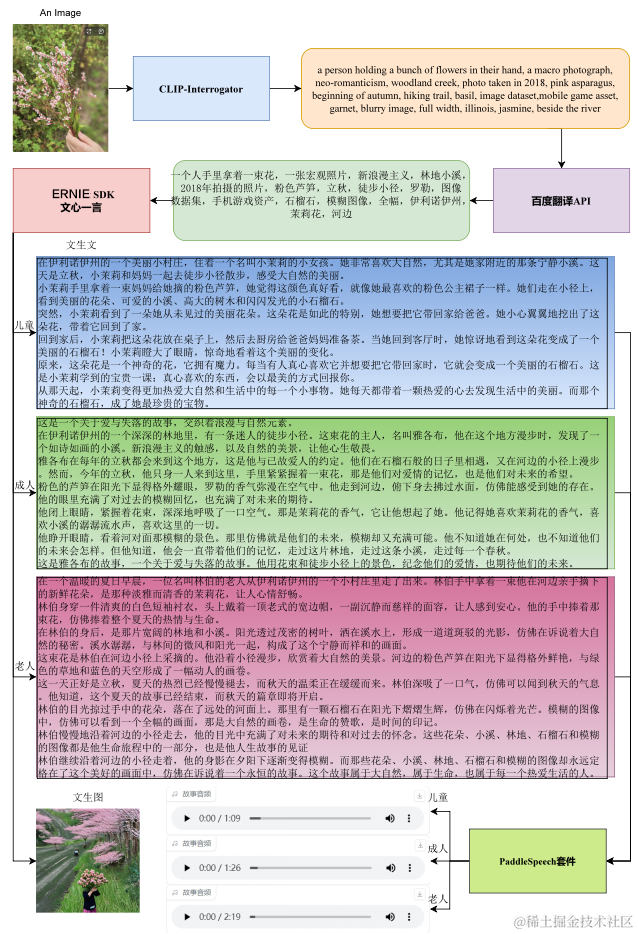
技术路径
接下来,我们看一下这个应用的几个功能具体是怎么实现的。打开飞桨星河社区,点击项目进行Fork,就可以运行里面的代码了。首先,需要配置项目的环境。在项目对应模块点击运行,就可以进行一键安装和配置。
图片关键信息提取
第一步,对进行图像中关键信息的提取。这一步需要用到CLIP Interrogator。CLIP Interrogator 是一个提示工程工具,结合了OpenAI的CLIP和Salesforce的BLIP,用于优化文本提示。它可以根据给定的图像和文本生成提示,帮助用户更好地理解和编辑图像。此外,CLIP Interrogator还提供了一些选项,如更改提示、调整强度等,使用户能更好地控制生成的结果。运行下列这段代码,即可进行这一图像的输出。
from PIL import Image
from clip_interrogator import Config, Interrogator
image_path = '/home/aistudio/launch/images/test02.jpg'
image = Image.open(image_path).convert('RGB')
ci = Interrogator(Config(clip_pretrained_model_name_or_path="openai/clip-vit-large-patch14"))
print(ci.interrogate_fast(image))
使用CLIP Interrogator从图像中得到的关键信息是英文的,而文心大模型更擅长处理中文。因此,为了提升最终的处理效果,调用百度翻译API对英文关键词进行翻译。
大家可以根据我所罗列的一些步骤调用百度翻译API。
百度翻译API:开发者只需传入待翻译的内容,并指定要翻译的源语言(支持源语言语种自动检测)和目标语言,即可得到相应的翻译结果。
故事生成
第二步,使用ERNIE SDK进行故事生成。文心大模型基于海量的中文数据训练,具有强大的对话问答、内容创作生成等能力。相较于其他大模型,其具有更快的响应速度和更丰富的功能。ERNIE SDK集成文心大模型能力,可用于开发各种自然语言处理应用,例如智能客服、聊天机器人、外语翻译器等。使用ERNIE SDK,开发者可以轻松地构建出高效、稳定、可靠的自然语言处理应用。
import erniebot as eb
# 创建单轮对话
eb.api_type = 'aistudio'
eb.access_token = "ebe9194da1106097f52ada09cb403b91546648ca"
audience = '成人'
prompt = f"""我给你一个简单的图片说明,请为{audience}观众生成一个与图片非常吻合的虚构故事。请为我生成有创意,正能量并且符合{audience}观众价值观和个人情感的很酷的虚构故事。图片描述如下:'{result_zh}'"""
def generate(prompt):
chat_completion = eb.ChatCompletion.create(
model='ernie-4',
messages=[{'role': 'user', 'content':prompt}],
)
return chat_completion.result
generate(prompt)
语音合成
第三步,通过调用语音合成API,将文本合成为自然流畅的语音,从而为用户提供更加丰富的语音交互体验。
import requests
import json
from bs4 import BeautifulSoup
import time
def get_access_token(api_key, secrte_key):
"""
使用 AK,SK 生成鉴权签名(Access Token)
:return: access_token,或是None(如果错误)
"""
url = "https://aip.baidubce.com/oauth/2.0/token"
params = {"grant_type": "client_credentials", "client_id": api_key, "client_secret": secrte_key}
return str(requests.post(url, params=params).json().get("access_token"))
# 创建词典数据
data = {
"度小宇": 1,
"度小美": 0,
"度逍遥(基础)": 3,
"度丫丫": 4,
"度逍遥(精品)": 5003,
"度小鹿": 5118,
"度博文": 106,
"度小童": 110,
"度小萌": 111,
"度米朵": 103,
"度小娇": 5
}
# 定义处理函数,根据选择按钮的值返回对应的词典数据
def handle_selection(key):
return data[key]
