Rust类型之字符串
发布时间:2024年01月11日
字符串
Rust 中的字符串类型是String。虽然字符串只是比字符多了一个“串”字,但是在Rust中这两者的存储方式完全不一样,字符串不是字符的数组,String内部存储的是Unicode字符串的UTF8编码,而char直接存的是Unicode Scalar Value。
Rust字符串对Unicode字符集有着良好的支持,可以看一下示例:
let hello = String::from("こんにちは");
let hello = String::from("Dobry den");
let hello = String::from("Hello");
let hello = String::from("???????");
let hello = String::from("??????");
let hello = String::from("?????");
let hello = String::from("你好");
let hello = String::from("Olá");
let hello = String::from("?????? ?????");
let hello = String::from("Здравствуйте");
let hello = String::from("Hola");
Rust 中的String不能通过下标去访问。
let testString = String::from("天下");
let s = testString[0]; // 你可能想把“天”字取出来,但实际上这样是错误的
String存储的Unicode序列的UTF8编码,而UTF8编码是变长编码。上边即使能访问成功,也只能取出一个字符的 UTF8 编码的第一个字节,很可能是没有意义的。因此 Rust 直接对String禁止了这个索引操作。
字符串字面量中的转义
与 C 语言一样,Rust 中转义符号也是反斜杠\,可用来转义各种字符。
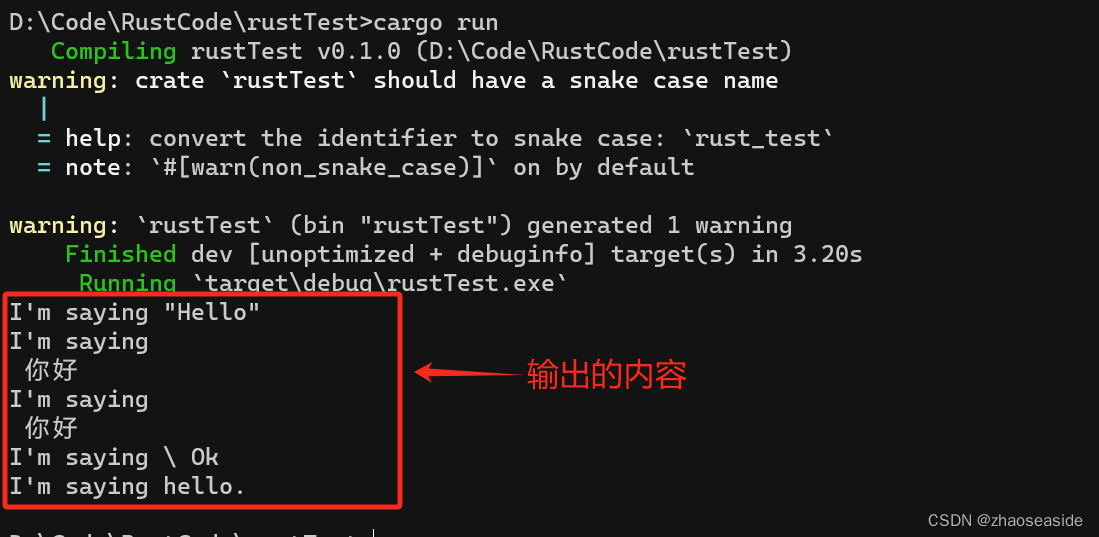
fn main() {
// 将""号进行转义
let byte_escape = "I'm saying \"Hello\"";
println!("{}", byte_escape);
//输出的内容为 I'm saying "Hello"
// 分两行打印
let byte_escape = "I'm saying \n 你好";
println!("{}", byte_escape);
//输出的内容是
// I'm saying
// 你好
// Windows下的换行符
let byte_escape = "I'm saying \r\n 你好";
println!("{}", byte_escape);
//输出的内容是
// I'm saying
// 你好
// 打印出 \ 本身
let byte_escape = "I'm saying \\ Ok";
println!("{}", byte_escape);
//输出的内容是 I'm saying \ Ok
// 强行在字符串后面加个0,与C语言的字符串一致。
let byte_escape = "I'm saying hello.\0";
println!("{}", byte_escape);
//输出的内容是 I'm saying hello.
