java基础之Java8新特性-Stream(流)
简介
流(Stream)是 Java 8 引入的一种处理集合数据的抽象概念,它提供了一种更简洁、更灵活的方式来操作和处理集合数据。流可以看作是一系列元素的管道,可以对这些元素进行筛选、转换、排序、归约等操作,实现各种数据处理需求。与传统的循环迭代方式相比,流的代码更易读、更易于并行化处理,并且能够充分发挥多核处理器的优势。通过使用流,可以提高代码的可读性和可维护性,同时也能够更高效地处理大规模数据集合。

Stream的常用案例
1.steam将list集合转set集合
public static void main(String [] args){
List<Student> students=Arrays.asList(new Student("小明",18),new Student("小黑",16),new Student("小红",17));
//转成流并进行set集合转换
Set<Student> sets=students.stream().collect(Collectors.toSet());
//集合遍历
sets.forEach(stu->System.out.println(stu.toString()));
}在上面的示例中,我们首先创建了一个 List 集合 list,包含了三个对象。然后使用 stream 方法将其转换为流,接着使用 collect 方法将流中的元素收集到一个 Set 集合中,使用 Collectors.toSet() 指定要收集到的集合类型。最终得到了一个包含唯一元素的 Set 集合。
注意:转成set集合需要重写实体类Student的equals 方法和?hashCode 方法。
2.steam将list集合转map集合
public static void main(String [] args){
List<Student> students=Arrays.asList(new Student("小明",18),new Student("小黑",16),new Student("小红",17));
//转成Stream
Stream<Student> stream=students.stream();
//转Map
Map<String,Student> map=stream.collect(Collectors.toMap(student->student.getName(), student->student));
//遍历
map.forEach((key,value)->System.out.println(key+"--"+value));
}在上面的示例中,我们首先创建了一个包含学生对象的 List<Student> 集合 students。然后使用 stream 方法将其转换为流,接着使用 collect 方法将流中的元素收集到一个 Map 集合中,使用 Collectors.toMap() 指定键和值的提取方式。在这里,我们使用学生对象的姓名作为键,学生对象本身作为值。
3.steam计算求和
public static void main(String[] args) {
List<Student> students= Arrays.asList(new Student("小明",18),new Student("小黑",16),new Student("小红",17));
//创建流并累加年龄
int sum=students.stream().mapToInt(Student::getAge).sum();
System.out.println(sum);
}4.steam查找最值
public static void main(String[] args) {
List<Student> students= Arrays.asList(new Student("小明",18),new Student("小黑",16),new Student("小红",17));
//找出年龄最大的人
Optional<Student> max=students.stream().max((o1, o2)->o1.getAge()-o2.getAge());
System.out.println(max);
//找出年龄最小的人
Optional<Student> min=students.stream().min((o1, o2)->o1.getAge()-o2.getAge());
System.out.println(min);
}5.stream的match
match 方法用于判断流中的元素是否符合指定的条件,并返回一个布尔值。
match 方法有三个变种:
-
allMatch方法:判断流中的所有元素是否都符合指定的条件,如果都符合,返回true,否则返回false。 -
anyMatch方法:判断流中是否存在任意一个元素符合指定的条件,如果有,返回true,否则返回false。 -
noneMatch方法:判断流中是否不存在任何一个元素符合指定的条件,如果没有,返回true,否则返回false。
public static void main(String[] args) {
List<Student> students= Arrays.asList(new Student("小明",18),new Student("小黑",16),new Student("小红",17));
// 判断所有学生年龄是否都大于17
boolean match = students.stream().allMatch(s -> s.getAge() > 17);
System.out.println(match);//false
//判断只要有一个学生年龄小于17
boolean match1 = students.stream().anyMatch(s -> s.getAge() < 17);
System.out.println(match1);//true
//判断没有一个学生年龄大于18
boolean match2 = students.stream().noneMatch(s -> s.getAge() > 18);
System.out.println(match2);//true
}6.stream过滤器
filter 方法接受一个 Predicate 参数,该参数是一个函数式接口,用于指定过滤条件。filter 方法会根据条件筛选出流中符合条件的元素,并返回一个新的流。
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
// 过滤并打印出所有偶数
Stream<Integer> evenNumbers = numbers.stream().filter(n -> n % 2 == 0);
evenNumbers.forEach(System.out::println);