def get_taskid(api_key, secrte_key, prompt, voice, speed, pitch, volume):
create_url = "https://aip.baidubce.com/rpc/2.0/tts/v1/create?access_token=" + get_access_token(api_key, secrte_key)
create_payload = json.dumps({
"text": prompt, #待合成的文本
"format": "wav", #音频格式
"voice": handle_selection(voice), #音库
"lang": "zh", #语言,固定zh
"speed": speed, #语速
"pitch": pitch, #音调
"volume": volume, #音量
"enable_subtitle": 2, #是否开启字幕时间戳,取值范围0, 1, 2
"break": 5000 #段落间隔
})
create_headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
create_response = requests.request("POST", create_url, headers=create_headers, data=create_payload)
create_data = json.loads(create_response.text)
task_id = create_data['task_id']
# print(task_id)
# with open("task_id.txt", "w") as file:
# # 清空文件内容
# # file.truncate(0)
# # 将task_id写入文件
# file.write(task_id)
return task_id
def get_speechurl(api_key, secrte_key, prompt, voice, speed, pitch, volume):
query_url = "https://aip.baidubce.com/rpc/2.0/tts/v1/query?access_token=" + get_access_token(api_key, secrte_key)
task_id = get_taskid(api_key, secrte_key, prompt, voice, speed, pitch, volume)
query_payload = json.dumps({
"task_ids": [
task_id #create获取的task_id
]
})
query_headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
# 循环检查任务状态,直到任务成功
while True:
query_response = requests.request("POST", query_url, headers=query_headers, data=query_payload)
query_data = json.loads(query_response.text)
print(query_data)
# 检查任务状态
if query_data['tasks_info'][0]['task_status'] == 'Success':
speech_url = query_data['tasks_info'][0]['task_result']['speech_url']
return speech_url
break
def exchange_speech(api_key, secrte_key, prompt, voice, speed, pitch, volume):
speech_url = get_speechurl(api_key, secrte_key, prompt, voice, speed, pitch, volume)
html = f'''
<video controls="" autoplay="" name="media">
<source src={speech_url} type="audio/x-wav">
</video>
'''
# 使用 BeautifulSoup 提取音频 URL
soup = BeautifulSoup(html, 'html.parser')
audio_url = soup.find('source')['src']
# 使用 requests 下载音频文件
response = requests.get(audio_url)
filename = "output_audio.wav"
# 保存至本地文件
with open(filename, 'wb') as audio_file:
audio_file.write(response.content)
return f"{filename}"
“文心一言情感关怀之旅”怎么用?