}
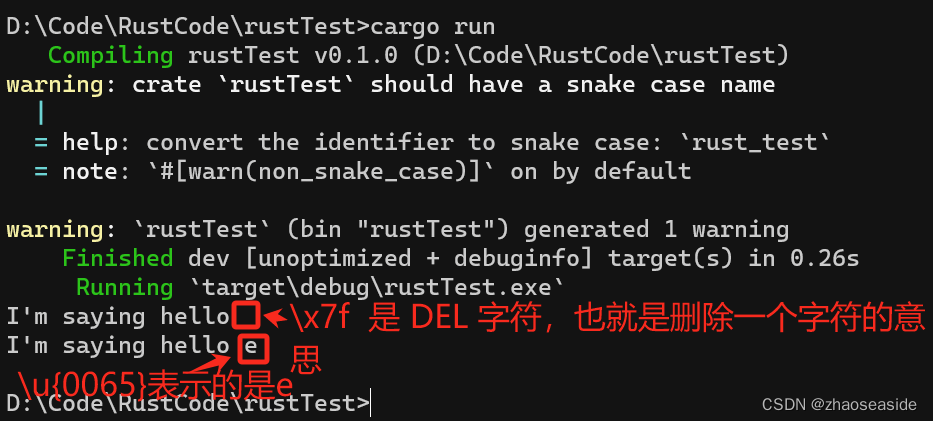
Rust 还支持通过\x输入等值的 ASCII 字符,以及通过\u{}输入等值的 Unicode 字符。
fn main() {
// 使用 \x 输入等值的ASCII字符(最高7位)
let byte_escape = "I'm saying hello \x7f";
println!("{}", byte_escape);
// 使用 \u{} 输入等值的Unicode字符(最高24位)
let byte_escape = "I'm saying hello \u{0065}"; // 0065表示的是十六进制 65,也是十进制 101
println!("{}", byte_escape);
}
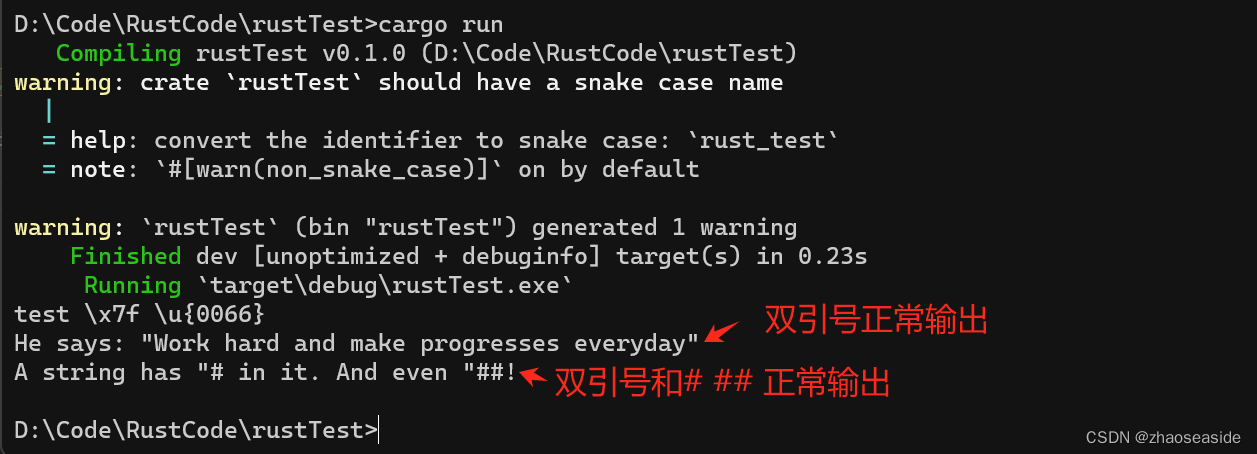
禁止转义的字符串字面量
我们要是想输出原始字面量,也就是不进行转义,使用 r""或r#""#把字符串字面量套起来就行了。
fn main() {
// 字符串字面量前面加r,表示不转义
let test_str = r"test \x7f \u{0066}";
println!("{}", test_str);
// 这个字面量必须使用r##这种形式,因为我们希望在字符串字面量里面保留""
let test_string = r#"He says: "Work hard and make progresses everyday""#;
println!("{}", test_string );
// 如果遇到字面量里面有#号的情况,可以在r后面,加任意多的前后配对的#号,
// 只要能帮助Rust编译器识别就行
let test_string1 = r###"A string has "# in it. And even "##!"###;
println!("{}", test_string1);
}
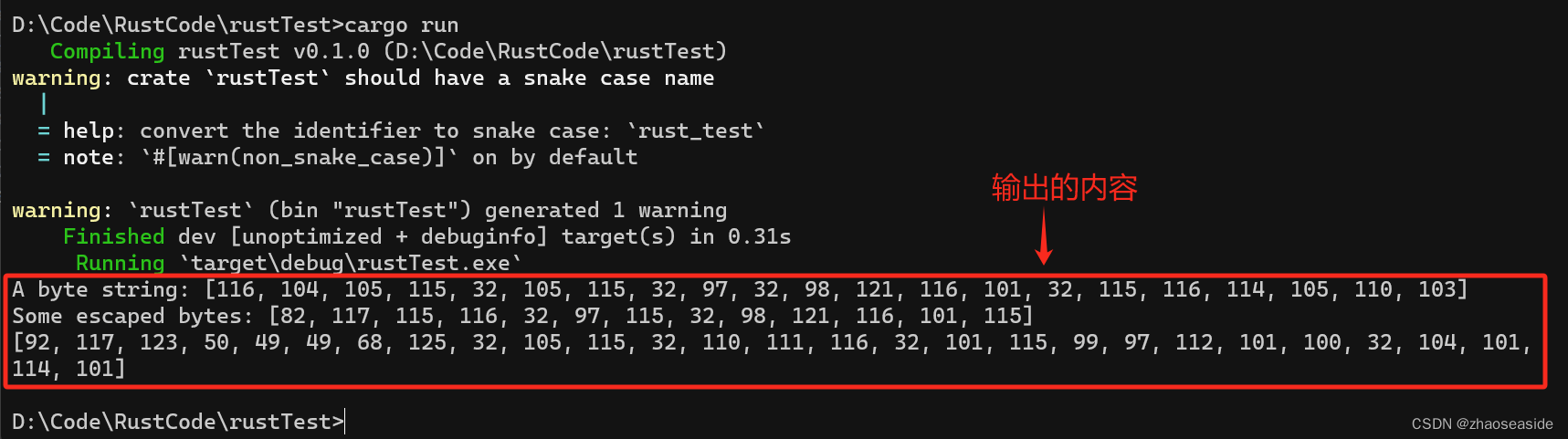
字节串