}7.stream Limit和skip
Stream 类提供了 limit 和 skip 方法,用于限制流中元素的数量。
1.limit?方法:该方法用于截取流中的前 n 个元素,并返回一个新的流。如果流中的元素不足 n 个,则返回包含所有元素的流。
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
// 获取前3个元素
Stream<Integer> limitedStream = numbers.stream().limit(3);
limitedStream.forEach(System.out::println);
}2.skip?方法:该方法用于跳过流中的前 n 个元素,并返回一个新的流。如果流中的元素不足 n 个,则返回一个空的流。
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
//跳过前两个元素
Stream<Integer> skipStream = numbers.stream().skip(2);
skipStream.forEach(System.out::println);
}一般我们会通过limit方法和skip搭配进行分页截取
public static void main(String[] args) {
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5,6,7,8,9,10);
//一页五个截取第二页
Stream<Integer> skipLimitStream = numbers.stream().skip(5).limit(5);
skipLimitStream.forEach(System.out::println);
}8.stream实现排序
public static void main(String[] args) {
// 创建一个包含整数的Stream
Stream<Integer> stream1 = Stream.of(3, 1, 4, 1, 5, 9);
Stream<Integer> stream2 = Stream.of(3, 1, 4, 1, 5, 9);
// 使用sorted()方法对Stream1进行升序排序(默认)
Stream<Integer> sortedStream = stream1.sorted();
sortedStream.forEach(System.out::println);
System.out.println("-----------------------------------------------");
// 使用sorted()方法对Stream2进行降序排序
Stream<Integer> sortedDescStream = stream2.sorted((a, b) -> b.compareTo(a));
sortedDescStream.forEach(System.out::println);
}9.组合案例
我们来看一个需求
对给定的学生列表按照年龄降序排列并查找姓张的,获取前3位
public static void main(String[] args) {
List<Student> students= Arrays.asList(new Student("张明",18),
new Student("李黑",16),
new Student("王红",17),
new Student("张三",36),
new Student("李四",27),
new Student("刘备",56),
new Student("关羽",47),
new Student("张飞",49),
new Student("张同",17),
new Student("张良",41));
//降序排序--查找姓张的--截取前三位
students.stream().sorted((s1,s2)->s2.getAge()-s1.getAge())
.filter(s->s.getName().startsWith("张"))
.limit(3).forEach(System.out::println);
System.out.println("-----------------------------------------------");
}通过对流进行一系列的中间操作就可以完成这个需求,这种链式调用可以使代码非常简洁。
10.并行流
Stream 类提供了并行流的支持,可以通过 parallel 方法将一个顺序流转换为并行流。并行流可以充分利用多核处理器的优势,将流中的元素进行并发处理,从而提高处理效率。
前面所有流的示例都是顺序流(单线程),有时在面对较大的数据处理单线程效率太慢,我们就可以使用并行流(多线程)进行优化。
来看一个需求,求1-1亿的累加和,分别用单线程的顺序流跟多线程的并行流来看执行效率。
public static void main(String[] args) {
// 顺序流计算
long start = System.currentTimeMillis();
int sum = IntStream.rangeClosed(1, 1000000000).sum();
long end = System.currentTimeMillis();
System.out.println("顺序流计算结果:" + sum + ",耗时:" + (end - start) + " 毫秒");
// 并行流计算
start = System.currentTimeMillis();
sum = IntStream.rangeClosed(1, 1000000000).parallel().sum();
end = System.currentTimeMillis();
System.out.println("并行流计算结果:" + sum + ",耗时:" + (end - start) + " 毫秒");
}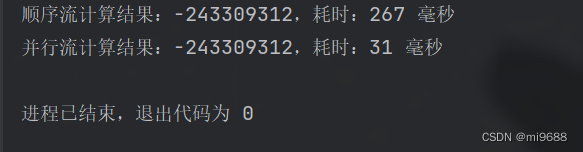
可以看到执行效率还是有明显提升的。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 用python编写popper支持的pdf转jpg格式windows应用程序
- 逆向获取某音乐软件的加密(js逆向)
- C++ 字符串中找子串出现的个数。
- 黑客掌握的木马攻击运行的技巧之一开机启动并隐藏 cmd 窗口程序在后台运行
- 嵌入式PC技术的应用领域有哪些?
- MySQL备份总结
- 【PWA】渐进式Web应用(Progressive Web App)
- Hive之set参数大全-9
- 计算机创新协会冬令营——暴力枚举题目07
- wireshark