接下来,我将一步步带大家体验这一应用,探索各个功能是如何实现的。点击任意一个example,实现API_KEY、SECRTE_KEY和图片自动填充。

当然,也可以自主上传图片;通过选择儿童、成人或者老人等目标受众,生成相应的内容。在此过程中,我们还可以选择想要的语音形态,包括语速、音量等,设置完毕后就可以进行睡前故事体验。
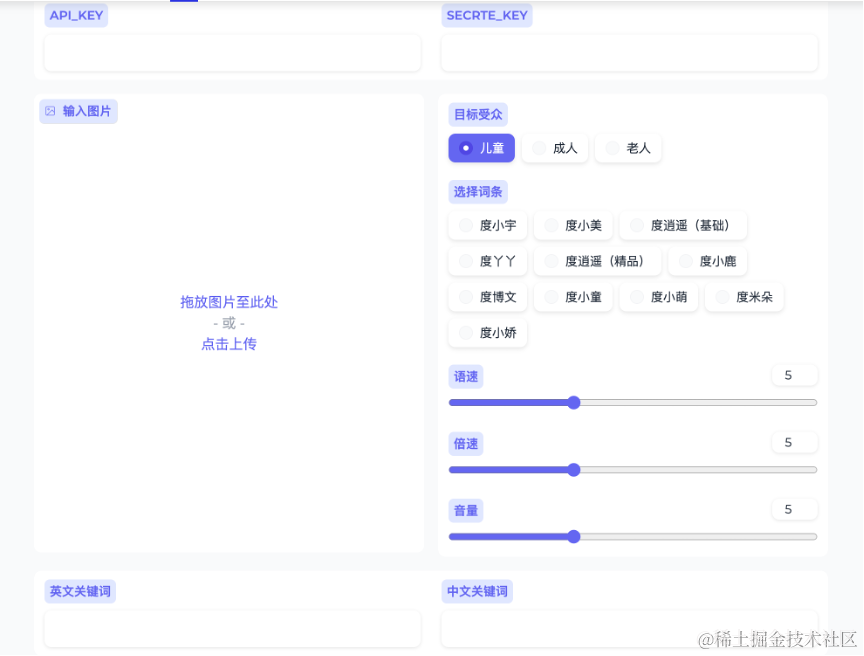
大概30秒就能生成中文或英文的故事,并以匹配的语音输出。用户可以通过输入图片、关键词完成故事创作,文心一言会根据图片和关键词生成一个富有创意、正能量的故事,符合所选受众的价值观以及个人情感需求。除此之外,生成的文字性内容也可以转换为语音、视频。
“文心一言情感关怀之旅”应用的下一个目标是把故事中的场景转换为看得见、摸得着的虚拟场景,真正能够在实际生活中使用,为人们提供一些情感知识,让AI更有温度,更透彻地理解人们想要表达的内容。大家可以进行更深入的探索,在配置基础上进行完善;也可以在我的应用或项目下面评论,建言献策,我将尽力完善应用,真正做到使个人情感与文心一言结合,为社会带来价值。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 项目中对日期进行格式化的方法
- Git学习笔记:3 git tag命令
- 手把手带你死磕ORBSLAM3源代码(十五)System.cc void System::SaveKeyFrameTrajectoryTUM类代码分析
- PFA试剂瓶-湿电子化学品行业年度最爱的瓶子
- Java中对象的创建和使用
- iview表格固定列横向滚动条无法拖动问题
- SGML .HTML 、XML和XHTML的区别?
- 牙科废水处理设备详细介绍
- 【分布式技术】监控平台zabbix介绍与部署
- SSL VPN移动安全接入策略