很多时候,我们只需要 ASCII 字符集,字符串字面量中用不到Unicode字符。对于这种问题,Rust 还有一种更紧凑的表示法:字节串。用b开头,双引号括起来,比如b"this is a byte string"。这时候字符串的类型已不是字符串,而是字节的数组 [u8; N],N为字节数。示例代码如下:
fn main() {
// 字节串的类型是字节的数组,而不是字符串了
let bytestring: &[u8; 21] = b"this is a byte string";
println!("A byte string: {:?}", bytestring);
// 可以看看下面这串打印出什么
let escaped = b"\x52\x75\x73\x74 as bytes";
println!("Some escaped bytes: {:?}", escaped);
// 字节串与原始字面量结合使用
let raw_bytestring = br"\u{211D} is not escaped here";
println!("{:?}", raw_bytestring);
}
文章来源:https://blog.csdn.net/qq_42108074/article/details/135514687
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 【数据库原理】(6)关系数据库的关系操作集合
- 如何设置gitlab.rb 将所有数据运行目录放置到指定目录
- MAC电脑如何正确的使用开发工具配置SVN
- 前后端分离下的鸿鹄电子招投标系统:使用Spring Boot、Mybatis、Redis和Layui实现源码与立项流程
- Golang标准库sync的使用
- UmiMax学习笔记
- 设计模式:原型模式
- <sa8650>sa8650 qcxserver-之-DiagnosticManager运用
- SpringBoot整合JWT+Spring Security+Redis实现登录拦截(二)权限认证
- 潍柴动力从产业技术品牌出发存在全球商用车竞争机会